
Рефераты по рекламе
Рефераты по физике
Рефераты по философии
Рефераты по финансам
Рефераты по химии
Рефераты по хозяйственному праву
Рефераты по цифровым устройствам
Рефераты по экологическому праву
Рефераты по экономико-математическому моделированию
Рефераты по экономической географии
Рефераты по экономической теории
Рефераты по этике
Рефераты по юриспруденции
Рефераты по языковедению
Рефераты по юридическим наукам
Рефераты по истории
Рефераты по компьютерным наукам
Рефераты по медицинским наукам
Рефераты по финансовым наукам
Рефераты по управленческим наукам
Психология и педагогика
Промышленность производство
Биология и химия
Языкознание филология
Издательское дело и полиграфия
Рефераты по краеведению и этнографии
Рефераты по религии и мифологии
Рефераты по медицине
Рефераты по сексологии
Рефераты по информатике программированию
Краткое содержание произведений
Реферат: Защита информации в системах дистанционного обучения с монопольным доступом
Реферат: Защита информации в системах дистанционного обучения с монопольным доступом
АННОТАЦИЯ
Данная диссертация посвящена вопросам построения систем защиты информации для программных пакетов, используемых в монопольном доступе. В качестве объекта для исследования и применения разработанных методов защиты служат системы дистанционного обучения и контроля знаний.
Рассмотрены различные методы применяемые для создания разнообразных систем защиты, рассмотрена возможность их применения для систем дистанционного обучения. Проанализированы ключевые места, требующие защиты и предложены варианты ее осуществления, отмечены их преимущества и недостатки. Предложены новые пути реализации защиты для систем используемых в монопольном режиме. Разработан набор программных модулей предназначенный для интеграции в защищаемый программный комплекс и реализующий подсистему защиты. Проведена апробация созданной подсистемы защиты на одном из пакетов дистанционного тестирования. Приведены руководства и программная документация по интеграции и использованию созданной подсистемы защиты для различных программных комплексов.
Диссертация содержит 168 страниц, 12 иллюстраций, 1 таблицу.
СОДЕРЖАНИЕ
|
ВВЕДЕНИЕ………………………………………………………………………... ГЛАВА 1. СОЗДАНИЕ ЗАЩИТЫ ДЛЯ ПРОГРАММНЫХ ПАКЕТОВ, НА ПРИМЕРЕ СИСТЕМЫ ДИСТАНЦИОННОГО ОБУЧЕНИЯ………………….……….. 1.1. Вопросы защиты информации, стоящие перед автоматизированными системами дистанционного обучения………………………………….. 1.2. Обзор публикаций по данной проблеме………………………………… 1.3. Задачи поставленные перед создаваемой системой защиты…………... 1.4. Выбор класса требований к системе защиты…………………………… 1.5. Выводы……………………………………………………………………. ГЛАВА 2. ПРЕДЛАГАЕМЫЕ МЕТОДЫ СОЗДАНИЯ ИНТЕГРИРУЕМОЙ СИСТЕМЫ ЗАЩИТЫ ИНФОРМАЦИИ ………………………………………………… 2.1. Выбор объектов для защиты……………………………………………. 2.2. Шифрование данных…………………………………………………….. 2.2.1. Некоторые общие сведения……………………………………… 2.2.2. Асимметричные криптосистемы……………………….……….. 2.2.2.1. Криптосистема Эль-Гамаля……………………………. 2.2.2.2. Криптосистема Ривеста-Шамира-Эйделмана………… 2.2.2.3. Криптосистема, основанная на эллиптических кривых…………………………………………………. 2.2.3. Адаптированный метод асимметричного шифрования……….. 2.3. Преимущества применения полиморфных алгоритмов шифрования…………………………………………………….………... 2.4. Функциональность системы защиты……………………………………. ГЛАВА 3. РЕАЛИЗАЦИЯ СИСТЕМЫ ЗАЩИТЫ………………………….. 3.1. Выбор средств разработки и организации системы………….………… 3.1.1. Краткая характеристика языка программирования С++………. 3.1.2. Краткая характеристика среды Visual C++…………….……….. 3.1.3. Краткая характеристика библиотеки ATL……………………… 3.1.4. Краткая характеристика библиотеки ZLIB…………………….. 3.2. Полиморфный генератор алгоритмов шифрования……………………. 3.2.1. Общие принципы работы полиморфных алгоритмов шифрования и расшифрования………………………………… 3.2.2. Виртуальная машина для выполнения полиморфных алгоритмов………………………………………………….……. 3.2.3. Генератор полиморфного кода…………………………….…….. 3.2.3.1. Блочная структура полиморфного кода……………….. 3.2.3.2. Алгоритм генерации полиморфного кода…….………. 3.2.3.3. Таблицы блоков для генерации полиморфного кода……………………………………………………... 3.2.4. Уникальность генерируемого полиморфного алгоритма и сложность его анализа…………………………………………... 3.3. Особенности реализации модуля защиты.……………………………… 3.4. Защита исполняемых файлов……………………………………………. ГЛАВА 4. ПРИМЕНЕНИЕ СИСТЕМЫ ЗАЩИТЫ………………….……… 4.1. Состав библиотеки Uniprot………………………………………………. 4.2. Руководство программиста по использованию модуля Uniprot.dll……………………………………………………….………... 4.3. Руководство программиста по использованию программы ProtectEXE.exe………………………………………………….….…….. 4.4. Описание использования системы защиты на примерах………………. 4.4.1. Подключение модуля защиты к программе на языке Visual C++………………………………………………………………... 4.4.2. Подключение модуля защиты к программе на языке Visual Basic………………………………………………………………. 4.4.3. Пример использования модуля защиты в программе на языке Visual Basic……………………………………….……………… 4.4.4. Пример использования программы ProtectEXE.exe…………… 4.5. Общие рекомендации по интеграции системы защиты……………….. ОСНОВНЫЕ ВЫВОДЫ И РЕЗУЛЬТАТЫ…………………………………. СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ ………………………… ПРИЛОЖЕНИЕ. ИСХОДНЫЕ ТЕКСТЫ БИБЛИОТЕКИ UNIPROT………………………………………………………………………..… |
7 12 12 14 27 30 33 34 34 38 38 40 41 42 43 43 45 47 48 48 48 49 50 51 52 52 56 59 59 62 63 65 68 69 70 70 71 86 88 88 89 90 98 99 101 102 105 |
ВВЕДЕНИЕ
Развитие вычислительной техники открыло перед человеком огромное количество новых возможностей. Вычислительная техника нашла применение практически во всех сферах жизнедеятельности человека. Но, как и любой другой предмет, который нас окружает, вычислительную технику можно использовать как во благо, так и во вред. Всегда есть категория людей, имеющих корыстные интересы, и готовых для их достижения пойти на все, не считаясь ни с интересами других, ни с законами. Так, в последнее время много проблем разработчикам программного обеспечения доставляет незаконное копирование и распространение программ (так называемое программное пиратство). К проблемам компьютерной индустрии также можно отнести постоянно совершенствующиеся программные вирусы, от которых порой лихорадит весь мир. Постоянные попытки взлома хакерами различных сетей и систем вынуждают создавать все более и более мощные средства защиты. Это лишь часть всего того, что причиняет сегодня вред разработчикам программного обеспечения и их пользователям. На борьбу с вредоносными программами (вирусами) тратятся огромные материальные ресурсы. Но пока значительных и радикальных побед на этом поле битвы не достигнуто. Это, в принципе, не удивительно, так как компьютерная индустрия находится на этапе становления. Кроме того, эта часть рынка позволяет получать сверхприбыли. Примером может служить компания Microsoft, которая за несколько лет из маленькой группы разработчиков превратилась в огромную корпорацию, получающую огромные доходы. Следовательно, если есть сверхприбыли, то есть и желающие незаконным путем получить их часть. Таким образом, защита информации сейчас являются одной из наиболее важных проблем развития информационных технологий. В связи со сказанным ранее, вопросы защиты информации и были выбраны мною в качестве тематики диссертационной работы.
Естественно, что проблемы, связанные с защитой информации, многогранны. И в своей работе я хочу затронуть и попытаться и решить только небольшую их часть, выбрав в качестве направления своей работы защиту систем, используемых в монопольном режиме, вне доверительной среды. Объектами исследования являться системы дистанционного обучения. Эти системы выбраны благодаря тому, что являются удачным примером программ, работающих в режиме монопольного доступа. Именно в таком режиме работает большинство систем дистанционного обучения. Под монопольным доступом понимается возможность пользователя совершать с программой любые действия, без возможности контроля со стороны. Для этих систем характерны такие задачи по информационной безопасности, как защита от несанкционированного копирования, от модификации программного кода в интересах пользователя, сокрытие от пользователя части информации и ряд других. Многие из этих задач весьма актуальны для систем дистанционного обучения и тестирования.
В настоящее время большинство специалистов в области образования возлагают надежды на современные персональные компьютеры, рассчитывая с их помощью существенно повысить качество обучения в массовых масштабах, особенно при организации самостоятельной работы и внешнем контроле [1, 2, 3]. Но при осуществлении этой задачи возникает множество проблем. Одна из них состоит в том, что в разработках автоматизированных системах дистанционного обучения (АСДО) нет никакой системы, никакого объединяющего начала, вследствие чего все АСДО являются уникальными, разрозненными, не сопряженными друг с другом ни по каким параметрам. Отсюда следует дублирование разработок электронных учебников, их высокая цена при не всегда гарантированном качестве, трудности организации внешнего контроля, а также неясность вопросов, относящихся к дидактической эффективности компьютерного обучения вообще, слабая интеграция традиционных учебников с компьютерными и многие другие. Все эти трудности, с которыми приходится сталкиваться разработчикам любых компьютерных обучающих систем, составляют «узкое» место в компьютеризации обучения. Не устранив его, трудно надеяться на успешное выполнение программы, представленной в проекте [4], где запланировано «создание и эффективное использование единой образовательной среды на компьютерной основе» и перечислены задачи, являющиеся первоочередными в выполнении программы. Например, одна из задач сформулирована следующим образом: «Создание, распространение и внедрение в учебный процесс современных электронных учебных материалов, их интеграция с традиционными учебными пособиями, а также разработка средств поддержки и сопровождения. Обеспечение качества, стандартизация и сертификация средств информационных технологий учебного назначения» [4]. Совершенно очевидно, что эффективность выполнения программы непосредственно зависит от того, насколько успешно будут преодолены трудности.
Очень важной проблемой в области организации самостоятельной работы и, особенно, компьютерного внешнего контроля является слабая защищенность образовательного программного обеспечения от «взлома» с целью доступа к правильным ответам и подделки результатов контроля [5, 6, 7, 8, 9, 10, 11, 12]. Эта проблема вытекает из того, что в основном современные контролирующие системы строятся на антропоморфном принципе, суть которого применительно к автоматизации обучения заключается в использовании памяти компьютера для хранения эталонных ответов вместе с заданиями. Как правило, они шифруются, но, как показывает практика, их всегда можно расшифровать. Эта проблема особенно остро встала с появлением в России дистанционных технологий обучения, где внешний контроль знаний осуществляется в основном компьютером в отсутствие преподавателя.
Существует также проблема защиты обучающего программного обеспечения от модификации его кода, с целью изменения алгоритма оценивания результатов тестирования или другого кода. Слабая защищенность от «взлома» любых антропоморфных контролирующих систем создает трудности при проведении контроля в системах дистанционного образования. Внешний контроль на расстоянии исключен, так как никто не может гарантировать, что контролирующие программы не были «взломаны» в процессе выполнения контрольной работы. В связи с этим, экзамен возможен лишь за счет выезда преподавателя к месту встречи с «дистанционщиками». Но и в этом случае объективность не гарантируется, так как благодаря наличию ответов в контролирующей программе, преподаватель может не только пользоваться инструкциями по проведению экзамена, но и проявлять собственную инициативу, по своему усмотрению распоряжаясь имеющейся у него информацией об эталонных ответах. Кроме того, из-за выездов преподавателей падает качество обучения студентов очной системы образования. В последнее время появилась новая форма экзамена, которую многие называют «распределенной» или «разнесенной» формой. Этот подход позаимствован у студентов заочной формы обучения. В этом случае студентам, обучающимся по дистанционной технологии, высылают только экзаменационные вопросы (без ответов). Студенты на них отвечают и высылают свои результаты в центр дистанционного обучения. Там они проверяются, и студентам сообщаются результаты. Такая форма обеспечивает достаточную объективность экзамена, но не пользуется популярностью, так как студенты хотят знать свои результаты сразу после экзамена, а не через несколько дней, потому что, в случае неудовлетворительной оценки, они смогут пересдать экзамен не сразу, а лишь спустя некоторое (довольно длительное) время.
Таким образом, исследование методов создания системы защиты программ дистанционного обучения имеют большое практическое значение. Но в связи с тем, что дистанционное образование находится в стадии становления в нашей стране, проблемы защиты практически не проработаны. В данной работе будут исследованы методы и предложено несколько подходов для создания интегрируемой системы защиты дистанционных образовательных систем.
Целью настоящей работы является анализ методов защиты информации без использования вспомогательных аппаратных средств и создание интегрируемого пакета программных модулей для защиты систем функционирующих в монопольном режиме вне доверенной вычислительной среды.
Задачи исследования.
Для достижения поставленной цели в диссертационной работе на примере АСДО сформулированы и решены следующие задачи:
1) Выделены основные ключевые объекты, подлежащие защите.
2) Разработаны методы защиты АСДО вне доверенной вычислительной среды от массовых попыток модификации кода.
3) Разработаны методы защиты данных для систем обучения и контроля знаний вне доверенной вычислительной среды.
4) Проведен анализ и предложены возможные способы применения разработанных методов.
5) На основе данных методов разработан набор программных модулей защиты, предназначенных для интегрирования в системы дистанционного обучения.
Актуальность работы обусловлена тем, что с развитием компьютерных технологий в образовательном процессе появилась необходимость в создании эффективных систем обучения, самоконтроля, внешнего контроля и защиты информации.
Научная новизна работы состоит в следующем:
1) Предложен метод защиты программ путем шифрования исполняемых файлов, основанный на использовании множества уникальных полиморфных алгоритмов.
2) Предложен метод организации защиты информации и ее обмена с применением идеологии открытого ключа, основанной на полиморфных алгоритмах.
3) Отказ от использования аппаратных средств.
4) Создание единого набора интегрируемых программных модулей для интеграции в различные системы дистанционного обучения.
Методы исследования базируются на анализе работ, посвященных вопросам защиты информации, и на работах, связанных с защитой обучающих программных комплексов.
Практическая ценность:
1. Разработаны эффективные методы защиты систем дистанционного обучения вне доверенной вычислительной среды.
2. Основываясь на разработанном методе полиморфных алгоритмах шифрования, были предложены механизмы, препятствующие созданию универсальных средств обхода системы защиты.
3. Разработанные методы не нуждаются в аппаратных средствах для своей реализации.
4. Возможность легкой интеграции созданной системы защиты в уже существующие программные комплексы дистанционного обучения.
Внедрение разработки:
Разработанная система защиты была интегрирована в программный комплекс Aquarius Education 4.0, созданный на кафедре АТМ под руководством Юхименко Александра и представляющий собой систему автоматизированного тестирования.
Апробация работы.
Все вопросы, относящиеся к теме диссертации, обсуждались на различных конференциях:
Построение защиты в системе контроля и передачи знаний. Печатный Сборник докладов международной научной конференции ММТТ-Дон. РГХАСМ, Ростов-на-Дону, 2002. 2 стр.
Система интеграции защиты информации для пакетов автономного дистанционного обучения. Печатный Сборник докладов международной научной конференции ММТТ-Дон. РГХАСМ, Ростов-на-Дону, 2003. 2 стр.
Диссертация состоит из введения, четырех глав, заключения и приложения.
В первой главе рассмотрены трудности разработки автоматизированных систем дистанционного обучения с точки зрения их защиты. Проведен обзор публикаций по данной тематике, выделены задачи, возлагаемые на разрабатываемую систему защиты.
Во второй главе предложены методы реализации требований, предъявленных системе защиты. Выбраны объекты защиты, рассмотрены асимметрические методы шифрования и предложен адаптированный метод для разрабатываемой системы.
В третьей главе внимание уделено непосредственно реализации системы защиты. Выбраны средства разработки, рассмотрен процесс создания компонентов системы защиты.
Четвертая глава описывает возможности разработанной системы и содержит руководство программиста по ее использованию, ряд примеров. Также даны общие рекомендации по интеграции разработанной системы.
В заключении подведены итоги проделанной работы.
В приложении приведен исходный текст модуля защиты.
ГЛАВА 1. СОЗДАНИЕ ЗАЩИТЫ ДЛЯ ПРОГРАММНЫХ ПАКЕТОВ, НА ПРИМЕРЕ СИСТЕМЫ ДИСТАНЦИОННОГО ОБУЧЕНИЯ
1.1. Вопросы защиты информации, стоящие перед автоматизированными системами дистанционного обучения
Все большее внимание уделяется новому направлению в образовании – дистанционному обучению. Дистанционное образование с одной стороны открывает новые возможности, с другой ставит новые задачи. Одной из задач является построение защиты в системе контроля и передачи знаний.
Примером может служить контроль за достоверностью результатов компьютерного тестирования. Сюда же, относится проблема построения системы разграничения доступа в различных программных комплексах, предназначенных для автоматизации процесса обучения. Рассмотрим часто встречающуюся на данный момент ситуацию. На кафедре создана система, включающая виртуального лектора и подсистему тестирования. В случае использования данной системы в аудиториях кафедры, никаких сложностей не возникает, так как студенты находятся под контролем преподавательского состава. Но ориентация образования на дистанционное обучение вносит свои коррективы. Возникает потребность в возможности использования данного программного обеспечения студентом на своей локальной машине. Такая задача может быть решена (и решается достаточно хорошо) с применением сетевых технологий. В такой системе студент заходит на сайт, где он может заниматься обучением или проходить различные виды тестирования. Но система неудобна тем, что требует постоянного подключения к сети. Имеют место следующие негативные стороны:
а) немалые финансовые затраты;
б) необходимость, чтобы каждый студент имел возможность находиться в сети;
в) низкая пропускная способность, если брать во внимание качество отечественных телефонных линий;
г) вынужденное ограничение учебного материала, вызванного его объемом. Например, придется ограничиться картинкой, где совсем бы не помешало показать видеоролик.
Отсюда возникает потребность сделать эту систему автономной с возможностью распространения ее на носителях, таких, как CD-ROM.
Естественно, сразу встает проблема защиты данных, которые служат для проведения тестирования. Если обучающую информацию можно хранить свободно, то доступ к информации, предназначенной для проведения тестирования, должен быть закрыт для студента. Еще один вопрос состоит в том, как организовать сбор информации о проведенном тестировании – проблема достоверности полученных результатов. Предположим, что студент приносит результат (отчет, сгенерированный программой) своего тестирования на дискете в виде файла. Следовательно, он не должен иметь возможность его модифицировать. Да и как быть уверенным, что он не воспользовался системой, специально измененной для фальсификации результатов тестирования.
Сформулируем основные проблемы, связанных с защитой, и ряд других вопросов, относящихся к системам дистанционного обучения.
1. Отсутствие возможности достоверно определить, прошел ли студент тестирование самостоятельно. Для этой задачи он вполне мог использовать другого человека (например, более подготовленного студента).
2. Неизвестно, сколько раз студент предпринял попытку пройти тестирование. Студент имеет возможность устанавливать систему дистанционного обучения в нескольких экземплярах и/или копировать ее, тем самым сохраняя ее текущее состояние. Так студент получает возможность неограниченного количества попыток прохождения тестирования и возможность выбрать из них попытку с наилучшим результатом.
3. Существует возможность создания универсального редактора файлов результатов тестирования. Он может использоваться студентом для корректировки оценок выставленных программой тестирования.
4. Существует угроза создания универсальной программы просмотра файлов с заданиями и ответами. Тем самым, студент имеет возможность узнать верные ответы на вопросы в тестах.
5. Возможность модификации программного кода системы тестирования, с целью изменения алгоритма выставления оценок.
6. Необходима легкая адаптация уже существующих систем дистанционного обучения и тестирования. Это в первую очередь связанно с тем, что к этим системам уже существуют базы с лекциями, тестовыми заданиями и так далее.
1.2. Обзор публикаций по данной проблеме
В предыдущем разделе были сформулированы ряд основных проблем систем дистанционного обучения и контроля, с точки зрения защиты. Эти или подобные проблемы возникают у всех, кто занимается созданием систем дистанционного обучением. Вопрос дистанционного обучения сейчас становится все более популярным. И практически все ВУЗы заняты созданием своих систем дистанционного обучения. В интернете имеется огромное количество информации по этим разработкам. Интересно, что, говоря о преимуществах той или иной системы, обычно как-то умалчивается о том, каким образом система защищена. Конечно, некоторые системы при проведении тестирования подразумевают видеоконференцию. Но это весьма дорогой метод и, естественно, он вряд ли в скором времени получит распространение.
В качестве подхода к решению некоторых проблем, можно привести пример системы, описанной в еженедельнике "Закон. Финансы. Налоги." в статье "Компьютер-экзаменатор" [13]:
"Ученые СГУ разработали новую тест-систему. Для контроля знаний студентов в Современном гуманитарном университете применяется оригинальная система тестирования, использующая печатные материалы.
Для повышения качества учебного процесса внедрена система с применением персонального компьютера преподавателя и индивидуальных электронных приборов тестирования. При ее использовании полностью исключается рутинная ручная проверка и проставление оценок методистом.
Система обеспечивает индивидуальное (а не групповое) тестирование в любое удобное студенту время и по любому предмету. У студентов нет возможность доступа к печатным ключам тестов и изменения оценки за тест. Кроме того, абсолютно исключается несанкционированное копирование и последующее использование ПО, обслуживающего систему тестирования.
В состав системы входят личные идентификаторы студентов и преподавателей, ПК, прибор тестирования и устройство ввода-вывода информации.
В качестве личных идентификаторов используются бесконтактные пластиковые электронные карты, вырабатывающие уникальный код. Прибор тестирования, который раздается каждому студенту, обеспечивает контроль времени, а также прием и передачу данных от компьютера и обратно по оптическому каналу. Устройство ввода-вывода информации в прибор тестирования, подключаемое к ПК, преобразует данные, поступающие от компьютера, в оптические сигналы, передаваемые в прибор тестирования. Одно устройство ввода-вывода информации может поддерживать работу любого числа приборов тестирования.
Работа электронной системы происходит по следующему сценарию. Системе предъявляется личный идентификатор (пластиковая карточка с кодом) методиста, который будет проводить тестирование. Далее системе предъявляется ЛИ студента. Система производит поиск в базе данных и вывод на экран монитора данные о студенте (ФИО, номер контракта и номер группы). Методист выбирает тест, на который будет отвечать студент. Данные можно ввести как с клавиатуры, так и проведя сканером по штрих-коду, нанесенному на каждый вариант теста. Студенту выдаются прибор тестирования и лист с вопросами. Время, выделенное для ответа на тест, контролируется в приборе тестирования и в компьютере. Студент, нажав клавишу на приборе тестирования, видит оставшееся у него время. За 5 мин. до конца тестирования прибор предупреждает студента звуковым и текстовым сообщениями. По окончании тестирования студент возвращает прибор методисту. Производится активация устройства ввода-вывода и прием собранных данных из прибора в компьютер.
Далее система сравнивает ответы студента с эталонными и выставляет оценку, которую затем заносит в итоговую зачетную ведомость. Каждую оценку система подписывает своей электронной подписью. Электронная подпись в последующем автоматически проверяется, и любое несанкционированное изменение данных в зачетной ведомости будет исключено.
Аналогов такой системы в настоящее время не существует. СГУ готов всем заинтересовавшимся данной уникальной системой оказать всестороннее содействие и консультации."
Применить подобные методы на практике затруднительно. Причина очевидна – это слишком высокая цена построения системы с использованием таких аппаратных средств, да и это не совсем то решения проблем дистанционного тестирования.
Решение многих из перечисленных проблем может лежать в построении системы по принципу клиент/сервер, с использованием сетей Intranet/Internet. Но это противоречит возможности использования таких программ в локальном режиме. А также это противоречит пункту, касающемуся адаптации уже существующих систем. А следовательно построение подобной модели рассматриваться не будет.
В некоторых докладах вполне честно отмечается, что существует масса нерешенных проблем. Примером может являться тезисы доклада О.С. Белокрылова в "Использование курса дистанционного обучения на экономическом факультете РГУ" [14]. В них отмечено, что проведенная работа дает различные положительные результаты применения интернет-технологии. Но далее отмечается, что новационный характер продукта обусловливает наличие некоторых недоработок и негативных сторон программы. Одной из них является: "слабая защита (студенты могут использовать чужой пароль и выполнять задание под чужим именем);".
О том же говорит С. В. Алешин, рассматривая принципы построения оболочки информационно-образовательной среды «Chopin», имеющей структуру, показанную на рисунке 1 [15].
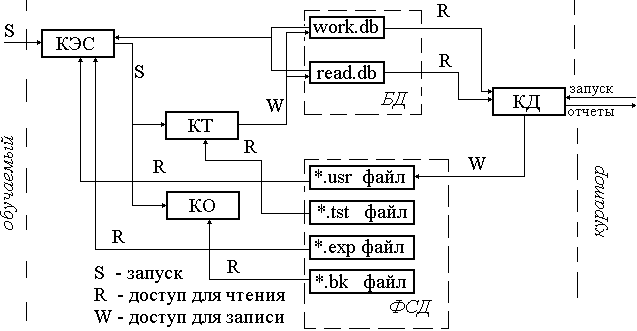
Рисунок 1. Структура оболочки «Chopin»
Он отмечает:
"Готовые тесты хранятся в файловой системе данных (ФСД) в виде текстовых файлов Windows с расширением “tst”. Подобный формат очень удобен при практической эксплуатации системы. Система является прозрачной, логика ее работы может быть проконтролирована до самого нижнего уровня. Вместе с тем, подобная открытость создает ряд проблем в обеспечении ее безопасности. Система информационной безопасность основана на разграничении прав пользователей."
В статье "Проблема обратной связи при дистанционном обучении." А.Г. Оганесян отмечает, что система дистанционного образования должна иметь достаточные средства защиты от несанкционированного вмешательства и подмены реальных студентов их дублерами [16]. Далее говорится, что проблема идентификации студентов, кажется, вообще не имеет решения. Действительно, как уже отмечалось, пароли и иные атрибуты личной идентификации проблемы не решают, т.к. студент заинтересован заменить себя дублером и располагает неограниченными возможностями такой подмены. Техническое решение для ее обнаружения придумать пока не удалось. А вот организационные, похоже, есть. Выход может быть в создании постепенного контроля знаний с целью формирования трудностей для подмены проходящего тестирование дублером. Найти дублера на один экзамен намного проще, чем на весь период обучения.
В некоторых работах отмечается, что примененные системы защиты может иметь негативные стороны. В тезисах докладов Занимонец Ю.М. отмечает: "иногда чрезмерные меры защиты создавали проблемы при инсталляции и эксплуатации программного обеспечения" [17]. Следовательно, немаловажным моментом является хорошая продуманность системы защиты. В противном случае она может скорее навредить, чем принести пользу. Из этого вновь можно сделать выводы, что вопросы защиты (в области дистанционного образования) плохо проработаны.
Некоторые
ученые рассматривают
защиту в очень
ограниченном
аспекте. Н.Н.
Сенцов и В.С.
Солдаткин,
описывая программный
комплекс
тестового
контроля знаний
«Тест», говорят
о следующем
[18]:
"Каждая часть программного комплекса функционирует самостоятельно. В клиентской части нет возможности доступа к базе данных для ее изменения – это возможно из администраторской части при знании пароля доступа к базе данных. Для работы клиентской части необходима заполненная база данных тестовыми заданиями. Это должно быть заведомо сделано из части администратора."
Таким образом, существует защита от модификации, но нет защиты от просмотра. Так же, вполне очевидно, отсутствует и защита отчетов о результатах тестирования
В некоторых статьях эта проблема не рассматривается. Весьма интересная система, описанная в статье "Автоматизированная система разработки электронных учебников." А.А. Мицель, очевидно вообще не защищена [19]. Все это говорит о том, что эти проблемы весьма важные, но в этой области мало наработок.
Аналогично, Д.А. Жолобов, говоря о создании генератора мультимедийных учебников, отмечает, что программа должна обладать возможностью защиты данных учебника от несанкционированного доступа [20]. Но ничего не говорится о том, как реализована защита в этой системе.
Р.И.Вергазов и П.А.Гудков, описывая систему автоматизированного дистанционного тестирования, отмечают, что в сетевом варианте можно построить весьма надежную систему [21]. Существует вариант для работы системы и в локальном режиме. Но не упоминается, существуют ли защита при использовании этой системы в данном режиме.
Теперь обратимся к списку проблем, приведенному в предыдущем разделе. Проведем обзор исследований по данным вопросам в различных работах.
1. Отсутствие возможности определить, прошел ли студент тестирование самостоятельно. Для этой задачи он вполне мог использовать другого человека (например, более подготовленного студента).
Это, пожалуй, самая сложная задача. Невозможно помешать студенту пойти к другу и попросить выполнить определенную лабораторную работу, пройти тестирование. Без применения специальной аппаратуры это практически нереально. Но, естественно, применение аппаратных средств невозможно в силу хотя бы своей цены. Следовательно, такой вариант рассматриваться не будет. По крайней мере он не реален да данном этапе состояния образования в нашей стране.
Проблема того, что студент может пойти к товарищу, а не выполнять лабораторную работу дома, практически является проблемой установки нескольких копий комплекса "виртуальная лаборатория". А следовательно, эта проблема будет обсуждена в пункте № 2.
Вот что пишет П.С. Ложников по вопросу распознавание пользователей в системах дистанционного образования [22]:
"Сегодня остро стоит вопрос о качестве знаний, полученных с использованием технологии дистанционного образования. При очной форме обучения большинство преподавателей ведут учет посещаемости студентов. С переходом на дистанционное образование (ДО) аудитория обучаемых увеличилась в несколько раз, и учитывать посещаемость студентов проблематично. ДО предъявляет определенные требования к психологическим особенностям обучаемого. Во-первых, у него должна быть высокая устойчивая мотивация к получению образования. Во-вторых, студент достаточно четко должен представлять желаемый результат обучения. И, в-третьих, он должен понимать, что несет ответственность за знания, полученные с помощью СДО. Говорить о том, что сегодня идут на дистанционную форму обучения люди с такими психологическими данными нельзя. Большинство людей в России учится за сам факт получения диплома. И у многих утверждение о том, что ДО обеспечивает человеку свободный график обучения, ассоциируется со свободным посещением сервера СДО. В связи с этим, существует вероятность того, что при тестировании студент может посадить за компьютер вместо себя более осведомленного в предмете человека. Навигационная система ДО должна проверять, находится ли за удаленным компьютером именно тот обучаемый, за которого он себя выдает, то есть, произвести распознавание пользователя.
Каким образом сегодня решается эта проблема? Каждый поступающий на обучение в СДО человек получает свое входное имя и пароль для входа на сервер с учебными материалами. При обращении обучаемого к серверу о нем можно собирать информацию, полезную для преподавателя:
перечень страниц, посещенных пользователем за сеанс работы;
время, проведенное на каждой странице;
активированные гиперссылки на данной странице;
перечень файлов, которые были скопированы пользователем с учебного сервера;
время тестирования;
и др.
При необходимости администратор сервера СДО может с помощью собираемой информации восстановить любой сценарий сеанса работы какого-либо обучаемого.
Но вся собранная таким образом информация является косвенной. То есть, если в систему вошел человек по входному имени и паролю своего коллеги с целью отметиться и принять участие в тестировании, то его невозможно разоблачить. Другими словами, нужны прямые доказательства того, что данный сеанс обучения провел действительно тот пользователь, с чьим именем сопоставлены входное имя и пароль."
Далее в статье идет речь о распознавании пользователей с применением дополнительного аппаратного обеспечения. Предлагается использовать такие биометрические характеристики человека, как отпечаток пальца, геометрия руки, радужная оболочка глаза, сетчатка глаза, голос, геометрия лица, что для нас не представляет интереса.
Более интересным является направление, обозначенное в статье как распознавание пользователей с использованием дополнительного программного обеспечения. Развитие исследования данного вопроса мы можем найти в пособии "Как защитить информацию" (глава "Идентификация пользователя: СВОЙ - ЧУЖОЙ?") [23]. Вот основные идеи, излагаемые в этом руководстве:
"Почерк уникален, это знают все. Но немногие догадываются, что в общении с компьютером индивидуальность пользователя проявляется также: скорость, привычка использовать основную или дополнительную часть клавиатуры, характер «сдвоенных» и «строенных» нажатий клавиш, излюбленные приемы управления компьютером..., с помощью которых можно выделить конкретного человека среди всех работавших на данной машине. И ничего удивительного, - это сродни способности меломанов различать на слух пианистов, исполняющих одно произведение. Как же выявить индивидуальные особенности клавиатурного почерка? Также, как и при графологической экспертизе: нужны эталонный и исследуемый образцы текста. Лучше, если их содержание будет одинаковым (так называемая, парольная или ключевая фраза). Разумеется, по двум-трем, даже по десяти нажатым клавишам отличить пользователя невозможно, нужна статистика.
При наборе ключевой фразы компьютер позволяет зафиксировать много различных параметров, но для идентификации наиболее удобно использовать время, затраченное на ввод отдельных букв. А повторив ввод фразы несколько раз, в результате будем иметь множество временных интервалов для каждого символа. На базе полученных значений всегда можно рассчитать среднее время ввода каждого символа, допустимое отклонение от среднего, и хранить эти результате в качестве эталонов для каждого пользователя.
Уникальные особенности клавиатурного почерка выявляются двумя методами: по набору ключевой фразы или по «свободному» тексту. Каждый обязательно имеет режимы настройки и идентификации. При настройке определяются и запоминаются эталонные характеристики ввода пользователем ключевых фраз, например, время, затраченное на отдельные буквы. А в режиме идентификации, после исключения грубых ошибок, эталонное и полученное множества сопоставляются (проверяется гипотеза о равенстве их центров распределения)."
Далее в руководстве излагаются соответствующие алгоритмы для настройки и организации идентификации системы, использующей анализ клавиатурного подчерка, движений мышки. Применительно к системам дистанционного обучения, использование подобного метода могло бы дать возможность выявления ситуации, когда за компьютер сядет другой человек. Хотя приведенные в статье методы интересны, но они достаточно ненадежны, а исследование в этом направлении потребует отдельной работы. Для обучения системы необходимо определенное время. В случае студента этого времени практически нет, да и при своей работе ему придется вводить совсем немного текстовых данных. Движения мышки в такой системе анализировать будет сложно.
2. Неизвестно, сколько раз студент предпринял попытку пройти тестирование. Студент имеет возможность устанавливать систему дистанционного обучения в нескольких экземплярах и/или копировать ее, тем самым сохраняя ее текущее состояние. Студент получает возможность неограниченного количества попыток прохождения тестирования и выбора из них попытки с наилучшим результатом.
Применение различных ухищрений при хранении информации о проделанной студентом работе. Решить эту проблему не просто. В любом случае невозможно узнать, что студент установил пакет программ дистанционного обучения на двух компьютерах, а затем использует один для тренировки и подбора правильных ответов, а второй уже для тестирования. При чем он может поступить проще и воспользоваться программой для создания множества виртуальных машин на одной физической. Такой программой, например, является WMware [24]. Или может создать одну виртуальную машину и установить на ней программу, производящую тестирования. А затем, если результат прохождения тестирования его не будет устраивать, он сможет восстановить предыдущее состояние всей виртуальной системы, просто сделав откат. Это, например, позволяет произвести уже упомянутая ранее программа WMware. Т.е., фактически, используя такую программу, студент имеет возможность создавать "моментальный слепок" всего компьютера. Что позволяет ему необходимо вернуться к предыдущему состоянию.
Одним из методом решения данной проблемы может стать использование индивидуальной дискеты студента. Идея здесь та же, что и использовалась при защите программного обеспечения от несанкционированного копирования. Сейчас для этих целей все чаше используется технология электронных ключей (Hasp и т.д.). Смысл в том, что дискета форматируется, а затем используется особым образом. Т.е. работать с такой дискетой может только специальный набор программ. Стандартными методами такую дискету нельзя ни скопировать, ни просмотреть информацию на ней, так как она хранится в особом формате. Работать с такой дискетой могут только программы, входящие в состав системы дистанционного обучения. Без ключевой дискеты система работать не будет. На этой дискете можно отмечать количество попыток тестирование и т.д., тем самым решая рассматриваемую проблему.
Но эта технология не является решением проблемы. Посмотрим, что, например, говорится в электронном пособии по борьбе с хакерами о некоторых таких системах [23]:
"Система JAWS.
Ключевая информация в системе располагается на дорожке 0 инженерного цилиндра с номером 42. Автор системы защиты от копирования JAWS утверждает, что созданные дискеты не копируются программой COPYWRIT. Это утверждение не соответствует действительности. Дискета копируется программой COPYWRIT, если указать максимальный номер копируемого цилиндра, равным 42.
Система НОТА.
Авторы этой системы также решили расположить информацию о защите в области инженерных цилиндров. В отличие от системы JAWS они решили использовать дорожку 0 цилиндра 41. Однако программа COPYWRIT также успешно копируют эту дискету.
Система SHIELD
Авторы системы SHIELD не пошли проторенным путем использования инженерного цилиндра и нарушения CHRN. Они использовали свободное пространство на дорожке 0 цилиндров 0, 1 и 2 для размещения ключевой информации. Дискета не копируется напрямую программой COPYWRIT. Однако после копирования программой COPYWRIT достаточно обработать данные программой DISK EXPLORER и Вы имеете работоспособную копию.
Система BOARD.
На дискете применяется метод форматирования с длиной 1. Также применяется метод увеличения длины последнего сектора, для запутывания программ COPYIIPC и COPYWRIT. Применяемый формат имеет следующие характеристики. Формат одинаков для цилиндров 0 и 41. Выполняется форматирование на 11 секторов с N=1, GAP=255 и символом заполнителем формата “X”. Первые 9 секторов имеют стандартные R от 1 до 9 и N=2. Предпоследний CHRN имеет R=11 и N=6. У последнего сектора поля CHRN соответственно равны 123, 17, 249 и 7. Полученный формат при работе с секторами от 1 до 9 имеет “отрицательный” GAP3, так как форматирование выполняется с кодом длины 1, а операции с секторами выполняются с кодом длины 2. При этом CRC сектора залезает на SYNC адресного маркера идентификатора следующего сектора. В первом секторе цилиндра 41 записывается ключевая информация, а сектора 2, 3, ... , 9 заполняются символами F6h, что должно маскировать их под обычный формат. Вместе с тем, авторы проверяют из всего объема ключевой информации только информацию из первого сектора на цилиндре 41. Поэтому при копировании достаточно завести обычный сектор с номером 1 на 41 цилиндре и переписать туда ключевую информацию. Авторы не использовали дополнительных возможностей контроля ключевой информации. Анализ данных при чтении предпоследнего сектора на ключевых дорожках позволяет контролировать размер GAP3 и символ заполнитель, использованные при форматировании, а также CHRN последнего сектора на дорожке и длину дорожки. "
Описание многих других систем здесь опушено, так как в целом они схожи с уже описанными. Как видно, использование данного подхода не решает проблему. Достаточно легко воспользоваться специализированными программами копирования или создать свой аналог. Отсюда можно сделать вывод, что разработка системы с использованием ключевой дискеты не рациональна. Подобный подход также повлечет массу сложностей. Например, не ясно, что делать в случае утери или порчи дискеты. Но, по всей видимости, в этом случае студенту придется проходить тестирование еще один раз, что явно неприемлемо.
Можно сделать вывод, что без использования специальных аппаратных средств, данная проблема также не имеет достаточно удовлетворительного решения. Но к ее решению можно постараться приблизиться, используя специфические методы хранения состояния (например в реестре и т.п.) и тем самым усложняя процесс махинации. Но в общем случае это опять не даст результата, если студент воспользуется виртуальной машиной, созданной, например, программой WMware.
3. Существует возможность создания универсального редактора файлов результатов тестирования. Он может использоваться студентом для корректировки оценок выставленных программой тестирования.
Здесь можно было воспользоваться идеей ключевой дискеты для сохранения результата. Тем самым модификация результата стала бы весьма затруднительной. Но этот метод имеет одно ограничение, которое делает его практически непригодным. Это необходимость использования для передачи результата дискеты. Т.е. вместо того, чтобы просто отослать результат по сети, придется доставлять его на дискете.
Но есть другой метод. Это использование шифрования с открытым ключом. Для краткого ознакомления с шифрованием с использования открытого ключа обратиться к книге Баpичева Сеpгея "Kpиптогpафия без секретов" [25]:
"Как бы ни были сложны и надежны криптографические системы - их слабое место при практической реализации - проблема распределения ключей. Для того, чтобы был возможен обмен конфиденциальной информацией между двумя субъектами ИС, ключ должен быть сгенерирован одним из них, а затем каким-то образом опять же в конфиденциальном порядке передан другому. Т.е. в общем случае для передачи ключа опять же требуется использование какой-то криптосистемы.
Для решения этой проблемы на основе результатов, полученных классической и современной алгеброй, были предложены системы с открытым ключом.
Суть их состоит в том, что каждым адресатом ИС генерируются два ключа, связанные между собой по определенному правилу. Один ключ объявляется открытым, а другой закрытым. открытый ключ публикуется и доступен любому, кто желает послать сообщение адресату. секретный ключ сохраняется в тайне.
Исходный текст шифруется открытым ключом адресата и передается ему. зашифрованный текст в принципе не может быть расшифрован тем же открытым ключом. Дешифpование сообщение возможно только с использованием закрытого ключа, который известен только самому адресату.
криптографические системы с открытым ключом используют так называемые необратимые или односторонние функции, которые обладают следующим свойством: при заданном значении x относительно просто вычислить значение f(x), однако если y=f(x), то нет простого пути для вычисления значения x.
Множество классов необратимых функций и порождает все разнообразие систем с открытым ключом. Но не всякая необратимая функция годится для использования в реальных ИС.
В самом определении необратимости присутствует неопределенность. Под необратимостью понимается не теоретическая необратимость, а практическая невозможность вычислить обратное значение, используя современные вычислительные средства за обозримый интервал времени.
Поэтому чтобы гарантировать надежную защиту информации, к системам с открытым ключом (СОК) предъявляются два важных и очевидных требования:
преобразование исходного текста должно быть необратимым и исключать его восстановление на основе открытого ключа.
определение закрытого ключа на основе открытого также должно быть невозможным на современном технологическом уровне. при этом желательна точная нижняя оценка сложности (количества операций) раскрытия шифра.
Алгоритмы шифрования с открытым ключом получили широкое распространение в современных информационных системах. Так, алгоритм RSA стал мировым стандартом де-факто для открытых систем.
Вообще, все предлагаемые сегодня криптосистемы с открытым ключом опираются на один из следующих типов необратимых преобразований:
Разложение больших чисел на простые множители.
Вычисление логарифма в конечном поле.
Вычисление корней алгебраических уравнений.
Здесь же следует отметить, что алгоритмы криптосистемы с открытым ключом (СОК) можно использовать в трех назначениях.
Как самостоятельные средства защиты передаваемых и хранимых данных.
Как средства для распределения ключей. алгоритмы СОК более трудоемки, чем традиционные криптосистемы. Поэтому часто на практике рационально с помощью СОК распределять ключи, объем которых как информации незначителен. А потом с помощью обычных алгоритмов осуществлять обмен большими информационными потоками.
Средства аутентификации пользователей."
4. Существует возможность создания универсальной программы просмотра файлов с заданиями и ответами. Таким образом, студент имеет возможность узнать верные ответы на вопросы в тестах.
Подобной проблемы касается Б.Н. Маутов в статье "Защита электронных учебников на основе программно-аппаратного комплекса "Символ-КОМ" [26]. Но ее существенным недостатком является наличие аппаратной части. Что весьма ограничивает возможность использования системы.
Естественным выходом из данной ситуации является применение шифрования данных. Но принципиально данную проблему разрешить невозможно. Студенту необходимо задать вопрос и сверить с ответом, а для этого необходимо расшифровать данные с эталонными ответами. Для их расшифровки необходим ключ, который в любом случае надо где-то хранить. Следовательно, при желании, информацию можно получить в открытом виде.
Побочной проблемой является возможность внесения заинтересованным лицом несанкционированного изменения баз данных обучающих систем. Данную проблему затрагивает Тыщенко О.Б., говоря о необходимости применения паролей или системы паролей [27]. Хотя вопрос рассматривается в статье несколько с другого ракурса, он пересекается с обсуждаемой проблемой. Хранение данных в обучающей системе подразумевает возможность их просмотра, а, следовательно, наличие способа доступа к этим данных.
5. Возможность модификации программного кода системы тестирования с целью изменения алгоритма выставления оценок.
Как ни странно, но столь важный вопрос защиты практически не освящен. Почти во всех работах по теме защиты информации в системах дистанционного обучения он не рассматривается. Отчасти это понятно. Для систем построенных с использованием сети Internet, его практически не существует. Так как контролирующая часть находится на стороне сервера, то данная проблема не актуальна. Для систем дистанционного обеспечения, предназначенных для локального режима использования, эта проблема практически сводится к широко известной проблеме защиты ПО от взлома. Очевидно, что это и является причиной того, что данный вопрос не получает раскрытия в различных работах. Но это не делает его менее важным.
Вот что, например, пишет Оганесян А. Г. в статье "Проблема «шпаргалок» или как обеспечить объективность компьютерного тестирования?" [28]:
"Почти каждый студент, впервые сталкивающийся с новой для него системой компьютерного тестирования, старается отыскать лазейки, позволяющие получать завышенные оценки. Поиск идёт широким фронтом и рано или поздно большинство лазеек обнаруживается и становится достоянием всех студентов. Бороться с ней не нужно. Более того, полезно поощрять этот процесс, помогающий отыскивать прорехи в системе компьютерного тестирования. Для этого, правда, в неё приходится встраивать специальные механизмы, позволяющие наблюдать за действиями студентов, поскольку не в их интересах делиться с преподавателем своими находками."
Хотелось бы здесь отметить, что перед тем, как поощрять процесс отыскивания прорех, надо все-таки создать систему защиты достаточно высокого уровня. С точки зрения модификации программного кода, данная статья не предлагает соответствующих методов защиты. Далее, не понятно, каким образом можно встраивать специальные механизмы, позволяющие наблюдать за действиями студентов. Точнее, достаточно сложно создание надежного механизма, за счет которого система дистанционного обучения сообщит о своем взломе соответствующей системе на стороне преподавателя. Таким образом, поставленный вопрос весьма важен и требует тщательной проработки.
6. Необходима возможность легкой адаптации уже существующих систем дистанционного обучения и тестирования. Это в первую очередь связанно с тем, что под эти системы уже существуют базы с лекциями, тестовыми заданиями и так далее.
Немаловажным фактором является то, что существующие на данный момент различные системы автоматизации процесса обучения написаны на разных языках. Это Visual C++, Delphi и Visual Basic и другие языки. Следовательно, для взаимодействия с ними нужно удобный и, главное, поддерживаемый всеми этими языками механизм взаимодействия. Можно использовать такие средства, как именованные каналы, сокеты. Но использование таких механизмов хотя и стандартно в ОС Windows, но их использование совсем не простое. Надо иметь определенные знания по данному вопросу.
В последнее время широкое применение нашла технология COM. Многие АСДО, разработанные с ее использованием или с использованием таких ее разновидностей, как OLE и ActiveX. Для примера приведем слова Романенко В.В., описывающего создание автоматизированной системы разработки электронных учебников [29]:
"В системе будут использованы многие современные технологии программирования, в частности, COM, то есть система будет иметь модульную структуру, связанную интерфейсами COM. Это сделает систему гибкой, легко модифицируемой. По таким принципам создаются все современные офисные приложения."
Можно сделать вывод, что взаимодействие модуля защиты с использованием технологии COM очень гибко и широко используется для построения модульных программ. Это очень важно, так как необходимо именно легкое интегрирование в уже существующие системы.
1.3. Задачи поставленные перед системой защиты
Ранее были перечислены основные проблемы, связанные с организацией защиты в системах дистанционного обучения и контроля знаний. Был проведен обзор публикаций по данным вопросам. Попытаемся теперь отделить те задачи, решение которых лежит вне сферы возможности программных средств и решение которых относятся к административным средствам контроля. Для остальных задач попробуем предложить методы их решения и включить поддержку их решений в функциональность разрабатываемой системы защиты.
К сожалению, первые две проблемы лежат вне сферы возможности программных средств без применения дополнительного аппаратного обеспечения. Напомним их.
1. Отсутствие возможности достоверно определить, прошел ли студент тестирование самостоятельно. Для этой задачи он вполне мог использовать другого человека (например, более подготовленного студента).
Естественным решением данной проблемы может служить только правильное построение курса. Процесс контроля знаний следует строить так, чтобы усложнить процесс подмены дублером. Найти дублера на один тест намного проще, чем на весь период обучения. Таким образом, мы вынуждены исключить этот вопрос из списка задач, решение которых должен предоставить разрабатываемый модуль защиты.
2. Неизвестно, сколько раз студент предпринял попытку пройти тестирование. Студент имеет возможность устанавливать систему дистанционного обучения в нескольких экземплярах и/или копировать ее, тем самым сохраняя ее текущее состояние. Так студент получает возможность неограниченного количества попыток прохождения тестирования.
Эта задача в чем-то аналогична предыдущей и также, к сожалению, не имеет программного решения. Решением этой проблемы скорее будет являться правильное построение системы дистанционного обучения. Например, при тестировании целесообразно предложить достаточно большое количество вопросов, наиболее оптимальным выходом является их автоматическая генерация. Это исключило бы возможность просмотра всех вопросов и пробы разных вариантов ответов. Примером такой системы может служить система генерации задач по физике, составляемых по определенным правилам, используя в качестве значений, предложенных для решения, случайные числа.
3. Существует возможность создания универсального редактора файлов результатов тестирования. Он может использоваться студентом для корректировки оценок выставленных программой тестирования.
Здесь на помощь может прийти применение механизма открытых ключей. Именно такой механизм необходимо будет реализовать в системе защиты. Отметим, что будет использоваться шифрование с использованием открытого ключа не в классическом понимании. Метод будет состоять в генерации полиморфных алгоритмов шифрования/расшифрования. При этом одному алгоритму шифрования будет соответствовать один алгоритм расшифровки. А воссоздание алгоритма шифровки/расшифровки по имеющимся в наличии обратного алгоритма слишком трудоемко. Модуль должен будет обеспечить построении сложного для анализа полиморфного кода, что должно препятствовать построению обратного алгоритма.
4. Существует возможность создания универсальной программы просмотра файлов с заданиями и ответами. Таким образом, студент имеет возможность узнать верные ответы на вопросы в тестах.
Решение данной проблемы представляется мне не в использовании стойких криптоалгоритмов, а в способе хранения данных. Одно дело, если все данные будут храниться в текстовом виде. Потом этот текстовый файл будет просто подвергнут шифрованию. В этом случае, расшифровав эти данные с использованием найденного ключа, злоумышленник получит все, что ему надо. Совсем другое дело, если написать механизм чтения/записи данных, использующий записи различных типов. Допустим, мы сохраняем сначала блок с названием работы, потом, сохраняем идентификатор картинки, затем данные самой картинки, затем данные о правильном ответе, и т.д. И теперь знание ключа расшифровки мало что дает, т.к. для еще надо знать формат сохраняемых данных. А взломщик это может узнать только проведя глубокий анализ внутренней работы ПО. А даже если кто и проведет, и будет знать формат читаемых/сохраняемых данных, он должен будет создать программу, позволяющую работать с ними. В силу того, что хранимые данные могут иметь весьма сложный формат, то это маловероятно. Иначе придется повторить довольно большую часть неизвестного программного кода.
Дополнительную сложность должен внести генератор алгоритмов шифрования/расшифрования. Путем хранения данных в пакетах, отдаваемых студенту, и зашифрованных различными алгоритмами, будет достигаться дополнительная сложность создания универсальной программы просмотра.
5. Возможность модификации программного кода системы тестирования, с целью изменения алгоритма выставления оценок или другого кода.
Как ни странно, подсказать решение могут такие программы, как вирусы. Точнее, полиморфные вирусы. Полиморфной называется программа, каждый штамм (копия) которой отличается от другого. Два экземпляра такой программы могут не совпадать ни одной последовательностью байт, но при этом функционально они являются копиями [30]. Вирусы используют полиморфные генераторы для усложнения их обнаружения. Для нас полиморфный код интересен по другой причине. В него очень сложно внести изменения. Точнее, внести исправление в конкретный экземпляр приложения не представляется большой проблемой, а вот применить этот метод модификации к другому экземпляру невозможно. Отсюда следует высокая сложность написания универсального алгоритма, который бы изменял полиморфную программу так, чтобы она начала функционировать как этого хочет злоумышленник.
В результате возникает идея построения подсистемы по следующему описанию. Система представляет из себя файл, который хранится в зашифрованном виде. Программа-загрузчик расшифровывает его непосредственно в памяти и затем запускает. Каждый файл зашифрован своим методом, а следовательно, и простая модификация невозможна.
Возможно создание программы, взламывающей систему тестирования, базирующуюся на методах динамической модификации памяти программы или на создании и загрузки слепка данных в память. Но создание подобной программы уже само по себе весьма сложно и требует высокой квалификации.
6. Необходима возможность легкой адаптации уже существующих систем дистанционного обучения и тестирования. Это, в первую очередь, связанно с тем, что под эти системы уже существуют базы с лекциями, тестовыми заданиями и так далее.
Эта задача полностью лежит в сфере информационных технологий и имеет достаточно простое решение. В ОС Windows существует механизм, который позволит легко адаптировать уже существующие системы дистанционного обучения и тестирования, причем, созданных на различных языках. Он обладает широкой поддержкой средств разработки и библиотек. Это COM (Component Object Model). COM - модель компонентных объектов Microsoft [31].
В частности, примером простоты работы с COM-модулями может служить Visual Basic. В других средствах разработки программного обеспечения этому механизму уделено много внимания. В Visual C++ существует мощная библиотека ATL (Active Template Library) для разработки COM-модулей и взаимодействия с ними. ATL - библиотека активных шаблонов, которая представляет собой множество шаблонов языка C++, предназначенных для построения эффективных СОМ-компонентов. Но главное преимущество в том, что для того чтобы подключить модуль защиты, кроме самой DLL, понадобится только библиотека типов (TLB файл). Библиотека типов предназначена для предоставления другим приложениям и средам программирования информации о составных объектах, которые в ней содержатся.
1.4. Выбор класса требований к системе защиты
Занимаясь разработкой системы защиты, было бы логичным выбрать класс, к которому она будет принадлежать. Это важно в частности с точки зрения бедующего пользователя такой системы. Он должен иметь представление о ее свойствах, надежности и возможной сфере применения. Основополагающими документами в области информационной безопасности на данный момент являются:
Оранжевая книга (TCSEC)
Радужная серия
Гармонизированные критерии Европейских стран (ITSEC)
Рекомендации X.800
Концепция защиты от НСД Гостехкомиссии при Президенте РФ.
Остановим наше внимание на TCSEC. Оранжевая книга выбрана, как документ ставший своего рода классическим.
TCSEC, называемый чаще всего по цвету обложки "Оранжевой книгой", был впервые опубликован в августе 1983 года. Уже его название заслуживает комментария. Речь идет не о безопасных, а о надежных системах, причем слово "надежный" трактуется так же, как в сочетании "надежный человек" — человек, которому можно доверять. "Оранжевая книга" поясняет понятие безопасной системы, которая "управляет, посредством соответствующих средств, доступом к информации, так что только должным образом авторизованные лица или процессы, действующие от их имени, получают право читать, писать, создавать и удалять информацию".
В "Оранжевой книге" надежная система определяется как "система, использующая достаточные аппаратные и программные средства, чтобы обеспечить одновременную обработку информации разной степени секретности группой пользователей без нарушения прав доступа".
Сразу отметим, что TCSEC для разрабатываемой системы фактически непригоден. Данный документ разработан с точки зрения безопасности уровня военных и других государственных служб. В нашем случае, подход с точки зрения построению столь защищенных систем излишен. Ведь заинтересованным во взломе разрабатываемой системы скорее всего будет являться студент, проходящий обучение на защищенной ею АСДО. Следовательно и построение программно-аппаратной системы является излишним и дорогим занятием. Это подтверждает малую пригодность использования для классификации такие документы, как TCSEC. И как мы увидим далее, разрабатываемая система по классификации TCSEC не предоставляет никакой защиты. То есть система, адаптированная с ее использованием, защищенной являться не будет.
Основные элементы политики безопасности, согласно "Оранжевой книге", включают в себя по крайней мере:
Произвольное управление доступом;.
Безопасность повторного использования объектов;
Метки безопасности;
Принудительное управление доступом.
Произвольное управление доступом — это метод ограничения доступа к объектам, основанный на учете личности субъекта или группы, в которую субъект входит. Произвольность управления состоит в том, что некоторое лицо (обычно владелец объекта) может по своему усмотрению давать другим субъектам или отбирать у них права доступа к объекту.
Безопасность повторного использования объектов — важное на практике дополнение средств управления доступом, предохраняющее от случайного или преднамеренного извлечения секретной информации из "мусора". Безопасность повторного использования должна гарантироваться для областей оперативной памяти (в частности, для буферов с образами экрана, расшифрованными паролями и т.п.), для дисковых блоков и магнитных носителей в целом.
Для реализации принудительного управления доступом с субъектами и объектами ассоциируются метки безопасности. Метка субъекта описывает его благонадежность, метка объекта — степень закрытости содержащейся в нем информации.
Согласно "Оранжевой книге", метки безопасности состоят из двух частей — уровня секретности и списка категорий. Уровни секретности, поддерживаемые системой, образуют упорядоченное множество, которое может выглядеть, например, так:
совершенно секретно;
секретно;
конфиденциально;
несекретно.
Принудительное управление доступом основано на сопоставлении меток безопасности субъекта и объекта. Субъект может читать информацию из объекта, если уровень секретности субъекта не ниже, чем у объекта, а все категории, перечисленные в метке безопасности объекта, присутствуют в метке субъекта. В таком случае говорят, что метка субъекта доминирует над меткой объекта. Смысл сформулированного правила понятен — читать можно только то, что положено. Субъект может записывать информацию в объект, если метка безопасности объекта доминирует над меткой субъекта.
Принудительное управление доступом реализовано во многих вариантах операционных систем и СУБД, отличающихся повышенными мерами безопасности. Независимо от практического использования, принципы принудительного управления являются удобным методологическим базисом для начальной классификации информации и распределения прав доступа.
"Критерии" Министерства обороны США открыли путь к ранжированию информационных систем по степени надежности. В "Оранжевой книге" определяется четыре уровня безопасности (надежности) — D, C, B и A. Уровень D предназначен для систем, признанных неудовлетворительными. По мере перехода от уровня C к A к надежности систем предъявляются все более жесткие требования. Уровни C и B подразделяются на классы (C1, C2, B1, B2, B3) с постепенным возрастанием надежности. Таким образом, всего имеется шесть классов безопасности — C1, C2, B1, B2, B3, A1.
Разрабатываемая система, не позволит обеспечить уровень даже класса С1. По этому мы не будем приводить и рассматривать требования, налагающиеся "Оранжевой книгой" на определенные классы.
1.5. Выводы
Как следует из предыдущего материала, проблема защиты систем локального дистанционного обучения действительно актуальна и требует к себе внимания. При этом, к настоящему моменту наработок в этой области очень не много. Большая часть системы защиты лежит вне сферы возможности программного обеспечения и требует соответствующей административной организации и контроля. Что говорит о необходимости разработки теоретических и практических методик построения локального дистанционного процесса обучения. Этот раздел, пожалуй, можно отнести к педагогическим наукам. Но сама по себе педагогика не способна, без поддержки с технической стороны, построить такую систему дистанционного обучения, которая бы соответствовала всем требованиям, как со стороны качества обучения, так и с точки зрения организации контроля при таком обучении. Таким образом, решение для организации систем дистанционного обучения может дать только симбиоз педагогических и технических наук. А, следовательно, основной задачей информационных технологий является построение необходимой технической базы, для дальнейшего ее использования в организации различных схем дистанционного обучения, в том числе, возможно, еще и не разработанных. Многие шаги в этом направлении уже сделаны. Например, разработано огромное количество систем дистанционного обучении и тестирования. Защита же таких систем, будет являться еще одним большим шагом, так как, если хоть одно из основных требований к системам дистанционного обучения не будет выполнено, то, фактически, это означает и невозможность использование такой системы в целом. Система защиты должна иметь возможность легкого включения в уже существующие АСДО. Язык, на котором написана такая система, не должен, по возможности, иметь значения, то есть система защиты должна быть универсальна. Этой системе необходимо предоставлять набор сервисов, удобный в использовании. Они будут использоваться создателями системы обучения для адаптации их систем к требованиям с точки зрения защиты. Именно такую универсальную и легко интегрируемую систему защиты я и попытаюсь разработать и показать на примерах, где и как она может найти свое применение.
ГЛАВА 2. ПРЕДЛАГАЕМЫЕ МЕТОДЫ СОЗДАНИЯ ИНТЕГРИРУЕМОЙ СИСТЕМЫ ЗАЩИТЫ ИНФОРМАЦИИ
2.1. Выбор объектов для защиты
Рассмотрим структурное построение некоторых систем дистанционного локального тестирования и обучения и постараемся выделить общие слабые места и возможности защиты.
Как уже говорилось ранее, система защиты, разрабатываемая в данной работе, не относится к системам дистанционного обучения, построенных по технологии клиент-сервер. Такие системы уже по определению достаточно хорошо защищены. Все базы данных с материалами для обучения, тестирования и так далее, хранятся на сервере. В нужный момент только часть этих данных попадает на компьютер клиента (см. рисунок 2). В этом случае, например, не требуется защита базы с ответами, поскольку проверка правильности может происходить на серверной стороне. Тем не менее, для такой системы модуль защиты будет также возможно полезен. Так, если на компьютере студента устанавливается некий набор программ, организующий его обучение, то возможно и существование критических мест, где может пригодиться защита исполняемых модулей от модификации кода или другая функциональность модуля защиты.
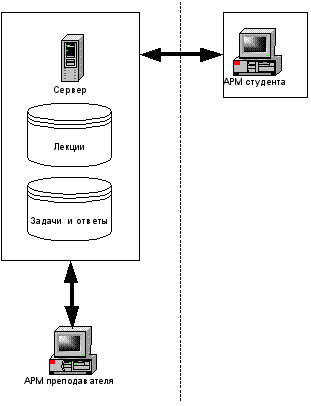
Рисунок 2.
Но разрабатываемая система защиты, как упоминалось ранее, ориентирована на локальный пакет дистанционного обучения. Отсюда следует, что базы с задачами, лекциями и так далее, хранятся непосредственно на компьютере студента (см. рисунок 3).
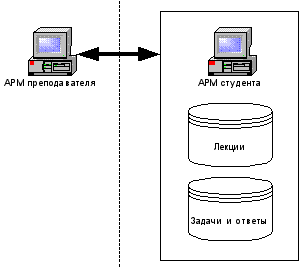
Рисунок 3.
В таком случае уязвимым местом становятся такие объекты, как каналы связи между АРМ преподавателя и студента. Возможен вариант взаимодействия между этими АРМами в режиме off-line. Под уязвимыми объектами понимаются различные файлы (например с результатами промежуточного тестирования), с помощь которых и организуется информационное взаимодействие между АРМ. Уязвимы базы лекций, базы с задачами и ответами. Также само программное обеспечение может быть подвержено модификации. На рисунке 4 изображена структурная схема одной из возможной системы дистанционного обучения.
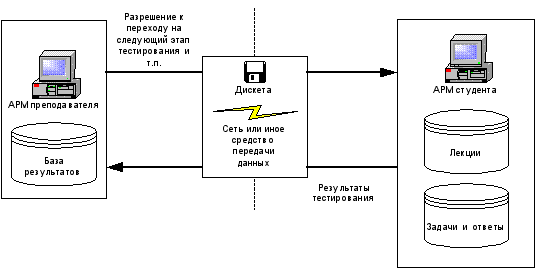
Рисунок 4.
Теперь рассмотрим более подробно объекты системы дистанционного локального обучения, требующие защиты.
Данные, являющиеся текстом задач с ответами, могут быть просмотрены. Это не будет простым делом в случае, если эти данные хранятся в сложном бинарном формате, так как без знания устройства соответствующего формата, просмотр таких данных внешними программами весьма сложен. Многие АСДО хранят эти задачи в простом текстовом виде или в формате WORD документов, и, следовательно, просмотр таких данных никаких сложностей не вызовет. И, соответственно, доступ к базе задач автоматически дискредитируют систему тестирования.
Возможна ситуация, когда нежелательна возможность неограниченного доступа не только к базам заданий/ответов, но и к обучающему материалу. Например, нежелательно широкое распространение обучающих материалов, и требуется ограничить их просмотр только из соответствующей системы тестирования. Естественно, абсолютной защиты тут придумать невозможно, так как в любом случае нельзя, запретить, например, просто сфотографировать монитор. Но, тем не менее, шифрование таких данных иногда оправдано.
Исполняемые файлы систем тестирования подвержены модификации с целью изменения алгоритма их работы. Примером может служить изменение алгоритма выставления оценки за пройденное тестирование или алгоритма генерации отчета с соответствующей оценкой. Дополнительная сложность состоит в том, чтобы усложнить процесс массового взлома. Нет такой программы, которую невозможно сломать. Критерий трудоемкости взлома прямо пропорционален критерию надежности. Таким образом, стоит задача по возможности предотвратить создание программы – взломщика, которую можно будет применить для модификации обучающего пакета любого студента. Следовательно, необходимо не создание очень сложной системы защиты исполняемых модулей. Задача состоит в том, чтобы разработанная кем-то программа–взломщик не имела своего действия на другие пакеты, или, точнее сказать, чтобы создание такой программы было очень трудоемким и экономически нецелесообразным. Представим такую ситуацию. Группе студентов выдали пакет дистанционного обучающего программного обеспечения. Один из студентов вместо честного обучения и тестирования потратил все время на изучение и взлом этой системы, в результате чего получил высокую оценку, так и не ознакомившись с предметом. Такой частный случай сам по себе не страшен. Намного страшнее, если после этого данный студент начнет распространять свое техническое достижение. И, таким образом, может получиться, что все студенты следующего года обучения воспользуются этим. Результатом будет полное не владение курсом студентами, обучение которых происходит на взломанной системе дистанционного обучения. Один из путей защиты – это создание уникальных программных модулей. То есть модулей, для которых неприменима простая программа-взломщик модифицирующая определенную последовательность байт. Предлагаемое решение генерации таких модулей будет описано в дальнейшем и будет основано на применении полиморфных алгоритмов шифрования.
Изменению могут быть подвержены результаты тестирования, то есть отчет, формируемый системой обучения/тестирования. Система дистанционного обучения может быть построена по принципу, когда студент присылает файл с результатами его тестирования по электронной почте или, скажем, приносит на дискете. В этом случае, этот файл не имеет право представлять собой, например, простой текстовый файл. Часто в простых системах тестирования, изначально не разрабатывавшихся для дистанционного обучения, эти файлы для удобства представляются текстовыми документами или другими форматами удобными для просмотра. В общем случае, здесь просто необходимо применение шифрования данных. В реализуемой системе она будет построена на основе асимметричных механизмов шифрования. Это, во-первых, позволит защитить данные от модификации, а, во-вторых, "подпишет" полученные данные. Достаточно каждого студента снабдить пакетом тестирования с уникальным ключом, и будет невозможно воспользоваться чужим файлом с отчетом.
2.2. Шифрование данных
2.2.1. Некоторые общие сведения
Проблема защиты информации путем ее преобразования, исключающего ее прочтение посторонним лицом, волновала человеческий ум с давних времен. История криптографии - ровесница истории человеческого языка. Более того, первоначально письменность сама по себе была криптографической системой, так как в древних обществах ею владели только избранные.
Бурное развитие криптографические системы получили в годы первой и второй мировых войн. Появление вычислительных средств в послевоенные годы ускорило разработку и совершенствование криптографических методов. Вообще история криптографии крайне увлекательна, и достойна отдельного рассмотрения. В качестве хорошей книги по теме криптографии можно рекомендовать "Основы современной криптографии" Баричев С. Г. [32].
Почему проблема использования криптографических методов в информационных системах (ИС) стала в настоящий момент особо актуальна?
С одной стороны, расширилось использование компьютерных сетей, в частности, глобальной сети Интернет, по которым передаются большие объемы информации государственного, военного, коммерческого и частного характера, не допускающего возможность доступа к ней посторонних лиц.
С другой стороны, появление новых мощных компьютеров, технологий сетевых и нейронных вычислений сделало возможным дискредитацию криптографических систем, еще недавно считавшихся практически нераскрываемыми.
Все это постоянно подталкивает исследователей на создание новых криптосистем и тщательный анализ уже существующих.
Проблемой защиты информации путем ее преобразования занимается криптология. Криптология разделяется на два направления – криптографию и криптоанализ. Цели этих направлений прямо противоположны.
Криптография занимается поиском и исследованием методов преобразования информации с целью скрытия ее содержания.
Сфера интересов криптоанализа исследование возможности расшифровывания информации без знания ключей.
Современная криптография разделяет их на четыре крупных класса.
Симметричные криптосистемы.
Криптосистемы с открытым ключом.
Системы электронной цифровой подписи (ЭЦП).
Системы управление ключами.
Основные направления использования криптографических методов – передача конфиденциальной информации по каналам связи (например, электронная почта), установление подлинности передаваемых сообщений, хранение информации (документов, баз данных) на носителях в зашифрованном виде.
Итак, криптография дает возможность преобразовать информацию таким образом, что ее прочтение (восстановление) возможно только при знании ключа.
Приведем определения некоторых основных терминов, используемых в криптографии.
Алфавит конечное множество используемых для кодирования информации знаков.
Текст упорядоченный набор из элементов алфавита.
В качестве примеров алфавитов, используемых в современных ИС можно привести следующие:
алфавит Z33 – 32 буквы русского алфавита (исключая "ё") и пробел;
алфавит Z256 – символы, входящие в стандартные коды ASCII и КОИ-8;
двоичный алфавит Z2 = {0,1};
восьмеричный или шестнадцатеричный алфавит.
Шифрование – процесс преобразования исходного текста, который носит также название открытого текста, в шифрованный текст.
Расшифрование – процесс, обратный шифрованию. На основе ключа шифрованный текст преобразуется в исходный.
Криптографическая система представляет собой семейство T преобразований открытого текста. Члены этого семейства индексируются, или обозначаются символом k; параметр k обычно называется ключом. Преобразование Tk определяется соответствующим алгоритмом и значением ключа k.
Ключ – информация, необходимая для беспрепятственного шифрования и расшифрования текстов.
Пространство ключей K – это набор возможных значений ключа.
Криптосистемы подразделяются на симметричные и асимметричные (или с открытым ключом).
В симметричных криптосистемах для шифрования, и для расшифрования используется один и тот же ключ.
В системах с открытым ключом используются два ключа - открытый и закрытый (секретный), которые математически связаны друг с другом. Информация шифруется с помощью открытого ключа, который доступен всем желающим, а расшифровывается с помощью закрытого ключа, известного только получателю сообщения.
Термины распределение ключей и управление ключами относятся к процессам системы обработки информации, содержанием которых является выработка и распределение ключей между пользователями.
Электронной цифровой подписью называется присоединяемое к тексту его криптографическое преобразование, которое позволяет при получении текста другим пользователем проверить авторство и подлинность сообщения.
Кpиптостойкостью называется характеристика шифра, определяющая его стойкость к расшифрованию без знания ключа (т.е. криптоанализу). Имеется несколько показателей криптостойкости, среди которых:
количество всех возможных ключей;
среднее время, необходимое для успешной криптоаналитической атаки того или иного вида.
Эффективность шифрования с целью защиты информации зависит от сохранения тайны ключа и криптостойкости шифра.
2.2.2. Асимметричные криптосистемы
Теперь остановимся на асимметричные криптосистемам и кратко расскажем о них. Связано это с тем, что в дальнейшем в системе защиты будет предложен и использован механизм построенный по принципу асимметричных криптосистем.
Асимметричные или двухключевые системы являются одним из обширным классом криптографических систем. Эти системы характеризуются тем, что для шифрования и для расшифрования используются разные ключи, связанные между собой некоторой зависимостью. При этом данная зависимость такова, что установить один ключ, зная другой, с вычислительной точки зрения очень трудно.
Один из ключей (например, ключ шифрования) может быть сделан общедоступным, и в этом случае проблема получения общего секретного ключа для связи отпадает. Если сделать общедоступным ключ расшифрования, то на базе полученной системы можно построить систему аутентификации передаваемых сообщений. Поскольку в большинстве случаев один ключ из пары делается общедоступным, такие системы получили также название криптосистем с открытым ключом.
Криптосистема
с открытым
ключом определяется
тремя алгоритмами:
генерации
ключей, шифрования
и расшифрования.
Алгоритм генерации
ключей открыт,
всякий может
подать ему на
вход случайную
строку r
надлежащей
длины и получить
пару ключей
(k1,
k2).
Один из ключей
(например, k1)
публикуется,
он называется
открытым, а
второй, называемый
секретным,
хранится в
тайне. Алгоритмы
шифрования
![]() и расшифрования
и расшифрования
![]() таковы,
что для любого
открытого
текста m
таковы,
что для любого
открытого
текста m
![]() .
.
Рассмотрим
теперь гипотетическую
атаку злоумышленника
на эту систему.
Противнику
известен открытый
ключ k1,
но неизвестен
соответствующий
секретный
ключ k2.
Противник
перехватил
криптограмму
d
и пытается
найти сообщение
m,
где
![]() .
Поскольку
алгоритм шифрования
открыт, противник
может просто
последовательно
перебрать все
возможные
сообщения длины
n,
вычислить для
каждого такого
сообщения
mi
криптограмму
.
Поскольку
алгоритм шифрования
открыт, противник
может просто
последовательно
перебрать все
возможные
сообщения длины
n,
вычислить для
каждого такого
сообщения
mi
криптограмму
![]() и сравнить di
с d.
То сообщение,
для которого
di
= d
и будет искомым
открытым текстом.
Если повезет,
то открытый
текст будет
найден достаточно
быстро. В худшем
же случае перебор
будет выполнен
за время порядка
2nT(n),
где T(n)
– время, требуемое
для шифрования
сообщения длины
п.
Если
сообщения имеют
длину порядка
1000 битов, то такой
перебор неосуществим
на практике
ни на каких
самых мощных
компьютерах.
и сравнить di
с d.
То сообщение,
для которого
di
= d
и будет искомым
открытым текстом.
Если повезет,
то открытый
текст будет
найден достаточно
быстро. В худшем
же случае перебор
будет выполнен
за время порядка
2nT(n),
где T(n)
– время, требуемое
для шифрования
сообщения длины
п.
Если
сообщения имеют
длину порядка
1000 битов, то такой
перебор неосуществим
на практике
ни на каких
самых мощных
компьютерах.
Мы рассмотрели лишь один из возможных способов атаки на криптосистему и простейший алгоритм поиска открытого текста, называемый обычно алгоритмом полного перебора. Используется также и другое название: «метод грубой силы». Другой простейший алгоритм поиска открытого текста – угадывание. Этот очевидный алгоритм требует небольших вычислений, но срабатывает с пренебрежимо малой вероятностью (при больших длинах текстов). На самом деле противник может пытаться атаковать криптосистему различными способами и использовать различные, более изощренные алгоритмы поиска открытого текста.
Для примера кратко расскажем о нескольких классических асимметричных системах шифровани.
2.2.2.1. Криптосистема Эль-Гамаля
Система Эль-Гамаля – это криптосистема с открытым ключом, основанная на проблеме логарифма. Система включает как алгоритм шифрования, так и алгоритм цифровой подписи.
Множество параметров системы включает простое число p и целое число g, степени которого по модулю p порождают большое число элементов Zp. У пользователя A есть секретный ключ a и открытый ключ y, где y = ga (mod p). Предположим, что пользователь B желает послать сообщение m пользователю A. Сначала B выбирает случайное число k, меньшее p. Затем он вычисляет
y1 = gk (mod p) и y2 = m Е (yk (mod p)),
где Е обозначает побитовое "исключающее ИЛИ". B посылает A пару (y1, y2).
После получения шифрованного текста пользователь A вычисляет
m = (y1a mod p) Е y2.
Известен вариант этой схемы, когда операция Е заменяется на умножение по модулю p. Это удобнее в том смысле, что в первом случае текст (или значение хэш-функции) необходимо разбивать на блоки той же длины, что и число yk (mod p). Во втором случае этого не требуется и можно обрабатывать блоки текста заранее заданной фиксированной длины (меньшей, чем длина числа p).
2.2.2.2. Криптосистема Ривеста-Шамира-Эйделмана
Система Ривеста-Шамира-Эйделмана (Rivest, Shamir, Adlеman – RSA) представляет собой криптосистему, стойкость которой основана на сложности решения задачи разложения числа на простые сомножители. Кратко алгоритм можно описать следующим образом:
Пользователь A выбирает пару различных простых чисел pA и qA , вычисляет nA = pAqA и выбирает число dA, такое что НОД(dA, j(nA)) = 1, где j(n) – функция Эйлера (количество чисел, меньших n и взаимно простых с n. Если n = pq, где p и q – простые числа, то j(n) = (p 1)(q 1)). Затем он вычисляет величину eA, такую, что dAЧeA = 1 (mod j(nA)), и размещает в общедоступной справочной таблице пару (eA, nA), являющуюся открытым ключом пользователя A.
Теперь пользователь B, желая передать сообщение пользователю A, представляет исходный текст
x = (x0, x1, ..., xn–1), x О Zn , 0 Ј i < n,
по основанию nA:
N = c0+c1 nA+....
Пользователь
В зашифровывает
текст при передаче
его пользователю
А, применяя к
коэффициентам
сi
отображение
![]() :
:
![]() ,
,
получая
зашифрованное
сообщение N'.
В силу выбора
чисел dA
и eA,
отображение
![]() является
взаимно однозначным,
и обратным к
нему будет
отображение
является
взаимно однозначным,
и обратным к
нему будет
отображение
![]()
Пользователь
А производит
расшифрование
полученного
сообщения N',
применяя
![]() .
.
Для
того чтобы
найти отображение
![]() ,
обратное по
отношению к
,
обратное по
отношению к
![]() ,
требуется
знание множителей
nA
= pAqA.
Время выполнения
наилучших из
известных
алгоритмов
разложения
при n
> 10145
на сегодняшний
день выходит
за пределы
современных
технологических
возможностей.
,
требуется
знание множителей
nA
= pAqA.
Время выполнения
наилучших из
известных
алгоритмов
разложения
при n
> 10145
на сегодняшний
день выходит
за пределы
современных
технологических
возможностей.
2.2.2.3. Криптосистема, основанная на эллиптических кривых
Рассмотренная выше криптосистема Эль-Гамаля основана на том, что проблема логарифмирования в конечном простом поле является сложной с вычислительной точки зрения. Однако, конечные поля являются не единственными алгебраическими структурами, в которых может быть поставлена задача вычисления дискретного логарифма. В 1985 году Коблиц и Миллер независимо друг от друга предложили использовать для построения криптосистем алгебраические структуры, определенные на множестве точек на эллиптических кривых.
2.2.3. Адаптированный метод асимметричного шифрования
Рассмотренные ранее методы построения асимметричных алгоритмов криптопреобразований хоть и интересны, но не достаточно хорошо подходят для решаемой задачи. Можно было бы взять реализацию уже готового асимметричного алгоритма, или согласно теоретическому описанию, реализовать его самостоятельно. Но, во-первых, здесь встает вопрос о лицензировании и использовании алгоритмов шифрования. Во-вторых, использование стойких криптоалгоритмов связано с правовой базой, касаться которой бы не хотелось. Сам по себе стойкий алгоритм шифрования здесь не нужен. Он просто излишен и создаст лишь дополнительное замедление работы программы при шифровании/расшифровании данных. Также планируется выполнять код шифрования/расшифрования в виртуальной машине, из чего вытекают большие трудности реализации такой системы, если использовать сложные алгоритмы шифрования. Виртуальная машина дает ряд преимуществ, например, делает более труднодоступной возможность проведения некоторых операций. В качестве примера можно привести проверку алгоритмом допустимого срока своего использования.
Отсюда следует вывод, что создаваемый алгоритм шифрования должен быть достаточен прост. Но при этом он должен обеспечивать асимметричность и быть достаточно сложным для анализа. Именно исходя из этих позиций берет свое начало идея создания полиморфных алгоритмов шифрования.
Основная сложность будет состоять в построении генератора, который должен выдавать на выходе два алгоритма. Один – для шифрования, другой – для расшифрования. Ключей у этих алгоритмов шифрования/расшифрования нет. Можно сказать, что они сами являются ключами, или что они содержат ключ внутри. Они должны быть устроены таким образом, чтобы производить уникальные преобразования над данными. То есть два сгенерированных алгоритма шифрования должны производить шифрования абсолютно различными способами. И для их расшифровки возможно будет использовать только соответствующий алгоритм расшифрования, который был сгенерирован в паре с алгоритмом шифрования.
Уникальность создания таких алгоритмов должен обеспечить полиморфный генератор кода. Выполняться такие алгоритмы будут в виртуальной машине. Анализ таких алгоритмов должен стать весьма трудным и нецелесообразным занятием.
Преобразования над данными будут достаточно тривиальны, но практически, вероятность генерации двух одинаковых алгоритмов должна стремиться к нулю. В качестве элементарных действий следует использовать такие нересурсоемкие операции, как сложение с каким-либо числом или, например, побитовое "исключающее или" (XOR). Но повторение нескольких таких преобразований с изменяющимися аргументами операций (в зависимости от адреса шифруемой ячейки) делает шифр достаточно сложным. Генерации каждый раз новой последовательности таких преобразований с участием различных аргументов усложняет анализ алгоритма.
2.3. Преимущества применения полиморфных алгоритмов шифрования
К преимуществам применения полиморфных алгоритмов шифрования для систем, по функциональности схожим с АСДО, можно отнести следующие пункты:
слабая очевидность принципа построения системы защиты;
сложность создания универсальных средств для обхода системы защиты;
легкая реализация системы асимметрического шифрования;
возможность легкой, быстрой адаптации и усложнения такой системы;
возможность расширения виртуальной машины с целью сокрытия части кода.
Рассмотрим теперь каждый их этих пунктов по отдельности и обоснуем эти преимущества. Можно привести и другие удобства, связанные с использование полиморфных механизмов в алгоритмах шифрования. Но, на мой взгляд, перечисленные преимущества являются основными и заслуживающими внимания.
1) Слабая очевидность принципа построения системы защиты, является следствием выбора достаточно своеобразных механизмов. Во-первых, это само выполнение кода шифрования/расшифрования в виртуальной машине. Во-вторых, наборы полиморфных алгоритмов, уникальных для каждого пакета защищаемого программного комплекса. Это должно повлечь серьезные затруднения при попытке анализа работы такой системы с целью поиска слабых мест для атаки. Если система сразу создаст видимость сложности и малой очевидности работы своих внутренних механизмов, то скорее всего это остановит человека от дальнейших исследований. Правильно построенная программа с использованием разрабатываемой системой защиты может не только оказаться сложной на вид, но и быть такой в действительности. Выбранные же методы сделают устройство данной системы нестандартным, и, можно сказать, неожиданным.
2) Сложность создания универсальных средств для обхода системы защиты заключается в возможности генерации уникальных пакетов защищенного ПО. Создание универсального механизма взлома средств защиты затруднено при отсутствии исходного кода. В противном случае необходим глубокий, подробный и профессиональный анализ такой системы, осложняемый тем, что каждая система использует свои алгоритмы шифрования/расшифрования. А модификация отдельного экземпляра защищенного ПО интереса не представляет. Ведь основной упор сделан на защиту от ее массового взлома, а не на высокую надежность отдельного экземпляра пакета.
3) Легкая реализация системы асимметрического шифрования, хоть и является побочным эффектом, но очень полезна и важна. Она представляет собой следствие необходимости генерировать два разных алгоритма, один для шифрования, а другой для расшифрования. На основе асимметрического шифрования можно организовать богатый набор различных механизмов в защищаемом программном комплексе. Примеры такого применения будут даны в других разделах данной работы.
4) Возможность легкой, быстрой адаптации и усложнения такой системы. Поскольку для разработчиков система предоставляется в исходном коде, то у него есть все возможности для его изменения. Это может быть вызвано необходимостью добавления новой функциональности. При этом для такой функциональности может быть реализована поддержка со стороны измененной виртуальной машины. В этом случае работа новых механизмов может стать сложной для анализа со стороны. Также легко внести изменения с целью усложнения генератора полиморфного кода и увеличения блоков, из которых строятся полиморфные алгоритмы. Это, например, может быть полезно в том случае, если кем-то, не смотря на все сложности, будет создан универсальный пакет для взлома системы зашиты. Тогда совсем небольшие изменения в коде, могут свести на нет труды взломщика. Стоит отметить, что это является очень простым действием, и потенциально способствует защите, так как делает процесс создания взлома еще более нерациональным.
5) Поскольку программисту отдаются исходные коды система защиты, то он легко может воспользоваться существующей виртуальной машиной и расширить ее для собственных нужд. То же самое касается и генератора полиморфных алгоритмов. Например, он может встроить в полиморфный код ряд специфической для его системы функций. Сейчас имеется возможность ограничить возможность использования алгоритмов по времени. А где-то, возможно, понадобится ограничение по количеству запусков. Можно расширить только виртуальную машину с целью выполнения в ней критических действий. Например, проверку результатов ответа. Выполнение виртуального кода намного сложнее для анализа, а, следовательно, расширяя механизм виртуальной машины, можно добиться существенного повышения защищенности АСДО.
2.4. Функциональность системы защиты
Ранее были рассмотрены цели, для которых разрабатывается система защиты, а также методы, с использованием которых эта система будет построена. Сформулируем функции системы защиты, которые она должна будет предоставить программисту.
Генератор полиморфных алгоритмов шифрование и расшифрования.
Виртуальная машина в которой могут исполняться полиморфные алгоритмы. Отметим также, что виртуальная машина может быть легко адаптирована, с целью выполнения программ иного назначения.
Асимметричная система шифрования данных.
Ограничение использования полиморфных алгоритмов по времени.
Защита исполняемых файлов от модификации.
Контроль за временем возможности запуска исполняемых файлов.
Поддержка таблиц соответствий между именами зашифрованных файлов и соответствующих им алгоритмам шифрования/расшифрования.
Упаковка шифруемых данных.
ГЛАВА 3. РЕАЛИЗАЦИЯ СИСТЕМЫ ЗАЩИТЫ
3.1. Выбор средств разработки и организации системы
Для разработки системы защиты необходим компилятор, обладающий хорошим быстродействием генерируемого кода. Требование к быстродействию обусловлено ресурсоемкостью алгоритмов шифрования и расшифрования. Также необходима среда с хорошей поддержкой COM. Желательно, чтобы язык был объектно ориентированный, что должно помочь в разработке достаточно сложного полиморфного генератора.
Естественным выбором будет использование Visual C++. Он отвечает всем необходимым требованиям. Также понадобится библиотека для сжатия данных. Наиболее подходящим кандидатом является библиотека ZLIB. Теперь рассмотрим по отдельности каждый из этих компонентов, с целью показать почему был сделан именно такой выбор. В рассмотрение войдут: язык С++, среда Visual C++, библиотека активных шаблонов (ATL), библиотека ZLIB.
3.1.1. Краткая характеристика языка программирования С++
Объектно-ориентированный язык С++ создавался как расширение языка Си. Разработанный Бьярном Страуструпом (Bjarne Stroustroup) из AT&T Bell Labs в начале 80-х, С++ получил широкое распространение среди программистов по четырем важным причинам.
В языке С++ реализовано несколько дополнений к стандартному Си. Наиболее важным из этих дополнений является объектная ориентация, которая позволяет программисту использовать объектно-ориентированную парадигму разработки.
Компиляторы С++ широко доступны, а язык соответствует стандартам ANSI.
Большинство программ на С++ широко доступны, а язык соответствует стандартам ANSI.
Большинство программ на Си без всяких изменений, либо с незначительными изменениями , можно компилировать с помощью компилятора С++. Кроме того, многие программисты, владеющие языком Си, могут сразу начать работать с компилятором С++, постепенно осваивая его новые возможности. При этом не нужно осваивать новый сложный объектно-ориентированный язык с нуля.
Программы на С++ обычно сохраняют эффективность программ на Си. Поскольку разработчики С++ уделяли большое внимание эффективности генерируемого кода, С++ наилучшим образом подходит для задач, где быстродействие кода имеет важное значение.
Хотя большинство экспертов рассматривают С++ как самостоятельный язык, фактически С++ представляет собой развитое объектно-ориентированное расширение Си, или объектно-ориентированный «гибрид». Язык допускает смешанное программирование с использованием концепции программирования Си и объектно-ориентированной концепции, и это можно охарактеризовать как недостаток.
Объектно-ориентированное программирование (ООП) основная методология программирования 90-х годов. Она является результатом тридцатилетнего опыта и практики, которые берут начало в языке Simula 67 и продолжаются в языках Smalltalk, LISP, Clu и в более поздних Actor, Eiffel, Objective C, Java и С++. ООП это стиль программирования, который фиксирует поведение реального мира так, что детали разработки скрыты, а это позволяет тому, кто решает задачу, мыслить в терминах, присущих этой задаче, а не программирования. ООП это программирование, сфокусированное на данных, причем данные и поведение неразрывно связаны. Они вместе составляют класс, а объекты являются экземплярами класса.
С++ относительно молодой и развивающийся язык, только в 1998 году был утвержден стандарт ANSI, и еще не все компиляторы полностью соответствуют этому стандарту. Тем не менее язык очень популярен и распространен не меньше, чем Си.
Выбор был остановлен на языке С++ по следующим причинам. Поскольку будет использоваться среда Visual C++, то нет смысла отказываться от преимуществ языка С++, тем более, что программа достаточно сложная. Например, механизмы исключений могут быть весьма полезны. Еще одним преимуществом является возможность использовать умные указатели на COM интерфейсы, что часто бывает очень удобно. Использование библиотеки ATL тоже подразумевает необходимость языка С++, так как она написана именно на нем.
3.1.2. Краткая характеристика среды Visual C++
В связи с тем, что сегодня уровень сложности программного обеспечения очень высок, разработка приложений Windows с использованием только какого-либо языка программирования (например, языка C) значительно затрудняется. Программист должен затратить массу времени на решение стандартных задач по созданию многооконного интерфейса. Реализация технологии COM потребует от программиста еще более сложной работы.
Чтобы облегчить работу программиста практически все современные компиляторы с языка C++ содержат специальные библиотеки классов. Такие библиотеки включают в себя практически весь программный интерфейс Windows и позволяют пользоваться при программировании средствами более высокого уровня, чем обычные вызовы функций. За счет этого значительно упрощается разработка приложений, имеющих сложный интерфейс пользователя, облегчается поддержка технологии COM и взаимодействие с базами данных.
Современные интегрированные средства разработки приложений Windows позволяют автоматизировать процесс создания приложения. Для этого используются генераторы приложений. Программист отвечает на вопросы генератора приложений и определяет свойства приложения - поддерживает ли оно многооконный режим, технологию COM, трехмерные органы управления, справочную систему. Генератор приложений, создаст приложение, отвечающее требованиям, и предоставит исходные тексты. Пользуясь им как шаблоном, программист сможет быстро разрабатывать свои приложения.
Подобные средства автоматизированного создания приложений включены в компилятор Microsoft Visual C++ и называются MFC AppWizard. Заполнив несколько диалоговых панелей, можно указать характеристики приложения и получить его тексты, снабженные обширными комментариями. MFC AppWizard позволяет создавать однооконные и многооконные приложения, а также приложения, не имеющие главного окна, -вместо него используется диалоговая панель. Можно также включить поддержку технологии COM, баз данных, справочной системы.
Среда Visual C++ 6.0 была выбрана как одно из лучших средств разработки на языке С++ для ОС Microsoft Windows. Немаловажным фактором является ее поддержка такими утилитами, как Visual Assist, BoundsChecker, которые в свою очередь позволяют создавать программы более быстро и качественно. Компилятор Visual C++ генерирует достаточно оптимизированный код, что весьма важно для разрабатываемого приложения.
3.1.3. Краткая характеристика библиотеки ATL
Библиотека активных шаблонов (ATL) представляет собой основу для создания небольших СОМ - компонентов. В ATL использованы новые возможности шаблонов, добавленные в C++. Исходные тексты этой библиотеки поставляются в составе системы разработки Visual C++. Кроме того, в эту систему разработки введено множество мастеров Visual C++, что облегчает начальный этап создания ATL-проектов.
Библиотека ATL обеспечивает реализацию ключевых возможностей СОМ компонентов. Выполнения многих рутинных процедур, с которыми мы столкнулись при разработке последнего примера, можно избежать за счет использования классов шаблонов ATL. Приведем далеко не полный список функций ATL. Некоторые из них будут рассмотрены в этой главе.
Утилита AppWizard, предназначенная для создания первичного ATL-проекта.
Мастер объектов, используемый для добавления в проект компонентов различных типов.
Поддержка по умолчанию основных интерфейсов COM, таких как IUnknown и IClassFactory.
Поддержка механизма транспортировки пользовательского интерфейса.
Поддержка базового механизма диспетчеризации (автоматизации) и двунаправленного интерфейса.
Существенная поддержка разработки небольших элементов управления ActiveX.
Основной задачей ATL является облегчение создания небольших СОМ-компонентов. Задача MFC — ускорение разработки больших Windows-приложений. Функции MFC и ATL несколько перекрываются, в первую очередь в области поддержки OLE и ActiveX.
Поскольку разрабатываемый модуль защиты не велик и не требует какой либо работы с графическим интерфейсом, то вполне естественно выбрать его, а не более тяжелый и излишний по функциональности MFC.
3.1.4. Краткая характеристика библиотеки ZLIB
Библиотека ZLIB представляет собой небольшую и удобную библиотеку на языке С. Ее назначение – упаковка и распаковка данных. Поскольку она распространяется в исходных кодах, то ее будет легко и удобно использовать в разрабатываемом модуле. Также отметим, что эта библиотека является свободно распространяемой, что не влечет за собой нарушения авторских прав.
3.2. Полиморфный генератор алгоритмов шифрования
Рассмотрим построение генератора полиморфных алгоритмов шифрования и расшифрования. Эти алгоритмы всегда генерируются парами, механизм их генерации весьма схож и осуществляется одним кодом. Разница только в том, что используются блоки, производящие обратные преобразования. Вначале рассмотрим, как вообще выглядят общий алгоритм шифрования/расшифрования. Затем покажем, как выглядит готовый код алгоритма шифрования/расшифрования, и расскажем о виртуальной машине, в которой он выполняется. Также будет приведет отладочный вывод виртуальный машины, демонстрирующий работу алгоритмов шифрования/расшифрования. Затем будет рассмотрен непосредственно сам алгоритм построения полиморфного кода, и подсчитана вероятность генерации одинаковых алгоритмов и пути повышения сложности полиморфных алгоритмов.
3.2.1. Общие принципы работы полиморфных алгоритмов шифрования и расшифрования
Представим генерируемые алгоритмы шифрования/расшифрования в общем виде. Они состоят из 8 функциональных блоков, некоторые из которых могут повторяться. На рисунке 5 приведена абстрактная схема работы алгоритма шифрования/расшифрования. Повторяющиеся блоки обозначены эллипсами, находящимися под квадратами. Количество таких блоков выбирается случайно при генерации каждой новой пары алгоритмов. Функциональные блоки и их номер отмечены числом в маленьком прямоугольнике, расположенным в правом верхнем углу больших блоков.
Сразу отметим, что при своей работе виртуальная машина использует виртуальные регистры и память. Начальное содержимое виртуальной памяти, как и сам сгенерированный алгоритм, хранится в файле. Например, именно в виртуальной памяти может быть записано, сколько байт необходимо расшифровать. Некоторые виртуальные регистры и виртуальные ячейки памяти содержат мусор и не используются или используются в холостых блоках. Холостые блоки состоят из одной или более базовых инструкций виртуальной машины. Они не являются функциональными блоками, и их описание будет опушено. Холостым блокам будет уделено внимание в следующем разделе. На схеме произвольные регистры/ячейки памяти обозначаются как буква А с цифрой. Полиморфный генератор случайным образом выбирает, какой же именно регистр или ячейка памяти будет задействована в каждом конкретном алгоритме шифрования/расшифрования. Рассмотрим теперь каждый из функциональных блоков более подробно.
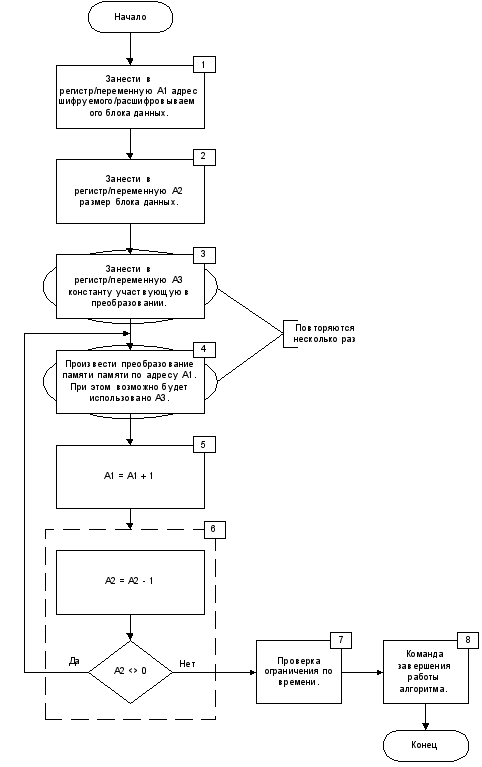
Рисунок 5. Алгоритм шифрования/расшифрования в общем виде.
Блок 1 заносит в виртуальный регистр или переменную (обозначим ее как A1) адрес шифруемого/расшифруемого блока данных. Для виртуальной машины этот адрес на самом деле всегда является нулем. Дело в том, что когда происходит выполнение виртуальной инструкции модификации данных, то виртуальная машина добавляет к этому адресу настоящий адрес в памяти и уже с ним производит операции. Можно представить A1 как индекс в массиве шифруемых/расшифруемых данных, адресуемых с нуля.
Блок 2 заносит в виртуальный регистр или переменную (обозначим ее как A2) размер блока данных. А2 выполняет роль счетчика в цикле преобразования данных. Заметим, что ее значение всегда в 4 раза меньше, чем настоящий размер шифруемых/расшифруемых данных. Это связано с тем, что полиморфные алгоритмы всегда работают с блоками данных, кратных по размеру 4 байтам. Причем, операции преобразования выполняются над блоками, кратными 4 байтам. О выравнивании данных по 4 байта заботятся более высокоуровневые механизмы, использующие виртуальную машину и полиморфные алгоритмы для шифрования и расшифрования данных. Возникает вопрос, откуда алгоритму "знать", какого размера блок ему необходимо зашифровать, ведь при его генерации такой информации просто нет. Необходимое значение он просто берет из ячейки памяти. Виртуальная машина памяти знает именно об этой ячейке памяти и перед началом выполнения полиморфного алгоритма заносит туда необходимое значение.
Блок 3 помещает в виртуальный регистр или переменную (обозначим ее как A3) константу, участвующую в преобразовании. Эта константа, возможно, затем и не будет использована для преобразования данных, все зависит от того, какой код будет сгенерирован. Блок 3 может быть повторен несколько раз. Над данными осуществляется целый набор различных преобразований, и в каждом из них участвуют различные регистры/переменные, инициализированные в блоке 3.
Блок 4 можно назвать основным. Именно он, а, точнее сказать, набор этих блоков производит шифрование/расшифрование данных. Количество этих блоков случайно и равно количеству блоков номер 3. При преобразованиях не обязательно будет использовано значение из A3. Например, вместо A3 может использоваться константа или значение из счетчика. На данный момент полиморфный генератор поддерживает 3 вида преобразований: побитовое "исключающее или" (XOR), сложение и вычитание. Набор этих преобразование можно легко расширить, главное, чтобы такое преобразование имело обратную операцию.
Блок 5 служит для увеличения A1 на единицу. Как и во всех других блоках эта операция может быть выполнена по-разному, то есть с использованием различных элементарных инструкций виртуальной машины.
Блок 6 организует цикл. Он уменьшает значение A2 на единицу, и если результат не равен 0, то виртуальная машина переходит к выполнению четвертого блока. На самом деле управление может быть передано на один из холостых блоков между блоком 3 и 4, но с функциональной точки зрения это значения не имеет.
Блок 7 производит проверку ограничения по времени использования алгоритма. Код по проверке на ограничение по времени относится к холостым командам и, на самом деле, может присутствовать и выполнятся в коде большое количество раз. То, что он относится к холостым блокам кода вовсе не значит, что он не будет нести функциональной нагрузки. Он будет действительно проверять ограничение, но он, как и другие холостые блоки, может располагаться произвольным образом в пустых промежутках между функциональными блоками. Поскольку этот блок может теоретически никогда не встретиться среди холостых блоков, то хоть один раз его следует выполнить. Именно поэтому он и вынесен как один из функциональных блоков. Если же при генерации алгоритма от генератора не требуется ограничение по времени, то в качестве аргумента к виртуальной команде проверки времени используется специальное число.
Блок 8 завершает работу алгоритма.
3.2.2. Виртуальная машина для выполнения полиморфных алгоритмов
Для начала приведем список инструкций, поддерживаемых на данный момент виртуальной машиной. Коды этих инструкций имеют тип E_OPERATION и определены в файле p_enums.h следующим образом:
enum E_OPERATION // Инструкции
{
EO_ERROR = -1, // Недопустимая инструкция
EO_EXIT_0, EO_EXIT_1, EO_EXIT_2, // Конец работы
EO_NOP_0, EO_NOP_1, EO_NOP_2, EO_NOP_3, // Пустые команды
EO_TEST_TIME_0, EO_TEST_TIME_1, // Контроль времени
EO_MOV, EO_XCHG, // Пересылка данных
EO_PUSH, EO_POP, // Работа со стеком
EO_XOR, EO_AND, EO_OR, EO_NOT, // Логические операции
EO_ADD, EO_SUB, EO_MUL, EO_DIV, EO_NEG, // Арифметические операции
EO_INC, EO_DEC,
EO_TEST, EO_CMP, // Операции сравнения
// (влияют на флаги)
EO_JMP, EO_CALL, EO_RET, // Операторы безусловного перехода
EO_JZ, EO_JNZ, EO_JA, EO_JNA, // Условные переходы
};
В таблице 1 приведена информация по этим инструкциям и перечислены их аргументы.
Таблица 1. Описание инструкций виртуальной машины.
|
Название |
Действие |
|
EO_EXIT_0 EO_EXIT_1 EO_EXIT_2 |
Команды завершения работы. После ее выполнения виртуальная машина остановится, и управление будет передано выше. Данные инструкции аргументов не имеют. |
|
EO_TEST_TIME_0 EO_TEST_TIME_1 |
Команды контроля времени. Имеют один аргумент - последний доступный день использования. |
|
EO_MOV |
Команда пересылки данных. Имеет два аргумента – источник и получатель. |
|
EO_XCHG |
Данная команда обменивает значения двух регистров или ячеек памяти, переданных в двух аргументах. |
|
EO_PUSH |
Сохраняет переданный аргумент в стеке. |
|
EO_POP |
Снимает значение с вершины стека и помещает в указанную ячейку памяти или регистр. |
|
EO_XOR |
Логическая операция XOR. Имеет два аргумента. Результат помещается в ячейку памяти или регистр, переданный в качестве первого аргумента. |
Продолжение таблицы 1. Описание инструкций виртуальной машины.
|
Название |
Действие |
|
EO_AND |
Логическая операция AND. Имеет два аргумента. Результат помещается в ячейку памяти или регистр, переданный в качестве первого аргумента. |
|
EO_OR |
Логическая операция OR. Имеет два аргумента. Результат помещается в ячейку памяти или регистр, переданный в качестве первого аргумента. |
|
EO_NOT |
Логическая операция NOT. Имеет один аргумент. Результат помещается в ячейку памяти или регистр, переданный в качестве аргумента. |
|
EO_ADD |
Арифметическая операция сложения. Имеет два аргумента. Результат помещается в ячейку памяти или регистр, переданный в качестве первого аргумента. |
|
EO_SUB |
Арифметическая операция вычитания. Имеет два аргумента. Результат помещается в ячейку памяти или регистр, переданный в качестве первого аргумента. |
|
EO_MUL |
Арифметическая операция умножения. Имеет два аргумента. Результат помещается в ячейку памяти или регистр, переданный в качестве первого аргумента. |
|
EO_DIV |
Арифметическая операция деления. Имеет два аргумента. Результат помещается в ячейку памяти или регистр, переданный в качестве первого аргумента. |
|
EO_NEG |
Арифметическая операция изменения знака. Имеет один аргумент. Результат помещается в ячейку памяти или регистр, переданный в качестве аргумента. |
|
EO_INC |
Увеличивает значение ячейки памяти или регистра на единицу, передаваемой в единственном аргументе. |
|
EO_DEC |
Уменьшает значение ячейки памяти или регистра на единицу, передаваемой в единственном аргументе. |
|
EO_TEST |
Операция сравнения двух аргументов на равенство. Если аргументы равны, то флаг ZERO выставляется в true, в противном случае в false. |
|
EO_CMP |
Операция сравнения двух аргументов. Если аргументы равны, то флаг ZERO выставляется в true, в противном случае в false. Если первый аргумент меньше второго, то флаг ABOVE выставляется в true, в противном случае в false. |
Продолжение таблицы 1. Описание инструкций виртуальной машины.
|
Название |
Действие |
|
EO_JMP |
Данная инструкция осуществляет безусловный переход по адресу, указанному в качестве аргумента. |
|
EO_CALL |
Данная инструкция осуществляет вызов функции по адресу, указанному в качестве аргумента. |
|
EO_RET |
Данная инструкция возвращает управление предыдущей функции. Аргументов нет. |
|
EO_JZ |
Условный переход по адресу, указанному в качестве аргумента. Условием является ZERO == true. |
|
EO_JNZ |
Условный переход по адресу, указанному в качестве аргумента. Условием является ZERO == false. |
|
EO_JA |
Условный переход по адресу, указанному в качестве аргумента. Условием является ABOVE == true. |
|
EO_JNA |
Условием является ABOVE == false. |
Отметим, что аргументы могут быть следующих типов:
EOP_REG – Регистр
EOP_REF_REG – Память по адресу в регистре.
EOP_VAR – Переменная.
EOP_REF_VAR – Память по адресу в переменной.
EOP_CONST – Константное значение.
EOP_RAND – Случайное число.
Перечисленные типы объявлены в файле p_enums.h.
Для примера, приведем как будет выгладить код сложения регистра N 1 с константой 0x12345:
DWORD AddRegAndConst[] = { EO_ADD, EOP_REG , 1, EOP_CONST, 0x12345 };
Для наглядной демонстрации, как происходит выполнение кода в виртуальной машине при шифровании/расшифровании данных, приведем отрывок из отладочного отчета. Каждое действие в отладочном режиме протоколируется в файле uniprot.log. Благодаря этому, было легко отлаживать механизм генерации полиморфных алгоритмов и саму работу алгоритмов. Дополнительным результатом создания механизма протоколирования стала возможность показать, как происходит выполнение алгоритма шифрования расшифрования. Ниже приведен отрывок из файла uniprot.log, относящийся к процессу шифрования данных. С целью сокращения объема текста, убраны дублирующийся вывод внутри цикла. Также при генерации этого алгоритма были выставлена вложенность шифрования равная единицы и почти убраны холостые блоки.
=== Start TranslateOperations ===
mov RAND ==> REG_2
xchg REG_2 VAR_16 REG_2 VAR_16
mov CONST ==> VAR_11
dec VAR_11 ==> VAR_11
cmp VAR_11 CONST
jnz CONST
mov RAND ==> REG_6
xchg VAR_14 VAR_12 VAR_14 VAR_12
mov CONST ==> VAR_15
add VAR_15 VAR_18 ==> VAR_15
mov RAND ==> REG_4
mov CONST ==> VAR_19
add VAR_19 VAR_9 ==> VAR_19
add REG_8 REG_7 ==> REG_8
xchg REG_2 VAR_13 REG_2 VAR_13
Эта часть повторяется много раз:
mov RAND ==> REG_6
xor REF_VAR_11 VAR_14 ==> REF_VAR_11
mov RAND ==> REG_4
mov RAND ==> REG_9
xor REF_VAR_11 VAR_15 ==> REF_VAR_11
sub VAR_11 CONST ==> VAR_11
mov RAND ==> REG_7
dec VAR_14 ==> VAR_14
cmp VAR_14 CONST
jnz CONST
…………..
mov RAND ==> REG_1
add REG_9 REG_6 ==> REG_9
test_time1 VAR_10
OK TIME (continue)
exit
3.2.3. Генератор полиморфного кода
3.2.3.1. Блочная структура полиморфного кода
Основу генератора полиморфного кода составляют таблицы выбора. Как уже было описано ранее, алгоритм шифрования и расшифрования состоит из восьми обязательных функциональных блоков. Каждый блок хоть и выполнит строго определенную функцию, но может быть реализован многими способами. Причем с использованием различных виртуальных регистров и виртуальных ячеек памяти. Возможные комбинации реализации блока описаны в специальных таблицах следующего вида, о которых будет сказано позднее.
//--------------------------------------------------------------
// Блок N5. (x1)
// Служит для организации цикла.
// ES_VARIABLE_0 – ячейка, которая может быть занята под счетчик.
// ES_REG_0 - регистр, который может быть занят под счетчик.
// ES_ADDRESS_0 - куда осуществить переход для повтора цикла.
BLOCK_START(05_00)
EO_DEC, EOP_VAR, ES_VARIABLE_0,
EO_CMP, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 0,
EO_JNZ, EOP_CONST, ES_ADDRESS_0
BLOCK_END(05_00)
BLOCK_START(05_01)
EO_DEC, EOP_REG, ES_REG_0,
EO_CMP, EOP_REG, ES_REG_0, EOP_CONST, 0,
EO_JNZ, EOP_CONST, ES_ADDRESS_0
BLOCK_END(05_01)
BLOCKS_START(05)
BLOCK(05_00)
BLOCK(05_01)
BLOCKS_END(05)
BLOCKS_SIZE_START(05)
BLOCK_SIZE(05_00)
BLOCK_SIZE(05_01)
BLOCKS_SIZE_END(05)
//--------------------------------------------------------------
Под полиморфизмом понимается не только выбор и сочетание произвольного набора блоков, но и их расположение в памяти. Стоит отметить, что просто построение алгоритма из набора различных блоков достаточно сложная процедура. Так как необходимо учитывать использование виртуальных регистров и виртуальной памяти, используемых в разных блоках по разному. Например, использование определенного регистра в качестве счетчика во втором блоке автоматически приводит к учету этой особенности и назначению этого регистра во всех других блоках.
Как было сказано ранее, алгоритмы шифрования и расшифрования генерируются одним алгоритмом и функционально различаются только блоками преобразований данных. На этом их схожесть заканчивается. Коды алгоритма шифрования и расшифрования могут быть совершенно непохожи друг на друга и состоять из разного набора инструкций виртуальной машины.
Вернемся к распределению блоков в памяти. Помимо того, что каждый алгоритм состоит из произвольного набора функциональных блоков, эти блоки не имеют фиксированного места расположения. Скажем, что под весь алгоритм выделено 200 байт, а размер всех блоков в сумме составляет 100 байт. В результате положение этих блоков как бы "плавает" от одного сгенерированного алгоритма к другому. Должно выполняться лишь одно условие: соблюдение четкой последовательности расположения блоков. То есть, адрес расположения блока с большим номером не может быть меньше, чем адрес блока с меньшим номером. Для большей наглядности приведем рисунок 6.
![]() Рисунок
6.
Расположение
функциональных
блоков в памяти.
Рисунок
6.
Расположение
функциональных
блоков в памяти.
Белым цветом показаны все функциональные блоки. Серым цветом отмечены пустые места, которые будут заполнены произвольными холостыми блоками.
Может получиться, например, и такая картина распределения блоков, когда между некоторыми нет промежутка заполняемого холостыми блоками. Такая ситуация показана на рисунке 7.
![]() Рисунок
7.
Плотное расположение
функциональных
блоков в памяти.
Рисунок
7.
Плотное расположение
функциональных
блоков в памяти.
Как функциональные блоки, так и холостые, могут иметь различную длину. После случайного расположения функциональных блоков происходит заполнение пустых пространств между ними холостыми блоками. Причем, существуют холостые блоки длиной 1, для того чтобы можно было заполнить пустые места в любом случае. Размер памяти, выделенный под создаваемый код алгоритма, выбирается произвольно. В данной версии он лежит в пределах от 160 до 200 байт. Это с запасом покрывает максимально необходимый размер памяти, необходимый для размещения 8 самых больших функциональных блоков из всех возможных, и оставляет место под холостые блоки. Более большой полиморфный код хоть и будет сложнее для анализа, но это может существенно замедлить процесс шифрования и расшифрования. По этому лучше всего придерживаться разумного баланса.
3.2.3.2. Алгоритм генерации полиморфного кода
Опишем теперь пошагово как работает генератор полиморфного кода.
На первом этапе выбираются характеристики будущих алгоритмов. К ним относятся:
a) размер памяти, выделенной под код;
б) в каких регистрах или ячейках будут располагаться указатели на модифицируемый код;
г) сколько раз будут повторяться функциональные блоки 3 и 4;
д) в каких регистрах или ячейках будут располагаться счетчики циклов;
При этом количество повторений блоков 3 и 4 должно быть одинаковым и для алгоритма шифрования и для алгоритма расшифрования, так как каждой команде преобразования данных при шифровании должна быть сопоставлена обратная команда в алгоритме расшифрования.Виртуальная память, используемая в алгоритме, заполняется случайными значения.
Создается 1-ый функциональный блок и помещается в промежуточное хранилище.
а) Случайным образом ищется подходящий первый блок. Критерий поиска – блок должен использовать регистр или ячейку памяти под указатель, в зависимости от того какие характеристики были выбраны на первом шаге (пункт б).
б) В код блока подставляется соответствующий номер регистра или адрес виртуальной ячейки памяти.Создается 2-ой функциональный блок и помещается в промежуточное хранилище. Алгоритм создания подобен алгоритму, описанному в шаге 3. Но только теперь подставляется не только номер регистра или ячейки памяти, куда помещается значение, но и адрес памяти с источником. В эту ячейку памяти в дальнейшем виртуальная машина будет помещать размер шифруемой/расшифруемой области.
Необходимое количество раз создаются и помещаются в промежуточное хранилище функциональные блоки под номером 3. Механизм их генерации также схож с шагами 3 и 4. Отличием является то, что некоторые константы в коде блока заменяются случайными числами. Например, эти значения при шифровании или расшифровании будут складываться с преобразуемыми ячейками памяти, вычитаться и так далее.
Подсчитывается размер уже сгенерированных блоков. Это число затем будет использоваться для случайной генерации адреса начала блоков в цикле.
Рассчитывается размер памяти, который будет выделен под уже сгенерированные блоки (расположенные до цикла) с резервированием места под холостые блоки. Также подсчитывается адрес первого блока в цикле.
Необходимое количество раз создаются и помещается в промежуточное хранилище функциональные блоки под номером 3. Это шаг несколько сложнее, чем все другие. Здесь весьма сильная зависимость между сгенерированным кодом шифрования и расшифрования. В коде расшифрования используются обратные по действию операции относительно операций шифрования. При этом они располагаются в обратной последовательности.
Создается 5-ый функциональный блок и помещается в промежуточное хранилище.
Создается 6-ой функциональный блок и помещается в промежуточное хранилище. Это блок, организующий цикл, поэтому он использует адреса, рассчитанные на шаге 7.
Создается 7-ой функциональный блок и помещается в промежуточное хранилище.
Создается 8-ой функциональный блок и помещается в промежуточное хранилище.
Созданные функциональные блоки размещаются в одной области памяти с промежутками случайного размера. После чего получается картина подобная тем, что приведены на рисунках 6 и 7.
Оставшиеся промежутки заполняются случайно выбранными холостыми блоками. При этом эти блоки также подвергаются модификации кода. Например, подставляются случайные, но неиспользуемые номера регистров, записываются случайные константы и так далее.
Происходит запись в файл необходимых идентификаторов, структур, различных данных и самого полиморфного кода. В результате мы получаем то, что называется файлом с полиморфный алгоритмом.
3.2.3.3. Таблицы блоков для генерации полиморфного кода
Выше неоднократно упоминались таблицы блоков, среди которых происходит выбор. Приведем для примера часть таблицы с блоками N 1 и опишем ее устройство.
//--------------------------------------------------------------
// Блок N0. (x1)
// Служит для инициализации указателя нулем.
// ES_VARIABLE_0 - ячейка которая может быть занята под указатель.
// ES_REG_0 - регистр который может быть занят под указатель.
BLOCK_START(00_00)
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 0
BLOCK_END(00_00)
BLOCK_START(00_01)
EO_MOV, EOP_REG, ES_REG_0, EOP_CONST, 0
BLOCK_END(00_01)
BLOCK_START(00_02)
EO_PUSH, EOP_CONST, 0,
ES_RANDOM_NOP,
ES_RANDOM_NOP,
EO_POP, EOP_REG, ES_REG_0
BLOCK_END(00_02)
. . . . . . .
BLOCKS_START(00)
BLOCK(00_00)
BLOCK(00_01)
BLOCK(00_02)
BLOCK(00_03)
. . . . .
BLOCKS_END(00)
BLOCKS_SIZE_START(00)
BLOCK_SIZE(00_00)
BLOCK_SIZE(00_01)
BLOCK_SIZE(00_02)
BLOCK_SIZE(00_03)
. . . . .
BLOCKS_SIZE_END(00)
//--------------------------------------------------------------
Рассмотрим строку "BLOCK_START(00_00)". BLOCK_START представляет собой макрос который делает код более понятным и раскрывается так:
#define BLOCK_START(num) const static int block_##num [] = {
BLOCKS_END раскрывается в:
#define BLOCK_END(num) }; const size_t sizeBlock_##num =\
CALC_ARRAY_SIZE(block_##num);
Таким образом, BLOCK_START и BLOCK_END позволяет получить именованный массив и его длину. Это удобно для автоматического построения массива указателей на блоки и их длину. Нам более интересны не эти вспомогательные макросы, а следующая строка.
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 0
Она представляет собой один из вариантов реализации первого блока. EO_MOV означает, что будет выполнена команда пересылки данных. EOP_VAR означает, что запись будет производиться в ячейку памяти. Этот блок никогда не станет выбранным, если при выборе характеристик алгоритма будет решено, что под указатель необходимо использовать регистр. Если же будет принято решение использовать ячейку памяти, то этот блок попадет в список из которого затем случайным образом будет произведен выбор. ES_VARIABLE_0 это идентификатор на место которого будет подставлен номер переменной, используемой для хранения указателя. Этот номер также генерируется на этапе выбора характеристик. EOP_CONST означает, что переменной будет присвоено значение константы. Этим значением является 0.
Аналогичным образом интерпретируется строка: EO_MOV, EOP_REG, ES_REG_0, EOP_CONST, 0. Но теперь вместо виртуальной ячейки памяти выступает виртуальный регистр. Более интересным является следующий блок:
EO_PUSH, EOP_CONST, 0,
ES_RANDOM_NOP,
ES_RANDOM_NOP,
EO_POP, EOP_REG, ES_REG_0
Принцип его работы в следующем. На вершину стека помещается константное значение равное 0. На место ES_RANDOM_NOP помещаются произвольный холостой блок. В последней строке происходит получение значение из стека и запись его в виртуальный регистр, выбранный под указатель.
Макросы BLOCKS_START и BLOCKS_SIZE_START носят вспомогательный характер и не представляют большого интереса. Они просто строят таблицы адресов различных блоков и их размеров.
3.2.4. Уникальность генерируемого полиморфного алгоритма и сложность его анализа
Важная идея в разрабатываемом модуле защиты заключена в построении сложного для анализа полиморфного кода, что должно препятствовать построению обратного алгоритма, так как в защищаемых системах часто просто невозможно хранить ключи отдельно от данных. Если есть доступ к ключам, то и увеличивается вероятность каким-либо образом произвести несанкционированные действия. Из этого следует необходимость создания сложных для анализа алгоритмов шифрования/расшифрования. Одним из этих средств является виртуальная машина. Другим – использование полиморфных алгоритмов. Это затрудняет возможности по анализу механизмов шифрования данных, так как полный анализ одного алгоритма очень мало помогает в анализе другого. Чем больше возможно вариантов построения полиморфного кода, тем более трудоемкой становится процедура анализа. Следовательно, можно сказать, что критерий надежности повышается с ростом количества возможных вариантов полиморфного кода. Подсчитаем количество возможных вариантов, который может сгенерировать разработанный генератор полиморфного кода.
Вероятность генерации двух одинаковых пар составляет: (2^32*3)^5 3.5*10^50. Где 2^32 – случайно используемая константа для шифрования. 3 – количество возможных операций над числом. 5 – максимальное количество проходов для шифрования. Фактически это означает что два одинаковых алгоритма не будут никогда сгенерированы этой системой. Но это не является целью. Ведь то что не генерируются 2 одинаковых алгоритма, не так важно. Важно что анализ таких разнородных механизмов шифрования/расшифрования будет очень плохо поддаваться анализу.
Покажем на примере, что именно могут дать полиморфные алгоритмы. Предположим кто-то задумал создать универсальный редактор отчетов о выполненных работах, создаваемых АРМ студента. В этом отчете хранится оценка о тестировании. Ее исправление и является целью. АРМ студента шифрует файл с отчетом уникальным полиморфным алгоритмом, сгенерированным специально для данного студента. Ключ расшифрования у студента не хранится. Он находится у АРМ преподавателя и служит для идентификации, что студент выполнил работу именно на своем АРМ. В противном случае файл с отчетом просто не расшифруется.
Для обхода такой системы можно пойти двумя путями. Первый вариант состоит в эмуляции системы генерации отчетов и использования имеющегося файла с алгоритмом шифрования. Второй путь – это создание алгоритма расшифрования по алгоритму шифрования. После чего файл с отчетом можно будет легко расшифровать, модифицировать и вновь зашифровать. В обеих случаях придется разбираться, как использовать предоставляемые COM сервисы модуля защиты, что само по себе уже не простая задача. Но, допустим, это было сделано, и теперь мы остановимся на других моментах.
В первом случае может понадобиться разрабатывать достаточно сложную систему с целью эмуляции генератора отчета. Это очень труднореализуемо. В каком-то смысле придется повторить большую часть функциональности АРМ студента. Так, если в отчете будут храниться вопросы, которые были заданы студенту, то, фактически, придется работать с этой базой вопросов и случайно выбирать из них. В противном случае, если использовать строго определенный набор, то у всех, кто воспользуется такой системой взлома, будут совпадать отчеты. Это может привести к подозрению со стороны преподавателя. Таким образом, в грамотно и сложно организованной АСДО этот подход практически не применим.
Остался второй путь, заключающийся в генерации обратного алгоритма. Здесь на пути и встает многовариантность кода. Невозможно применить маску с целью поиска функциональных блоков, а следовательно, и просто их выделить. Можно только написать высокоинтеллектуальный анализатор кода, который превратит алгоритм в псевдокод, а уже затем по нему построит обратный. Это очень сложная задача. Причем, для написания такой программы придется досконально изучить код виртуальной машины. В том случае, когда исходные коды отсутствуют, все это может превратиться в непосильную задачу. Точнее сказать, в слишком дорогой в своей реализации, и доступной в написании только высококвалифицированному специалисту.
Если кто-то реализует второй вариант программы, то небольшого расширения базы блоков в исходных кодах будет достаточно, чтобы всю работу понадобилось проделать заново.
На мой взгляд, созданная система достаточно сложна в плане анализа и может эффективно помочь защищать АСДО и другие программы от несанкционированных действий.
3.3. Особенности реализации модуля защиты
Разрабатываемый модуль защиты Uniprot будет представлять собой файл типа dynamic link library (DLL) с именем Uniprot.dll.
Для организации взаимодействия модуль защиты предоставляет набор интерфейсов с использованием технологии COM. Для описания интерфейсов используется специальный язык - IDL, по своей структуре очень похожий на С++. В определении интерфейса описываются заголовки входящих в него функций с указанием их имен, возвращаемых типов, входных и выходных параметров, а также их типов. Подробно с предоставляемыми интерфейсами можно будет ознакомиться в разделе 4.2. Интерфейсы, описанные в IDL файле, преобразуются IDL-компилятором (MIDL.EXE) в двоичный формат и записываются в файл с расширением TLB, который называется библиотекой типов. Этот файл будет необходим, например, для использования модуля Uniprot.dll из среды Visual Basic. С процессом подключения TLB файлов в Visual Basic можно ознакомиться в разделе 4.4.2.
Для регистрации модуля в системе необходимо вызвать в нем функцию DllRegisterServer, которая внесет нужные изменения в реестр. Для этих целей можно воспользоваться утилитой regsvr32.exe. Она поставляется вместе с операционной системой, а потому должна находиться на любой машине. Regsvr32 должна загрузить СОМ-сервер и вызвать в нем функцию DllRegisterServer, которая внесет нужные изменения в реестр.
Организация работы с зашифрованными файлами строится на основе механизмов дескрипторов (или описателей файла). Каждому открытому или созданному файлу назначается уникальный (в рамках данного процесса) идентификатор, представляющий собой число в формате short. Этот идентификатор возвращается вызывающей программе, после чего она может проводить над этим файлом набор операций. Все номера открытых файлов хранятся во внутренней таблице модуля, и каждому из них соответствует структура данных, необходимая для работы с ним. В частности, там хранится текущая позиция для чтения данных, алгоритм для шифрования/расшифрования данных. Когда работа с файлом закончена, программа должна закрыть файл с соответствующим идентификатором. Он будет удален из таблицы, и в следующий раз тот же самый идентификатор может послужить для работы с другим файлом. Если файл не будет закрыт, то после завершения программы, использующей модуль защиты, файл будет поврежден, и работа с ним в дальнейшем будет невозможна.
3.4. Защита исполняемых файлов
Одним из средств, входящих в комплект разрабатываемой системы должна стать программа для защиты их от модификации. Было принято решение использовать уже имеющиеся механизмы шифрования, основанные на полиморфный алгоритмах. О преимуществах такого метода говорилось ранее. Во- первых, это большая сложность создания универсального взломщика, а, во-вторых, возможность запрещения запуска программ без наличия соответствующего файла с алгоритмом расшифрования.
Разработанная программа имеет два возможных режима запуска. Первый – для генерации зашифрованного файла из указанного исполняемого модуля. Второй –для запуска защищенного модуля. Рассмотрим шаги, которые выполняет механизм шифрования исходного файла.
Инициализация библиотеки Uniprot.
Чтение исполняемого файла в память.
Запуск исполняемого файла с флагом остановки. То есть программа загружается, но управления не получает.
Чтение частей загруженной программы и поиск ее соответствующих частей в прочитанном файле. Найденные части кода сохраняются отдельно. После чего их места в буфере с прочитанным файлом заменяются случайными значениями.
Генерация алгоритма шифрования и расшифрования.
Запись в зашифрованный файл буфера с прочитанным, а затем измененным файлом. В этот же файл пишутся выделенные фрагменты кода.
Удаление файла шифрования, так как он более не предоставляет интереса.
Теперь рассмотрим шаги, которые выполняет механизм запускающий зашифрованный файл на исполнение.
Поиск соответствующего файла с алгоритмом расшифрования.
Создание временного исполняемого файла и запись в него "испорченного" файла (см. механизм шифрования, пункт 4).
Запуск "испорченного" исполняемого файла с флагом остановки. То есть программа загружается, но управления не получает.
Восстановление "испорченных" мест в памяти. Изначальный код для исправления также хранится в зашифрованном файле.
Передача управления расшифрованному файлу.
Ожидание окончания выполнения запущенной программы.
Удаление временного файла.
Как видно из описания, данная программа достаточна проста в своем устройстве и достаточна эффективна.
ГЛАВА 4. ПРИМЕНЕНИЕ СИСТЕМЫ ЗАЩИТЫ
4.1. Состав библиотеки Uniprot
В состав библиотеки входят следующие компоненты:
Исходные тексты COM модуля Uniprot.dll.
Исходные тексты программы ProtectEXE.exe.
Отдельно собранные файлы, необходимые для подключения Uniprot.dll. Этими файлами являются: export.cpp, export.h, Uniprot.tlb.
Файл reg_uniprot.bat для регистрации COM модуля Uniprot.dll.
Руководство программиста по использованию модуля Uniprot.dll.
Руководство программиста по использованию программы ProtectEXE.exe.
Набор примеров написанных на Visual Basic, демонстрирующих работу с библиотекой Uniprot.
4.2. Руководство программиста по использованию модуля Uniprot.dll
Вначале опишем вспомогательный тип CreateMode, используемый в методе Create. Он описывает тип создаваемого зашифрованного файла. В данной версии модуля Uniprot он может иметь два значения: DEFAULT и DISABLE_ARC. Первый из них сообщает функции, что будет создан обыкновенный зашифрованный файл. Данные в нем будут вначале упакованы библиотекой zlib, а затем уже зашифрованы. Это может дать существенный выигрыш в плане уменьшения размера выходного файла, например, на картинках в формате BMP или простом тексте. Использование DISABLE_ARC приведет к созданию зашифрованного, но не сжатого файла. Это даст выигрыш по времени при распаковке и упаковке, но не уменьшит размер зашифрованного файла. Это также может быть полезно при шифровании уже сжатых файлов. Примером могут являться картинки в формате JPG.
enum CreateMode
{
DEFAULT = 0,
DISABLE_ARC = 1
} CreateMode;
Теперь опишем функции, предоставляемые интерфейсом IProtect. В этот интерфейс собраны функции общего плана и генерации файлов с полиморфными алгоритмами шифрование и расшифрования.
interface IProtect : IDispatch
{
[id(1), helpstring("method GetInfo")]
HRESULT GetInfo(
[out] short *version, [out] BSTR *info);
[id(2), helpstring("method Generate UPT files")]
HRESULT GenerateUPTfiles(
[in] BSTR algorithmCryptFileName,
[in] BSTR algorithmDecryptFileName);
[id(3), helpstring("method Generate Time Limit UPT files")]
HRESULT GenerateTimeLimitUPTfiles(
[in] BSTR algorithmCryptFileName,
[in] BSTR algorithmDecryptFileName,
[in] long LimitDays);
[id(4), helpstring("method Generate Time Limit UPT files")]
HRESULT GenerateTimeLimitUPTfiles2(
[in] BSTR algorithmCryptFileName,
[in] BSTR algorithmDecryptFileName,
[in] long LimitDaysCrypt,
[in] long LimitDaysDecrypt);
};
Теперь опишем каждую из функций интерфейса IProtect.
HRESULT GetInfo([out] short *version, [out] BSTR *info);
Функция GetInfo возвращает строку с краткой информации о данном модуле и его версии. Может быть использована для получения рядя сведений о модуле. Например, имя автора и год создания. Версия хранится в виде числа следующим образом: 0x0100 – версия 1.00, 0x0101 – версия 1.01, 0x0234 – версия 2.34 и так далее.
Описание используемых параметров:
version – сюда будет занесена версия модуля.
info – сюда будет занесена строка с краткой информацией о модуле.
HRESULT GenerateUPTfiles(
[in] BSTR algorithmCryptFileName,
[in] BSTR algorithmDecryptFileName);
Функция GenerateUPTfiles генерирует два файла-ключа. Они представляют собой сгенерированные полиморфным генератором алгоритмы шифрования и расшифрования. При этом расшифровать зашифрованный файл можно только соответствующим алгоритмом расшифрования. Генерируемая пара ключей на практике уникальна. Вероятность генерации двух одинаковых пар составляет: (2^32*3)^5 3.5*10^50. Где 2^32 – случайно используемая константа для шифрования. 3 – количество возможных операций над числом. 5 – максимальное количество проходов для шифрования.
Описание используемых параметров:
algorithmCryptFileName – имя выходного файла с алгоритмом шифрования.
algorithmDecryptFileName – имя выходного файла с алгоритмом расшифрования.
HRESULT GenerateTimeLimitUPTfiles(
[in] BSTR algorithmCryptFileName,
[in] BSTR algorithmDecryptFileName,
[in] long LimitDays);
Функция GenerateTimeLimitUPTfiles генерирует два файла-ключа, ограниченных в использовании по времени. В целом функция эквивалентна GenerateUPTfiles, но генерируемые ею алгоритмы имеют дополнительное свойство. Их использование ограничено определенным временем. Количество дней, в течении которых они будут работать, указывается в третьем параметре LimitDays. Отсчет начинается с текущего дня. Это может быть полезно, например, для ограничения срока использования проектов. Естественна защита сама по себе ненадежна, так как невозможно защититься от перевода часов на компьютере или модификации кода модуля защиты с целью удаления соответствующих проверок. Но тем не менее это может дать дополнительные свойства защищенности, по крайней мере от рядовых пользователей.
Описание используемых параметров:
algorithmCryptFileName – имя выходного файла с алгоритмом шифрования.
algorithmDecryptFileName – имя выходного файла с алгоритмом расшифрования.
LimitDays – количество дней, в течении которых будут функционировать сгенерированные алгоритмы.
HRESULT GenerateTimeLimitUPTfiles2(
[in] BSTR algorithmCryptFileName,
[in] BSTR algorithmDecryptFileName,
[in] long LimitDaysCrypt,
[in] long LimitDaysDecrypt);
Функция GenerateTimeLimitUPTfiles2 генерирует два файла-ключа, ограниченных в использовании по времени. В отличие от функции GenerateTimeLimitUPTfiles, время ограничения использования алгоритма шифрования и расшифрования задается не общее, а индивидуальное.
Описание используемых параметров:
algorithmCryptFileName – имя выходного файла с алгоритмом шифрования.
algorithmDecryptFileName – имя выходного файла с алгоритмом расшифрования.
LimitDaysCrypt – количество дней, в течении которых будут функционировать сгенерированный алгоритм шифрования.
LimitDaysDecrypt – количество дней, в течении которых будут функционировать сгенерированный алгоритм расшифрования.
Следующий предоставляемый модулем защиты интерфейс имеет имя IProtectFile. В нем собраны функции работы с зашифрованными файлами, такие как создание зашифрованного файла, запись в него, чтение и так далее. Идеология работы с зашифрованными файлами построена на дескрипторах. При создании или открытии зашифрованного файла ему в соответствие ставится дескриптор, с использованием которого в дальнейшем и ведется работа с файлом.
interface IProtectFile : IDispatch
{
[id(1), helpstring("method Create New File")]
HRESULT Create(
[in] BSTR name,
[in] CreateMode mode,
[in] BSTR uptFileNameForWrite,
[out, retval] short *handle);
[id(2), helpstring("method Open File")]
HRESULT Open(
[in] BSTR name,
[in] BSTR uptFileNameForRead,
[in] BSTR uptFileNameForWrite,
[out, retval] short *handle);
[id(3), helpstring("method Close File")]
HRESULT Close(
[in] short handle);
[id(4), helpstring("method Write To File")]
HRESULT Write(
[in] short handle,
[in] VARIANT buffer,
[out, retval] long *written);
[id(5), helpstring("method Read From File")]
HRESULT Read(
[in] short handle,
[out] VARIANT *buffer,
[out, retval] long *read);
[id(6), helpstring("method Write String To File")]
HRESULT WriteString(
[in] short handle,
[in] BSTR buffer,
[out, retval] long *written);
[id(7), helpstring("method Read String From File")]
HRESULT ReadString(
[in] short handle,
[out] BSTR *buffer,
[out, retval] long *read);
[id(8), helpstring("method From File")]
HRESULT FromFile(
[in] short handle,
[in] BSTR FileName,
[out, retval] long *read);
[id(9), helpstring("method To File")]
HRESULT ToFile(
[in] short handle,
[in] BSTR FileName,
[out, retval] long *written);
};
Опишем функции в данном интерфейсе.
HRESULT Create(
[in] BSTR name,
[in] CreateMode mode,
[in] BSTR uptFileNameForWrite,
[out, retval] short *handle);
Функция Create служит для создания новых зашифрованных файлов. Поскольку во вновь созданный файл можно только писать, то функции необходим для работы только файл с алгоритмом шифрования. Имя файла с этим алгоритмом передается третьим параметром и является обязательным. Параметр mode имеет тип CreateMode, для чего он служит, было сказано ранее. При успешном создании файл, в handle возвращается его дескриптор. По окончании работы с файлом, его обязательно нужно закрыть, используя функцию Close.
Описание используемых параметров:
name – имя создаваемого файла.
mode – тип создаваемого файла (см. ранее описание типа CreateMode)
uptFileNameForWrite – имя файла с алгоритмом шифрования.
handle – возвращаемый дескриптор созданного файла.
HRESULT Open(
[in] BSTR name,
[in] BSTR uptFileNameForRead,
[in] BSTR uptFileNameForWrite,
[out, retval] short *handle);
Функция Open открывает уже ранее созданный зашифрованный файл. Файл может быть открыт как для чтения так и для записи. После чего производить с ним можно только одну из двух операций - чтение или запись данных. Это обусловлено тем, что записи в файле представляют собой блоки различного размера. Данная особенность является следствием необходимости хранения такого типа данных, как VARIANT. Таким образом, запись к данным в файле может быть только последовательная. И если после открытия файла произвести в него запись, то прочитать старые данные из него будет уже невозможно. Можно сказать, что открытие файла для записи эквивалентно его созданию, за парой исключений. Первое исключение состоит в том, что при открытии файла не указывается его тип. То есть нет необходимости указывать, следует паковать данные перед шифрованием или нет. Информация о типе берется из уже существующего файла. Второе состоит в том, что для открытия файла, в отличии от создания, обязательно необходим файл с алгоритмом расшифрования. Режим открытия файла зависит от того, указан ли файл с алгоритмом шифрования. Имя файла с алгоритмом расшифрования является обязательным параметром. Файл с алгоритмом расшифрования – нет. Если он не будет указан, то из такого файла возможно будет только чтение. Если указан, то будет возможно как чтение, так и запись. При успешном открытии файла в handle возвращается дескриптор этого файла. По окончании работы с файлом его обязательно нужно закрыть, используя функцию Close.
Описание используемых параметров:
name – имя открываемого файла.
uptFileNameForRead – имя файла с алгоритмом расшифрования.
uptFileNameForWrite – имя файла с алгоритмом шифрования.
handle – возвращаемый дескриптор открытого файла.
HRESULT Close(
[in] short handle);
Функция Close закрывает ранее созданный или отрытый файл. Если программа при своей работе создаст новый зашифрованный файл или откроет уже существующий файл для записи, но не вызовет функцию Close до своего завершения, но файл будет поврежден. После закрытия файла дескриптор становится поврежденным и его более нельзя использовать в качестве параметра для других функций.
Описание используемых параметров:
handle – дескриптор закрываемого файла.
HRESULT Write(
[in] short handle,
[in] VARIANT buffer,
[out, retval] long *written);
Функция Write производит запись в файл данных, переданных в переменной типа VARIANT. Запись производится в файл связанный с дескриптором, передаваемый в параметре handle. В возвращаемом значении written после завершения работы функции, будет указано количество байт записанных в файл.
Поскольку при разработке модуля защиты изначально был заложен принцип возможности использования его в программах, написанных на различных языках, то немаловажным вопросом является программный интерфейс. Именно по этой причине и был выбран типа VARIANT.
Тип VARIANT предназначен для представления значений, которые могут динамически изменять свой тип. Если любой другой тип переменной зафиксирован, то в переменные VARIANT можно вносить переменные разных форматов. Шире всего VARIANT применяется в случаях, когда фактический тип данных изменяется или неизвестен в момент компиляции. Переменным типа VARIANT можно присваивать любые значения любых целых, действительных, строковых и булевых типов. Для совместимости с другими языками программирования предусмотрена также возможность присвоения этим переменным значений даты/времени. Кроме того, вариантные переменные могут содержать массивы переменной длины и размерности с элементами указанных типов. Все целые, действительные, строковые, символьные и булевы типы совместимы с типом VARIANT в отношении операции присваивания. Вариантные переменные можно сочетать в выражениях с целыми, действительными, строковыми, символьными и булевыми. При этом, например, все необходимые преобразования Delphi выполняет автоматически.
Правда, сразу оговоримся, что передавать модулю защиты в переменных VARIANT можно не совсем все что угодно. Например, нельзя передать адрес на COM интерфейс, что логичною, так как неясно, как подобные данные интерпретировать.
Описание используемых параметров:
handle – дескриптор файла для записи.
buffer – записываемое значение.
written – возвращает размер записанных данных в байтах.
HRESULT Read(
[in] short handle,
[out] VARIANT *buffer,
[out, retval] long *read);
Функция Read читает из файла данные и возвращает их в виде переменной типа VARIANT. Чтение производится из файла связанного с дескриптором, передаваемого в параметре handle. В возвращаемом значении read после завершения работы функции будет указано количество прочитанных из файла байт.
Описание используемых параметров:
handle – дескриптор файла для чтения.
buffer – возвращаемые данные.
read – возвращает размер прочитанных данных в байтах.
HRESULT WriteString(
[in] short handle,
[in] BSTR buffer,
[out, retval] long *written);
Функция WriteString служит для записи в зашифрованный файл строки. Отметим, что строку можно записать, используя функцию Write, так как тип VARIANT позволяет хранить строки. Эта функция заведена для большего удобства, так как строковый тип широко распространен. По крайней мере, как показала практика, он очень часто встречается в системах обучения и тестирования.
Описание используемых параметров:
handle – дескриптор файла для записи.
buffer – записываемая строка.
written – возвращает размер записанных данных в байтах.
HRESULT ReadString(
[in] short handle,
[out] BSTR *buffer,
[out, retval] long *read);
Функция ReadString служит для чтения строки из зашифрованного файла.
Описание используемых параметров:
handle – дескриптор файла для чтения.
buffer – возвращаемая строка.
read – возвращает размер прочитанных данных в байтах.
HRESULT FromFile(
[in] short handle,
[in] BSTR FileName,
[out, retval] long *read);
Функция FromFile позволяет записать в зашифрованный файл данные, прочитанные из другого файла. Иначе говоря, данная функция сохраняет целиком произвольный файл в зашифрованном файле. Это может быть удобно, если, например, следует сохранить и зашифровать набор картинок в формате jpg. Если бы данная функция отсутствовала, то пришлось бы вначале программно считывать эти файлы в память, а уже затем записывать в зашифрованный файл. Чтобы облегчить задачу программисту и была создана эта функция. Обратным действием – извлечением файла из зашифрованного хранилища – занимается функция ToFile. В результате получается искомый файл в незашифрованном виде. Это может показаться слабым местом в организации защиты. Но в этом есть смысл с точки зрения удобства адаптации уже существующих программный комплексов обучения и тестирования. Сразу хочется заметить, что если есть желание обойтись без временных файлов в незашифрованном виде, то никаких сложностей нет. Рассмотрим на примере jpg файла. Достаточно записать такой файл в зашифрованном виде, используя функцию Write. Это достаточно просто, так как тип VARIANT может хранить массивы байт. В дальнейшем этот массив байт будет возможно непосредственно считать в память и отобразить на экране, не прибегая к временным фалам не диске. Но дело в том, что часто это требует существенной доработки уже существующего программного обеспечения. И проще, по крайней, мере на начальном этапе внедрения системы защиты, за счет некоторого понижения степени надежности, быстро модифицировать уже имеющуюся программу. Эта может быть весьма важным моментом. Как только файл будет отображен на экране, этот временный файл можно тут же стереть.
Описание используемых параметров:
handle – дескриптор файла для чтения.
FileName – имя файла добавляемого в зашифрованное хранилище.
read – возвращает размер прочитанных данных в байтах.
HRESULT ToFile(
[in] short handle,
[in] BSTR FileName,
[out, retval] long *written);
Функция ToFile производит обратное действие относительно FromFile. Она извлекает файл из хранилища.
Описание используемых параметров:
handle – дескриптор файла для чтения.
FileName – имя извлекаемого файла.
written – возвращает размер записанных данных в байтах.
Интерфейс IProtectConformity объединяет набор вспомогательных функций, призванных облегчить использование системы с большим количеством файлов, с алгоритмами и зашифрованными данными. Например, возьмем АРМ преподавателя. В этой системе может быть большое количество различных данных, связанных с определенными студентами. Если эти данные зашифрованы, то необходимо знать, каким именно файлом с алгоритмом это сделано. Все эти взаимосвязи необходимо хранить. В случае, если такая система написана с использованием СУБД, сложностей возникнуть не должно. Если же нет, то придется вносить некоторую дополнительную функциональность, которая является подмножеством возможности СУБД. Чтобы облегчить адаптацию таких проектов, не использующих БД, предназначены функции описываемого интерфейса. Фактически, они позволяют строить и работать с таблицами соответствий. Такая таблица представляет собой набор пар, содержащий имя зашифрованного файла и имя соответствующего файла алгоритма для шифрования или расшифрования. В такой таблице возможен поиск, как по имени зашифрованного файла, так и по имени файла с алгоритмом. В дальнейшем файлы, хранящие информацию о соответствии файлов с данными и соответствующими файлами с алгоритмами, будем называть файлами соответствий. Отметим также, что файлы соответствий тоже подвергаются шифрованию.
interface IProtectConformity : IDispatch
{
[id(1), helpstring("method Create Conformity File")]
HRESULT CreateConformityFile(
[in] BSTR name,
[in] BSTR uptFileNameForRead,
[in] BSTR uptFileNameForWrite,
[in] BSTR ArrayOfStrings);
[id(2), helpstring("method Easy Create Conformity File")]
HRESULT EasyCreateConformityFile(
[in] BSTR name,
[in] BSTR uptFileNameForCreate,
[in] BSTR ArrayOfStrings);
[id(3), helpstring("method Read Conformity File")]
HRESULT ReadConformityFile(
[in] BSTR name,
[in] BSTR uptFileNameForRead,
[out, retval] BSTR *ArrayOfStrings);
[id(4), helpstring("method Get UptAlgName by FileName")]
HRESULT GetAlgName(
[in] BSTR Strings,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
[id(5), helpstring("method Get FileName by UptAlgName")]
HRESULT GetDataName(
[in] BSTR Strings,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
[id(6), helpstring("method Get UptAlgName by FileName From File")]
HRESULT GetAlgFromFile(
[in] BSTR FileName,
[in] BSTR uptFileNameForRead,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
[id(7), helpstring("method Get FileName by UptAlgName From File")]
HRESULT GetDataFromFile(
[in] BSTR FileName,
[in] BSTR uptFileNameForRead,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
};
Теперь опишем каждую из функций интерфейса IProtect.
HRESULT CreateConformityFile(
[in] BSTR name,
[in] BSTR uptFileNameForRead,
[in] BSTR uptFileNameForWrite,
[in] BSTR ArrayOfStrings);
Функция CreateConformityFile создает новый файл соответствий и записывает в него соответствующую таблицу. Таблица предается в виде одной строки, в которой последовательно записаны имена файлов. Все нечетные – имена файлов с данными, все четные – соответствующие алгоритмы шифрования или расшифрования. Имена должны быть заключены в двойные кавычки. Это связано с тем, что иначе невозможно работать с именами файлов, содержащими пробелы. Между кавычкой в конце имени одного файла и кавычкой перед именем второго может стоять произвольное количество пробелов и символов табуляции или возврата каретки и переноса строки. Поддержка одновременного хранения информации как о файлах для шифрования, так и для расшифрования не осуществлена. Это сделано по двум причинам. Во-первых, совсем не сложно завести два файла, а интерфейс функций и их количество существенно сокращается. Во-вторых, данная функциональность соответствия двух файлов может быть применена и для других целей. Хочется сделать ее более абстрактной. Следует дать следующий совет если для шифрования большого количества файлов одним алгоритмом: удобно создать соответствующий каталог, в который помещаются шифруемые файлы, записать в файл соответствий имя этого каталога и соответствующий алгоритм шифрования/расшифрования для работы с файлами в этом каталоге.
Файлы с алгоритмом шифрования и расшифрования для работы с файлом соответствий будут автоматически созданы, и будут иметь имена переданные в качестве аргументов функции.
Описание используемых параметров:
name – имя создаваемого файла, для хранения информации о соответствии.
uptFileNameForRead – имя создаваемого файла с алгоритмом расшифрования.
uptFileNameForWrite – имя создаваемого файла с алгоритмом шифрования.
ArrayOfStrings – строка с информацией о соответствиях.
HRESULT EasyCreateConformityFile(
[in] BSTR name,
[in] BSTR uptFileNameForCreate,
[in] BSTR ArrayOfStrings);
Функция EasyCreateConformityFile подобна функции CreateConformityFile, но в отличие от нее, не создает новые файлы с алгоритмами шифрования и расшифрования. Она использует уже существующий алгоритм шифрования.
name – имя создаваемого файла, для хранения информации о соответствии.
uptFileNameForCreate – имя файла с алгоритмом шифрования.
ArrayOfStrings – строка с информацией о соответствиях.
HRESULT ReadConformityFile(
[in] BSTR name,
[in] BSTR uptFileNameForRead,
[out, retval] BSTR *ArrayOfStrings);
Функция ReadConformityFile читает содержимое файла соответствий и возвращает его в виде строки. Строка имеет тот же формат, что и передаваемая например в функцию CreateConformityFile.
Описание используемых параметров:
name – имя зашифрованного файла c информацией о соответствиях.
uptFileNameForRead – имя файла с алгоритмом расшифрования.
ArrayOfStrings – возвращаемая строка с информацией о соответствиях.
HRESULT GetAlgName(
[in] BSTR Strings,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
Функция GetAlgName, используя имя файла с данными, возвращает соответствующий алгоритм шифрования или расшифрования. Поиск производится в переданной строке. Формат строки эквивалентен формату, с которым работают и другие функции. Например, EasyCreateConformityFile или ReadConformityFile.
Описание используемых параметров:
Strings – строка с информацией о соответствиях.
SearchName – имя файла с данными, для которого будет произведен поиск соответствующего алгоритма.
ResultStr – возвращаемое имя файла с алгоритмом.
HRESULT GetDataName(
[in] BSTR Strings,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
Функция GetDataName, используя имя файла с алгоритмом, возвращает имя соответствующего файла с данными. Поиск производится в переданной строке. Формат строки эквивалентен формату, с которым работаю и другие функции. Например EasyCreateConformityFile или ReadConformityFile.
Описание используемых параметров:
Strings – строка с информацией о соответствиях.
SearchName – имя файла с алгоритмом, для которого будет произведен поиск соответствующего файла с данными.
ResultStr – возвращаемое имя файла с данными.
HRESULT GetAlgFromFile(
[in] BSTR FileName,
[in] BSTR uptFileNameForRead,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
Функция GetAlgFromFile, подобно функции GetAlgName, возвращает соответствующий алгоритм шифрования или расшифрования по имени файла с данными. В отличие от нее, на входе она получает не строку с информацией о соответствиях, а имя с этой информацией и алгоритм для ее расшифрования. Функция может быть более удобна в плане ее использования, но она менее эффективна. Так, если требуется активно работать с таблицами соответствий, то для ускорения работы рекомендуется отказаться от использования функции GetAlgFromFile. Эффективнее будет однократно прочитать информацию о соответствиях, используя функцию ReadConformityFile, а затем использовать функцию GetAlgName.
Описание используемых параметров:
FileName – имя файла с зашифрованной информацией о соответствиях.
uptFileNameForRead – файл с алгоритмом расшифрования.
SearchName – имя файла с данными, для которого будет произведен поиск соответствующего алгоритма.
ResultStr – возвращаемое имя файла с алгоритмом.
HRESULT GetDataFromFile(
[in] BSTR FileName,
[in] BSTR uptFileNameForRead,
[in] BSTR SearchName,
[out, retval] BSTR *ResultStr);
Функция GetDataFromFile, подобно функции GetDataName, возвращает имя соответствующего файла с данными, по имени файла с алгоритмом. В отличии от нее, на входе она получает не строку с информацией о соответствиях, а имя с этой информацией и алгоритм для ее расшифрования. Функция может быть более удобна в плане ее использования, но она менее эффективна. Так, если требуется активно работать с таблицами соответствий, то для ускорения работы рекомендуется отказаться от использования функции GetDataFromFile. Эффективнее будет однократно прочитать информацию о соответствиях, используя функцию ReadConformityFile, а затем использовать функцию GetDataName.
Описание используемых параметров:
FileName – имя файла с зашифрованной информацией о соответствиях.
uptFileNameForRead – файл с алгоритмом расшифрования.
SearchName – имя файла с алгоритмом, для которого будет произведен поиск соответствующего файла с данными.
ResultStr – возвращаемое имя файла с данными.
4.3. Руководство программиста по использованию программы ProtectEXE.exe
Программа ProtectEXE.EXE предназначена для защиты исполняемых файлов от модификации. Под исполняемыми модулями понимаются EXE файлы в формате PE (Portable Executables). Защита исполняемых модулей основана на их шифровании. Особенностью утилиты ProtectEXE является то, что она шифрует каждый исполняемый файл уникальным полиморфным алгоритмом. Это затрудняет возможность использования программного взломщика, основанного на модификации определенных кодов в программе. Поскольку каждый исполняемый файл зашифрован своим методом, то и модифицировать их единым методом невозможно. Утилита ProtectEXE.EXE не позволяет защититься от динамического модифицирования в памяти. Это слишком сложно и не может быть достигнуто без существенной переделки исходного текста самой защищаемой программы. Но в рамках защиты дистанционных средств обучения такая защита должна быть достаточно эффективна, так как создание взламывающей программы экономически мало целесообразно, а следовательно и скорее всего не будет осуществлено.
Модуль ProtectEXE.EXE имеет два возможных режима запуска. Первый режим предназначен для генерации зашифрованного файла из указанного исполняемого модуля. Второй режим служит непосредственно для запуска защищенного модуля.
Опишем этап создания зашифрованного файла. Для создания зашифрованного файла необходимо запустить ProtectEXE.EXE, указав в качестве параметра имя шифруемого исполняемого файла. Можно указать не только имя, но и путь. В результате буду сгенерированы два файла. Если было указано только имя, то файлы будут располагаться в текущем каталоге. Если был указан путь к файлу, то сгенерированные файлы будут созданы в том же каталоге, где расположен и шифруемый файл. Первый файл будет иметь расширение upb. Он представляет собой непосредственно зашифрованный исполняемый файл. Второй файл будет иметь расширение upu. Он представляет собой ключ, необходимый для расшифровки исполняемого файла. При разработке ProtectEXE было принято решение хранить зашифрованный файл и ключ для его расшифровке не в едином файле, а раздельно. Это было сделано с целью большей гибкости. Если хранить все в одном файле, это будет означать, что его всегда будет возможно запустить. Раздельное хранение ключа позволяет создавать систему, где запуск определенных программ будет запрещен. Например, программа дистанционного обучения может позволять запускать набор определенных программ только тогда, когда будет выполнен ряд условий. Допустим, после сдачи определенного набора работ. Когда определенные работы будет сданы и защищены, АРМ преподавателя выдает студенту необходимые для дальнейшей работы ключевые файлы. Можно было бы, конечно, выдавать сразу расшифрованный бинарный файл, но программа может быть достаточно большой, и это просто нерационально. И, тем более, тогда нет никаких сложностей скопировать ее другому студенту, которому она еще не должна быть выдана.
Теперь опишем второй режим работы. Это непосредственно запуск зашифрованного модуля. Для его запуска необходимо запустить ProtectEXE, указав в качестве параметра путь и имя зашифрованного файла с расширением upb. Если будет найден ключевой файл с тем же именем, но с расширением upu, то программа будет запущена. При этом будет создан временный файл с расширением exe. Он будет располагаться в том же каталоге, где нахолодятся фалы с расширением upb и upu. Этот файл является временным и будет удален после завершения работы программы. Данный файл, хоть и носит расширение exe, не является исполняемым файлом. В чем можно убедиться, попытавшись запустить его. Результатом будет его зависание. Поэтому не следует бояться, что это расшифрованный файл, и студент сможет скопировать его, когда он будет создан.
4.4. Описание использования системы защиты на примерах
4.4.1. Подключение модуля защиты к программе на языке Visual C++
Распишем шаги, которые наобходимо проделать, чтобы подключить COM модуль Uniprot к программе, написанной на Visual C++.
Создайте новый или откройте уже существующий проект.
Создайте новую папку в каталоге с проекта или выберете уже существующую и скопируйте в нее необходимые для подключения библиотеки файлы. Это файлы: export.h, export.cpp, Uniprot.tlb.
Откройте MFC ClassWizard. Для этого выбирете в меню пункт
View->ClassWizard.Нажмите на кнопку Add Class и выберете пункт "From a type library…".
Укажите путь к файлу Uniprot.tlb и откройте его.
В диалоге Confirm Classes вам скорее всего будет достаточно сразу нажать кнопку "Ok". Но если вы не согласны с продложенными установками по умолчанию, то можете внести в них соответсвующие изменения.
Закройте диалог MFC ClassWizard.
Включите в проект файлы export.h, export.cpp.
Добавить include "export.h" в те модуле, где вы планируете использовать библиотеку Uniprot.
Проверьте, что у вас инициализируется работа с COM. То есть вызывается функция CoInitialize.
Теперь вы можете работать с библиотекой COM например так.
IProtect ProtectObj;
IProtectFile ProtectFileObj;
ProtectObj.CreateDispatch(UniprotLibID);
ProtectFileObj.CreateDispatch(UniprotLibID);
LPDISPATCH pDisp = ProtectFileObj.m_lpDispatch;
HRESULT hr = pDisp ->QueryInterface(
IProtectFileIntarfaceID,
(void**)&ProtectFileObj.m_lpDispatch);
VERIFY(hr == S_OK);
4.4.2. Подключение модуля защиты к программе на языке Visual Basic
Распишем шаги, которые наобходимо проделать, чтобы подключить COM модуль Uniprot к программе, написанной на Visual Basic.
Создайте новый или откройте уже существующий проект.
Создайте новую папку в каталоге с проекта или выберете уже существующую и скопируйте в нее необходимый для подключения библиотеки файл. Это файл: Uniprot.tlb.
Откройте диалог References. Для этого выбирете в меню пункт
Project->References.Нажмите кнопку Browse.
Укажите файл Uniprot.tlb и откройте его.
Поставьте в списке галочку напротив появившейся строки Uniprot 1.0 Type Library и нажмите Ok.
Теперь вы можете работать с библиотекой COM например так.
Dim handle As Integer
Dim obj As New protect
Dim ver As Integer
Dim strInfo As String
obj.GetInfo ver, strInfo
Dim s As String
s = "Version:" + Str(ver / 256) + "." +
Str((ver Mod 256) / 16) + Str(ver Mod 16)
s = s + Chr(13) + "Info:" + strInfo
MsgBox s
Dim file As IProtectFile
Set file = obj
handle = file.Create(FileName, Default, cryptUPT)
4.4.3. Пример использования модуля защиты в программе на языке Visual Basic
Рассмотрим несколько демонстрационных программах. Представим, что у нас существует комплекс, состоящий из двух частей. Первая из которых предназначена для преподавателя, а другая – для студента. В дальнейшем будем называть их соответственно "АРМ преподавателя" и "АРМ студента". АРМ преподавателя предназначена для составления вопросов и просмотра результатов тестирования. А АРМ студента предназначена для контроля знаний. Естественно, примеры данных программ будут очень упрощены.
Для начала приведем текст программы АРМ преподавателя без использования защиты. На рисунке 8 показан ее пользовательский интерфейс.
|
Private Sub Edit_Click() orm1.ole_doc.DoVerb End Sub Private Sub Form_Load() Form1.ole_doc.Format = "Rich Text Format" End Sub Private Sub Load_Click() Open "c:\temp\temp.rtf" For Input As #1 Dim str, tmp Do While Not EOF(1) Input #1, tmp str = str + tmp Loop Close #1 Form1.ole_doc.DoVerb vbOLEDiscardUndoState Form1.ole_doc.DataText = str Form1.ole_doc.Update End Sub Private Sub Save_Click() Dim msg Form1.ole_doc.DoVerb vbOLEDiscardUndoState msg = Form1.ole_doc.DataText Open "c:\temp\temp.rtf" For Output As #1 Print #1, msg Close #1 End Sub Private Sub ViewResult_Click() Open "c:\temp\result.txt" For Input As #1 Dim n As Integer Input #1, n Close #1 result = n End Sub |
Рисунок 8. Интерфейс АРМ преподавателя |
Итак, данная программа позволяет загрузить текст вопроса из файла, отредактировать его и опять сохранить. На практике, естественно, кроме этого должен существовать механизм генерации пакета программ и данных для студента. Т.е. в этот пакет, по всей видимости, должны входить АРМ студента, база данных и т.д. В нашем примере мы это опускаем и предполагаем, что сохраненный текст – все, что необходимо. Эта программа позволяет просмотреть файл с результатом тестирования по заданному вопросу. Это файл генерирует АРМ студента. Он представляет собой файл, в котором записано число – оценка за вопрос. Недостатки данной программы мы рассмотрим чуть ниже, когда познакомимся с АРМ студента. На рисунке 9 показан ее внешний вид.
|
Private Sub SaveResult(a) Open "c:\temp\result.txt" For Output As #1 Print #1, a Close #1 End End Sub Private Sub Command1_Click(Index As Integer) SaveResult (2) End Sub Private Sub Command2_Click() SaveResult (2) End Sub Private Sub Command3_Click() SaveResult (5) End Sub Private Sub Command4_Click() SaveResult (2) End Sub Private Sub Form_Load() Form1.ole_doc.Format = "Rich Text Format" Open "c:\temp\temp.rtf" For Input As #1 Dim str, tmp Do While Not EOF(1) Input #1, tmp str = str + tmp Loop Close #1 Form1.ole_doc.DoVerb vbOLEDiscardUndoState Form1.ole_doc.DataText = str Form1.ole_doc.Update End Sub |
Рисунок 9. Интерфейс АРМ студента |
Как видно эта программа очень проста. Она просто выводит текст вопроса и ждет ответ. После чего записывает оценку в файл. На рисунке 10 показано, как выглядит файл с результатом.
Рисунок 10. Файл с незашифрованным результатом
Естественно, такая система не выдерживает никакой критики с точки зрения защиты. Во-первых, файл с вопросом представляет из себя простой RTF-файл. Конечно, если эти файлы будут храниться в защищенной базе, то проблем не возникнет. Мы же предполагаем, что пока они хранятся открыто. Предположим, что таких файлов много, и недопустимо, чтобы студент имел к ним доступ. Соответственно, это одно из мест, где потребуется модуль защиты. Второе, пожалуй, еще более важное место – это файл с результатом. На данный момент это просто текстовый файл, с числом, обозначающий оценку. Хранение результата в таком виде как просто, так и недопустимо.
Теперь, используя модуль зашиты, мы исправим перечисленные недостатки. Для начала покажем новый интерфейс пользователя и объясним изменения. Кнопки "Загрузить текст", "Сохранить текст" остались, но теперь программа будет работать с зашифрованными данными. Кнопка "Импорт старых данных" предназначена для чтения незашифрованного файл с вопросом.
Кнопка "Сгенерировать пакет" генерирует 4 алгоритма. Первая пара алгоритмов шифрования/расшифрования используется для записи/чтения файла с вопросом. При этом студенту достаточно отдать только файл с алгоритмом расшифрования. Вторая пара используется при работе с файлом, содержащим результат тестирования. Алгоритм шифрования предназначен для АРМ студента. Алгоритм расшифрования относится к АРМ преподавателя и служи для расшифрования этого файла. Передача студенту только некоторых алгоритмов повышает надежность защиты.
Новый интерфейс АРМ преподавателя изображен на рисунке 11.
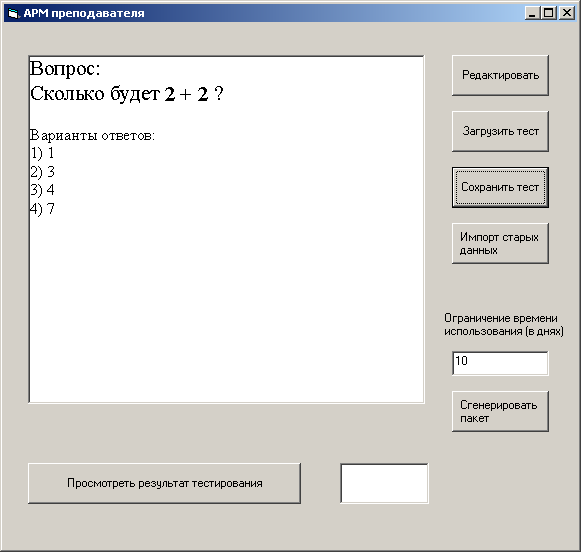
Рисунок 11. Новый интерфейс АРМ преподавателя
Рассмотрим, какие изменения понадобилось внести в программу. Их совсем не много. Добавилась глобальная перемеренная obj. Она предназначена для взаимодействия с COM-модулем. Глобальной она быть совсем не обязана, просто это было сделано для краткости программы. Типом этой переменный является указатель на интерфейс IProtect. Но использовать этот интерфейс для шифрования/расшифрования не представляется возможным. Поэтому, в дальнейшем obj будем преобразовывать этот указатель к указателю на интерфейс IProtectFile.
Dim obj As New protect
Private Sub Edit_Click()
Form1.ole_doc.DoVerb
End Sub
Private Sub Form_Load()
Form1.ole_doc.Format = "Rich Text Format"
End Sub
Данная подпрограмма предназначена для генерации 4 алгоритмов шифрования/расшифрования. Для простоты она записываются во временную папку. Причем, генерируемые алгоритмы будут ограничены в использовании по времени. Файл "c:\temp\crypt.upt" и "c:\temp\decrypt.upt" предназначены для работы с файлом содержащим вопрос. Файл "c:\temp\cryptres.upt" и "c:\temp\decryptres.upt" предназначены для работы с фалом результата. Следовательно для работы АРМ-преподавателя необходимы файлы "c:\temp\crypt.upt" , "c:\temp\decrypt.upt" и "c:\temp\decryptres.upt". А для АРМ-студента необходимы файлы "c:\temp\decrypt.upt", "c:\temp\cryptres.upt".
Private Sub Generate_Click()
Dim days As Integer
days = DaysLimit
obj.GenerateTimeLimitUPTfiles "c:\temp\crypt.upt", "c:\temp\decrypt.upt", days
obj.GenerateTimeLimitUPTfiles "c:\temp\cryptres.upt", "c:\temp\decryptres.upt", days
End Sub
Эта подпрограмма фактически является старой подпрограммой загрузки файла с вопросом. Она служит для импорта данных в старом формате чтобы не набирать же вопрос заново.
Private Sub Import_Click()
Open "c:\temp\temp.rtf" For Input As #1
Dim str, tmp
Do While Not EOF(1)
Input #1, tmp
str = str + tmp
Loop
Close #1
Form1.ole_doc.DoVerb vbOLEDiscardUndoState
Form1.ole_doc.DataText = str
Form1.ole_doc.Update
End Sub
Вот новая подпрограмма чтения текста вопроса из файла. Дадим комментарии к некоторым строчкам.
Dim file As IProtectFile – объявляет указатель на интерфейс IProtectFile, который позволяет шифровать/расшифровывать файлы.
handle = file.Open("c:\temp\temp.dat", "c:\temp\decrypt.upt", "c:\temp\crypt.upt") – открываем файл с вопросом и сохраняем дескриптор открытого файла.
readSize = file.Read(handle, v) – читаем переменную типа Variant, которая на самом деле будет представлять из себя строку.
file.Close (handle) – закрывает файл.
Private Sub Load_Click()
Dim handle As Integer
Dim file As IProtectFile
Set file = obj
handle = file.Open("c:\temp\temp.dat", "c:\temp\decrypt.upt", "c:\temp\crypt.upt")
Dim readSize As Long
Dim v As Variant
readSize = file.Read(handle, v)
Dim str As String
str = v
Form1.ole_doc.DoVerb vbOLEDiscardUndoState
Form1.ole_doc.DataText = str
Form1.ole_doc.Update
file.Close (handle)
End Sub
Вот как теперь выглядит новая подпрограмма сохранения вопроса в файл.
Private Sub Save_Click()
Dim handle As Integer
Dim file As IProtectFile
Set file = obj
handle = file.Create("c:\temp\temp.dat", Default, "c:\temp\crypt.upt")
Dim writeSize As Long
Dim v As Variant
Dim str As String
str = Form1.ole_doc.DataText
v = str
writeSize = file.Write(handle, v)
file.Close (handle)
End Sub
И последнее, это новая подпрограмма чтения файлов с результатом тестирования.
Private Sub ViewResult_Click()
Dim handle As Integer
Dim file As IProtectFile
Set file = obj
handle = file.Open("c:\temp\result.dat", "c:\temp\decryptres.upt", "c:\temp\cryptres.upt")
Dim readSize As Long
Dim v As Variant
readSize = file.Read(handle, v)
Dim str As String
result = v
file.Close (handle)
End Sub
Внешний вид АРМ студента не изменился. Приведем только текст программы.
Dim obj As New protect
Private Sub SaveResult(a)
Dim handle As Integer
Dim file As IProtectFile
Set file = obj
handle = file.Create("c:\temp\result.dat", Default, "c:\temp\cryptres.upt")
Dim writeSize As Long
Dim v As Variant
Dim str As String
str = Form1.ole_doc.DataText
v = a
writeSize = file.Write(handle, v)
file.Close (handle)
End
End Sub
Private Sub Command1_Click(Index As Integer)
SaveResult (2)
End Sub
Private Sub Command2_Click()
SaveResult (2)
End Sub
Private Sub Command3_Click()
SaveResult (5)
End Sub
Private Sub Command4_Click()
SaveResult (2)
End Sub
Private Sub Form_Load()
Form1.ole_doc.Format = "Rich Text Format"
Dim handle As Integer
Dim file As IProtectFile
Set file = obj
handle = file.Open("c:\temp\temp.dat", "c:\temp\decrypt.upt", "c:\temp\crypt.upt")
Dim readSize As Long
Dim v As Variant
readSize = file.Read(handle, v)
Dim str As String
str = v
Form1.ole_doc.DoVerb vbOLEDiscardUndoState
Form1.ole_doc.DataText = str
Form1.ole_doc.Update
file.Close (handle)
End Sub
Для примера на рисунке 12 приведен пример зашифрованного файла с результатом тестирования. Теперь понять, что в нем хранится, стало сложным делом.
Рисунок 12. Файл с зашифрованным результатом
4.4.4. Пример использования программы ProtectEXE.exe
В качестве примера приведем код на Visual С++, который производит шифрование исполняемого файла, а затем код, производящий запуск зашифрованного файла. Обе функции принимают на входе имя файла с расширение exe. Для большей ясности рекомендуется ознакомиться с приведенным ранее описанием программы ProtectEXE.
void CreateEncryptedModule(const CString &FileName)
{
CString Line(_T("ProtectExe.exe "));
Line += FileName;
STARTUPINFO StartupInfo;
memset(&StartupInfo, 0, sizeof(StartupInfo));
StartupInfo.cb = sizeof(StartupInfo);
PROCESS_INFORMATION ProcessInformation;
if (!CreateProcess(Line, NULL, NULL, NULL, FALSE, 0,
FALSE, NULL, &StartupInfo,
&ProcessInformation))
throw _T("Error run ProtectExe.exe");
WaitForInputIdle(ProcessInformation.hProcess,
INFINITE);
WaitForSingleObject(ProcessInformation.hProcess,
INFINITE);
CloseHandle(ProcessInformation.hProcess);
DeleteFile(FileName);
}
void RunEncryptedModule(const CString &FileName)
{
CString EncryptedFileName(FileName);
EncryptedFileName = EncryptedFileName.Mid(0, FileName.GetLength() - 3);
EncryptedFileName +=_T("upb");
CString Line(_T("ProtectExe.exe"));
Line += EncryptedFileName;
STARTUPINFO StartupInfo;
memset(&StartupInfo, 0, sizeof(StartupInfo));
StartupInfo.cb = sizeof(StartupInfo);
PROCESS_INFORMATION ProcessInformation;
if (!CreateProcess(Line, NULL, NULL, NULL, FALSE, 0,
FALSE, NULL, &StartupInfo, &ProcessInformation))
throw _T("Error run ProtectExe.exe");
WaitForInputIdle(ProcessInformation.hProcess, INFINITE);
WaitForSingleObject(ProcessInformation.hProcess, INFINITE);
CloseHandle(ProcessInformation.hProcess);
}
4.5. Общие рекомендации по интеграции системы защиты
В данном разделе будет дан ряд различных советов и рекомендаций, целью которых является помощь в создании более надежной и эффективной системы защиты. Рекомендации носят разрозненный характер и поэтому не объединены в единый и связанный текст, а будут приведены отдельными пронумерованными пунктами.
1. Перед началом работ по модификации существующего программного обеспечения с целью интеграции системы защиты рекомендуется тщательно ознакомиться с приведенной документацией и с примерами по использованию различных функций. Также необходимым требованием перед началом работ, является базовые навыки работы с технологией COM. Если вы не знакомы с технологией COM, то здесь можно порекомендовать в качестве литературы по данной теме следующие книги: Модель COM и применение ATL 3.0 [31], Сущность технологии COM. [33], Programming Distributed Applications with COM and Microsoft Visual Basic 6.0 [34].
2. Перед тем как приступать непосредственно к созданию программных средств или их модификации, призванных защитить целевую систему, в начале следует продумать административную организацию бедующей системы. Как говорилось ранее, множество различных проблем, связанных с защитой АСДО, могут быть разрешены только административными методами. И пока не будет разработана соответствующая организационная система, программная защита отдельных ее компонентов будет иметь мало смысла. Отсюда и вытекает данная рекомендация уделить этой задаче большое внимание, даже больше, чем следует уделить защите используемых в ней программных компонентов. К сожалению, в этой работе вопросы административной организации такой системы практически не затрагиваются. Это связано с тем, что задача сама по себе огромна и требует отдельного целого ряда работ. Причем направленность этого рода работ носит, скорее, педагогический характер, и, следовательно, относится к соответствующей сфере педагогических наук. В проделанной же работе подготовлены средства, которые необходимы и будут использованы в новых или адаптируемых АСДО.
3. Во многих системах дистанционного обучения используются различные принципы, с помощью которых возможно отказаться от хранения ответов в открытом виде. Это позволяет быть уверенным, что ответы для базы вопросов никогда не будут просмотрены. В основном такие системы построены на использовании функции, которая односторонне преобразует ответ в некий код, затем сравниваемый с эталонными. Разработанная система защиты легко позволяет использовать аналогичный механизм. Для этого достаточно создать ключ шифрования. Ключ расшифрования не нужен, его можно удалить. Затем каждый верный ответ отдельно шифруется этим ключом. В результате получается набор файлов с зашифрованными ответами. После чего их будет удобно объединить в один единый файл, но это уже зависит от того, как будет реализовываться такая система. Затем этот файл, содержащий в себе зашифрованные ответы и ключ шифрования, отдается студенту. Когда студент вводит ответ, он шифруется отданным ему ключом. После чего зашифрованный файл с ответом сравнивается с эталонным. Если они совпадают, ответ верен. В результате, хотя ответы и хранятся у студента, воспользоваться он ими не может. Если кто-то поставит пред собой цель узнать, какие ответы верны, то нужно или перебирать все варианты, шифруя их и сравнивая, что весьма трудоемко, или провести анализ полиморфного алгоритма шифрования и создать соответствующий алгоритм расшифрования, что еще более трудоемко.
4. Еще одной из рекомендаций будет создание системного журнала. По этому поводу рекомендуется ознакомиться со статьей Оганесяна А. Г. " Проблема «шпаргалок» или как обеспечить объективность компьютерного тестирования?" [28].
5. Создавая АСДО, позаботьтесь о дублировании информации. В противном случае, уничтожение, например, базы с данными о сданных работах может иметь весьма тяжелые последствия. Это – совет не относится к защите информации, но может помочь весьма повысить надежность системы в целом.
ОСНОВНЫЕ ВЫВОДЫ И РЕЗУЛЬТАТЫ
1. Выполнен сравнительный анализ существующих подходов к организации защиты данных в системах с монопольным доступом, на примере автоматизированных систем дистанционного обучения. Отмечено, что существует много защищенных обучающие систем, функционирующих в среде интернет, но практически отсутствуют защищенные пакеты для локального использования. Это обусловлено плохо проработанными и еще не достаточно хорошо изученными методами построения защищенных АСДО.
2. На основе анализа, предложен ряд мер, позволяющий повысить защищенность АСДО. Разработаны программные средства, предназначенные для интеграции в уже существующие обучающие системы, с целью их защиты при использовании вне доверенной вычислительной среды.
3. В разработанном программном обеспечении были использованы новые технологии шифрования данных. Полностью исключена необходимость использования аппаратных средств.
4. Разработана система защиты, руководство для программиста, набор тестовых примеров и рекомендации по ее применению. Созданная система была интегрирована в уже существующий комплекс Aquarius Education 4.0, разработанный на кафедре АТМ.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Аунапу Т.Ф., Веронская М.В. Автоматизация обучения с позиций системного анализа // Управление качеством высшего образования в условиях многоуровневой подготовки специалистов и внедрения образовательных стандартов: Тез. докладов республиканской научно-методической конференции. — Барнаул: Алт. гос. техн. ун-т, 1996. — С. 5 — 6. д
2. Брусенцов Н.П., Маслов С.П., Рамиль Альварес X. Микрокомпьютерная система «Наставник». — М.: Наука, 1990. — 224 с.
3. Кондратова О.А. Психологические требования к проектированию компьютерных учебных средств и систем обучения // Проблемы гуманизации и новые методы обучения в системе инженерного образования: Тез. докл. межвузовской научно-практической конференции. — Новокузнецк: Сиб. Гос. горно-металлургическая академия, 1995. — С. 78 — 80.
4. Федеральная целевая программа «Развитие единой образовательной информационной среды на 2002 — 2006 годы» (проект). — М.: Минобразования, 2001. — 35 с.
5. Кручинин В.В., Ситникова Е.А. Проблема защиты компьютерных экзаменационных программ в ТМЦ ДО // Современное образование: массовость и качество. Тез. докл. региональной научно-методической конференции. — Томск: ТУСУР, 2001. — С. 144.
6. Махутов Б.Н., Шевелев М.Ю. Защита электронных учебников в дистанционном обучении // Образование XXI века: инновационные технологии, диагностика и управление в условиях информатизации и гуманизации: Материалы III Всероссийской научно-методической конференции с международным участием. — Красноярск: КГПУ, 2001. — С. 106 — 108.
7. Раводин О.М. Проблемы создания системы дистанционного образования в ТУСУРе // Дистанционное образование. Состояние, проблемы, перспективы. Тез. докл. научно- методической конференции, Томск, 19 ноября Э 1997 г. — Томск: ТУ СУР, 1997. — С. 19 — 25.
8. Шевелев М.Ю. Автоматизированный внешний контроль самостоятельной работы студентов в системе дистанционного образования /У Дистанционно образование. Состояние, проблемы, перспективы. Тез. докл. научно-методической конференции. — Томск: ТУСУР, 1997. — С. 49.
9. Шевелев М.Ю. Прибор для дихотомической оценки семантических сообщений в автоматизированных обучающих системах // Современные техника и технологии. Сб. статей международной научно-практической конференции. — Томск: ТПУ, 2000. — С. 152.
10. Шевелев М.Ю. Программно-аппаратная система контроля и защиты информации // Современное образование: массовость и качество. Тез. докл. научно-методической конференции 1-2 февраля 2001 г. — Томск: ТУСУР, 2001.—С. 99—100.
11. Шелупанов А.А., Пряхин А.В. Анализ проблемы информации в системе дистанционного образования // Современное образование: массовость и качество. Тез. докл. региональной научно-методической конференции. — Томск: ТУ СУР, 2001. — С. 159 — 161.
12. Кацман Ю.Я. Применение компьютерных технологий при дистанционном обучении студентов // Тез. докладов региональной научно методической конференции "Современное образование: массовость и качество". – Томск: ТУСУР, 2001. – С.170 – 171.
13. Пресс-группа СГУ. Компьютер-экзаменатор. // Электронный еженедельник "Закон. Финансы. Налоги." – 2000. – № 11 (77).
14. Белокрылова О.С. Использование курса дистанционного обучения на экономическом факультете РГУ // Cовременные информационные технологии в учебном процессе: Тез. докл. Учебно-методическая конференция. – Апрель 2000.
15. Алешин С.В. Принципы построения оболочки информационно – образовательной среды CHOPIN // Новые информационные технологии : Тез. докл. Восьмая международная студенческая школа семинар. – Крым: Алтайский государственный технический университет, Май 2000.
16. Оганесян А.Г. Проблема обратной связи при дистанционном обучении // Открытое образование. – 2002. – март.
17. Занимонец Ю.М., Зинькова Ж.Г. Проведение всероссийского компьютерного тестирования "Телетестинг-2000" в Ростовском госуниверсите // Современные информационные технологии в учебном процессе : Тез. докл. Учебно-методическая конференция. – 2000. – апрель.
18. Сенцов, В.С. Программный комплекс тестового контроля знаний «Тест» // Новые информационные технологии: Тез. докл. Восьмая международная студенческая школа семинар. – Крым: Алтайский государственный технический университет, Май 2000.
19. Мицель. А.А. Автоматизированная система разработки электронных учебников // Открытое образование. – 2001. – май.
20. Жолобов Д.А. Генератор мультимедиа учебников // Новые информационные технологии: Тез. докл. Восьмая международная студенческая школа семинар. – Крым: Астраханский государственный технический университет, Май 2000.
21. Вергазов Р. И., Гудков П. А. Система автоматизированного дистанционного тестирования // Новые информационные технологии: Тез. докл. Восьмая международная студенческая школа семинар. – Крым: Пензенский государственный университет, Май 2000.
22. Ложников П. С. Распознавание пользователей в системах дистанционного образования: обзор // Educational Technology & Society. – 2001. – № 4, http://ifets.ieee.org/russian/depository/v4_i2/html/4.html
23. Расторгуев С.П., Долгин А.Е., Потанин М.Ю. Как защитить информацию // Электронное пособие по борьбе с хакерами. http://kiev-security.org.ua
24. Ерижоков А.А. Использование VMWare 2.0 // Публикация в сети ИНТЕРНЕТ на сервере http://www.citforum.ru/operating_systems/vmware/index.shtml.
25. Баpичев С. Kpиптогpафия без секретов. – М.: Наука, 1998. – 105 с.
26. Маутов Б.Н. Защита электронных учебников на основе программно-аппаратного комплекса "Символ-КОМ" // Открытое образование. – 2001. – апрель.
27. Тыщенко О.Б. Новое средство компьютерного обучения - электронный учебник // Компьютеры в учебном процессе. – 1999. – № 10. – С. 89-92.
28. Оганесян А. Г., Ермакова Н. А., Чабан К. О. Проблема «шпаргалок» или как обеспечить объективность компьютерного тестирования? // «Львіська політехніка». – 2001. – № 6. Публикация в сети ИНТЕРНЕТ на сервере http://www.mesi.ru/joe/N6_00/oga.html.
29. Романенко В.В. Автоматизированная система разработки электронных учебников. // Новые информационные технологии в университетском образовании: Тез. докл. Материалы седьмой Международной Научно-Методической конференции. – Томск: Томский Государственный Университет Систем Управления и Радиоэлектроники, Март 2000.
30. Касперский Е.В. Компьютерные вирусы: что это такое и как с ними бороться. – М.: СК Пресс, 1998. – 288 с., ил.
31. Трельсон Э. Модель COM и применение ATL 3.0: Пер. с англ. – СПб. БХВ-Петербург, 2001. – 928 с. ил.
32. Баричев С. Г. и др. «Основы современной криптографии». – М.: «Горячая линия –Телеком», 2001 – 120 с.
33. Бокс. Д. Сущность технологии COM. Библиотека программиста. – СПб.: Питер, 2001. – 400 с.: ил.
34. Ted Pattison. Programming Distributed Applications with COM and Microsoft Visual Basic 6.0. – Microsoft Press, 1998. – 260 c. ISBN 1-57231-961-5
ТУЛЬСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
На правах рукописи
Карпов Андрей Николаевич
ЗАЩИТА ИНФОРМАЦИИ В СИСТЕМАХ ДИСТАНЦИОННОГО ОБУЧЕНИЯ С МОНОПОЛЬНЫМ ДОСТУПОМ
Направление 553000 - Системный анализ и управление
Программная подготовка 553005 – Системный
анализ данных и моделей принятия решений
АВТОРЕФЕРАТ
диссертации на соискание степени
магистра техники и технологии
Тула 2004
Работа выполнена на кафедре автоматики и телемеханики
Тульского государственного университета
Научный руководитель
д.т.н. Богатырев М.Ю. _____________
Консультатнт
к.т.н. проф. Теличко Г.Н. _____________
Защита диссертации состоится 16 июня 2004 г. в 10 ч. 00 мин.
Секретарь ГАК
кандидат технических наук, доцент Спицын А.В.
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность темы. В последнее время много проблем разработчикам и пользователям программного обеспечения доставляют проблемы информационной безопасности. Вопросы защиты информации весьма обширны, поэтому в данной работе будет рассмотрена защита автоматизированных систем дистанционного обучения (АСДО). Они являются удачным образцом систем, функционирующих в режиме монопольного доступа вне доверительной среды. Под монопольным доступом понимается возможность пользователя совершать с программой любые действия без внешнего контроля. Для систем, функционирующих вне доверительной среды, характерны следующие задачи информационной безопасности: защита от несанкционированного копирования, защита от модификации программного кода, сокрытие от пользователя части информации и ряд других задач. Это отмечают Алешин С. В., Белокрылова О.С., Жолобов Д.А., Мицель А.А., Оганесян А.Г., Шевелев М.Ю и другие авторы в работах, посвященных защите информации в АСДО.
Объект исследования – автоматизированная система дистанционного обучения.
Предмет исследования – организация защиты информации для систем с монопольным режимом доступа, функционирующих вне доверительной среды.
Цель работы. Целью диссертационной работы является анализ методов защиты информации без использования вспомогательных аппаратных средств и создание интегрируемого пакета программных модулей для защиты систем, функционирующих в монопольном режиме вне доверенной вычислительной среды.
Гипотеза исследования – возможность использования механизма полиморфных алгоритмов шифрования для предотвращения массовых попыток взлома автоматизированных систем дистанционного обучения.
Задачи исследования. Для достижения поставленной цели в диссертационной работе на примере АСДО сформулированы и решены следующие задачи:
1. Выделены основные ключевые объекты, подлежащие защите.
2. Разработаны методы защиты АСДО вне доверенной вычислительной среды от массовых попыток модификации кода.
3. Разработаны методы защиты данных для систем обучения и контроля знаний вне доверенной вычислительной среды.
4. Проведен анализ и предложены возможные способы применения разработанных методов.
Методы исследования. Исследования базируются на анализе работ посвященных вопросам защиты информации, и на работах, связанных с защитой обучающих программных комплексов.
Теоретические результаты – предложены новые методы защиты автоматизированных систем дистанционного обучения, основанные на использовании полиморфных алгоритмов.
Практическая ценность.
1. Разработаны эффективные методы защиты систем дистанционного обучения вне доверенной вычислительной среды.
2. Основываясь на разработанном методе полиморфных алгоритмах шифрования, были предложены механизмы, препятствующие созданию универсальных средств обхода системы защиты.
3. Разработанные методы не нуждаются в аппаратных средствах для своей реализации.
4. Возможность легкой интеграции созданной системы защиты в уже существующие программные комплексы дистанционного обучения.
Реализация – система защиты была интегрирована в программный комплекс Aquarius Education 4.0, созданный на кафедре АТМ под руководством Юхименко Александра и представляющий собой систему автоматизированного тестирования.
Область применения – сфера образования
Публикации. По теме диссертации опубликованы две научных работы.
Структура и объем работы. Диссертация состоит из введения, четырех глав, заключения, списка литературы и приложения. Материал изложен на 168 страницах, содержит 12 рисунков, одну таблицу и список литературы из 34 наименований.
ОСНОВНОЕ СОДЕРЖАНИЕ РАБОТЫ
Во введении сказано о выборе в качестве темы диссертационной работы, вопросов защиты информации, применительно к системам с монопольным доступом. А также о выборе в качестве объекта исследования автоматизированных систем обучения и актуальности данного направления исследований.
В первой главе рассмотрены трудности разработки автоматизированных систем дистанционного обучения с точки зрения их защиты. Проведен обзор публикаций по данной тематике, выделены задачи, возлагаемые на разрабатываемую систему защиты.
Все большее внимание уделяется новому направлению в образовании – дистанционному обучению. Одной из задач при построении АСДО является их защита. Примером может служить установление достоверности результатов компьютерного тестирования. Сюда же относится проблема построения системы разграничения доступа в различных программных комплексах, предназначенных для автоматизации процесса обучения. Рассмотрим часто встречающуюся на данный момент ситуацию. На кафедре создана система, включающая виртуального лектора и подсистему тестирования. В случае использования данной системы в аудиториях кафедры никаких сложностей не возникает, так как студенты находятся под контролем преподавательского состава. Но ориентация образования в сторону дистанционного обучения вносит свои коррективы. Возникает потребность в возможности использования данного программного обеспечения студентом на своей локальной машине. Такая задача может быть решена (и решается достаточно хорошо) с использованием сетевых технологий. В такой системе студент заходит на сайт, где он может заниматься обучением или проходить различные виды тестирования. Но такая система неудобна тем, что требует постоянного подключения к сети, влечет немалые финансовые затраты, вынуждена ограничивать учебный материал. Например, придется ограничиться картинкой там, где совсем бы не помешало показать видеоролик. Отсюда возникает потребность сделать эту систему автономной, с возможностью распространения ее на таких носителях, как CD-ROM.
Сформулируем основные проблемы, связанных с защитой и рядом других вопросов, относящихся к системам дистанционного обучения.
1. Отсутствие возможности достоверно определить, прошел ли студент тестирование самостоятельно. Для этой задачи он вполне мог использовать другого человека (например, более подготовленного студента).
2. Неизвестно, сколько раз студент предпринял попытку пройти тестирование. Студент имеет возможность устанавливать систему дистанционного обучения в нескольких экземплярах и/или копировать ее, тем самым сохраняя ее текущее состояние. Так, студент получает возможность неограниченного количества попыток прохождения тестирования и возможность выбрать из них попытку с наилучшим результатом.
3. Существует возможность создания универсального редактора файлов результатов тестирования. Он может использоваться студентом для корректировки оценок выставленных программой тестирования.
4. Существует возможность создания универсальной программы просмотра файлов с заданиями и ответами. Тем самым, студент имеет возможность узнать верные ответы на вопросы в тестах.
5. Возможность модификации программного кода системы тестирования, с целью изменения алгоритма выставления оценок.
6. Необходима возможность легкой адаптации уже существующих систем дистанционного обучения и тестирования. Это в первую очередь связанно с тем, что к этим системам уже существуют базы с лекциями, тестовыми заданиями и так далее.
Практически все ВУЗы заняты созданием своих систем дистанционного обучения. В интернете имеется огромное количество информации по этим разработкам. Интересно, что говоря о преимуществах той или иной системы, обычно умалчивается о том, каким образом система защищена, из чего можно сделать вывод о плохой проработке данного вопроса. К сожалению, в рамках автореферата невозможно предоставить развернутый обзор каждого из перечисленных вопросов, поэтому приведем только несколько ссылок, чтобы подчеркнуть актуальность и необходимость работы в выбранном направлении.
В статье "Проблема обратной связи при дистанционном обучении." А.Г. Оганесян отмечает, что система дистанционного образования должна иметь достаточные средства защиты от несанкционированного вмешательства и подмены реальных студентов их дублерами. Далее говорится, что проблема идентификации студентов – дистанщиков, кажется вообще не имеет решения. Действительно, пароли и иные атрибуты личной идентификации проблемы не решают, т.к. студент заинтересован заменить себя дублером и располагает неограниченными возможностями такой подмены. Техническое решение для ее обнаружения придумать пока не удалось. А вот организационные, похоже, есть. Выход может быть в создании постепенного контроля знаний, с целью формирования трудностей для подмены проходящего тестирование дублером. Ведь найти дублера на один экзамен намного проще, чем на весь период обучения.
В некоторых работах отмечается, что примененние системы защиты может иметь негативные стороны. В тезисах докладов Занимонец Ю.М. отмечает: "иногда чрезмерные меры защиты создавали проблемы при инсталляции и эксплуатации программного обеспечения". Следовательно, немаловажным моментом является хорошая продуманность системы защиты. В противном случае она может скорее навредить, чем принести пользу. Из этого вновь можно сделать выводы, что вопросы защиты (в области дистанционного образования) плохо проработаны.
Некоторые
ученые рассматривают
защиту в очень
ограниченном
аспекте. Н.Н.
Сенцов и В.С.
Солдаткин,
описывая программный
комплекс
тестового
контроля знаний
«Тест», говорят
о следующем:
"Каждая часть программного комплекса функционирует самостоятельно. В клиентской части нет возможности доступа к базе данных для ее изменения – это возможно из администраторской части, при знании пароля доступа к базе данных. Для работы клиентской части необходима заполненная база данных тестовыми заданиями. Это должно быть заведомо сделано из части администратора."
Таким образом, существует защита от модификации, но нет защиты от просмотра. Так же, вполне очевидно, отсутствует и защита отчетов о результатах тестирования.
Аналогично, Д.А. Жолобов, говоря о создании генератора мультимедийных учебников, отмечает, что программа должна обладать возможностью защиты данных учебника от несанкционированного доступа. Но ничего не говорится о том, как реализована защита в этой системе.
А Р.И.Вергазов и П.А.Гудков, описывая систему автоматизированного дистанционного тестирования, отмечают, что в сетевом варианте можно построить весьма надежную систему. Существует вариант для работы системы и в локальном режиме. Но не упоминается, существуют ли защита при использовании этой системы в локальном режиме.
Отделим те задачи, решение которых лежит вне сферы возможности программных средств и решение которых относится к административным средствам контроля. Для остальных задач предложены методы их решения, и сказано о необходимости включить поддержку их решений в функциональность разрабатываемой системы защиты.
К сожалению, первые две проблемы лежат вне сфер возможности программных средств без применения дополнительного аппаратного обеспечения. Естественным решением данных проблем может служить только правильное построение курса. Контроль знаний следует строить так, чтобы усложнить процесс подмены дублером. Найти дублера на один тест намного проще, чем на весь период обучения. При тестировании целесообразно предложить достаточно большое количество вопросов, наиболее оптимальным выходом является автоматическая генерация. Это исключило бы возможность просмотра всех вопросов и пробы разных вариантов ответов.
Помешать возможности создания универсального редактора файлов результатов тестирования может механизм открытых ключей. Именно такой механизм необходимо будет реализовать в системе защиты. Отметим, что будет использоваться шифрование с применением открытого ключа не в классическом понимании. Метод будет состоять в генерации полиморфных алгоритмов шифрования/расшифрования. При этом одному алгоритму шифрования будет соответствовать один алгоритм расшифровки. А воссоздание алгоритма шифровки/расшифровки по имеющимся обратному алгоритму слишком трудоемко.
Решение проблемы возможности создания универсальной программы просмотра файлов с заданиями и ответами представляется мне не в использовании стойких криптоалгоритмов, а в способе хранения данных. Помочь может генератор алгоритмов шифрования/расшифрования, позволяющий создавать уникальные пакеты АСДО. Путем хранения данных в пакетах, отдаваемых студенту и зашифрованных различными алгоритмами, будет реализовываться сложность создания универсальной программы просмотра.
Рассмотрим проблему возможности модификации программного кода системы тестирования с целью изменения алгоритма выставления оценок или другого кода. Как ни странно, подсказать решение могут такие программы, как вирусы. Точнее, полиморфные вирусы. Полиморфной называются программа, каждый штамм (копия) которой отличается от другого. Два экземпляра такой программы могут не совпадать ни одной последовательностью байт, но при этом функционально они являются копиями. Вирусы используют полиморфные генераторы для усложнения их обнаружения. Для нас полиморфный код интересен по другой причине. В него очень сложно внести изменения. Точнее, внести исправление в конкретный экземпляр приложения не представляется большой проблемой, а вот применить этот метод модификации на другом экземпляре невозможно. Отсюда следует высокая сложность написания универсального алгоритма, который бы изменял полиморфную программу так, чтобы она начала функционировать, как этого хочет злоумышленник.
Отсюда возникает идея построить подсистему по следующему описанию. Система представляет из себя файл, который хранится в зашифрованном виде. Программа-загрузчик расшифровывает его непосредственно в памяти и затем запускает. Таким образом, невозможно написать обыкновенную программу, модифицирующую этот файл. Ведь каждый файл зашифрован своим методом, а следовательно и простая модификация невозможна.
Конечно, возможно создание программы, взламывающей систему тестирования, базирующуюся на методах динамической модификации памяти программы или на создании и загрузки слепка данных в память. Но создание подобной программы уже само по себе весьма сложно и требует высокой квалификации.
Задача легкой адаптации уже существующих АСДО полностью лежит в сфере информационных технологий и имеет достаточно простое решение. В ОС Windows имеется механизм, который позволит легко адаптировать уже существующие системы дистанционного обучения и тестирования, причем разработанные на различных языках. Он обладает широкой поддержкой средств разработки и библиотек. Это COM (Component Object Model). COM - модель компонентных объектов Microsoft (стандартный механизм, включающий интерфейсы, с помощью которых одни объекты предоставляют свои сервисы другим, - является основой многих объектных технологий, в том числе OLE и ActiveX) [15].
Во второй главе предложены методы для реализации требований, поставленных системе защиты. Выбраны объекты защиты, рассмотрены асимметрические методы шифрования и предложен адаптированный метод для разрабатываемой системы.
Система защиты, предложенная в данной работе, не относится к системам дистанционного обучения, построенным по технологии клиент-сервер. Такие системы уже по своей идеологии достаточно хорошо защищены. Все базы данных с материалами для обучения, тестирования и так далее хранятся на сервере. В нужный момент только часть этих данных попадает на компьютер клиента. В этом случае, например, не требуется защита базы с ответами, поскольку проверка правильности может происходить на серверной стороне. Но, тем не менее, для такой системы модуль защиты будет также полезен. Так, если на компьютере студента устанавливается некий набор программ, организующий его обучение, то возможно и существование критических мест, где может пригодиться защита исполняемых модулей от модификации кода или другая функциональность модуля защиты.
Рассмотрим более подробно объекты системы дистанционного локального обучения, требующие защиты.
Данные, являющиеся текстом задач с ответами, могут быть просмотрены с корыстной целью. Это не является простым занятием в случае, если эти данные хранятся в сложном бинарном формате, так как без знания устройства соответствующего формата, просмотр таких данных внешними программами весьма сложен. Но многие АСДО хранят эти задачи в простом текстовом виде или в виде документов WORD, и, следовательно, просмотр таких данных никаких сложностей не вызовет. И, соответственно, доступ к базе задач автоматически дискредитируют систему тестирования.
Может возникнуть ситуация, когда нежелательна возможность неограниченного доступа не только к базам заданий/ответов, но и к обучающему материалу. Например, нежелательно широкое распространение обучающих материалов, и требуется ограничить их просмотр только из соответствующей системы тестирования. Естественно, абсолютной защиты тут придумать невозможно, так как в любом случае просто физически нельзя запретить, например, сфотографировать монитор. Но, тем не менее, шифрование таких данных иногда оправдано.
Исполняемые файлы систем тестирования подвержены модификации с целью изменения алгоритма их работы. Примером может служить модификация алгоритма выставления оценки за пройденное тестирование или алгоритма генерации отчета с соответствующей оценкой. Дополнительная трудность состоит в том, чтобы усложнить процесс массового взлома. Нет такой программы, которую невозможно было бы взломать. Но вот критерий трудоемкости взлома прямо пропорционален критерию надежности. Таким образом, стоит задача по возможности ограничения возможности создания программы – взломщика, которую можно будет применить для модификации обучающего пакета любого студента. Задача состоит не в создании очень сложной системы защиты исполняемых модулей. Задача состоит в том, чтобы разработанная кем-то программа–взломщик не имела своего действия на другие пакеты, или, точнее сказать, чтобы создание такой программы было очень трудоемким и экономически нецелесообразным. Представим такую ситуацию. Группе студентов выдали пакет дистанционного обучающего программного обеспечения. Один из студентов вместо честного обучения и тестирования потратил все время на изучение и взлом этой системы в результате чего получил высокую оценку, так и не ознакомившись с предметом. Такой частный случай сам по себе не страшен. Намного страшнее, если после этого данный студент начнет распространять свое техническое достижение. И, таким образом, все студенты следующего года обучения воспользуются этим. Результатом будет полное не владение курсом студентами, обучение которых происходит на взломанной АСДО. Один из путей защиты – это создание уникальных программных модулей. То есть модулей, для которых неприменима простая программа - взломщик модифицирующая определенную последовательность байт. Предлагаемое решение генерации таких модулей будет описано в дальнейшем и будет основано на применении полиморфных алгоритмов шифрования.
Изменению могут быть подвержены результаты тестирования, то есть отчет, формируемый системой обучения/тестирования. Система дистанционного обучения может быть построена по принципу, когда студент присылает файл с результатами его тестирования по электронной почте или, скажем, приносит на дискете. В этом случае этот файл не должен представлять собой, например, простой текстовый файл. Часто в простых системах тестирования, изначально не разрабатывавшихся для дистанционного обучения, эти файлы для удобства представляются текстовыми документами или другими форматами, удобными для просмотра. В общем случае, здесь просто необходимо применение шифрования данных. В реализуемой системе защита будет построена на основе асимметричных механизмов шифрования. Это, во-первых, позволит защитить данные от модификации, а во-вторых, "подпишет" полученные данные. Так как каждого студента будет достаточно снабдить пактом тестирования с уникальным ключом, что сделает невозможным использование чужого файла с отчетом.
Теперь остановимся на асимметричных криптосистемах и кратко расскажем о них. Связано это с тем, что в дальнейшем в системе защиты будет предложен и использован механизм построенный по принципу асимметричных криптосистем.
Асимметричные или двухключевые системы являются одним из обширных классов криптографических систем. Эти системы характеризуются тем, что для шифрования и для расшифрования используются разные ключи, связанные между собой некоторой зависимостью. При этом данная зависимость такова, что установить один ключ, зная другой, с вычислительной точки зрения очень трудно.
Один из ключей (например, ключ шифрования) может быть общедоступным, в этом случае проблема получения общего секретного ключа для связи отпадает. Если сделать общедоступным ключ расшифрования, то на базе полученной системы можно построить систему аутентификации передаваемых сообщений. Поскольку в большинстве случаев один ключ из пары делается общедоступным, такие системы получили также название криптосистем с открытым ключом.
Классические методы построения асимметричных алгоритмов криптопреобразований хоть нам и интересны, но не достаточно хорошо подходят для решаемой задачи. Можно было бы взять реализацию уже готового асимметричного алгоритма, или согласно теоретическому описанию реализовать подобный алгоритм самостоятельно. Но, во-первых, здесь встает вопрос о лицензировании и использовании алгоритмов шифрования. Но использование стойких криптоалгоритмов связано с правовой базой, касаться которой бы не хотелось. Ведь сам по себе стойкий алгоритм шифрования здесь не нужен. Он просто излишен, и создаст лишь дополнительное замедление работы программы при шифровании/расшифровании данных. Также планируется выполнять код программы шифрования/расшифрования в виртуальной машине, из чего вытекает большая сложность реализации такой системы, если использовать сложные алгоритмы шифрования. Виртуальная машина дает ряд преимуществ, например, делает более скрытной возможность проведения некоторых операций. В качестве примера можно привести проверку алгоритмом допустимого срока своего использования.
Отсюда следует вывод, что создаваемый алгоритм шифрования должен быть прост. Но при этом он должен обеспечивать асимметричность и быть достаточно сложным для анализа. Исходя их этих позиций, берет свое начало идея создания полиморфных алгоритмов шифрования.
Основная сложность будет состоять в построении генератора, который должен выдавать на выходе два алгоритма. Один для шифрования, другой для расшифрования. Ключей у этих алгоритмов шифрования/расшифрования нет. Можно сказать что они сами являются ключами, или что они содержат ключ внутри. Они должны быть устроены таким образом, чтобы производить уникальные преобразования над данными. То есть, два сгенерированных алгоритма шифрования должны производить шифрования абсолютно различными способами. И для их расшифровки возможно будет использовать только соответствующий алгоритм расшифрования, который был сгенерирован в паре с алгоритмом шифрования.
Уникальность создания таких алгоритмов должен обеспечить полиморфный генератор кода. Исполняться алгоритмы будут в виртуальной машине. Анализ алгоритмов должен стать весьма трудным и нецелесообразным занятием.
Преобразования же над данными будут достаточно тривиальны, но практически уникальны. Точнее, вероятность генерации двух одинаковых алгоритмов должна стремиться к нулю. В качестве же элементарных действий следует использовать такие нересурсоемкие операции, как сложение с каким либо числом или, например, побитовое исключающее или (XOR). Но повторение нескольких таких преобразований, да еще с изменяющимися аргументами операций (в зависимости от адреса шифруемой ячейки), делает шифр достаточно сложным. А генерации каждый раз новой последовательности таких преобразований, да еще с участием различных аргументов, делает алгоритм сложным для анализа.
Остановимся чуть подробнее на основных преимуществах применения полиморфных алгоритмов шифрования для систем, по функциональности схожих с АСДО.
Слабая очевидность принципа построения системы защиты. Это является следствием выбора достаточно своеобразных механизмов. Во-первых, это само выполнение кода шифрования или расшифрования в виртуальной машине. А во-вторых, наборы полиморфных алгоритмов, уникальных для каждого пакета защищаемого программного комплекса. Это должно повлечь серьезные затруднения при попытке анализа работы такой системы, с целью поиска слабых мест для атаки. И это очень важно. Так как, если система сразу создаст видимость сложности и малой очевидности работы своих внутренних механизмов, то, скорее всего, это остановит человека от дальнейших исследований. Правильно построенная программа, с использованием разрабатываемой системой защиты, может не только оказаться сложной на вид, но и быть таковой в действительности. Выбранные же методы сделают устройство такой системы нестандартным, и даже, можно сказать, неожиданным.
Сложность создания универсальных средств для обхода системы защиты. Данное преимущество заключается в возможности генерации уникальных пакетов защищенного ПО. Создание универсального механизма взлома средств защиты, затруднено в случае отсутствия исходного кода. В противном случае необходим глубокий, подробный и профессиональный анализ такой системы, осложняемый тем, что каждый экземпляр системы использует свои алгоритмы шифрования/расшифрования. А модификация отдельного экземпляра, защищенного ПО интереса не представляет. Ведь основной упор сделан на защиту от ее массового взлома, а не на высокую надежность отдельного экземпляра пакета.
Легкая реализация системы асимметрического шифрования. Это представляет собой следствие необходимости генерировать два разных алгоритма, один для шифрования, а другой для расшифрования. На основе асимметрического шифрования можно организовать богатый набор различных механизмов в защищаемом программном комплексе.
Возможность легкой, быстрой адаптации и усложнения такой системы. Поскольку для разработчиков система предоставляется в исходном коде, то у него есть все возможности для его изменения. Это может быть вызвано необходимостью добавления новой функциональности. При этом, для такой функциональности может быть реализована поддержка со стороны измененной виртуальной машины. В этом случае работа новых механизмов может стать сложной для анализа со стороны. Также легко внести изменения с целью усложнения генератора полиморфного кода, и увеличения блоков, из которых строятся полиморфные алгоритмы. Это, например, может быть полезно в том случае, если кем-то, не смотря на все сложности, будет создан универсальный пакет для взлома системы зашиты. Тогда совсем небольшие изменения в коде, могут свести на нет труды взломщика. Стоит отметить, что это является очень простым действием, и потенциально так же способствует защите, так как делает процесс создания взлома еще более нерациональным.
Поскольку программисту отдаются исходные коды система защиты, то он легко может воспользоваться существующей виртуальной машиной и расширить ее для собственных нужд. То же самое касается и генератора полиморфных алгоритмов. Например, он может встроить в полиморфный код ряд специфических для его системы функций. Сейчас имеется возможность ограничить возможность использования алгоритмов по времени. А где-то, возможно понадобится ограничение по количеству запусков. Можно расширить только виртуальную машину с целью выполнения в ней критических действий.
В третьей главе внимание уделено непосредственно реализации системы защиты. Выбраны средства разработки, рассмотрен процесс создания компонентов системы защиты.
Для разработки системы защиты необходим компилятор, обладающий хорошим быстродействием генерируемого кода. Требование к быстродействию обусловлено ресурсоемкостью алгоритмов шифрования и расшифрования. Также необходима среда с хорошей поддержкой COM. Желательно, чтобы язык был объектно-ориентированный, что должно помочь в разработке достаточно сложного полиморфного генератора.
Естественным выбором будет использование Visual C++. Данное средство разработки отвечает всем необходимым требованиям. Также понадобится библиотека для сжатия данных. Наиболее подходящим кандидатом является библиотека ZLIB.
Рассмотрим общие принципы работы полиморфных алгоритмов шифрования и расшифрования. Алгоритмы состоят из 8 функциональных блоков, некоторые из которых могут повторяться. На рисунке 1 приведена абстрактная схема работы алгоритма шифрования/расшифрования.
Повторяющиеся блоки обозначены эллипсами, находящимися под квадратами. Количество таких блоков выбирается случайно при генерации каждой новой пары алгоритмов. Функциональные блоки и их номер отмечены числом в маленьком прямоугольнике, расположенным в правом верхнем углу больших блоков.
|
|
|
Рисунок 1. Алгоритм шифрования/расшифрования в общем виде. |
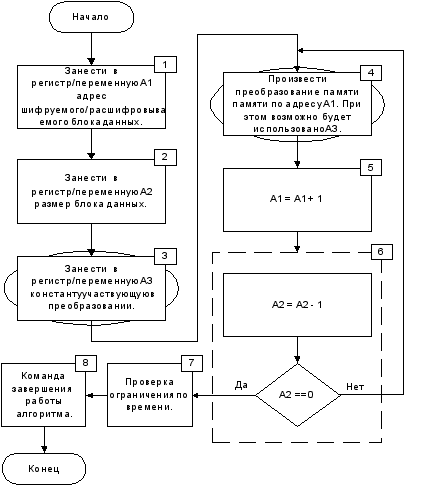
Сразу отметим, что при своей работе виртуальная машина использует виртуальные регистры и память. Начальное содержимое виртуальной памяти, как и сам сгенерированный алгоритм хранится в файле. Например, именно в виртуальной памяти может быть записано, сколько байт необходимо расшифровать. Некоторые виртуальные регистры и виртуальные ячейки памяти содержат мусор и не используются или используются в холостых блоках. Холостые блоки состоят из одной или более базовых инструкций виртуальной машины. Они не являются функциональными, и описание их здесь будет опушено. Холостым блокам будет уделено внимание в следующем разделе. На схеме произвольные регистры/ячейки памяти обозначаются как буква А с и цифрой. Полиморфный генератор случайным образом выбирает, какой же именно регистр или ячейка памяти будет задействована в каждом конкретном алгоритме шифрования/расшифрования. Рассмотрим теперь каждый из функциональных блоков более подробно.
Блок 1 заносит в виртуальный регистр или переменную (обозначим ее как A1) адрес шифруемого/расшифруемого блока данных. Для виртуальной машины этот адрес на самом деле всегда является нулем. Дело в том, что когда происходит выполнение виртуальной инструкции модификации данных, то виртуальная машина добавляет к этому адресу настоящий адрес в памяти и уже с ним производит операции. Можно представить A1 как индекс в массиве шифруемых/расшифруемых данных, адресуемых с нуля.
Блок 2 заносит в виртуальный регистр или переменную (обозначим ее как A2) размер блока данных. А2 выполняет роль счетчика в цикле преобразования данных. Заметим, что ее значение всегда в 4 раза меньше, чем настоящий размер шифруемых/расшифруемых данных. Это связано с тем, что полиморфные алгоритмы всегда работают с блоками данных кратных по размеру 4 байтам. Причем, операции преобразования выполняются над блоками кратными 4 байтам. О выравнивании данных по 4 байта заботятся более высокоуровневые механизмы, использующие виртуальную машину и полиморфные алгоритмы для шифрования и расшифрования данных. Возникает вопрос, откуда алгоритму знать, какого размера блок ему необходимо зашифровать, ведь при его генерации такой информации просто нет. Необходимое значение он просто берет из ячейки памяти. Дело в том, что виртуальная машина памяти "знает" именно об этой виртуальной ячейке памяти и перед началом выполнения полиморфного алгоритма заносит туда необходимое значение.
Блок 3 помещает в виртуальный регистр или переменную (обозначим ее как A3) константу, участвующую в преобразовании. Эта константа, возможно, затем и не будет использована для преобразования данных, все зависит от того, какой код будет сгенерирован. Блок 3 может быть повторен несколько раз. Над данными осуществляется целый набор различных преобразований и в каждом из них участвуют различные регистры/переменные инициализированные в блоке 3.
Блок 4 можно назвать основным. Именно он, а, точнее сказать, набор этих блоков производит шифрование/расшифрование данных. Количество этих блоков случайно, и равно количеству блоков номер 3. Но при преобразованиях не обязательно будет использовано значение из A3. Например, вместо A3 может использоваться константа или значение из счетчика. На данный момент полиморфный генератор поддерживает 3 вида преобразований: побитовое "исключающее или" (XOR), сложение и вычитание. Набор этих преобразование можно легко расширить, главное, чтобы такое преобразование имело обратную операцию.
Блок 5 служит для увеличения A1 на единицу. Как и во всех других блоках эта операция может быть выполнена по-разному, то есть с использованием различных элементарных инструкций виртуальной машины.
Блок 6 организует цикл. Он уменьшает значение A2 на единицу, и если результат не равен 0, то виртуальная машина переходит к выполнению четвертого блока. На самом деле управление может быть передано на один из холостых блоков между блоком 3 и 4, но с функциональной точки зрения это значения не имеет.
Блок 7 производит проверку ограничения по времени использования алгоритма. Код по проверке на ограничение по времени относится к холостым командам, и на самом деле может присутствовать и выполнятся в коде большое количество раз. То, что он относится к холостым блокам кода вовсе не значит, что он не будет нести функциональной нагрузки. Он будет действительно проверять ограничение, но, как и другие холостые блоки, располагаться произвольным образом в пустых промежутках между функциональными блоками. Поскольку этот блок может теоретически никогда не встретиться среди холостых блоков, то хоть один раз его следует выполнить. Именно поэтому он и вынесен как один из функциональных блоков. Если же при генерации алгоритма от генератора не требуется ограничение по времени, то в качестве аргумента к виртуальной команде проверки времени используется специальное число.
Блок 8 завершает работу алгоритма.
Опишем теперь по шагам, как работает генератор полиморфного кода.
1.
На первом этапе
выбираются
характеристики
будущих алгоритмов.
К ним относятся:
a)
размер памяти,
выделенной
под код;
б)
в каких регистрах
или ячейках
будут располагаться
указатели на
модифицируемый
код;
г) сколько
раз будут
повторяться
функциональные
блоки 3 и 4;
д) в каких регистрах или ячейках будут располагаться счетчики циклов;
При этом количество повторений блоков 3 и 4 должно быть одинаковым и для алгоритма шифрования и для алгоритма расшифрования, так как каждой команде преобразования данных при шифровании должна быть сопоставлена обратная команда в алгоритме расшифрования.
2. Виртуальная память, используемая в алгоритме, заполняется случайными значения.
3.
Создается 1-ый
функциональный
блок и помещается
в промежуточное
хранилище.
а)
Случайным
образом ищется
подходящий
первый блок.
Критерий поиска
– блок должен
использовать
регистр или
ячейку памяти
под указатель,
в зависимости
от того какие
характеристики
были выбраны
на первом шаге
(пункт б).
б) В
код блока
подставляется
соответствующий
номер регистра
или адрес виртуальной
ячейки памяти.
4. Создается 2-ой функциональный блок и помещается в промежуточное хранилище. Алгоритм создания подобен алгоритму, описанному в шаге 3. Но теперь подставляется не только номер регистра или ячейки памяти, куда помещается значение, но и адрес памяти с источником. В эту ячейку памяти в дальнейшем виртуальная машина будет помещать размер шифруемой/расшифруемой области.
5. Необходимое количество раз создаются и помещается в промежуточное хранилище функциональные блоки под номером 3. Механизм их генерации также схож с шагами 3 и 4. Отличием является то, что некоторые константы в коде блока заменяются случайными числами. Например, эти значения при шифровании или расшифровании будут складываться с преобразуемыми ячейками памяти, вычитаться и так далее.
6. Подсчитывается размер уже сгенерированных блоков. Это число затем будет использоваться для случайной генерации адреса начала блоков в цикле.
7. Рассчитывается размер памяти, который будет выделен под уже сгенерированные блоки (расположенные до цикла) с резервированием места под холостые блоки. Также подсчитывается адрес первого блока в цикле.
8. Необходимое количество раз создаются и помещается в промежуточное хранилище функциональные блоки под номером 3. Это шаг несколько сложнее, чем все другие. Во-первых, здесь весьма сильная зависимость между сгенерированным кодом шифрования и расшифрования. В коде расшифрования используются обратные по действию операции относительно операций шифрования. При этом они располагаются в обратной последовательности.
9. Создается 5-ой функциональный блок и помещается в промежуточное хранилище.
10. Создается 6-ой функциональный блок и помещается в промежуточное хранилище. Это блок, организующий цикл, поэтому он использует адреса, рассчитанные на шаге 7.
11. Создается 7-ой функциональный блок и помещается в промежуточное хранилище.
12. Создается 8-ой функциональный блок и помещается в промежуточное хранилище.
13. Созданные функциональные блоки размещаются в одной области памяти с промежутками случайного размера.
14. Оставшиеся промежутки заполняются случайно выбранными холостыми блоками. При этом эти блоки также подвергаются модификации кода. Например, подставляются случайные но неиспользуемые номера регистров, записываются случайные константы и так далее.
15. Происходит запись в файл необходимых идентификаторов, структур, различных данных и самого полиморфного кода. В результате мы получаем то, что называется файлом с полиморфный алгоритмом.
Четвертая глава описывает возможности разработанной системы и содержит руководство программиста по ее использованию, ряд примеров. Также даны общие рекомендации по интеграции разработанной системы.
В начале главы приведен список компонентов, входящих в разработанную библиотеку защиты Uniprot. Затем подробно описаны интерфейсы, предоставляемые программисту модулем Uniprot.dll. Модуль экспортирует три интерфейса: IProtect, IProtectFile, IProtectConformity.
В интерфейсе IProtect собраны функции общего плана и генерации файлов с полиморфными алгоритмами шифрования и расшифрования. К сожалению в рамках автореферата не удастся более подробно остановиться на описании как этого, так и следующих интерфейсов, хотя они очень важны для точного понимания предоставляемых модулем возможностей.
В IProtectFile собраны функции работы с зашифрованными файлами, такие как создание зашифрованного файла, запись в него, чтение и так далее. Идеология работы с зашифрованными файлами построена на дескрипторах. При создании или открытии зашифрованного файла ему в соответствие ставится дескриптор, с использованием которого в дальнейшем и ведется работа с файлом.
Интерфейс IProtectConformity является вспомогательным и объединяет набор функций, призванных облегчить использование системы с большим количеством файлов с алгоритмами и зашифрованных данных.
Глава содержит также руководство программиста по использованию программы ProtectEXE.exe. Программа ProtectEXE.EXE предназначена для защиты исполняемых файлов от модификации. Под исполняемыми модулями понимаются EXE файлы в формате PE (Portable Executables). Защита исполняемых модулей основана на их шифровании. Особенностью утилиты ProtectEXE является то, что она шифрует каждый исполняемый файл уникальным полиморфным алгоритмом. Это затрудняет возможность использования программного взломщика, основанного на модификации определенных кодов в программе. Поскольку каждый исполняемый файл зашифрован своим методом, то и модифицировать их единым методом невозможно. Утилита ProtectEXE.EXE не позволяет защититься от динамического модифицирования в памяти. Это слишком сложно и не может быть достигнуто, без существенной переделки исходного текста самой защищаемой программы. Но в рамках защиты дистанционных средств обучения такая защита должна быть достаточно эффективна и достаточна. Ведь создание взламывающей программы экономически мало целесообразно, а, следовательно, и, скорее всего, не будет осуществлено.
Далее в главе описано использования системы защиты на примерах. Так например рассмотрено подключение модуля защиты к программе на языке Visual C++ и Visual Basic. Приведен пример использования модуля защиты в программе на языке Visual Basiс, Пример использования программы ProtectEXE.exe.
В конце главы дан ряд общих рекомендаций по интеграции системы защиты.
В заключении подведены итоги проделанной работы.
В приложениях приведен исходный текст модуля защиты.
ОСНОВНЫЕ РЕЗУЛЬТАТЫ РАБОТЫ
1. Выполнен сравнительный анализ существующих подходов к организации защиты данных в системах с монопольным доступом на примере автоматизированных систем дистанционного обучения. Отмечено, что существует много защищенных обучающие систем, функционирующих в среде интернет, но практически отсутствуют защищенные пакеты для локального использования. Это обусловлено плохо проработанными и еще не достаточно хорошо изученными методами построения защищенных АСДО.
2. На основе анализа предложен ряд мер, позволяющий повысить защищенность АСДО. Разработаны программные средства, предназначенные для интеграции в уже существующие обучающие системы с целью их защиты при использовании вне доверенной вычислительной среды.
3. В разработанном программном обеспечении были использованы новые технологии шифрования данных. Полностью исключена необходимость использования аппаратных средств.
4. Разработана система защиты, руководство для программиста, набор тестовых примеров и рекомендации по ее применению. Созданная система была интегрирована в уже существующий комплекс Aquarius Education 4.0, разработанный на кафедре АТМ.
СПИСОК ОСНОВНЫХ ПУБЛИКАЦИЙ ПО ТЕМЕ ДИССЕРТАЦИИ
Построение защиты в системе контроля и передачи знаний. Печатный Сборник докладов международной научной конференции ММТТ-Дон. РГХАСМ, Ростов-на-Дону, 2002. 2 стр.
Система интеграции защиты информации для пакетов автономного дистанционного обучения. Печатный Сборник докладов международной научной конференции ММТТ-Дон. РГХАСМ, Ростов-на-Дону, 2003. 2 стр.
ђ §¤Ґ«: Їа®Ја ¬¬Ёа®ў ЁҐ
”€Ћ: Љ аЇ®ў Ђ¤аҐ© ЌЁЄ®« ҐўЁз
forsp@list.ru
‡ йЁв Ёд®а¬ жЁЁ ў бЁб⥬ е ¤Ёбв жЁ®®Ј® ®Ўг票п б ¬®®Ї®«мл¬ ¤®бвгЇ®¬
„ЁЇ«®¬
168
Часть исходных текстов вспомогательного характера опущена. В качестве примера можно привести класс com_ptr, представляющий вспомогательный класс для более удобной работы с COM интерфейсом. Также полностью опущены исходные тектсыт свободно распрострняемой библиотеки ZLIB 1.1.2.
Файл blocks.h.
#ifndef __BLOCKS_H__
#define __BLOCKS_H__
#ifndef CALC_ARRAY_SIZE
#define CALC_ARRAY_SIZE(arr) ((int) (sizeof arr / sizeof arr[0]))
#endif
#define BLOCK_START(num) const static int block_##num [] = {
#define BLOCK_END(num) }; const size_t sizeBlock_##num = CALC_ARRAY_SIZE(block_##num);
#define BLOCKS_START(num) const static int * const blocks_##num [] = {
#define BLOCKS_END(num) }; const size_t sizeBlocksArray_##num = CALC_ARRAY_SIZE(blocks_##num);
#define BLOCK(num) static_cast(block_##num),
#define BLOCKS_SIZE_START(num) const static unsigned sizeBlocks_##num [] = {
#define BLOCK_SIZE(num) sizeBlock_##num,
#define BLOCKS_SIZE_END(num) };
// Абстрактный алгоритм
// [ADDR(REG|VAR)
// [COUNT(REG|VAR)
// VAR)
// label:
// {
// TEMP
// TEMP = TEMP opearation R[i]
// [ADDR]
// ADDR++
// COUNT--
// } * i(1; n)
// if (COUNT!=0)
// GOTO label
// TrstDate
// EXIT
//-----------------------------------------------------------------------------
// Блок N0. (x1)
// Служит для инициализации указателя нулем.
// ES_VARIABLE_0 - ячейка которая может быть занята под указатель.
// ES_REG_0 - регистр который может быть занят под указатель.
BLOCK_START(00_00)
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 0
BLOCK_END(00_00)
BLOCK_START(00_01)
EO_MOV, EOP_REG, ES_REG_0, EOP_CONST, 0
BLOCK_END(00_01)
BLOCK_START(00_02)
EO_PUSH, EOP_CONST, 0,
ES_RANDOM_NOP,
ES_RANDOM_NOP,
EO_POP, EOP_REG, ES_REG_0
BLOCK_END(00_02)
BLOCK_START(00_03)
EO_PUSH, EOP_CONST, ES_RANDOM_CONST,
ES_RANDOM_NOP,
EO_POP, EOP_REG, ES_REG_0,
EO_SUB, EOP_REG, ES_REG_0, EOP_REG, ES_REG_0
BLOCK_END(00_03)
BLOCK_START(00_04)
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 1,
EO_DEC, EOP_VAR, ES_VARIABLE_0,
EO_CMP, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 0,
EO_JNZ, EOP_CONST, ES_RANDOM_CONST
BLOCK_END(00_04)
BLOCK_START(00_05)
EO_XOR, EOP_REG, ES_REG_0, EOP_REG, ES_REG_0
BLOCK_END(00_05)
BLOCK_START(00_06)
EO_XOR, EOP_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_0
BLOCK_END(00_06)
BLOCKS_START(00)
BLOCK(00_00)
BLOCK(00_01)
BLOCK(00_02)
BLOCK(00_03)
BLOCK(00_04)
BLOCK(00_05)
BLOCK(00_06)
BLOCKS_END(00)
BLOCKS_SIZE_START(00)
BLOCK_SIZE(00_00)
BLOCK_SIZE(00_01)
BLOCK_SIZE(00_02)
BLOCK_SIZE(00_03)
BLOCK_SIZE(00_04)
BLOCK_SIZE(00_05)
BLOCK_SIZE(00_06)
BLOCKS_SIZE_END(00)
//-----------------------------------------------------------------------------
//-----------------------------------------------------------------------------
// Блок N1. (x1)
// Служит для инициализации счетчика нужным значением.
// ES_VARIABLE_0 - ячейка которая может быть занята под значение.
// ES_REG_0 - регистр который может быть занят под значение.
// ES_VARIABLE_1 - Отсюда необхлдимо взять размер
BLOCK_START(01_00)
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(01_00)
BLOCK_START(01_01)
EO_MOV, EOP_REG, ES_REG_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(01_01)
BLOCK_START(01_02)
EO_PUSH, EOP_VAR, ES_VARIABLE_1,
ES_RANDOM_NOP,
ES_RANDOM_NOP,
EO_POP, EOP_REG, ES_REG_0
BLOCK_END(01_02)
BLOCK_START(01_03)
EO_PUSH, EOP_VAR, ES_VARIABLE_1,
EO_MOV, EOP_REG, ES_REG_0, EOP_RAND,
EO_POP, EOP_REG, ES_REG_0
BLOCK_END(01_03)
BLOCK_START(01_04)
EO_XCHG, EOP_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(01_04)
BLOCK_START(01_05)
EO_XCHG, EOP_REG, ES_REG_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(01_05)
BLOCKS_START(01)
BLOCK(01_00)
BLOCK(01_01)
BLOCK(01_02)
BLOCK(01_03)
BLOCK(01_04)
BLOCK(01_05)
BLOCKS_END(01)
BLOCKS_SIZE_START(01)
BLOCK_SIZE(01_00)
BLOCK_SIZE(01_01)
BLOCK_SIZE(01_02)
BLOCK_SIZE(01_03)
BLOCK_SIZE(01_04)
BLOCK_SIZE(01_05)
BLOCKS_SIZE_END(01)
//-----------------------------------------------------------------------------
//-----------------------------------------------------------------------------
// Блок N2. (xN)
// Служит для инициализации модификатора нужным значением.
// ES_VARIABLE_0 - ячейка которая может быть занята под значение.
// ES_REG_0 - регистр который может быть занят под значение.
// ES_VARIABLE_1 - ячейка, где может храниться модификатор
// ES_COSNT_0 - здесь может храниться модификатор
BLOCK_START(02_00)
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(02_00)
BLOCK_START(02_01)
EO_MOV, EOP_REG, ES_REG_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(02_01)
BLOCK_START(02_02)
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_CONST, ES_CONST_0
BLOCK_END(02_02)
BLOCK_START(02_03)
EO_MOV, EOP_REG, ES_REG_0, EOP_CONST, ES_CONST_0
BLOCK_END(02_03)
BLOCK_START(02_04)
EO_XCHG, EOP_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(02_04)
BLOCK_START(02_05)
EO_XCHG, EOP_REG, ES_REG_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(02_05)
BLOCK_START(02_06)
EO_PUSH, EOP_CONST, ES_CONST_0,
ES_RANDOM_NOP,
ES_RANDOM_NOP,
EO_POP, EOP_REG, ES_REG_0
BLOCK_END(02_06)
BLOCK_START(02_07)
EO_MOV, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 0,
EO_ADD, EOP_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(02_07)
BLOCKS_START(02)
BLOCK(02_00)
BLOCK(02_01)
BLOCK(02_02)
BLOCK(02_03)
BLOCK(02_04)
BLOCK(02_05)
BLOCK(02_06)
BLOCK(02_07)
BLOCKS_END(02)
BLOCKS_SIZE_START(02)
BLOCK_SIZE(02_00)
BLOCK_SIZE(02_01)
BLOCK_SIZE(02_02)
BLOCK_SIZE(02_03)
BLOCK_SIZE(02_04)
BLOCK_SIZE(02_05)
BLOCK_SIZE(02_06)
BLOCK_SIZE(02_07)
BLOCKS_SIZE_END(02)
//-----------------------------------------------------------------------------
//-----------------------------------------------------------------------------
// Блок N3. (xN)
// Служит для преобразования одной ячейки памяти.
// ES_VARIABLE_0 - \ указатель на ячейку памяти
// ES_REG_0 - /
// ES_VARIABLE_1 - \ модификатор
// ES_REG_1 - /
// ES_VARIABLE_2 - \ счетчик
// ES_REG_2 - /
// ES_SPECIFIC_0 - сюда подставить операцию
//. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
const static int block_03_operation_AB[] =
{
EO_XOR, EO_ADD, EO_SUB
};
const static int block_03_operation_BA[] =
{
EO_XOR, EO_SUB, EO_ADD
};
BLOCK_START(03_00)
ES_SPECIFIC_0, EOP_REF_REG, ES_REG_0, EOP_REG, ES_REG_1
BLOCK_END(03_00)
BLOCK_START(03_01)
ES_SPECIFIC_0, EOP_REF_VAR, ES_VARIABLE_0, EOP_REG, ES_REG_1
BLOCK_END(03_01)
BLOCK_START(03_02)
ES_SPECIFIC_0, EOP_REF_REG, ES_REG_0, EOP_REG, ES_REG_2
BLOCK_END(03_02)
BLOCK_START(03_03)
ES_SPECIFIC_0, EOP_REF_VAR, ES_VARIABLE_0, EOP_REG, ES_REG_2
BLOCK_END(03_03)
BLOCK_START(03_04)
ES_SPECIFIC_0, EOP_REF_REG, ES_REG_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(03_04)
BLOCK_START(03_05)
ES_SPECIFIC_0, EOP_REF_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_1
BLOCK_END(03_05)
BLOCK_START(03_06)
ES_SPECIFIC_0, EOP_REF_REG, ES_REG_0, EOP_VAR, ES_VARIABLE_2
BLOCK_END(03_06)
BLOCK_START(03_07)
ES_SPECIFIC_0, EOP_REF_VAR, ES_VARIABLE_0, EOP_VAR, ES_VARIABLE_2
BLOCK_END(03_07)
BLOCKS_START(03)
BLOCK(03_00)
BLOCK(03_01)
BLOCK(03_02)
BLOCK(03_03)
BLOCK(03_04)
BLOCK(03_05)
BLOCK(03_06)
BLOCK(03_07)
BLOCKS_END(03)
BLOCKS_SIZE_START(03)
BLOCK_SIZE(03_00)
BLOCK_SIZE(03_01)
BLOCK_SIZE(03_02)
BLOCK_SIZE(03_03)
BLOCK_SIZE(03_04)
BLOCK_SIZE(03_05)
BLOCK_SIZE(03_06)
BLOCK_SIZE(03_07)
BLOCKS_SIZE_END(03)
//-----------------------------------------------------------------------------
//-----------------------------------------------------------------------------
// Блок N4. (x1)
// Служит для увеличения значения указателя.
// ES_VARIABLE_0 - ячейка которая может быть занята под указатель.
// ES_REG_0 - регистр который может быть занят под указатель.
BLOCK_START(04_00)
EO_ADD, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 1
BLOCK_END(04_00)
BLOCK_START(04_01)
EO_INC, EOP_VAR, ES_VARIABLE_0
BLOCK_END(04_01)
BLOCK_START(04_02)
EO_INC, EOP_REG, ES_REG_0
BLOCK_END(04_02)
BLOCK_START(04_03)
EO_SUB, EOP_VAR, ES_VARIABLE_0, EOP_CONST, -1
BLOCK_END(04_03)
BLOCK_START(04_04)
EO_SUB, EOP_REG, ES_REG_0, EOP_CONST, -1
BLOCK_END(04_04)
BLOCK_START(04_05)
EO_NEG, EOP_REG, ES_REG_0,
ES_RANDOM_NOP,
ES_RANDOM_NOP,
EO_DEC, EOP_REG, ES_REG_0,
EO_NEG, EOP_REG, ES_REG_0
BLOCK_END(04_05)
BLOCKS_START(04)
BLOCK(04_00)
BLOCK(04_01)
BLOCK(04_02)
BLOCK(04_03)
BLOCK(04_04)
BLOCK(04_05)
BLOCKS_END(04)
BLOCKS_SIZE_START(04)
BLOCK_SIZE(04_00)
BLOCK_SIZE(04_01)
BLOCK_SIZE(04_02)
BLOCK_SIZE(04_03)
BLOCK_SIZE(04_04)
BLOCK_SIZE(04_05)
BLOCKS_SIZE_END(04)
//-----------------------------------------------------------------------------
//-----------------------------------------------------------------------------
// Блок N5. (x1)
// Служит для организации цикла.
// ES_VARIABLE_0 - ячейка которая может быть занята под счетчик.
// ES_REG_0 - регистр который может быть занят под счетчик.
// ES_ADDRESS_0 - куда осуществить переход для повтора цикла.
BLOCK_START(05_00)
EO_DEC, EOP_VAR, ES_VARIABLE_0,
EO_CMP, EOP_VAR, ES_VARIABLE_0, EOP_CONST, 0,
EO_JNZ, EOP_CONST, ES_ADDRESS_0
BLOCK_END(05_00)
BLOCK_START(05_01)
EO_DEC, EOP_REG, ES_REG_0,
EO_CMP, EOP_REG, ES_REG_0, EOP_CONST, 0,
EO_JNZ, EOP_CONST, ES_ADDRESS_0
BLOCK_END(05_01)
BLOCKS_START(05)
BLOCK(05_00)
BLOCK(05_01)
BLOCKS_END(05)
BLOCKS_SIZE_START(05)
BLOCK_SIZE(05_00)
BLOCK_SIZE(05_01)
BLOCKS_SIZE_END(05)
//-----------------------------------------------------------------------------
//-----------------------------------------------------------------------------
// Блок N6. (x1)
// Служит для проверки временных ограничений. (может отсутсвовать)
// ES_CONST_0 - константа которая может содержать дату для контроля.
// ES_VARIABLE_0 - ячейка которая может содержать дату для контроля.
BLOCK_START(06_00)
EO_TEST_TIME_0, EOP_CONST, ES_CONST_0
BLOCK_END(06_00)
BLOCK_START(06_01)
EO_TEST_TIME_1, EOP_CONST, ES_CONST_0
BLOCK_END(06_01)
BLOCK_START(06_02)
EO_TEST_TIME_0, EOP_VAR, ES_VARIABLE_0
BLOCK_END(06_02)
BLOCK_START(06_03)
EO_TEST_TIME_1, EOP_VAR, ES_VARIABLE_0
BLOCK_END(06_03)
BLOCKS_START(06)
BLOCK(06_00)
BLOCK(06_01)
BLOCK(06_02)
BLOCK(06_03)
BLOCKS_END(06)
BLOCKS_SIZE_START(06)
BLOCK_SIZE(06_00)
BLOCK_SIZE(06_01)
BLOCK_SIZE(06_02)
BLOCK_SIZE(06_03)
BLOCKS_SIZE_END(06)
//-----------------------------------------------------------------------------
// Блок N7. (x1)
// Служит для завершения.
BLOCK_START(07_00)
EO_EXIT_0
BLOCK_END(07_00)
BLOCK_START(07_01)
EO_EXIT_1
BLOCK_END(07_01)
BLOCK_START(07_02)
EO_EXIT_2,
EO_NOP_0,
EO_JMP, EOP_CONST, 0
BLOCK_END(07_02)
BLOCKS_START(07)
BLOCK(07_00)
BLOCK(07_01)
BLOCK(07_02)
BLOCKS_END(07)
BLOCKS_SIZE_START(07)
BLOCK_SIZE(07_00)
BLOCK_SIZE(07_01)
BLOCK_SIZE(07_02)
BLOCKS_SIZE_END(07)
//-----------------------------------------------------------------------------
// Блок NOP.
BLOCK_START(nop_00)
EO_XCHG, EOP_REG, ES_RANDOM_REG, EOP_VAR, ES_RANDOM_VAR,
BLOCK_END(nop_00)
BLOCK_START(nop_01)
EO_ADD, EOP_REG, ES_RANDOM_REG, EOP_REG, ES_RANDOM_USE_REG,
BLOCK_END(nop_01)
BLOCK_START(nop_02)
EO_NOP_0
BLOCK_END(nop_02)
BLOCK_START(nop_03)
EO_NOP_1
BLOCK_END(nop_03)
BLOCK_START(nop_04)
EO_NOP_2
BLOCK_END(nop_04)
BLOCK_START(nop_05)
EO_NOP_3
BLOCK_END(nop_05)
BLOCK_START(nop_06)
EO_MOV, EOP_REG, ES_RANDOM_REG, EOP_RAND
BLOCK_END(nop_06)
BLOCKS_START(Nops)
BLOCK(nop_00)
BLOCK(nop_01)
BLOCK(nop_02)
BLOCK(nop_03)
BLOCK(nop_04)
BLOCK(nop_05)
BLOCK(nop_06)
BLOCKS_END(Nops)
BLOCKS_SIZE_START(Nops)
BLOCK_SIZE(nop_00)
BLOCK_SIZE(nop_01)
BLOCK_SIZE(nop_02)
BLOCK_SIZE(nop_03)
BLOCK_SIZE(nop_04)
BLOCK_SIZE(nop_05)
BLOCK_SIZE(nop_06)
BLOCKS_SIZE_END(Nops)
//-----------------------------------------------------------------------------
#endif // __BLOCKS_H__
Файл p_enums.h.
#ifndef __P_ENUMS_H__
#define __P_ENUMS_H__
#ifndef CALC_ARRAY_SIZE
#define CALC_ARRAY_SIZE(arr) ((int) (sizeof arr / sizeof arr[0]))
#endif
enum E_OPERATION // Инструкции
{
EO_ERROR = -1, // Недопустимая инструкция
EO_EXIT_0, EO_EXIT_1, EO_EXIT_2, // Конец рабоботы
EO_NOP_0, EO_NOP_1, EO_NOP_2, EO_NOP_3, // Пустые команды
EO_TEST_TIME_0, EO_TEST_TIME_1, // Контроль времени
EO_MOV, EO_XCHG, // Пересылка данных
EO_PUSH, EO_POP, // Работа со стеком
EO_XOR, EO_AND, EO_OR, EO_NOT, // Логические операции
EO_ADD, EO_SUB, EO_MUL, EO_DIV, EO_NEG, // Арифметические операции
EO_INC, EO_DEC,
EO_TEST, EO_CMP, // Операции сравнения
// (влияют на флаги)
EO_JMP, EO_CALL, EO_RET, // Операторы безусловного перехода
EO_JZ, EO_JNZ, EO_JA, EO_JNA, // Условные переходы
};
#define LAST_DEFINED_NOP EO_NOP_3
#define LAST_OPERATION EO_JNA
enum E_FLAGS // Флаги
{
EF_ZERO = 1, // Ноль
EF_ABOVE = 2, // Больше
};
enum E_OPERAND
{ // Операндом является:
EOP_REG = 0, // Регистр
EOP_REF_REG, // Память по адресу в регистре
EOP_VAR, // Переменная
EOP_REF_VAR, // Память по адресу в переменная
EOP_CONST, // Константное значение
EOP_RAND // Случайное число
};
enum E_SUBSTITUTION // Подстановки
{
// НЕ зАБЫВАТЬ подправить ArraySubstitution
ES_RANDOM_NOP = 0x0A0FF00, // Сюда можно подставить любой NOP-блок
ES_RANDOM_CONST = 0x0A0FF01, // Сюда можно подставит любое число
ES_RANDOM_REG = 0x0A0FF02, // Сюда можно подставить любой незанятый
// регистр
ES_RANDOM_VAR = 0x0A0FF03, // Сюда можно подставить любую незанятую
// переменную
ES_RANDOM_USE_REG = 0x0A0FF04, // Сюда можно подставить любой незанятый
// или занятый регистр
ES_RANDOM_USE_VAR = 0x0A0FF05, // Сюда можно подставить любую незанятую
// или занятую переменную
ES_VARIABLE_0 = 0x0B0FF02, // Сюда подставляются данные, актуальные
ES_VARIABLE_1 = 0x0B0FF03, // для данного блока
ES_VARIABLE_2 = 0x0B0FF04,
ES_REG_0 = 0x0C0FF05,
ES_REG_1 = 0x0C0FF06,
ES_REG_2 = 0x0C0FF07,
ES_ADDRESS_0 = 0x0D0AA08,
ES_ADDRESS_1 = 0x0D0AA09,
ES_CONST_0 = 0x0E0AA0A,
ES_CONST_1 = 0x0E0AA0B,
ES_SPECIFIC_0 = 0x0E0BB0C,
ES_SPECIFIC_1 = 0x0E0BB0D
};
static const E_SUBSTITUTION AllSubstitution[] =
{ ES_RANDOM_NOP, ES_RANDOM_CONST, ES_RANDOM_REG, ES_RANDOM_VAR,
ES_RANDOM_USE_REG, ES_RANDOM_USE_VAR,
ES_VARIABLE_0, ES_VARIABLE_1, ES_VARIABLE_2,
ES_REG_0, ES_REG_1, ES_REG_2,
ES_ADDRESS_0, ES_ADDRESS_1,
ES_CONST_0, ES_CONST_1,
ES_SPECIFIC_0, ES_SPECIFIC_1
};
unsigned AllSubstitutionSize = CALC_ARRAY_SIZE(AllSubstitution);
#endif // __P_ENUMS_H__
Файл pdebug.h.
#ifndef __PDEBUG_H__
#define __PDEBUG_H__
#ifdef _DEBUG
#define WRITE_LOG
#endif
#ifdef WRITE_LOG
void WriteToLog(LPCTSTR str, bool newLine = true);
void WriteToLog(int num, bool newLine = true);
#else
inline void WriteToLog(LPCTSTR, bool = true) { }
inline void WriteToLog(int, bool = true) { }
#endif
#endif //__PDEBUG_H__
Файл pdebug.cpp.
#include "stdafx.h"
#include
#include "pdebug.h"
#include "ckg_str.h"
#ifdef WRITE_LOG
static FILE *logFile = NULL;
void WriteToLog(LPCTSTR str, bool newLine)
{
if (!logFile)
{
logFile = _tfopen(_T("uniprot.log"), _T("wb"));
_ASSERT(logFile);
}
fwrite(str, sizeof(TCHAR), _tcslen(str), logFile);
if (newLine)
{
static LPCTSTR endStr = _T("\r\n");
fwrite(endStr, sizeof(TCHAR), _tcslen(endStr), logFile);
}
fflush(logFile);
}
void WriteToLog(int num, bool newLine)
{
CkgString str;
str.Format(_T("%d "), num);
WriteToLog(str, newLine);
}
#endif
Файл polymorphism.h.
#ifndef __POLYMORPHISM_H__
#define __POLYMORPHISM_H__
// Чему должны быть кранты размеры данных.
#define ROUND_SATA_SIZE 64
// Минимально допустимый год.
// (Вычитется в GetCurrentDayNum)
#define MIN_YEAR 1970 // бездумно не трогать.
// (подумать над DataToDay())
void CryptData (BYTE &dataArray, size_t size, BYTE &algorithmDataArray,
size_t algorithmDataSize);
void DecryptData(BYTE &dataArray, size_t size, BYTE &algorithmDataArray,
size_t algorithmDataSize);
void CryptData (BYTE &dataArray, size_t size, const TCHAR &fileName);
void DecryptData(BYTE &dataArray, size_t size, const TCHAR &fileName);
unsigned GetCurrentDayNum();
void GenerateAlgorithm(pure_c_ptr &algorithmCrypt, size_t &sizeCrypt,
pure_c_ptr &algorithmDecrypt, size_t &sizeDecrypt,
unsigned deltaTimeCrypt = 0,
unsigned deltaTimeDecrypt = 0);
void GenerateAlgorithm(const TCHAR &algorithmCryptFileName,
const TCHAR &algorithmDecryptFileName,
unsigned deltaTimeCrypt = 0,
unsigned deltaTimeDecrypt = 0);
int CoolRand();
int CoolRand(unsigned limit);
#endif // __POLYMORPHISM_H__
Файл polymorphism.cpp.
#include "stdafx.h"
#include
#include
#include
#include "resource.h"
#include "cpp_ptr.h"
#include "c_ptr.h"
#include "ckg_str.h"
#include "ckg_error.h"
#include "ckg_alloc.h"
#include "ckg_array.h"
#include "polymorphism.h"
#include "p_enums.h"
#include "blocks.h"
#include "pdebug.h"
// Количество переменных для виртуальной машины.
// В отличии от виртуальных регистров, переменные
// явдяются инициализированными до начала работы.
const unsigned variablesNum = 20;
// Количество виртуальных регистров
const unsigned registersNum = 10;
const BYTE idSupportAlgorithm = 1; // Идентификатор блока с алгоритмом
const BYTE idCryptAlgorithm = 0; // Алгоритм для шифрования
const BYTE idDecryptAlgorithm = 1; // Алгоритм для расшифрования
const unsigned maxUseTime = INT_MAX; // Ограничение по максимальному
// времени использования (дней).
typedef CkgSimpleContainerArray Block;
struct AlgorithmDataStruct
{
BYTE idSupportAlgorithm;
BYTE idType;
size_t sizeAll;
int variables[variablesNum];
unsigned numVarForSetSize; // В переменную с этим номером занести
// размер данных
};
const unsigned minSizeAlgorithm = 160; // Придельные размеры алгоритма.
const unsigned maxSizeAlgorithm = 200; //
const unsigned minNumTransformation = 2; // Придельное количество
const unsigned maxNumTransformation = 5; // трансформаций.
const unsigned numBlocks = 8; // Количество блоков.
const unsigned numBlocksBeforeLoop = 3; // Количество блоков до метки
// Loop.
const unsigned dataSizeSmoothing = ROUND_SATA_SIZE;
// Чему должны быть кранты
// размеры данных
struct AlgorithmParameters
{
unsigned sizeAlgorithm; // Размер алгоритма
unsigned numTransformation; // Количество блоков для преобразования
bool addressIsReg; // Адрес в регистре или переменной
unsigned addressNumber; // Номер переменной или регистра где
// будет храниться адрес.
bool modificatoryIsReg[maxNumTransformation];
// Модификатор регистр / переменная.
unsigned modificatorsNumbers[maxNumTransformation];
// Номера регистров/переменных для
// модификаторов.
unsigned counterIsReg; // Счетчик в регистре или переменной.
unsigned counterNumber; // Номер переменной или регистра где
// будет храниться счетчик.
unsigned initCounterNumber; // Какую переменную использовать для
// инициализации счетчика
unsigned totalNumTrueBlocks; // Сколько всего блоков должно получиться
// (без учета nops)
bool usedRegisters[registersNum]; // Занятые регистры.
bool usedVariables[variablesNum]; // Занятые перемненные.
};
//-----------------------------------------------------------------------------
#ifdef _DEBUG
void DebugTestBlock(int a)
{
unsigned sizeArrayAllSubstitution = CALC_ARRAY_SIZE(AllSubstitution);
_ASSERT(a != EO_ERROR);
for (unsigned i = 0; i < sizeArrayAllSubstitution; i++)
_ASSERT(AllSubstitution[i] != a);
}
#define DEBUG_TEST_BLOCK(a) DebugTestBlock(a)
#else
#define DEBUG_TEST_BLOCK(a)
#endif // _DEBUG
//-----------------------------------------------------------------------------
int TestRegNum(int reg)
return reg;
//-----------------------------------------------------------------------------
int TestVarNum(int var)
return var;
//-----------------------------------------------------------------------------
void SkepValue(const int *&p)
{
E_OPERAND operand = static_cast(*p++);
switch (operand)
{
case EOP_REG:
case EOP_REF_REG:
case EOP_VAR:
case EOP_REF_VAR:
case EOP_CONST: *p++; return;
case EOP_RAND: return;
default: CkgExcept(_T("error operand type"));
}
}
//-----------------------------------------------------------------------------
int GetValue(const int *&p, int &variables, int ®isters, const int &data)
{
E_OPERAND operand = static_cast(*p++);
int reg, var;
switch (operand)
{
case EOP_REG: reg = TestRegNum(*p++);
WriteToLog(_T("REG_"), false);
WriteToLog(reg, false);
return (®isters)[reg];
case EOP_REF_REG: {
reg = TestRegNum(*p++);
int n = (®isters)[reg];
WriteToLog(_T("REF_REG_"), false);
WriteToLog(reg, false);
return (&data)[n];
}
case EOP_VAR: var = TestVarNum(*p++);
WriteToLog(_T("VAR_"), false);
WriteToLog(var, false);
return (&variables)[var];
case EOP_REF_VAR: {
var = TestVarNum(*p++);
int n = (&variables)[var];
WriteToLog(_T("REF_VAR_"), false);
WriteToLog(var, false);
return (&data)[n];
}
case EOP_CONST: WriteToLog(_T("CONST "), false);
return *p++;
case EOP_RAND: WriteToLog(_T("RAND "), false);
return CoolRand();
default: CkgExcept(_T("error operand type"));
}
return 0; // anti warning
}
//-----------------------------------------------------------------------------
void SetValue(const int *&p, int &variables, int ®isters, int &data,
int value)
{
E_OPERAND operand = static_cast(*p++);
int reg, var;
switch (operand)
{
case EOP_REG: reg = TestRegNum(*p++);
(®isters)[reg] = value;
WriteToLog(_T("REG_"), false);
WriteToLog(reg, false);
break;
case EOP_REF_REG: {
reg = TestRegNum(*p++);
int n = (®isters)[reg];
(&data)[n] = value;
WriteToLog(_T("REF_REG_"), false);
WriteToLog(reg, false);
break;
}
case EOP_VAR: var = TestVarNum(*p++);
(&variables)[var] = value;
WriteToLog(_T("VAR_"), false);
WriteToLog(var, false);
break;
case EOP_REF_VAR: {
var = TestVarNum(*p++);
int n = (&variables)[var];
(&data)[n] = value;
WriteToLog(_T("REF_VAR_"), false);
WriteToLog(var, false);
break;
}
default: CkgExcept(_T("error operand type"));
}
}
//-----------------------------------------------------------------------------
void TranslateOperations(const int &operations, const int &variables,
BYTE &memory)
{
const int *p = &operations;
cpp_arr_ptr vars(new int[variablesNum]);
TestPtr(vars);
cpp_arr_ptr regs(new int[registersNum]);
TestPtr(regs);
memcpy(vars.ptr(), &variables, variablesNum * sizeof(int));
memset(regs.ptr(), 0, registersNum * sizeof(int));
int *data = reinterpret_cast(&memory);
CkgSimpleContainerArray stack;
unsigned flags = 0;
WriteToLog(_T("\r\n=== Start TranslateOperations ===\r\n"));
E_OPERATION operation;
for (;;)
{
if (*p == EO_ERROR)
CkgExcept(IDS_PL_ERROR_INSTRUCTION_IN_ALG_0);
if (*p < 0 || *p > LAST_OPERATION)
CkgExcept(IDS_PL_ERROR_INSTRUCTION_IN_ALG);
operation = static_cast(*p++);
switch (operation)
{
case EO_EXIT_0: WriteToLog(_T("exit")); return;
case EO_EXIT_1: WriteToLog(_T("exit")); return;
case EO_EXIT_2: WriteToLog(_T("exit")); return;
case EO_NOP_0: break;
case EO_NOP_1: break;
case EO_NOP_2: break;
case EO_NOP_3: break;
case EO_MOV: {
WriteToLog(_T("mov "), false);
const int *oldP = p;
SkepValue(p);
int value = GetValue(p, *vars, *regs, *data);
WriteToLog(_T(" ==> "), false);
SetValue(oldP, *vars, *regs, *data, value);
WriteToLog(_T(""));
break;
}
case EO_XCHG: {
const int *oldP = p;
WriteToLog(_T("xchg "), false);
int value1 = GetValue(p, *vars, *regs, *data);
int value2 = GetValue(p, *vars, *regs, *data);
p = oldP;
WriteToLog(_T(" "), false);
SetValue(p, *vars, *regs, *data, value2);
SetValue(p, *vars, *regs, *data, value1);
WriteToLog(_T(""));
break;
}
case EO_PUSH: {
WriteToLog(_T("push "), false);
int value = GetValue(p, *vars, *regs, *data);
WriteToLog(_T(""));
stack.Add(value);
break;
}
case EO_POP: {
WriteToLog(_T("pop "), false);
int value = stack.Remove(stack.GetSize() - 1);
SetValue(p, *vars, *regs, *data, value);
WriteToLog(_T(""));
break;
}
case EO_XOR:
case EO_AND:
case EO_OR:
case EO_ADD:
case EO_SUB:
case EO_MUL:
case EO_DIV:
case EO_NOT:
case EO_NEG:
case EO_INC:
case EO_DEC:
{
const int *oldP = p;
#ifdef WRITE_LOG
if (operation == EO_NOT)
WriteToLog(_T("not "), false);
else if (operation == EO_NEG)
WriteToLog(_T("neg "), false);
else if (operation == EO_INC)
WriteToLog(_T("inc "), false);
else if (operation == EO_DEC)
WriteToLog(_T("dec "), false);
#endif
int value = GetValue(p, *vars, *regs, *data);
if (operation == EO_NOT)
value = 0 ^ value;
else if (operation == EO_NEG)
value = -value;
else if (operation == EO_INC)
value++;
else if (operation == EO_DEC)
value--;
else
CkgExcept();
WriteToLog(" ==> ", false);
SetValue(oldP, *vars, *regs, *data, value);
WriteToLog("");
break;
}
case EO_CMP:
case EO_TEST:
{
#ifdef WRITE_LOG
if (operation == EO_CMP)
WriteToLog(_T("cmp "), false);
else if (operation == EO_TEST)
WriteToLog(_T("test "), false);
#endif
int value1 = GetValue(p, *vars, *regs, *data);
int value2 = GetValue(p, *vars, *regs, *data);
WriteToLog("");
flags = 0;
if (operation == EO_CMP)
= ((value1 == value2) * EF_ZERO)
else if (operation == EO_TEST)
{
flags = (((value1 & value2) == 0) * EF_ZERO);
}
else
CkgExcept();
break;
}
case EO_JMP: {
WriteToLog(_T("jmp "), false);
int addr = GetValue(p, *vars, *regs, *data);
WriteToLog("\r\n");
p = (&operations) + addr;
break;
}
case EO_CALL: {
WriteToLog(_T("call "), false);
int addr = GetValue(p, *vars, *regs, *data);
WriteToLog("\r\n");
stack.Add(p - (&operations));
p = (&operations) + addr;
break;
}
case EO_RET: {
WriteToLog(_T("ret\r\n"));
int addr = stack.Remove(stack.GetSize() - 1);
p = (&operations) + addr;
break;
}
case EO_JZ:
case EO_JNZ:
case EO_JA:
case EO_JNA:
{
#ifdef WRITE_LOG
if (operation == EO_JZ)
WriteToLog(_T("jz "), false);
if (operation == EO_JNZ)
WriteToLog(_T("jnz "), false);
if (operation == EO_JA)
WriteToLog(_T("ja "), false);
if (operation == EO_JNA)
WriteToLog(_T("jna "), false);
#endif
int addr = GetValue(p, *vars, *regs, *data);
WriteToLog("\r\n");
if (operation == EO_JZ && !(flags & EF_ZERO))
break;
else if (operation == EO_JNZ && (flags & EF_ZERO))
break;
else if (operation == EO_JA && !(flags & EF_ABOVE))
break;
else if (operation == EO_JNA && (flags & EF_ABOVE))
break;
p = (&operations) + addr;
break;
}
case EO_TEST_TIME_0:
{
WriteToLog(_T("test_time0 "), false);
int day = abs(GetValue(p, *vars, *regs, *data));
WriteToLog("");
if (static_cast(GetCurrentDayNum()) > day)
{
WriteToLog("ERROR TIME (except)");
data[0] ^= 0x00030001;
break;
}
WriteToLog("OK TIME (continue)");
break;
}
case EO_TEST_TIME_1:
{
WriteToLog(_T("test_time1 "), false);
int dayTmp = GetValue(p, *vars, *regs, *data);
WriteToLog("");
unsigned day = static_cast(abs(dayTmp));
if (GetCurrentDayNum()
{
WriteToLog("OK TIME (continue)");
break;
}
WriteToLog("ERROR TIME (except)");
GetValue(p, *vars, *regs, *data);
GetValue(p, *vars, *regs, *data);
SetValue(p, *vars, *regs, *data, 0);
p = (&operations) - dayTmp;
break;
}
}
}
}
//-----------------------------------------------------------------------------
void CryptDecryptData(BYTE &dataArray, size_t size, BYTE &algorithmDataArray,
size_t algorithmDataSize, bool crypt)
&algorithmDataArray;
//-----------------------------------------------------------------------------
void CryptData(BYTE &dataArray, size_t size, BYTE &algorithmDataArray,
size_t algorithmDataSize)
{
CryptDecryptData(dataArray, size, algorithmDataArray,
algorithmDataSize, true);
}
//-----------------------------------------------------------------------------
void DecryptData(BYTE &dataArray, size_t size, BYTE &algorithmDataArray,
size_t algorithmDataSize)
{
CryptDecryptData(dataArray, size, algorithmDataArray,
algorithmDataSize, false);
}
//-----------------------------------------------------------------------------
void CryptDecryptData(BYTE &dataArray, size_t size, const TCHAR &fileName,
bool crypt)
{
FILE *f = _tfopen(&fileName, _T("rb"));
if (!f)
CkgExcept(ERROR_OPEN_FILE);
try
{
if (fseek(f, 0, SEEK_END))
CkgExcept(ERROR_READ_FILE);
long algorithmDataSize = ftell(f);
cpp_arr_ptr algorithmDataArray(new BYTE[algorithmDataSize]);
TestPtr(algorithmDataArray);
if (fseek(f, 0, SEEK_SET))
CkgExcept(ERROR_READ_FILE);
if (fread(algorithmDataArray, sizeof(BYTE), algorithmDataSize, f) !=
static_cast(algorithmDataSize))
CkgExcept(ERROR_READ_FILE);
if (fclose(f))
CkgExcept(ERROR_CLOSE_FILE);
f = 0;
CryptDecryptData(dataArray, size, *algorithmDataArray,
algorithmDataSize, crypt);
}
catch (...)
{
if (f)
fclose(f);
throw;
}
}
//-----------------------------------------------------------------------------
void CryptData(BYTE &dataArray, size_t size, const TCHAR &fileName)
{
CryptDecryptData(dataArray, size, fileName, true);
}
//-----------------------------------------------------------------------------
void DecryptData(BYTE &dataArray, size_t size, const TCHAR &fileName)
{
CryptDecryptData(dataArray, size, fileName, false);
}
//-----------------------------------------------------------------------------
unsigned GetRandomNonUsedRegister(const AlgorithmParameters ¶meters)
{
unsigned i;
unsigned numberNonUsedRegisters = 0;
for (i = 0; i < registersNum; i++)
numberNonUsedRegisters += !parameters.usedRegisters[i];
if (!numberNonUsedRegisters)
CkgExcept();
unsigned randomNum = CoolRand(numberNonUsedRegisters) + 1;
for (i = 0; i < registersNum; i++)
{
randomNum -= !parameters.usedRegisters[i];
if (!randomNum)
break;
}
_ASSERT(!randomNum && !parameters.usedRegisters[i]);
return i;
}
//-----------------------------------------------------------------------------
unsigned GetRandomNonUsedVariable(const AlgorithmParameters ¶meters)
{
unsigned i;
unsigned numberNonUsedVariables = 0;
for (i = 0; i < variablesNum; i++)
numberNonUsedVariables += !parameters.usedVariables[i];
if (!numberNonUsedVariables)
CkgExcept();
unsigned randomNum = CoolRand(numberNonUsedVariables) + 1;
for (i = 0; i < variablesNum; i++)
{
randomNum -= !parameters.usedVariables[i];
if (!randomNum)
break;
}
_ASSERT(!randomNum && !parameters.usedVariables[i]);
return i;
}
//-----------------------------------------------------------------------------
unsigned ReserveRandomNonUsedRegister(AlgorithmParameters ¶meters)
{
unsigned num = GetRandomNonUsedRegister(parameters);
parameters.usedRegisters[num] = true;
return num;
}
//-----------------------------------------------------------------------------
unsigned ReserveRandomNonUsedVariables(AlgorithmParameters ¶meters)
{
unsigned num = GetRandomNonUsedVariable(parameters);
parameters.usedVariables[num] = true;
return num;
}
//-----------------------------------------------------------------------------
void RandomInitAlgorithmParameters(AlgorithmParameters ¶meters,
unsigned numTransformation)
{
unsigned i;
for (i = 0; i < registersNum; i++)
parameters.usedRegisters[i] = false;
for (i = 0; i < variablesNum; i++)
parameters.usedVariables[i] = false;
parameters.sizeAlgorithm =
CoolRand(maxSizeAlgorithm - minSizeAlgorithm) + minSizeAlgorithm;
parameters.numTransformation = numTransformation;
parameters.addressIsReg = CoolRand(2) == 1;
if (parameters.addressIsReg)
parameters.addressNumber = ReserveRandomNonUsedRegister(parameters);
else
parameters.addressNumber = ReserveRandomNonUsedVariables(parameters);
for (i = 0; i < parameters.numTransformation; i++)
{
bool isReg = CoolRand(2) == 1;
parameters.modificatoryIsReg[i] = isReg;
if (isReg)
parameters.modificatorsNumbers[i] = ReserveRandomNonUsedRegister(parameters);
else
parameters.modificatorsNumbers[i] = ReserveRandomNonUsedVariables(parameters);
}
parameters.counterIsReg = CoolRand(2);
if (parameters.counterIsReg)
parameters.counterNumber = ReserveRandomNonUsedRegister(parameters);
else
parameters.counterNumber = ReserveRandomNonUsedVariables(parameters);
parameters.initCounterNumber = ReserveRandomNonUsedVariables(parameters);
parameters.totalNumTrueBlocks =
numBlocks + parameters.numTransformation * 2 - 2;
}
//-----------------------------------------------------------------------------
void RandomInitAlgorithmParameters(AlgorithmParameters (¶meters)[2])
{
SYSTEMTIME lpSystemTime;
GetSystemTime(&lpSystemTime);
srand(unsigned(lpSystemTime.wSecond) * 1000 + lpSystemTime.wMilliseconds);
unsigned numTransformation = (maxNumTransformation > minNumTransformation) ?
CoolRand(maxNumTransformation - minNumTransformation) + minNumTransformation :
1;
RandomInitAlgorithmParameters(parameters[0], numTransformation);
RandomInitAlgorithmParameters(parameters[1], numTransformation);
}
//-----------------------------------------------------------------------------
bool SearchSubstitution(const Block &block, unsigned &position)
{
unsigned blockSize = block.GetSize();
_ASSERT(position
for (; position < blockSize; position++)
{
int a = block[position];
for (unsigned i = 0; i < AllSubstitutionSize; i++)
if (AllSubstitution[i] == a)
return true;
}
return false;
}
//-----------------------------------------------------------------------------
struct SAppropriate
{
bool testSize;
unsigned maxSize;
bool testContain;
const int *shouldContain;
unsigned numShouldContain;
bool testNotContain;
unsigned numNotShouldContain;
const int *notShouldContain;
SAppropriate() : testSize(false), maxSize(0),
testContain(false), shouldContain(NULL), numShouldContain(0),
testNotContain(false), notShouldContain(NULL), numNotShouldContain(0)
{ }
~SAppropriate() { }
};
//-----------------------------------------------------------------------------
bool Search(const int &block, unsigned blockSize, int needFind)
{
_ASSERT(blockSize);
unsigned j;
for (j = 0; j < blockSize; j++)
if ((&block)[j] == needFind)
break;
return !(j == blockSize);
}
//-----------------------------------------------------------------------------
bool SearchRandomAppropriateBlock(unsigned numberBlockForTest,
const unsigned &blocksSize,
const int * const &addrBlocks,
const SAppropriate &appropriate,
unsigned &retAppropriateBlock)
{
_ASSERT(numberBlockForTest);
CkgSimpleContainerArray convenianceSample;
for (unsigned i = 0; i < numberBlockForTest; i++)
{
unsigned blockSize = (&blocksSize)[i];
_ASSERT(blockSize);
if (appropriate.testSize && blockSize > appropriate.maxSize)
continue;
const int *block = (&addrBlocks)[i];
_ASSERT(block);
if (appropriate.testContain)
{
_ASSERT(appropriate.shouldContain && appropriate.numShouldContain);
bool found = true;
for (unsigned j = 0; j < appropriate.numShouldContain && found; j++)
{
int needFind = appropriate.shouldContain[j];
found = Search(*block, blockSize, needFind);
}
if (!found)
continue;
}
if (appropriate.testNotContain)
{
_ASSERT(appropriate.notShouldContain && appropriate.numNotShouldContain);
bool found = false;
for (unsigned j = 0; j < appropriate.numNotShouldContain && !found; j++)
{
int needFind = appropriate.notShouldContain[j];
found = Search(*block, blockSize, needFind);
}
if (found)
continue;
}
convenianceSample.Add(i);
}
unsigned numConvenianceSample = convenianceSample.GetSize();
if (!numConvenianceSample)
return false;
unsigned select = numConvenianceSample > 1 ?
CoolRand(numConvenianceSample) :
0;
retAppropriateBlock = convenianceSample[select];
return true;
}
//-----------------------------------------------------------------------------
bool ReplacemenRandomEntity(int &entity, const AlgorithmParameters ¶meters)
{
switch (entity)
{
case ES_RANDOM_NOP: {
unsigned NumNops = LAST_DEFINED_NOP - EO_NOP_0;
entity = CoolRand(NumNops);
entity += EO_NOP_0;
_ASSERT(entity >= EO_NOP_0 && entity
break;
}
case ES_RANDOM_CONST: entity = CoolRand(); break;
case ES_RANDOM_REG: entity = GetRandomNonUsedRegister(parameters); break;
case ES_RANDOM_VAR: entity = GetRandomNonUsedVariable(parameters); break;
case ES_RANDOM_USE_REG: entity = CoolRand(registersNum); break;
case ES_RANDOM_USE_VAR: entity = CoolRand(variablesNum); break;
default: return false;
}
return true;
}
//-----------------------------------------------------------------------------
void CreateNopBlock(Block &block, AlgorithmParameters ¶meters, cpp_arr_ptr &,
unsigned maxSize)
{
_ASSERT(block.IsEmpty());
if (!maxSize)
CkgExcept();
SAppropriate appropriate;
appropriate.testSize = true;
appropriate.maxSize = maxSize;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_Nops, *sizeBlocks_Nops,
*blocks_Nops, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_Nops[index]; i++)
block.Add(blocks_Nops[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
CkgExcept();
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock0_(Block &block, AlgorithmParameters ¶meters, cpp_arr_ptr &)
{
_ASSERT(block.IsEmpty());
SAppropriate appropriate;
appropriate.testContain = true;
appropriate.numShouldContain = 1;
int whatSearch = parameters.addressIsReg ? ES_REG_0 : ES_VARIABLE_0;
appropriate.shouldContain = &whatSearch;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_00, *sizeBlocks_00,
*blocks_00, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_00[index]; i++)
block.Add(blocks_00[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
{
int newValue = EO_ERROR;
int b = block[position];
switch (b)
{
case ES_REG_0: _ASSERT(parameters.addressIsReg);
newValue = parameters.addressNumber;
break;
case ES_VARIABLE_0: _ASSERT(!parameters.addressIsReg);
newValue = parameters.addressNumber;
break;
default: CkgExcept();
}
block.GetRef(position) = newValue;
}
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock0(Block block[], AlgorithmParameters parameters[], cpp_arr_ptr vars[])
{
CreateBlock0_(block[0], parameters[0], vars[0]);
CreateBlock0_(block[1], parameters[1], vars[1]);
}
//-----------------------------------------------------------------------------
void CreateBlock1_(Block &block, AlgorithmParameters ¶meters, cpp_arr_ptr &)
{
_ASSERT(block.IsEmpty());
SAppropriate appropriate;
appropriate.testContain = true;
appropriate.numShouldContain = 1;
int whatSearch = parameters.counterIsReg ? ES_REG_0 : ES_VARIABLE_0;
appropriate.shouldContain = &whatSearch;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_01, *sizeBlocks_01,
*blocks_01, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_01[index]; i++)
block.Add(blocks_01[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
{
int newValue = EO_ERROR;
int b = block[position];
switch (b)
{
case ES_REG_0: _ASSERT(parameters.counterIsReg);
newValue = parameters.counterNumber;
break;
case ES_VARIABLE_0: _ASSERT(!parameters.counterIsReg);
newValue = parameters.counterNumber;
break;
case ES_VARIABLE_1: newValue =
parameters.initCounterNumber;
break;
default: CkgExcept();
}
block.GetRef(position) = newValue;
}
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock1(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[])
{
CreateBlock1_(block[0], parameters[0], vars[0]);
CreateBlock1_(block[1], parameters[1], vars[1]);
}
//-----------------------------------------------------------------------------
void CreateBlock2_(Block &block, AlgorithmParameters ¶meters,
cpp_arr_ptr &vars, unsigned n, int randValue)
{
_ASSERT(n < maxNumTransformation);
SAppropriate appropriate;
appropriate.testContain = true;
appropriate.numShouldContain = 1;
int whatSearch = parameters.modificatoryIsReg[n] ? ES_REG_0 : ES_VARIABLE_0;
appropriate.shouldContain = &whatSearch;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_02, *sizeBlocks_02,
*blocks_02, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_02[index]; i++)
block.Add(blocks_02[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
{
int newValue = EO_ERROR;
int b = block[position];
switch (b)
{
case ES_REG_0: _ASSERT(parameters.modificatoryIsReg[n]);
newValue = parameters.modificatorsNumbers[n];
break;
case ES_VARIABLE_0: _ASSERT(!parameters.modificatoryIsReg[n]);
newValue = parameters.modificatorsNumbers[n];
break;
case ES_VARIABLE_1: {
unsigned varNum =
ReserveRandomNonUsedVariables(parameters);
vars[varNum] = randValue;
newValue = static_cast(varNum);
break;
}
case ES_CONST_0: newValue = randValue;
break;
default: CkgExcept();
}
block.GetRef(position) = newValue;
}
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock2(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[], unsigned n)
{
int randValue = CoolRand();
CreateBlock2_(block[0], parameters[0], vars[0], n, randValue);
CreateBlock2_(block[1], parameters[1], vars[1], n, randValue);
}
//-----------------------------------------------------------------------------
void CalcBlocksSize(Block (*blocks)[2], unsigned num, unsigned &size1, unsigned &size2)
{
_ASSERT(num);
unsigned i;
size1 = 0;
for (i = 0; i < num; i++)
size1 += blocks[i][0].GetSize();
size2 = 0;
for (i = 0; i < num; i++)
size2 += blocks[i][1].GetSize();
}
//-----------------------------------------------------------------------------
void CreateLoopAddres_(unsigned num, const AlgorithmParameters ¶meters,
unsigned sizeBeforeLoop,
unsigned &addr)
{
const double dispersion = 0.1;
const double k = (static_cast(CoolRand()) / INT_MAX) * dispersion;
_ASSERT(fabs(k)
const double allSize = parameters.sizeAlgorithm;
const double sizeInBlocks = num;
const double allSizeInBlocks = parameters.totalNumTrueBlocks;
double randAddr = sizeInBlocks * allSize / allSizeInBlocks;
_ASSERT(static_cast(randAddr) > sizeBeforeLoop);
randAddr += randAddr * k;
addr = static_cast(randAddr);
_ASSERT(addr >= sizeBeforeLoop);
if (addr < sizeBeforeLoop)
CkgExcept();
}
//-----------------------------------------------------------------------------
void CreateLoopAddres(unsigned num, const AlgorithmParameters parameters[],
unsigned sizeBeforeLoop1,
unsigned sizeBeforeLoop2,
unsigned &addr1, unsigned &addr2)
{
_ASSERT(sizeBeforeLoop1 && sizeBeforeLoop2);
CreateLoopAddres_(num, parameters[0], sizeBeforeLoop1, addr1);
CreateLoopAddres_(num, parameters[1], sizeBeforeLoop2, addr2);
}
//-----------------------------------------------------------------------------
void CreateBlock3_(Block &block, AlgorithmParameters ¶meters,
cpp_arr_ptr &, unsigned n, int &numSelectedBlock,
bool useCounterForModify)
{
_ASSERT(CALC_ARRAY_SIZE(block_03_operation_AB) ==
CALC_ARRAY_SIZE(block_03_operation_BA));
bool isBA = numSelectedBlock != -1;
if (!isBA)
{
numSelectedBlock = CALC_ARRAY_SIZE(block_03_operation_AB) > 1 ?
CoolRand(CALC_ARRAY_SIZE(block_03_operation_AB)) : 0;
}
SAppropriate appropriate;
appropriate.testContain = true;
appropriate.numShouldContain = 1 + useCounterForModify;
unsigned index;
int whatSearch[2];
whatSearch[0] = parameters.addressIsReg ? ES_REG_0 : ES_VARIABLE_0;
whatSearch[1] = parameters.counterIsReg ? ES_REG_2 : ES_VARIABLE_2;
appropriate.shouldContain = whatSearch;
appropriate.testNotContain = true;
appropriate.numNotShouldContain = 2 + (!useCounterForModify) * 2;
int whatNotContain[4];
appropriate.notShouldContain = whatNotContain;
whatNotContain[0] = !parameters.modificatoryIsReg[n] ?
ES_REG_1 : ES_VARIABLE_1;
whatNotContain[1] = !parameters.counterIsReg ?
ES_REG_2 : ES_VARIABLE_2;
whatNotContain[2] = ES_VARIABLE_2;
whatNotContain[3] = ES_REG_2;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_03, *sizeBlocks_03,
*blocks_03, appropriate, index))
CkgExcept();
index;
for (unsigned i = 0; i < sizeBlocks_03[index]; i++)
block.Add(blocks_03[index][i]);
unsigned position = 0;
int checkCountUse = useCounterForModify;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
{
int newValue = EO_ERROR;
int b = block[position];
switch (b)
{
case ES_REG_0: _ASSERT(parameters.addressIsReg);
newValue = parameters.addressNumber;
break;
case ES_REG_1: _ASSERT(parameters.modificatoryIsReg[n]);
newValue = parameters.modificatorsNumbers[n];
break;
case ES_REG_2: _ASSERT(parameters.counterIsReg);
newValue = parameters.counterNumber;
checkCountUse--;
_ASSERT(checkCountUse == 0);
break;
case ES_VARIABLE_0: _ASSERT(!parameters.addressIsReg);
newValue = parameters.addressNumber;
break;
case ES_VARIABLE_1: _ASSERT(!parameters.modificatoryIsReg[n]);
newValue = parameters.modificatorsNumbers[n];
break;
case ES_VARIABLE_2: _ASSERT(!parameters.counterIsReg);
newValue = parameters.counterNumber;
checkCountUse--;
_ASSERT(checkCountUse == 0);
break;
case ES_SPECIFIC_0: if (isBA)
newValue = block_03_operation_BA[numSelectedBlock];
else
newValue = block_03_operation_AB[numSelectedBlock];
break;
default: CkgExcept();
}
block.GetRef(position) = newValue;
}
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
if (checkCountUse != 0)
CkgExcept(_T("Ошибка в алгоритме генерации UPT-файлов (function CreateBlock3_). Обратитесь к разработчику."));
}
//-----------------------------------------------------------------------------
void CreateBlock3AB(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[], unsigned n,
int &numSelectedBlock, bool useCounterForModify)
{
_ASSERT(vars && n < maxNumTransformation);
numSelectedBlock = -1;
CreateBlock3_(block[0], parameters[0], vars[0], n, numSelectedBlock,
useCounterForModify);
_ASSERT(numSelectedBlock >= 0);
}
//-----------------------------------------------------------------------------
void CreateBlock3BA(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[], unsigned n,
int numSelectedBlock, bool useCounterForModify)
{
_ASSERT(vars && n < maxNumTransformation);
_ASSERT(numSelectedBlock >= 0);
CreateBlock3_(block[1], parameters[1], vars[1], n, numSelectedBlock,
useCounterForModify);
}
//-----------------------------------------------------------------------------
void CreateBlock4_(Block &block, AlgorithmParameters ¶meters, cpp_arr_ptr &)
{
_ASSERT(block.IsEmpty());
SAppropriate appropriate;
appropriate.testContain = true;
appropriate.numShouldContain = 1;
int whatSearch = parameters.addressIsReg ? ES_REG_0 : ES_VARIABLE_0;
appropriate.shouldContain = &whatSearch;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_04, *sizeBlocks_04,
*blocks_04, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_04[index]; i++)
block.Add(blocks_04[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
{
int newValue = EO_ERROR;
int b = block[position];
switch (b)
{
case ES_REG_0: _ASSERT(parameters.addressIsReg);
newValue = parameters.addressNumber;
break;
case ES_VARIABLE_0: _ASSERT(!parameters.addressIsReg);
newValue = parameters.addressNumber;
break;
default: CkgExcept();
}
block.GetRef(position) = newValue;
}
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock4(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[])
{
CreateBlock4_(block[0], parameters[0], vars[0]);
CreateBlock4_(block[1], parameters[1], vars[1]);
}
//-----------------------------------------------------------------------------
void CreateBlock5_(Block &block, AlgorithmParameters ¶meters,
cpp_arr_ptr &, unsigned addr)
{
_ASSERT(block.IsEmpty());
SAppropriate appropriate;
appropriate.testContain = true;
appropriate.numShouldContain = 1;
int whatSearch = parameters.counterIsReg ? ES_REG_0 : ES_VARIABLE_0;
appropriate.shouldContain = &whatSearch;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_05, *sizeBlocks_05,
*blocks_05, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_05[index]; i++)
block.Add(blocks_05[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
{
int newValue = EO_ERROR;
int b = block[position];
switch (b)
{
case ES_REG_0: _ASSERT(parameters.counterIsReg);
newValue = parameters.counterNumber;
break;
case ES_VARIABLE_0: _ASSERT(!parameters.counterIsReg);
newValue = parameters.counterNumber;
break;
case ES_ADDRESS_0: newValue = static_cast(addr);
break;
default: CkgExcept();
}
block.GetRef(position) = newValue;
}
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock5(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[], unsigned addr1, unsigned addr2)
{
CreateBlock5_(block[0], parameters[0], vars[0], addr1);
CreateBlock5_(block[1], parameters[1], vars[1], addr2);
}
//-----------------------------------------------------------------------------
void CreateBlock6_(Block &block, AlgorithmParameters ¶meters,
cpp_arr_ptr &vars, int deltaTime)
{
_ASSERT(block.IsEmpty());
SAppropriate appropriate;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_06, *sizeBlocks_06,
*blocks_06, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_06[index]; i++)
block.Add(blocks_06[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
{
int newValue = EO_ERROR;
int b = block[position];
switch (b)
{
case ES_CONST_0: newValue = deltaTime;
break;
case ES_VARIABLE_0: newValue = ReserveRandomNonUsedVariables(parameters);
vars[static_cast(newValue)] = deltaTime;
break;
default: CkgExcept();
}
block.GetRef(position) = newValue;
}
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock6(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[], unsigned deltaTimeCrypt,
unsigned deltaTimeDecrypt)
{
_ASSERT((deltaTimeCrypt == 0) == (deltaTimeDecrypt == 0));
if (!deltaTimeCrypt)
{
int entity;
unsigned NumNops = LAST_DEFINED_NOP - EO_NOP_0;
entity = CoolRand(NumNops);
entity += EO_NOP_0;
_ASSERT(entity >= EO_NOP_0 && entity
block->Add(entity);
return;
}
if (deltaTimeCrypt > maxUseTime || deltaTimeCrypt > INT_MAX ||
deltaTimeDecrypt > maxUseTime || deltaTimeDecrypt > INT_MAX)
CkgExcept(_T("Задан слишком большой период времени для возможности использования алгоритма."));
bool invert = CoolRand(2) == 1;
int newDeltaTimeCrypt = invert ? -static_cast(deltaTimeCrypt) :
static_cast(deltaTimeCrypt);
invert = CoolRand(2) == 1;
int newDeltaTimeDecrypt = invert ? -static_cast(deltaTimeDecrypt) :
static_cast(deltaTimeDecrypt);
CreateBlock6_(block[0], parameters[0], vars[0], newDeltaTimeCrypt);
CreateBlock6_(block[1], parameters[1], vars[1], newDeltaTimeDecrypt);
}
//-----------------------------------------------------------------------------
void CreateBlock7_(Block &block, AlgorithmParameters ¶meters,
cpp_arr_ptr &)
{
_ASSERT(block.IsEmpty());
SAppropriate appropriate;
unsigned index;
if (!SearchRandomAppropriateBlock(sizeBlocksArray_07, *sizeBlocks_07,
*blocks_07, appropriate, index))
CkgExcept();
for (unsigned i = 0; i < sizeBlocks_07[index]; i++)
block.Add(blocks_07[index][i]);
unsigned position = 0;
while (SearchSubstitution(block, position))
{
if (!ReplacemenRandomEntity(block.GetRef(position), parameters))
CkgExcept();
DEBUG_TEST_BLOCK(block.Get(position));
position++;
}
}
//-----------------------------------------------------------------------------
void CreateBlock7(Block block[], AlgorithmParameters parameters[],
cpp_arr_ptr vars[])
{
CreateBlock7_(block[0], parameters[0], vars[0]);
CreateBlock7_(block[1], parameters[1], vars[1]);
}
//-----------------------------------------------------------------------------
void GenerateArrayRndDeltas(CkgSimpleContainerArray &deltas,
unsigned num, unsigned freeRegionSize)
{
_ASSERT(num && freeRegionSize);
_ASSERT(deltas.IsEmpty());
unsigned i;
for (i = 0; i < num; i++)
{
unsigned rnd;
#ifdef _DEBUG
unsigned counter = 0;
#endif
do
{
_ASSERT(counter++ < 10);
rnd = CoolRand(freeRegionSize);
if (freeRegionSize
CkgExcept(_T("Ошибка в алгоритме генерации UPT-файлов (function GenerateArrayRndDeltas). Обратитесь к разработчику."));
} while(deltas.IndexOf(rnd) != -1);
deltas.Add(rnd);
}
deltas.Add(freeRegionSize);
for (i = 0; i < deltas.GetSize() - 1; i++)
for (unsigned j = i + 1; j < deltas.GetSize(); j++)
if (deltas[j] < deltas[i])
deltas.Swap(j, i);
for (i = deltas.GetSize() - 1; i > 0; i--)
{
_ASSERT(deltas[i] > deltas[i - 1]);
deltas.GetRef(i) -= deltas[i - 1];
}
#ifdef _DEBUG
{
unsigned size = 0;
for (i = 0; i < deltas.GetSize(); i++)
size += deltas[i];
_ASSERT(size == freeRegionSize);
}
#endif
}
//-----------------------------------------------------------------------------
void GenerateAndAddNopBlocks(const CkgSimpleContainerArray &deltas,
CkgArray &newArray,
AlgorithmParameters ¶meters,
cpp_arr_ptr vars[],
Block (*blocks)[2], bool isBA,
unsigned numFirstBlock)
{
_ASSERT(!deltas.IsEmpty());
for (unsigned i = 0; i < deltas.GetSize(); i++)
{
unsigned delta = deltas[i];
while (delta)
{
cpp_ptr nopBlock(new Block);
TestPtr(nopBlock);
CreateNopBlock(*nopBlock, parameters, *vars, delta);
unsigned nopBlockSize = nopBlock->GetSize();
_ASSERT(nopBlockSize && nopBlockSize
delta -= nopBlockSize;
newArray.Add(*nopBlock);
nopBlock.Detach();
}
if (i != deltas.GetSize() - 1)
{
cpp_ptr tmp(new Block);
TestPtr(tmp);
unsigned size = blocks[numFirstBlock + i][isBA].GetSize();
for (unsigned j = 0; j < size; j++)
tmp->Add(blocks[numFirstBlock + i][isBA][j]);
newArray.Add(*tmp);
tmp.Detach();
}
}
}
//-----------------------------------------------------------------------------
void SmearAndAddNopBlocks(Block (*blocks)[2], bool isBA,
AlgorithmParameters ¶meters,
cpp_arr_ptr vars[],
CkgArray &newArray, unsigned addr)
{
_ASSERT(blocks && vars && newArray.IsEmpty());
unsigned i;
unsigned freeRegionSize = addr;
unsigned totalNumTrueBlocks = parameters.totalNumTrueBlocks;
unsigned blocksBeforeLoop = numBlocksBeforeLoop + parameters.numTransformation - 1;
unsigned blocksAfterLoop = totalNumTrueBlocks - blocksBeforeLoop;
for (i = 0; i < blocksBeforeLoop; i++)
freeRegionSize -= blocks[i][isBA].GetSize();
_ASSERT(static_cast(freeRegionSize) > 0); // Не ошибка, но "рисково" получилось.
CkgSimpleContainerArray deltas;
GenerateArrayRndDeltas(deltas, blocksBeforeLoop, freeRegionSize);
_ASSERT(deltas.GetSize() == blocksBeforeLoop + 1);
GenerateAndAddNopBlocks(deltas, newArray, parameters, vars,
blocks, isBA, 0);
#ifdef _DEBUG
{
unsigned size = 0;
for (i = 0; i < newArray.GetSize(); i++)
size += newArray[i].GetSize();
_ASSERT(size == addr);
}
#endif
deltas.Clear();
_ASSERT(parameters.sizeAlgorithm > addr);
freeRegionSize = parameters.sizeAlgorithm - addr;
for (i = blocksBeforeLoop; i < totalNumTrueBlocks; i++)
freeRegionSize -= blocks[i][isBA].GetSize();
_ASSERT(static_cast(freeRegionSize) > 0); // Не ошибка, но "рисково" получилось.
GenerateArrayRndDeltas(deltas, blocksAfterLoop, freeRegionSize);
_ASSERT(deltas.GetSize() == blocksAfterLoop + 1);
GenerateAndAddNopBlocks(deltas, newArray, parameters, vars,
blocks, isBA, blocksBeforeLoop);
}
//-----------------------------------------------------------------------------
static int DebugFindMaxBlockSize(unsigned n, const unsigned *sizes)
{
_ASSERT(n && sizes);
unsigned max = 0;
for (unsigned i = 0; i < n; i++)
if (max < sizes[i])
max = sizes[i];
_ASSERT(max);
return max;
}
//-----------------------------------------------------------------------------
static void DebugTestParam()
{
unsigned sum = 0;
sum += DebugFindMaxBlockSize(sizeBlocksArray_00, sizeBlocks_00);
sum += DebugFindMaxBlockSize(sizeBlocksArray_01, sizeBlocks_01);
sum += DebugFindMaxBlockSize(sizeBlocksArray_02, sizeBlocks_02);
sum += DebugFindMaxBlockSize(sizeBlocksArray_03, sizeBlocks_03);
sum += DebugFindMaxBlockSize(sizeBlocksArray_04, sizeBlocks_04);
sum += DebugFindMaxBlockSize(sizeBlocksArray_05, sizeBlocks_05);
sum += DebugFindMaxBlockSize(sizeBlocksArray_06, sizeBlocks_06);
sum += DebugFindMaxBlockSize(sizeBlocksArray_07, sizeBlocks_07);
WriteToLog(_T("Calc Max Algorithm Size = "), false);
WriteToLog(sum);
// Если меньше, то наверно легко словить ошибку.
_ASSERT(sum * 2 < minSizeAlgorithm);
}
//-----------------------------------------------------------------------------
void GenerateAlgorithm(pure_c_ptr &algorithmCrypt, size_t &sizeCrypt,
pure_c_ptr &algorithmDecrypt, size_t &sizeDecrypt,
unsigned deltaTimeCrypt, unsigned deltaTimeDecrypt)
{
WriteToLog(_T("GenerateAlgorithm()"));
#ifdef _DEBUG
DebugTestParam();
#endif
unsigned i, j;
AlgorithmParameters parameters[2];
RandomInitAlgorithmParameters(parameters);
cpp_arr_ptr vars[2];
for (unsigned k = 0; k < 2; k++)
{
vars[k] = new int[variablesNum * sizeof(int)];
TestPtr(vars[k]);
for (i = 0; i < variablesNum; i++)
vars[k][i] = CoolRand();
}
Block (*blocks)[2] = new Block[parameters[0].totalNumTrueBlocks][2];
cpp_arr_ptr memControl(blocks);
unsigned num = 0;
CreateBlock0(blocks[num++], parameters, vars);
CreateBlock1(blocks[num++], parameters, vars);
for (i = 0; i < parameters[0].numTransformation; i++)
CreateBlock2(blocks[num++], parameters, vars, i);
unsigned sizeBeforeLoop1, sizeBeforeLoop2;
CalcBlocksSize(blocks, num, sizeBeforeLoop1, sizeBeforeLoop2);
unsigned addr1 = 0, addr2 = 0;
CreateLoopAddres(num, parameters, sizeBeforeLoop1, sizeBeforeLoop2, addr1, addr2);
CkgSimpleContainerArray selectedBlocks;
CkgSimpleContainerArray arrUseCounterForModify;
for (i = 0; i < parameters[0].numTransformation; i++)
{
int numSelectedBlock = -1;
bool useCounterForModify = CoolRand(2) == 1;
CreateBlock3AB(blocks[num++], parameters, vars, i, numSelectedBlock,
useCounterForModify);
selectedBlocks.Add(numSelectedBlock);
arrUseCounterForModify.Add(useCounterForModify);
}
_ASSERT(selectedBlocks.GetSize() == parameters[0].numTransformation);
for (i = 0; i < parameters[0].numTransformation; i++)
{
CreateBlock3BA(blocks[num - 1 - i], parameters, vars, i,
selectedBlocks[i], arrUseCounterForModify[i]);
}
CreateBlock4(blocks[num++], parameters, vars);
CreateBlock5(blocks[num++], parameters, vars, addr1, addr2);
CreateBlock6(blocks[num++], parameters, vars, deltaTimeCrypt, deltaTimeDecrypt);
CreateBlock7(blocks[num++], parameters, vars);
_ASSERT(num == parameters[0].totalNumTrueBlocks);
CkgArray blocksAB;
CkgArray blocksBA;
SmearAndAddNopBlocks(blocks, false, parameters[0], vars, blocksAB, addr1);
SmearAndAddNopBlocks(blocks, true, parameters[1], vars, blocksBA, addr2);
#ifdef _DEBUG
{
unsigned sizeAB = 0;
for (i = 0; i < blocksAB.GetSize(); i++)
sizeAB += blocksAB[i].GetSize();
unsigned sizeBA = 0;
for (i = 0; i < blocksBA.GetSize(); i++)
sizeBA += blocksBA[i].GetSize();
_ASSERT(sizeAB == parameters[0].sizeAlgorithm);
_ASSERT(sizeBA == parameters[1].sizeAlgorithm);
}
#endif
unsigned sizeAB = sizeof(AlgorithmDataStruct) +
parameters[0].sizeAlgorithm * sizeof(int);
unsigned sizeBA = sizeof(AlgorithmDataStruct) +
parameters[1].sizeAlgorithm * sizeof(int);
pure_c_ptr algorithmAB(static_cast(AccurateMalloc(sizeAB)));
pure_c_ptr algorithmBA(static_cast(AccurateMalloc(sizeBA)));
AlgorithmDataStruct &algorithmStructAB =
reinterpret_cast(*algorithmAB);
AlgorithmDataStruct &algorithmStructBA =
reinterpret_cast(*algorithmBA);
algorithmStructAB.idSupportAlgorithm = idSupportAlgorithm;
algorithmStructAB.idType = idCryptAlgorithm;
algorithmStructAB.sizeAll = sizeAB;
algorithmStructAB.numVarForSetSize = parameters[0].initCounterNumber;
memcpy(algorithmStructAB.variables, vars[0], sizeof(int) * variablesNum);
algorithmStructBA.idSupportAlgorithm = idSupportAlgorithm;
algorithmStructBA.idType = idDecryptAlgorithm;
algorithmStructBA.sizeAll = sizeBA;
algorithmStructBA.numVarForSetSize = parameters[1].initCounterNumber;
memcpy(algorithmStructBA.variables, vars[1], sizeof(int) * variablesNum);
_ASSERT(sizeof(AlgorithmDataStruct) % sizeof(int) == 0);
int *p = algorithmAB + sizeof(AlgorithmDataStruct) / sizeof(int);
for (i = 0; i < blocksAB.GetSize(); i++)
for (j = 0; j < blocksAB[i].GetSize(); j++)
*p++ = blocksAB[i][j];
p = algorithmBA + sizeof(AlgorithmDataStruct) / sizeof(int);
for (i = 0; i < blocksBA.GetSize(); i++)
for (j = 0; j < blocksBA[i].GetSize(); j++)
*p++ = blocksBA[i][j];
algorithmCrypt = reinterpret_cast(algorithmAB.ptr());
algorithmAB.Detach();
sizeCrypt = sizeAB;
algorithmDecrypt = reinterpret_cast(algorithmBA.ptr());
algorithmBA.Detach();
sizeDecrypt = sizeBA;
}
//-----------------------------------------------------------------------------
void GenerateAlgorithm(const TCHAR &algorithmCryptFileName,
const TCHAR &algorithmDecryptFileName,
unsigned deltaTimeCrypt,
unsigned deltaTimeDecrypt)
{
pure_c_ptr algorithmCrypt;
size_t sizeCrypt;
pure_c_ptr algorithmDecrypt;
size_t sizeDecrypt;
GenerateAlgorithm(algorithmCrypt, sizeCrypt, algorithmDecrypt, sizeDecrypt,
deltaTimeCrypt, deltaTimeDecrypt);
if(!algorithmCrypt || !sizeCrypt || !algorithmDecrypt || !sizeDecrypt)
CkgExcept();
FILE *f = NULL;
try
{
f = _tfopen(&algorithmCryptFileName, _T("wb"));
if (!f)
CkgExcept(ERROR_OPEN_FILE);
if (fwrite(algorithmCrypt, sizeof(BYTE), sizeCrypt, f) != sizeCrypt)
CkgExcept(ERROR_WRITE_FILE);
if (fclose(f))
CkgExcept(ERROR_CLOSE_FILE);
f = _tfopen(&algorithmDecryptFileName, _T("wb"));
if (!f)
CkgExcept(ERROR_OPEN_FILE);
if (fwrite(algorithmDecrypt, sizeof(BYTE), sizeDecrypt, f) != sizeDecrypt)
CkgExcept(ERROR_WRITE_FILE);
if (fclose(f))
CkgExcept(ERROR_CLOSE_FILE);
}
catch (...)
{
if (f)
fclose(f);
throw;
}
}
//-----------------------------------------------------------------------------
int CoolRand()
{
static unsigned flagInit;
int a = rand();
if (flagInit == 0)
{
SYSTEMTIME lpSystemTime;
GetSystemTime(&lpSystemTime);
srand(unsigned(lpSystemTime.wSecond) * 1000 + lpSystemTime.wMilliseconds);
flagInit = 1000;
}
else
flagInit--;
int b = rand();
int c = rand();
a
b
c += a;
c ^= b;
return c;
}
//-----------------------------------------------------------------------------
int CoolRand(unsigned limit)
{
_ASSERT(limit > 1);
return static_cast(CoolRand()) % limit;
}
//-----------------------------------------------------------------------------
static unsigned DataToDay(unsigned Year, unsigned Month, unsigned Day)
{
if (Month > 2)
++Month;
else
{
Month+=13;
--Year;
}
return static_cast(365.25*Year) +
static_cast(30.6*Month) + Day;
}
//=============================================================================unsigned GetCurrentDayNum()
unsigned GetCurrentDayNum()
{
SYSTEMTIME lpSystemTime;
GetSystemTime(&lpSystemTime);
unsigned year = lpSystemTime.wYear;
unsigned month = lpSystemTime.wMonth;
unsigned day = lpSystemTime.wDay;
unsigned temp = DataToDay(year, month, day);
if (year < MIN_YEAR)
CkgExcept(_T("На компьютере выставлен неверный год."));
year -= MIN_YEAR;
unsigned result = DataToDay(year, month, day);
if (temp == result)
return INT_MAX - 1;
if (DataToDay(year, month, day + 12) != result + 12)
return INT_MAX;
return result;
}
//-----------------------------------------------------------------------------
Файл ArchiverBase.h.
#ifndef __ARCHIVERBASE_H_
#define __ARCHIVERBASE_H_
#include "resource.h" // main symbols
const static DWORD signature = 0xCAB00100;
enum EIAB_ErrorNum
{
IAB_OK = 0,
IAB_ERROR_BUF_SIZE = 1,
IAB_ERROR_ALLOCATE_MEMORY = 2,
IAB_CRC_ERROR = 3,
IAB_THIS_IS_NOT_ARCHIVE = 4,
IAB_UNKNOWN_ERROR = 5
};
struct TitleArcData
{
DWORD signature; // Для идентификации, что это действительно
// поддерживаемая TitleArcData
unsigned long crcPack; // CRC всех данных после упаковки, кроме
// этого первого и второго пля
// (TitleArcData естественно не пакуется)
bool isPacked; // = true - данные были сжаты
// = false - данные не сжаты, так как слишком
// плохо пакуются (записаны как есть)
unsigned long sizeUnpack;// Размер распакованных данных
unsigned long crcUnpack; // CRC распакованных данных
unsigned long titleSize; // Размер структуры TitleArcData
// Предназначено для возможности дальнейшего
// расширения этой структуры
static inline GetSizeSkeep() // Сколько отступит, чтоб посчитать crcPack
{ return sizeof(DWORD) + sizeof(unsigned long); }
};
bool Crc32(
/* [in] */ unsigned long size,
/* [size_is][in] */ byte __RPC_FAR *buf,
/* [retval][out] */ unsigned long __RPC_FAR *crc);
bool Crc32Continue(
/* [in] */ unsigned long oldCrc,
/* [in] */ unsigned long size,
/* [size_is][in] */ byte __RPC_FAR *buf,
/* [retval][out] */ unsigned long __RPC_FAR *crc);
bool Pack(
/* [in] */ byte compressionLevel,
/* [in] */ unsigned long sizeIn,
/* [size_is][in] */ byte __RPC_FAR *bufIn,
/* [out] */ unsigned long __RPC_FAR *sizeOut,
/* [size_is][size_is][out] */ byte __RPC_FAR *__RPC_FAR *bufOut,
/* [retval][out] */ enum EIAB_ErrorNum __RPC_FAR *errorNum);
bool Unpacking(
/* [in] */ unsigned long sizeIn,
/* [size_is][in] */ byte __RPC_FAR *bufIn,
/* [out] */ unsigned long __RPC_FAR *sizeOut,
/* [size_is][size_is][out] */ byte __RPC_FAR *__RPC_FAR *bufOut,
/* [retval][out] */ enum EIAB_ErrorNum __RPC_FAR *errorNum);
void ArcExcept(EIAB_ErrorNum errNum);
#endif //__ARCHIVERBASE_H_
Файл ArchiverBase.cpp.
#include "stdafx.h"
#include "ArchiverBase.h"
#include "zlib.h"
#include "ckg_str.h"
#include "com_mem.h"
#include "ckg_error_com.h"
#include "pdebug.h"
//-----------------------------------------------------------------------------
bool Crc32(
/* [in] */ unsigned long size,
/* [size_is][in] */ byte __RPC_FAR *buf,
/* [retval][out] */ unsigned long __RPC_FAR *crc)
{
try
catch(...)
{ }
return false;
}
//-----------------------------------------------------------------------------
//-----------------------------------------------------------------------------
bool Crc32Continue(
/* [in] */ unsigned long oldCrc,
/* [in] */ unsigned long size,
/* [size_is][in] */ byte __RPC_FAR *buf,
/* [retval][out] */ unsigned long __RPC_FAR *crc)
{
try
catch(...)
{ }
return false;
}
//-----------------------------------------------------------------------------
bool Pack(
/* [in] */ byte compressionLevel,
/* [in] */ unsigned long sizeIn,
/* [size_is][in] */ byte __RPC_FAR *bufIn,
/* [out] */ unsigned long __RPC_FAR *sizeOut,
/* [size_is][size_is][out] */ byte __RPC_FAR *__RPC_FAR *bufOut,
/* [retval][out] */ enum EIAB_ErrorNum __RPC_FAR *errorNum)
{
WriteToLog(_T("Pack()"));
try {
int level = compressionLevel;
if (level > Z_BEST_COMPRESSION)
level = Z_BEST_COMPRESSION;
else if (level == 0)
level = Z_DEFAULT_COMPRESSION;
*sizeOut = 0;
*bufOut = NULL;
if (!bufIn || !sizeIn)
throw IAB_ERROR_BUF_SIZE;
unsigned titleSize = sizeof(TitleArcData);
unsigned assumedSizePackData = sizeIn + 12 +
unsigned(float(sizeIn) * 0.001f + 0.5f);
unsigned size = titleSize + assumedSizePackData;
pure_com_mem buf((byte *)CoTaskMemAlloc(size));
if (!buf)
throw IAB_ERROR_ALLOCATE_MEMORY;
TitleArcData &title = *((TitleArcData *)buf.ptr());
title.signature = signature;
title.sizeUnpack = sizeIn;
title.crcUnpack = crc32(0L, bufIn, sizeIn);
title.titleSize = titleSize;
unsigned long retSize = assumedSizePackData;
if (compress2(buf + titleSize, &retSize, bufIn, sizeIn, level)
!= Z_OK)
throw IAB_UNKNOWN_ERROR;
title.isPacked = (retSize < sizeIn);
if (title.isPacked)
size = titleSize + retSize;
else
{
size = titleSize + sizeIn;
memcpy(buf + titleSize, bufIn, sizeIn);
}
unsigned skip = TitleArcData::GetSizeSkeep();
title.crcPack = crc32(0L, buf + skip, size - skip);
*bufOut = (byte *)CoTaskMemRealloc(buf, size);
if (*bufOut)
buf.Detach();
else
throw IAB_ERROR_ALLOCATE_MEMORY;
*sizeOut = size;
*errorNum = IAB_OK;
return true;
}
catch(EIAB_ErrorNum num)
{
*errorNum = num;
return false;
}
catch(...)
{
*errorNum = IAB_UNKNOWN_ERROR;
return false;
}
}
//-----------------------------------------------------------------------------
bool Unpacking(
/* [in] */ unsigned long sizeIn,
/* [size_is][in] */ byte __RPC_FAR *bufIn,
/* [out] */ unsigned long __RPC_FAR *sizeOut,
/* [size_is][size_is][out] */ byte __RPC_FAR *__RPC_FAR *bufOut,
/* [retval][out] */ enum EIAB_ErrorNum __RPC_FAR *errorNum)
{
WriteToLog(_T("Unpacking()"));
try {
*sizeOut = 0;
*bufOut = NULL;
if (!bufIn ||
sizeIn < sizeof(TitleArcData) + 1) // "+1" - есть хоть один
// байт данных
throw IAB_ERROR_BUF_SIZE;
TitleArcData &title = *((TitleArcData *)bufIn);
if (title.signature != signature)
throw IAB_THIS_IS_NOT_ARCHIVE;
unsigned skip = TitleArcData::GetSizeSkeep();
if (title.crcPack != crc32(0L, bufIn + skip, sizeIn - skip))
throw IAB_CRC_ERROR;
skip = title.titleSize;
unsigned size = sizeIn - skip;
pure_com_mem buf;
if (!title.isPacked)
{
buf = (byte *)CoTaskMemAlloc(size);
if (!buf)
throw IAB_ERROR_ALLOCATE_MEMORY;
memcpy(buf, bufIn + skip, size);
}
else
{
buf = (byte *)CoTaskMemAlloc(title.sizeUnpack);
unsigned long len = title.sizeUnpack;
if (uncompress(buf, &len, bufIn + skip, size) != Z_OK)
throw IAB_UNKNOWN_ERROR;
}
if (title.crcUnpack != crc32(0L, buf, title.sizeUnpack))
throw IAB_CRC_ERROR;
*errorNum = IAB_OK;
*sizeOut = title.sizeUnpack;
*bufOut = buf.Detach();
return true;
}
catch(EIAB_ErrorNum num)
{
*errorNum = num;
return false;
}
catch(...)
{
*errorNum = IAB_UNKNOWN_ERROR;
return false;
}
}
//-----------------------------------------------------------------------------
void ArcExcept(EIAB_ErrorNum errNum)
{
WriteToLog(_T("Error: run ArcExcept()"));
if (errNum == IAB_OK)
return;
DWORD id;
switch(errNum)
{
case IAB_ERROR_BUF_SIZE: id = IDS_IABE_ERROR_BUF_SIZE; break;
case IAB_ERROR_ALLOCATE_MEMORY: id = IDS_IABE_ERROR_ALLOCATE_MEMORY; break;
case IAB_CRC_ERROR: id = IDS_IABE_ERROR_CRC_ERROR; break;
case IAB_THIS_IS_NOT_ARCHIVE: id = IDS_IABE_ERROR_THIS_IS_NOT_ARCHIVE;break;
default:
id = IDS_IABE_ERROR_UNKNOWN;
}
CkgExcept(id, EXTERNAL_COM_ERROR);
}
//-----------------------------------------------------------------------------
Файл globalDef.h.
#ifndef __GLOBAL_DEF_H_
#define __GLOBAL_DEF_H_
//Версия модуля. Используется при запросе информации.
const short moduleVersionInfo = 0x0110; // 1.10
#endif //__GLOBAL_DEF_H_
Файл protect.h.
// protect.h : Declaration of the CProtect
#ifndef __PROTECT_H_
#define __PROTECT_H_
#include "resource.h" // main symbols
#include "cpp_ptr.h"
#include "ckg_array.h"
#include "ckg_buf.h"
enum E_FILE_OPEN_MODE
{
EF_READONLY, EF_READWRITE
};
class ObjectFile
{
CreateMode fileMode;
FILE *f;
cpp_ptr buffer;
E_FILE_OPEN_MODE mode;
CkgString uptFileNameForWrite;
CkgString uptFileNameForRead;
bool isOpened;
bool isClosed;
ObjectFile() : f(NULL), isOpened(false), isClosed(false) { };
void CryptBuf();
void DecryptBuf();
public:
static ObjectFile &Create(BSTR name, BSTR uptFileNameForWrite,
CreateMode mode);
static ObjectFile &Open(BSTR name, BSTR uptFileNameForWrite,
BSTR uptFileNameForRead);
void Write(const void *buf, unsigned size);
void Read(void *buf, unsigned size);
void Seek(int position, int mode);
unsigned GetPosition() const { return buffer->GetPosition(); }
void Close();
~ObjectFile();
};
/////////////////////////////////////////////////////////////////////////////
// CProtect
class ATL_NO_VTABLE CProtect :
public CComObjectRootEx,
public CComCoClass,
public ISupportErrorInfo,
public IDispatchImpl,
public IDispatchImpl,
public IDispatchImpl
// public IDispatchImpl
{
static CkgArray files;
static CkgSimpleContainerArray handles;
void ContinueOpen(ObjectFile &file, short &handle);
void ContinueGenerateTimeLimitUPTfiles(BSTR algorithmCryptFileName,
BSTR algorithmDecryptFileName,
long LimitDaysCrypt,
long LimitDaysDecrypt);
HRESULT InternalGetAlgName(const CkgString &Strings,
CkgString SearchName,
CkgString &Result);
HRESULT InternalGetDataName(const CkgString &Strings,
CkgString SearchName,
CkgString &Result);
public:
CProtect()
{
}
DECLARE_REGISTRY_RESOURCEID(IDR_PROTECT)
DECLARE_PROTECT_FINAL_CONSTRUCT()
BEGIN_COM_MAP(CProtect)
COM_INTERFACE_ENTRY(IProtect)
//DEL COM_INTERFACE_ENTRY(IDispatch)
COM_INTERFACE_ENTRY(ISupportErrorInfo)
COM_INTERFACE_ENTRY2(IDispatch, IProtect)
COM_INTERFACE_ENTRY(IProtectFile)
COM_INTERFACE_ENTRY(IProtectConformity)
// COM_INTERFACE_ENTRY(IProtectBase)
END_COM_MAP()
// ISupportsErrorInfo
STDMETHOD(InterfaceSupportsErrorInfo)(REFIID riid);
// IProtect
public:
STDMETHOD(GenerateTimeLimitUPTfiles2)(/*[in]*/ BSTR algorithmCryptFileName, /*[in]*/ BSTR algorithmDecryptFileName, /*[in]*/ long LimitDaysCrypt, /*[in]*/ long LimitDaysDecrypt);
STDMETHOD(GenerateTimeLimitUPTfiles)(/*[in]*/ BSTR algorithmCryptFileName, /*[in]*/ BSTR algorithmDecryptFileName, /*[in]*/ long LimitDays);
STDMETHOD(GenerateUPTfiles)(/*[in]*/ BSTR algorithmCryptFileName, /*[in]*/ BSTR algorithmDecryptFileName);
STDMETHOD(GetInfo)(/*[out]*/ short *version, /*[out]*/ BSTR *info);
// IProtectFile
STDMETHOD(Create)(/*[in]*/ BSTR name, /*[in]*/ CreateMode mode, /*[in]*/ BSTR uptFileName, /*[out, retval]*/ short *handle);
STDMETHOD(Open)(/*[in]*/ BSTR name, /*[in]*/ BSTR uptFileNameForRead, /*[in]*/ BSTR uptFileNameForWrite, /*[out, retval]*/ short *handle);
STDMETHOD(Write)(/*[in]*/ short handle, /*[in]*/ VARIANT buffer, /*[out, retval]*/ long *written);
STDMETHOD(Read)(/*[in]*/ short handle, /*[out]*/ VARIANT *buffer, /*[out, retval]*/ long *read);
STDMETHOD(Close)(/*[in]*/ short handle);
STDMETHOD(WriteString)(/*[in]*/ short handle, /*[in]*/ BSTR buffer, /*[out, retval]*/ long *written);
STDMETHOD(ReadString)(/*[in]*/ short handle, /*[out]*/ BSTR *buffer, /*[out, retval]*/ long *read);
STDMETHOD(ToFile)(/*[in]*/ short handle, /*[in]*/ BSTR FileName, /*[oit, retval]*/ long *written);
STDMETHOD(FromFile)(/*[in]*/ short handle, /*[in]*/ BSTR FileName, /*[oit, retval]*/ long *read);
// IProtectConformity
STDMETHOD(CreateConformityFile)(/*[in]*/ BSTR name, /*[in]*/ BSTR uptFileNameForRead, /*[in]*/ BSTR uptFileNameForWrite, /*[in]*/ BSTR ArrayOfStrings);
STDMETHOD(EasyCreateConformityFile)(/*[in]*/ BSTR name, /*[in]*/ BSTR uptFileNameForCreate, /*[in]*/ BSTR ArrayOfStrings);
STDMETHOD(ReadConformityFile)(/*[in]*/ BSTR name, /*[in]*/ BSTR uptFileNameForRead, /*[out, retval]*/ BSTR *ArrayOfStrings);
STDMETHOD(GetAlgName)(/*[in]*/ BSTR Strings, /*[in]*/ BSTR SearchName, /*[out, retval]*/ BSTR *ResultStr);
STDMETHOD(GetDataName)(/*[in]*/ BSTR Strings, /*[in]*/ BSTR SearchName, /*[out, retval]*/ BSTR *ResultStr);
STDMETHOD(GetAlgFromFile)(/*[in]*/ BSTR FileName, /*[in]*/ BSTR uptFileNameForRead, /*[in]*/ BSTR SearchName, /*[out, retval]*/ BSTR *ResultStr);
STDMETHOD(GetDataFromFile)(/*[in]*/ BSTR FileName, /*[in]*/ BSTR uptFileNameForRead, /*[in]*/ BSTR SearchName, /*[out, retval]*/ BSTR *ResultStr);
// IProtectBase
};
#endif //__PROTECT_H_
Файл protect.cpp.
// protect.cpp : Implementation of CProtect
#include "stdafx.h"
#include
#include
#include
#include "globalDef.h"
#include "c_ptr.h"
#include "cpp_ptr.h"
#include "ckg_str.h"
#include "ckg_error_com.h"
#include "com_mem.h"
#include "Uniprot.h"
#include "protect.h"
#include "polymorphism.h"
#include "ArchiverBase.h"
#include "pdebug.h"
// В Visaul Basic все равно больше нельзя
const static unsigned maxDimDimensions = 60;
static bool TestFilePresent(BSTR name, bool maybeUnnecessary = false)
{
WriteToLog(_T("TestFilePresent()"));
if (!name && maybeUnnecessary)
return true;
if (!name)
return false;
USES_CONVERSION;
CkgString strName(W2T(name));
if (strName.IsEmpty() && maybeUnnecessary)
return true;
if (strName.IsEmpty())
return false;
FILE *f = _tfopen(strName, _T("rb"));
if (!f)
return false;
if (fclose(f))
CkgExcept(ERROR_CLOSE_FILE);
return true;
}
//=============================================================================
//class ObjectFile
//-----------------------------------------------------------------------------
void ObjectFile::CryptBuf()
{
WriteToLog(_T("ObjectFile::CryptBuf()"));
byte compressionLevel;
if (fileMode == DISABLE_ARC)
compressionLevel = 1; // min compression level
else
compressionLevel = 0; // default
unsigned long sizeOut;
BYTE *bufOut;
EIAB_ErrorNum err;
if (!Pack(compressionLevel, buffer->GetSize(),
static_cast(buffer->GetBuf()), &sizeOut, &bufOut, &err))
ArcExcept(err);
_ASSERT(sizeOut && bufOut);
pure_com_mem packet(bufOut);
buffer->Clear();
buffer->Write(&sizeOut, sizeof(unsigned));
buffer->Write(bufOut, sizeOut);
unsigned needAdd = static_cast(
(ROUND_SATA_SIZE - (sizeOut % ROUND_SATA_SIZE)) % ROUND_SATA_SIZE);
_ASSERT(needAdd != ROUND_SATA_SIZE);
for (unsigned i = 0; i < needAdd; i++)
{
int rnd = CoolRand();
Write(&rnd, 1);
}
_ASSERT((buffer->GetSize() - sizeof(unsigned)) % ROUND_SATA_SIZE == 0);
CryptData(*(static_cast(buffer->GetBuf()) + sizeof(unsigned)),
buffer->GetSize() - sizeof(unsigned),
*static_cast(uptFileNameForWrite));
}
//-----------------------------------------------------------------------------
void ObjectFile::DecryptBuf()
{
WriteToLog(_T("ObjectFile::DecryptBuf()"));
if (buffer->GetSize() < sizeof(TitleArcData) + sizeof(unsigned))
CkgExcept(ERROR_FILE_FORMAT);
unsigned packSize = *(static_cast(buffer->GetBuf()));
DecryptData(*(static_cast(buffer->GetBuf()) + sizeof(unsigned)),
buffer->GetSize() - sizeof(unsigned),
*static_cast(uptFileNameForRead));
unsigned long sizeOut;
BYTE *bufOut;
EIAB_ErrorNum err;
if(!Unpacking(packSize,
static_cast(buffer->GetBuf()) + sizeof(unsigned),
&sizeOut, &bufOut, &err))
ArcExcept(err);
_ASSERT(sizeOut && bufOut);
pure_com_mem unpacket(bufOut);
buffer->Clear();
buffer->Write(bufOut, sizeOut);
}
//-----------------------------------------------------------------------------
ObjectFile &ObjectFile::Create(BSTR name, BSTR uptFileNameForWrite,
CreateMode mode)
//-----------------------------------------------------------------------------
ObjectFile &ObjectFile::Open(BSTR name, BSTR uptFileNameForWrite,
BSTR uptFileNameForRead)
CkgExcept(ERROR_READ_FILE);
//-----------------------------------------------------------------------------
void ObjectFile::Write(const void *buf, unsigned size)
{
WriteToLog(_T("ObjectFile::Write()"));
if (mode == EF_READONLY)
CkgExcept(_T("Файл открыт только для чтения."));
if (!size)
{
buffer->SetSize(buffer->GetPosition());
return;
}
buffer->Write(buf, size);
}
//-----------------------------------------------------------------------------
void ObjectFile::Read(void *buf, unsigned size)
{
_ASSERT(!isClosed);
unsigned position = buffer->GetPosition();
if (buffer->GetSize() - position < size)
CkgExcept(ERROR_INVALID_ARGUMENT);
memcpy(buf, static_cast(buffer->GetBuf()) + position, size);
buffer->LSeek(position + size);
}
//-----------------------------------------------------------------------------
void ObjectFile::Seek(int position, int mode)
{
WriteToLog(_T("ObjectFile::Seek()"));
_ASSERT(!isClosed);
if (mode == SEEK_SET)
buffer->LSeek(position);
else if (mode == SEEK_CUR)
buffer->LSeek(buffer->GetPosition() + position);
else if (mode == SEEK_END)
buffer->LSeek(buffer->GetSize() + position);
else
CkgExcept(ERROR_INVALID_ARGUMENT);
}
//-----------------------------------------------------------------------------
void ObjectFile::Close()
{
WriteToLog(_T("ObjectFile::Close()"));
_ASSERT(!isClosed && isOpened);
isClosed = true; // Даже если и не закроем (возникнет исключение), то больше
// пробовать все равно толку нет
if (mode == EF_READWRITE)
{
if (fseek(f, 0, SEEK_SET))
CkgExcept(ERROR_WRITE_FILE);
if (fwrite(&fileMode, sizeof(BYTE), sizeof(CreateMode), f) != sizeof(CreateMode))
CkgExcept(ERROR_WRITE_FILE);
CryptBuf();
unsigned dataSize = buffer->GetSize();
if (fwrite(&dataSize, sizeof(BYTE), sizeof(unsigned), f) != sizeof(unsigned))
CkgExcept(ERROR_WRITE_FILE);
if (fwrite(buffer->GetBuf(), sizeof(BYTE),
dataSize, f) != dataSize)
CkgExcept(ERROR_WRITE_FILE);
if (fwrite(0, 1, 0, f) != 0)
CkgExcept(ERROR_WRITE_FILE);
}
if (fclose(f))
CkgExcept(ERROR_CLOSE_FILE);
f = NULL;
buffer = 0;
}
//-----------------------------------------------------------------------------
ObjectFile::~ObjectFile()
{
WriteToLog(_T("ObjectFile::~ObjectFile()"));
_ASSERT(isClosed);
if (isOpened && !isClosed)
Close();
if (f)
fclose(f);
}
//-----------------------------------------------------------------------------
/////////////////////////////////////////////////////////////////////////////
// CProtect
CkgArray CProtect::files(true);
CkgSimpleContainerArray CProtect::handles;
STDMETHODIMP CProtect::InterfaceSupportsErrorInfo(REFIID riid)
{
static const IID* arr[] =
{
&IID_IProtect
};
for (int i=0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
if (InlineIsEqualGUID(*arr[i],riid))
return S_OK;
}
return S_FALSE;
}
STDMETHODIMP CProtect::GetInfo(short *version, BSTR *info)
{
try
{
*version = moduleVersionInfo;
CComBSTR str;
str.LoadString(IDS_MODULE_INFO);
*info = str.Copy();
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::GenerateUPTfiles(BSTR algorithmCryptFileName,
BSTR algorithmDecryptFileName)
{
return GenerateTimeLimitUPTfiles(algorithmCryptFileName,
algorithmDecryptFileName,
0);
}
void CProtect::ContinueGenerateTimeLimitUPTfiles(
BSTR algorithmCryptFileName, BSTR algorithmDecryptFileName,
long LimitDaysDecrypt, long LimitDaysCrypt)
STDMETHODIMP CProtect::GenerateTimeLimitUPTfiles(BSTR algorithmCryptFileName,
BSTR algorithmDecryptFileName,
long LimitDays)
{
WriteToLog(_T("CProtect::GenerateTimeLimitUPTfiles()"));
try
{
ContinueGenerateTimeLimitUPTfiles(algorithmCryptFileName,
algorithmDecryptFileName,
LimitDays, LimitDays);
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
return S_OK;
}
STDMETHODIMP CProtect::GenerateTimeLimitUPTfiles2(BSTR algorithmCryptFileName,
BSTR algorithmDecryptFileName, long LimitDaysDecrypt,
long LimitDaysCrypt)
{
WriteToLog(_T("CProtect::GenerateTimeLimitUPTfiles2()"));
try
{
ContinueGenerateTimeLimitUPTfiles(algorithmCryptFileName,
algorithmDecryptFileName,
LimitDaysCrypt, LimitDaysDecrypt);
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
return S_OK;
}
void CProtect::ContinueOpen(ObjectFile &file, short &handle)
{
files.Add(file);
short i;
for (i = 1; i < SHRT_MAX; i++)
{
if (handles.IndexOf(i) == -1)
{
handle = i;
handles.Add(i);
break;
}
}
if (i == SHRT_MAX)
CkgExcept(_T("Нет больше свободных дескипторов."));
_ASSERT(handle);
}
STDMETHODIMP CProtect::Create(BSTR name, CreateMode mode, BSTR uptFileName, short *handle)
{
WriteToLog(_T("CProtect::Create()"));
try
{
_ASSERT(handle);
ContinueOpen(ObjectFile::Create(name, uptFileName, mode),
*handle);
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::Open(BSTR name, BSTR uptFileNameForRead,
BSTR uptFileNameForWrite, short *handle)
{
WriteToLog(_T("CProtect::Open()"));
try
{
_ASSERT(handle);
ContinueOpen(ObjectFile::Open(name, uptFileNameForWrite,
uptFileNameForRead), *handle);
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::Close(short handle)
{
WriteToLog(_T("CProtect::Close()"));
try
{
int index = handles.IndexOf(handle);
if (index == -1)
CkgExcept(_T("Ошибка закрытия файла. (Неверный дескриптор.)"));
handles.Remove(index);
files[index].Close();
files.Remove(index, true);
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
template
void WriteVariable(ObjectFile &file, const T &var, VARTYPE varType)
{
file.Write(&varType, sizeof(VARTYPE));
file.Write(&var, sizeof(T));
}
STDMETHODIMP CProtect::Write(short handle, VARIANT buffer, long *written)
{
WriteToLog(_T("CProtect::Write()"));
try
{
int index = handles.IndexOf(handle);
if (index == -1)
CkgExcept(_T("Ошибка записи в файл. (Неверный дескриптор.)"));
VARTYPE vt = buffer.vt;
ObjectFile &file = files[index];
unsigned oldSize = file.GetPosition();
if (!(vt & VT_BYREF) && !(vt & VT_ARRAY))
{
if (vt == VT_UI1)
WriteVariable(file, buffer.bVal, VT_UI1);
else if (vt == VT_I2)
WriteVariable(file, buffer.iVal, VT_I2);
else if (vt == VT_I4)
WriteVariable(file, buffer.lVal, VT_I4);
else if (vt == VT_R4)
WriteVariable(file, buffer.fltVal, VT_R4);
else if (vt == VT_R8)
WriteVariable(file, buffer.dblVal, VT_R8);
else if (vt == VT_BOOL)
WriteVariable(file, buffer.boolVal, VT_BOOL);
else if (vt == VT_ERROR)
WriteVariable(file, buffer.scode, VT_ERROR);
else if (vt == VT_CY)
WriteVariable(file, buffer.cyVal, VT_CY);
else if (vt == VT_DATE)
WriteVariable(file, buffer.date, VT_DATE);
else if (vt == VT_I1)
WriteVariable(file, buffer.cVal, VT_I1);
else if (vt == VT_UI2)
WriteVariable(file, buffer.uiVal, VT_UI2);
else if (vt == VT_UI4)
WriteVariable(file, buffer.ulVal, VT_UI4);
else if (vt == VT_INT)
WriteVariable(file, buffer.intVal, VT_INT);
else if (vt == VT_UINT)
WriteVariable(file, buffer.uintVal, VT_UINT);
else if (vt == VT_BSTR)
{
file.Write(&vt, sizeof(VARTYPE));
CComBSTR str(buffer.bstrVal);
unsigned len = str.Length();
file.Write(&len, sizeof(unsigned));
file.Write(static_cast(str), len * sizeof(OLECHAR));
}
else
CkgExcept(_T("Ошибка записи в файл. (VARIANT данного типа не поддерживается)"));
}
else if (vt & VT_ARRAY)
{
if (vt & VT_BSTR)
CkgExcept(ERROR_INVALID_ARGUMENT);
SAFEARRAY &safeArray = *buffer.parray;
if (safeArray.fFeatures == FADF_RECORD ||
safeArray.fFeatures == FADF_HAVEIID ||
safeArray.fFeatures == FADF_BSTR ||
safeArray.fFeatures == FADF_UNKNOWN ||
safeArray.fFeatures == FADF_DISPATCH ||
safeArray.fFeatures == FADF_VARIANT ||
safeArray.cDims > maxDimDimensions)
CkgExcept(_T("Ошибка записи в файл. (VARIANT с массивом данного типа не поддерживается)"));
file.Write(&vt, sizeof(VARTYPE));
file.Write(&safeArray.cDims, sizeof(safeArray.cDims));
file.Write(&safeArray.cbElements, sizeof(safeArray.cbElements));
file.Write(&safeArray.fFeatures, sizeof(safeArray.fFeatures));
const SAFEARRAYBOUND *bound = safeArray.rgsabound;
unsigned size = 0;
for (unsigned i = 0; i < safeArray.cDims; i++)
{
const long &Lbound = bound[i].lLbound;
const unsigned &cElements = bound[i].cElements;
file.Write(&Lbound, sizeof(Lbound));
file.Write(&cElements, sizeof(cElements));
if (!cElements)
CkgExcept(ERROR_INVALID_ARGUMENT);
size += cElements;
}
if (size == 0)
CkgExcept(ERROR_INVALID_ARGUMENT);
size *= safeArray.cbElements;
file.Write(safeArray.pvData, size);
}
else
CkgExcept(_T("Ошибка записи в файл. (VARIANT данного типа не поддерживается)"));
_ASSERT(file.GetPosition() - oldSize);
*written = file.GetPosition() - oldSize;
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::WriteString(short handle, BSTR buffer, long *written)
{
WriteToLog(_T("CProtect::WriteString()"));
try
{
int index = handles.IndexOf(handle);
if (index == -1)
CkgExcept(_T("Ошибка записи в файл. (Неверный дескриптор.)"));
ObjectFile &file = files[index];
unsigned oldSize = file.GetPosition();
CComBSTR str(buffer);
unsigned len = str.Length();
file.Write(&len, sizeof(unsigned));
file.Write(buffer, len * sizeof(OLECHAR));
_ASSERT(file.GetPosition() - oldSize);
*written = file.GetPosition() - oldSize;
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
template
T ReadVariable(ObjectFile &file)
{
T tmp;
file.Read(&tmp, sizeof(T));
return tmp;
}
STDMETHODIMP CProtect::Read(short handle, VARIANT *buffer, long *read)
{
WriteToLog(_T("CProtect::Read()"));
try
{
int index = handles.IndexOf(handle);
if (index == -1)
CkgExcept(_T("Ошибка чтения из файла. (Неверный дескриптор.)"));
ObjectFile &file = files[index];
unsigned oldSize = file.GetPosition();
CComVariant var;
VARTYPE vt = 0;
file.Read(&vt, sizeof(vt));
if (!(vt & VT_BYREF) && !(vt & VT_ARRAY))
{
if (vt == VT_UI1)
var = ReadVariable(file);
else if (vt == VT_I2)
var = ReadVariable(file);
else if (vt == VT_I4)
var = ReadVariable(file);
else if (vt == VT_R4)
var = ReadVariable(file);
else if (vt == VT_R8)
var = ReadVariable(file);
else if (vt == VT_BOOL)
var = ReadVariable(file);
else if (vt == VT_ERROR)
var = ReadVariable(file);
else if (vt == VT_CY)
var = ReadVariable(file);
else if (vt == VT_DATE)
var = ReadVariable(file);
else if (vt == VT_I1)
var = ReadVariable(file);
else if (vt == VT_UI2)
var = ReadVariable(file);
else if (vt == VT_UI4)
var = ReadVariable(file);
else if (vt == VT_INT)
var = ReadVariable(file);
else if (vt == VT_UINT)
var = ReadVariable(file);
else if (vt == VT_BSTR)
{
unsigned len = 0;
file.Read(&len, sizeof(len));
CComBSTR str(len);
file.Read(static_cast(str), len * sizeof(OLECHAR));
var = str;
}
else
CkgExcept(_T("Ошибка чтения из файла. (Возможно файл поврежден или имеет несовместимый формат)"));
*buffer = var;
}
else if (vt & VT_ARRAY)
{
CComVariant tmp;
memset(&tmp, 0, sizeof(tmp));
VariantInit(&tmp);
tmp.vt = vt;
struct {
SAFEARRAY safeArray;
SAFEARRAYBOUND buf[maxDimDimensions];
} trueSafeArr;
SAFEARRAY &safeArray = trueSafeArr.safeArray;
memset(&safeArray, 0, sizeof(safeArray));
tmp.parray = &safeArray;
file.Read(&safeArray.cDims, sizeof(safeArray.cDims));
file.Read(&safeArray.cbElements, sizeof(safeArray.cbElements));
file.Read(&safeArray.fFeatures, sizeof(safeArray.fFeatures));
_ASSERT(safeArray.cDims && safeArray.cbElements);
unsigned size = 0;
_ASSERT(safeArray.cDims
for (unsigned i = 0; i < safeArray.cDims; i ++)
{
long &Lbound = safeArray.rgsabound[i].lLbound;
ULONG &cElements = safeArray.rgsabound[i].cElements;
file.Read(&Lbound, sizeof(Lbound));
file.Read(&cElements, sizeof(cElements));
size += cElements;
}
size *= safeArray.cbElements;
if (!size)
CkgExcept(_T("Ошибка чтения из файла. (Возможно файл поврежден или имеет несовместимый формат)"));
cpp_arr_ptr data(new BYTE[size]);
TestPtr(data);
file.Read(data, size);
safeArray.pvData = data;
HRESULT hr = var.Copy(&tmp);
if (FAILED(hr))
CkgExceptHresult(hr);
if (FAILED(var.Detach(buffer)))
CkgExcept();
}
else
CkgExcept(_T("Ошибка чтения из файла. (Возможно файл поврежден или имеет несовместимый формат)"));
_ASSERT(file.GetPosition() - oldSize);
*read = file.GetPosition() - oldSize;
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::ReadString(short handle, BSTR *buffer, long *read)
{
WriteToLog(_T("CProtect::ReadString()"));
try
{
int index = handles.IndexOf(handle);
if (index == -1)
CkgExcept(_T("Ошибка чтения из файла. (Неверный дескриптор.)"));
ObjectFile &file = files[index];
unsigned oldSize = file.GetPosition();
unsigned len = 0;
file.Read(&len, sizeof(len));
CComBSTR str(len);
file.Read(static_cast(str), len * sizeof(OLECHAR));
*buffer = str.Copy();
_ASSERT(file.GetPosition() - oldSize);
*read = file.GetPosition() - oldSize;
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::CreateConformityFile(BSTR name, BSTR uptFileNameForRead,
BSTR uptFileNameForWrite,
BSTR ArrayOfStrings)
{
WriteToLog(_T("CProtect::Create()"));
try
{
HRESULT Result;
Result = GenerateUPTfiles(uptFileNameForWrite, uptFileNameForRead);
if (FAILED(Result))
return Result;
short handle;
Result = Create(name, DEFAULT, uptFileNameForWrite, &handle);
if (FAILED(Result))
return Result;
long tmp;
Result = WriteString(handle, ArrayOfStrings, &tmp);
Close(handle);
return Result;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::EasyCreateConformityFile(BSTR name, BSTR uptFileNameForCreate,
BSTR ArrayOfStrings)
{
WriteToLog(_T("CProtect::EasyCreate()"));
try
{
HRESULT Result;
short handle;
Result = Create(name, DEFAULT, uptFileNameForCreate, &handle);
if (FAILED(Result))
return Result;
long tmp;
Result = WriteString(handle, ArrayOfStrings, &tmp);
Close(handle);
return Result;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::ReadConformityFile(BSTR name, BSTR uptFileNameForRead,
BSTR *ArrayOfStrings)
{
WriteToLog(_T("CProtect::Read()"));
try
{
HRESULT Result;
short handle;
Result = Open(name, uptFileNameForRead, NULL, &handle);
if (FAILED(Result))
return Result;
long tmp;
Result = ReadString(handle, ArrayOfStrings, &tmp);
Close(handle);
return Result;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
HRESULT CProtect::InternalGetAlgName(const CkgString &Strings,
CkgString SearchName,
CkgString &Result)
{
if (Strings.IsEmpty() || SearchName.IsEmpty())
CkgExcept(ERROR_INVALID_ARGUMENT);
if (SearchName[0u] != CkgText('"'))
{
SearchName.Insert(CkgText('"'), 0);
SearchName = SearchName + CkgText('"');
}
Result = CkgText("");
const CkgChar *p = CkgStrStr(Strings, SearchName);
if (!p)
return S_FALSE;
p += SearchName.GetLength();
const CkgChar *Start = CkgStrChr(p, CkgText('"'));
if (!Start)
return S_FALSE;
Start++;
const CkgChar *End = CkgStrChr(Start, CkgText('"'));
return S_FALSE;
CkgString tmp(Start, End - Start);
Result = tmp;
return S_OK;
}
HRESULT CProtect::InternalGetDataName(const CkgString &Strings,
CkgString SearchName,
CkgString &Result)
{
if (Strings.IsEmpty() || SearchName.IsEmpty())
CkgExcept(ERROR_INVALID_ARGUMENT);
if (SearchName[0u] != CkgText('"'))
{
SearchName.Insert(CkgText('"'), 0);
SearchName = SearchName + CkgText('"');
}
const CkgChar *p = CkgStrStr(Strings, SearchName);
if (!p)
{
Result = CkgText("");
return S_FALSE;
}
unsigned Len = p - Strings;
if (!Len)
CkgExcept(ERROR_INVALID_DATA);
p--;
const CkgChar *End = CkgStrChrBk(p, CkgText('"'), Strings);
if (!End)
CkgExcept(ERROR_INVALID_DATA);
End--;
const CkgChar *Start = CkgStrChrBk(End, CkgText('"'), Strings);
if (!Start)
CkgExcept(ERROR_INVALID_DATA);
Start++;
CkgString tmp(Start, End - Start + 1);
Result = tmp;
return S_OK;
}
STDMETHODIMP CProtect::GetAlgName(BSTR Strings, BSTR SearchName,
BSTR *ResultStr)
{
WriteToLog(_T("CProtect::GetAlgName()"));
try
{
USES_CONVERSION;
CkgString Buf(W2T(Strings));
CkgString Name(W2T(SearchName));
CkgString Result;
Buf.MakeLower();
Name.MakeLower();
HRESULT Res = InternalGetAlgName(Buf, Name, Result);
CComBSTR bstr;
bstr = T2W(Result);
*ResultStr = bstr.Copy();
return Res;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::GetDataName(BSTR Strings, BSTR SearchName, BSTR *ResultStr)
{
WriteToLog(_T("CProtect::GetDataName()"));
try
{
USES_CONVERSION;
CkgString Buf(W2T(Strings));
CkgString Name(W2T(SearchName));
CkgString Result;
Buf.MakeLower();
Name.MakeLower();
HRESULT Res = InternalGetDataName(Buf, Name, Result);
CComBSTR bstr;
bstr = T2W(Result);
*ResultStr = bstr.Copy();
return Res;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::GetAlgFromFile(BSTR FileName, BSTR uptFileNameForRead,
BSTR SearchName, BSTR *ResultStr)
{
WriteToLog(_T("CProtect::GetAlgFromFile()"));
try
{
HRESULT Result;
CComBSTR SmartPtr;
BSTR ArrayOfString;
Result = ReadConformityFile(FileName, uptFileNameForRead, &ArrayOfString);
if (FAILED(Result))
return Result;
SmartPtr.Attach(ArrayOfString);
return GetAlgName(SmartPtr, SearchName, ResultStr);
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::GetDataFromFile(BSTR FileName, BSTR uptFileNameForRead, /*[in]*/ BSTR SearchName, BSTR *ResultStr)
{
WriteToLog(_T("CProtect::GetDataFromFile()"));
try
{
HRESULT Result;
CComBSTR SmartPtr;
BSTR ArrayOfString;
Result = ReadConformityFile(FileName, uptFileNameForRead, &ArrayOfString);
if (FAILED(Result))
return Result;
SmartPtr.Attach(ArrayOfString);
return GetDataName(SmartPtr, SearchName, ResultStr);
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::FromFile(short handle, BSTR FileName, long *read)
{
WriteToLog(_T("CProtect::FromFile()"));
try
{
int index = handles.IndexOf(handle);
if (index == -1)
CkgExcept(_T("Ошибка записи в файл. (Неверный дескриптор.)"));
ObjectFile &file = files[index];
USES_CONVERSION;
CkgString Name(W2T(FileName));
DWORD Len;
FILE *f = _tfopen(Name, _T("rb"));
if (!f)
CkgExcept(ERROR_OPEN_FILE);
if (fseek(f, 0, SEEK_END))
CkgExcept(ERROR_READ_FILE);
Len = ftell(f);
if (fseek(f, 0, SEEK_SET))
CkgExcept(ERROR_READ_FILE);
pure_c_ptr Buf((char *)malloc(Len));
TestPtr(Buf);
if (fread(Buf, sizeof(char), Len, f) != Len)
CkgExcept(ERROR_READ_FILE);
fclose(f);
file.Write(&Len, sizeof(Len));
file.Write(Buf, Len);
*read = Len + sizeof(Buf);
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
STDMETHODIMP CProtect::ToFile(short handle, BSTR FileName, long *written)
{
WriteToLog(_T("CProtect::ToFile()"));
try
{
int index = handles.IndexOf(handle);
if (index == -1)
CkgExcept(_T("Ошибка записи в файл. (Неверный дескриптор.)"));
ObjectFile &file = files[index];
DWORD Len;
file.Read(&Len, sizeof(Len));
pure_c_ptr Buf((char *)malloc(Len));
TestPtr(Buf);
file.Read(Buf, Len);
USES_CONVERSION;
CkgString Name(W2T(FileName));
FILE *f = _tfopen(Name, _T("wb"));
if (!f)
CkgExcept(ERROR_CREATE_FILE);
if (fwrite(Buf, sizeof(char), Len, f) != Len)
CkgExcept(ERROR_WRITE_FILE);
fclose(f);
*written = Len + sizeof(Buf);
return S_OK;
}
CONVERT_EXCEPTION_TO_COM_EXCEPTION
}
Файл Uniprot.idl.
// Uniprot.idl : IDL source for Uniprot.dll
//
// This file will be processed by the MIDL tool to
// produce the type library (Uniprot.tlb) and marshalling code.
import "oaidl.idl";
import "ocidl.idl";
typedef
[uuid(60B14ABC-035B-43f4-B1D0-B2A29A1BC02C), v1_enum]
enum CreateMode
{
DEFAULT = 0,
DISABLE_ARC = 1
} CreateMode;
[
object,
uuid(0BF8C246-389C-42FF-845F-198C5550BCED),
dual, oleautomation,
helpstring("IProtect Interface"),
pointer_default(unique)
]
interface IProtect : IDispatch
{
[id(1), helpstring("method GetInfo")] HRESULT GetInfo([out] short *version, [out] BSTR *info);
[id(2), helpstring("method Generate UPT files")] HRESULT GenerateUPTfiles([in] BSTR algorithmCryptFileName, [in] BSTR algorithmDecryptFileName);
[id(3), helpstring("method Generate Time Limit UPT files")] HRESULT GenerateTimeLimitUPTfiles([in] BSTR algorithmCryptFileName, [in] BSTR algorithmDecryptFileName, [in] long LimitDays);
[id(4), helpstring("method Generate Time Limit UPT files")] HRESULT GenerateTimeLimitUPTfiles2([in] BSTR algorithmCryptFileName, [in] BSTR algorithmDecryptFileName, [in] long LimitDaysCrypt, [in] long LimitDaysDecrypt);
};
[
object,
uuid(1F3ADD8E-45DE-44e7-8953-CD7CC302154A),
dual, oleautomation,
helpstring("IProtectFile Interface"),
pointer_default(unique)
]
interface IProtectFile : IDispatch
{
[id(1), helpstring("method Create New File")] HRESULT Create([in] BSTR name, [in] CreateMode mode, [in] BSTR uptFileNameForWrite, [out, retval] short *handle);
[id(2), helpstring("method Open File")] HRESULT Open([in] BSTR name, [in] BSTR uptFileNameForRead, [in] BSTR uptFileNameForWrite, [out, retval] short *handle);
[id(3), helpstring("method Close File")] HRESULT Close([in] short handle);
[id(4), helpstring("method Write To File")] HRESULT Write([in] short handle, [in] VARIANT buffer, [out, retval] long *written);
[id(5), helpstring("method Read From File")] HRESULT Read([in] short handle, [out] VARIANT *buffer, [out, retval] long *read);
[id(6), helpstring("method Write String To File")] HRESULT WriteString([in] short handle, [in] BSTR buffer, [out, retval] long *written);
[id(7), helpstring("method Read String From File")] HRESULT ReadString([in] short handle, [out] BSTR *buffer, [out, retval] long *read);
[id(8), helpstring("method From File")] HRESULT FromFile([in] short handle, [in] BSTR FileName, [out, retval] long *read);
[id(9), helpstring("method To File")] HRESULT ToFile([in] short handle, [in] BSTR FileName, [out, retval] long *written);
};
[
object,
uuid(FEB052E7-05D5-4a38-A40B-D5895DE69F87),
dual, oleautomation,
helpstring("IProtectConformity Interface"),
pointer_default(unique)
]
interface IProtectConformity : IDispatch
{
[id(1), helpstring("method Create Conformity File")] HRESULT CreateConformityFile([in] BSTR name, [in] BSTR uptFileNameForRead, [in] BSTR uptFileNameForWrite, [in] BSTR ArrayOfStrings);
[id(2), helpstring("method Easy Create Conformity File")] HRESULT EasyCreateConformityFile([in] BSTR name, [in] BSTR uptFileNameForCreate, [in] BSTR ArrayOfStrings);
[id(3), helpstring("method Read Conformity File")] HRESULT ReadConformityFile([in] BSTR name, [in] BSTR uptFileNameForRead, [out, retval] BSTR *ArrayOfStrings);
[id(4), helpstring("method Get UptAlgName by FileName")] HRESULT GetAlgName([in] BSTR Strings, [in] BSTR SearchName, [out, retval] BSTR *ResultStr);
[id(5), helpstring("method Get FileName by UptAlgName")] HRESULT GetDataName([in] BSTR Strings, [in] BSTR SearchName, [out, retval] BSTR *ResultStr);
[id(6), helpstring("method Get UptAlgName by FileName From File")] HRESULT GetAlgFromFile([in] BSTR FileName, [in] BSTR uptFileNameForRead, [in] BSTR SearchName, [out, retval] BSTR *ResultStr);
[id(7), helpstring("method Get FileName by UptAlgName From File")] HRESULT GetDataFromFile([in] BSTR FileName, [in] BSTR uptFileNameForRead, [in] BSTR SearchName, [out, retval] BSTR *ResultStr);
};
/*
[
object,
uuid(15A99543-9A8F-4032-B61F-8EDF01101A93),
dual, oleautomation,
helpstring("IProtectBase Interface"),
pointer_default(unique)
]
interface IProtectBase : IDispatch
{
};
*/
[
uuid(8B9F6840-7A50-4A94-AC80-B2C85F3C469C),
version(1.0),
helpstring("Uniprot 1.0 Type Library")
]
library UNIPROTLib
{
importlib("stdole32.tlb");
importlib("stdole2.tlb");
[
uuid(75581251-6B01-4164-850D-CD6A93D860BB),
helpstring("protect Class")
]
coclass protect
{
[default] interface IProtect;
interface IProtectFile;
interface IProtectConformity;
};
};
Министерство образования Российской Федерации
Тульский государственный университет
Кафедра автоматики и телемеханики
магистерская диссертация
направление 553000
Системный анализ и управление
ЗАЩИТА ИНФОРМАЦИИ В СИСТЕМАХ ДИСТАНЦИОННОГО ОБУЧЕНИЯ С МОНОПОЛЬНЫМ ДОСТУПОМ
|
Студент группы 240681/05 |
__________________ |
А.Н. Карпов |
|
Научный руководитель |
__________________ |
д.т.н., проф. М.Ю. Богатырев |
|
Консультанты |
__________________ |
к.т.н., проф. Г.Н. Теличко |
|
Руководитель магистерской программы |
__________________ |
д.т.н., проф. А.А. Фомичев |
|
Заведующий кафедрой |
__________________ |
д.т.н., проф. А.А. Фомичев |
Тула, 2004
Министерство образования Российской Федерации
Тульский государственный университет
Кафедра автоматики и телемеханики
магистерская диссертация
направление 553000
Системный анализ и управление
Приложение
Исходные тексты библиотеки Uniprot
|
Студент группы 240681/05 |
__________________ |
А.Н. Карпов |
|
Научный руководитель |
__________________ |
д.т.н., проф. М.Ю. Богатырев |
|
Консультанты |
__________________ |
к.т.н., проф. Г.Н. Теличко |
|
Руководитель магистерской программы |
__________________ |
д.т.н., проф. А.А. Фомичев |
|
Заведующий кафедрой |
__________________ |
д.т.н., проф. А.А. Фомичев |
Тула, 2004
МИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
ТУЛЬСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Кафедра автоматики и телемеханики
УТВЕРЖДАЮ
Зав. кафедрой ___________ А.А. Фомичев
«__»_____________200 г.
Задание
на выполнение магистерской диссертации
по направлению 553000 Системный анализ и управление
магистерской программе 553005 Системный анализ данных и модели принятия решений
студенту Карпову А. Н. группы 240681
Тема диссертации "Защита информации в системах дистанционного обучения с монопольным доступом"
утверждена приказом по университету от «23» января 2004 г. № 64ст
Срок сдачи студентом законченной диссертации «___» июня 2004 г.
Перечень вопросов, подлежащих разработке и исследованию в диссертации:
1) Создание защиты для программных пакетов, на примере системы дистанционного обучения.________________________________________
2) Предлагаемые методы создания интегрируемой системы защиты информации____________________________________________________
3) Реализация системы защиты.____________________________________
4) Применение системы защиты____________________________________
4. Перечень графического материала:
1) Общий принцип работы полиморфных алгоритмов шифрования и расшифрования._________________________________________________
2) Расположение функциональных блоков полиморфного алгоритма.____
3) Алгоритм генерации полиморфных кодов
._________________________
4) АСДО построенная по принципу Клиент-сервер.___________________
5) АСДО используемая в монопольном режиме.______________________
6) Пример защиты данных при обмене между автоматизированным рабочим местом (АРМ) студента и преподавателя.____________________
Всего 6 листов
Консультации по разделам
|
Наименование раздела |
Подпись |
Фамилия |
|
Вопросы защиты информации, стоящие перед автоматизированными системами дистанционного обучения |
_________________ |
Г.Н. Теличко |
Дата выдачи задания «2» февраля 2004 г.
Научный руководитель _____________
Задание принял к исполнению
«2» февраля 2004 г. студент ____________ А.Н. Карпов