
Рефераты по рекламе
Рефераты по физике
Рефераты по философии
Рефераты по финансам
Рефераты по химии
Рефераты по хозяйственному праву
Рефераты по цифровым устройствам
Рефераты по экологическому праву
Рефераты по экономико-математическому моделированию
Рефераты по экономической географии
Рефераты по экономической теории
Рефераты по этике
Рефераты по юриспруденции
Рефераты по языковедению
Рефераты по юридическим наукам
Рефераты по истории
Рефераты по компьютерным наукам
Рефераты по медицинским наукам
Рефераты по финансовым наукам
Рефераты по управленческим наукам
Психология и педагогика
Промышленность производство
Биология и химия
Языкознание филология
Издательское дело и полиграфия
Рефераты по краеведению и этнографии
Рефераты по религии и мифологии
Рефераты по медицине
Рефераты по сексологии
Рефераты по информатике программированию
Краткое содержание произведений
Реферат: Интерпретация блок-схем
Реферат: Интерпретация блок-схем
Томский государственный университет
Факультет прикладной математики и кибернетики
Кафедра программирования
ДОПУСТИТЬ К ЗАЩИТЕ В ГАК
зав. кафедрой программирования профессор, д.т.н.
_______________ А.Ю.Матросова
“____ ” ________________ 1999 г.
Соловьёв Александр Станиславович
Система визуального программирования
“Блок-схема” на основе языка блок-схем
(дипломная работа)
Научный руководитель доцент, к.т.н.
_________ Н.А.Белоусова
Автор работы
_________ А.С. Соловьев
Томск 1999
Реферат
Дипломная работа представляет собой систему программирования, которая облегчает обучение программированию и началам алгоритмизации. Основная идея, положенная в основу работы, - это создание системы трансляции с языка блок - схем.
Созданная система “Блок-схема” обладает удобным интерфейсом, графическим редактором блок-схем, встроенным текстовым редактором, интерпретатором и конвертором на язык программирования Си. В системе предусмотрена возможность получения информации (справок) как о самой системе, так и о языке блок - схем. Система снабжена демонстрационными примерами.
Система создана в двух вариантах:
Под операционную систему MS-DOS 3.x и выше;
Под операционные системы Windiows 95, Windows 98 и Windows NT.
В первом случае, разработка велась с помощью языка Borland C++ 3.1 (совместима с языком Turbo C 2.0). Во втором, с помощью пакета Borland C++Builder 3.0.
Оглавление
Введение 5
1. Языки программирования 7
1.1. Классификация 7
1.2. Сравнительная характеристика языков. 9
2. Трансляторы 10
2.1. Классификация 10
2.2. Компиляторы и интерпретаторы 10
3. Язык блок-схем 12
3.1. Правила построения блок-схем 12
3.2. Блоки 13
3.3. Связки 15
3.4. Язык наполнения блок – схем 15
4. Система программирования 19
4.1. Графический редактор 19
4.2. Встроенный текстовый редактор 22
4.3. Интерпретатор 23
4.3.1. Этапы трансляции 23
Трансляция 24
Оптимизация 24
Программа на внутреннем языке 24
Анализ 24
Трансляция 24
Оптимизация 24
4.3.2. Лексический анализ 25
4.3.2.1. Задачи лексического анализа 25
4.3.2.2. Сканер 26
4.3.3. Синтаксический и семантический анализ 28
4.3.4. Польская инверсная запись (ПолИЗ) 28
4.3.4.1. Алгоритм Дейкстры формирования ПолИЗа 29
4.3.4.2. ПолИЗ выражений, содержащих переменные синтаксиса 30
4.3.4.3. Алгоритм перевода ПолИЗа в машинные команды 32
4.3.5. Общая схема работы интерпретатора 35
4.4. Оболочка системы 36
4.4.1. Работа с файлами 36
4.4.2. Знакомство с системой 37
4.4.2.1. MS-Dos версия системы 37
4.4.2.2. Windows версия системы 41
4.5. Внутреннее представление данных 47
Заключение 49
Литература 50
Приложение 51
Приложение 1: Примеры блок-схем 51
Приложение 2: Матрицы переходов анализаторов 53
Приложение 3: Текст основных классов программы 59
Введение
Основная проблема, которая встает перед обучаемыми на занятиях по информатике, это неосязаемость изучаемого предмета. Живя в материальном мире человеку довольно трудно и не очень интересно разбираться с неосязаемыми операторами.
Наиболее естественной формой представления (восприятия) информации является графический образ – рисунок, чертеж, схема и т.д. К этой форме человек прибегает всякий раз (возможно неявно для себя), когда необходимо решать (описывать, формулировать) действительно сложные задачи. Эффективное оперирование наглядными образами, быстрое установление смысловой связи между ними – является сильной стороной человеческого мышления.
Еще во времена становления программирования, когда программы писались на внутреннем языке ЭВМ – машинном коде (ассемблере), неотъемлемой частью разработки программ было использование блок-схем. Как мы все хорошо знаем: “ Схемой алгоритма называется такое графическое представление алгоритма, в котором этапы процесса обработки информации и носители информации представлены в виде геометрических символов из заданного ограниченного набора, а последовательность процесса отражена направлением линий ” [1]. Их применение значительно облегчало восприятие и анализ программы. Двумерное представление программы более ясно отражало ее структуру. Применение блок-схем позволяло быстрее и качественнее разрабатывать и отлаживать программы, а также облегчалось их сопровождение. Данное свойство блок-схем было “узаконено” и они стали обязательной частью документации.
Сохранение двух различных форм представления программ – самого текста и блок-схемы всегда чревато ошибками, поскольку трудно постоянно поддерживать их соответствие. Более того, многие программисты никогда не любили вычерчивать блок-схемы и создавали их после того, как программа была закончена, и лишь потому, что блок-схемы требовались в качестве документации. Таким образом, польза, которую могли бы принести блок-схемы, отсутствовала и именно тогда, когда она была наиболее нужна – при разработке программы.
Естественным развитием данной ситуации является объединение двух подходов в описании программ: в виде текста и блок-схемы. Результатом такого объединения является понятие визуального программирования. Под ним понимается способ описания алгоритма решения задачи в графическом виде, соединяющий достоинства текста и блок-схем программ. Что в сочетании с современными графическими возможностями ЭВМ и их способностью взять на себя рутинные операции и максимально упростить весь процесс программирования, делает это направление очень перспективным.
Вследствие всего выше сказанного, представляет интерес реализация системы визуального программирования, в рамках которой, будет представлена возможность определения алгоритма в графическом виде, подобно блок-схеме, но с элементами потокового программирования и использованием в полной мере графических и интерактивных возможностей компьютера, что в конечном итоге не только облегчает понимание написанного, но и сильно облегчает процесс создания программ.
Обучаемый намного быстрее и легче разберется в каком либо языке, если ему дать возможность самому составить блок-схему алгоритма, посмотреть как он (алгоритм) будет выполняться, проследить изменения значений переменных, а затем посмотреть, как выглядит исходный текст непосредственно на изучаемом языке.
В 70ых годах были довольно успешные попытки создания систем, с помощью которых ЭВМ понимала язык блок-схем (например, ОДА). Но все-таки это были языки блок-схем не в чистом виде. В них присутствовали описатели, с помощью которых ЭВМ строила из алгоритма блок-схему.
В идеальном случае программист должен создавать блок-схему, непосредственно работая с планшетом, на котором изображается блок-схема.
Если ориентировать разрабатываемую систему на начинающего программиста, который учится не только программированию, сколько началам алгоритмизации, то система должна быть интерпретирующего типа с удобным интерфейсом. Это значит, что процесс интерпретации должен отображаться на экране в форме, позволяющей пользователю следить за этим процессом, прерывать его, наблюдать, как изменяются значения переменных.
1. Языки программирования
1.1. Классификация
В системном программировании языком называется определенный набор символов и правил (соглашений), устанавливающих способы комбинаций этих символов для записи осмысленных сообщений (текстов).
Различают, вообще говоря, нестрого, естественные языки, на которых говорят и пишут люди в повседневной жизни, и искусственные языки, создаваемые для некоторых частных целей.
Искусственные языки, предназначенные для записи программ, называются языками программирования. Каждая ЭВМ имеет свой собственный язык программирования – язык команд или машинный язык и может исполнять программы, написанные только на этом языке. В машинном языке каждой команде соответствует определенная операция, которую может выполнять машина. Однако на машинном языке программировать трудно из-за чрезмерной детализации программы. Поэтому уже на ЭВМ первого и второго поколения для повышения производительности труда программистов начали применять языки программирования, не совпадающие с машинными языками. На ЭВМ третьего поколения машинный язык практически не применяется для программирования задач, за ним сохранилась лишь роль внутреннего языка ЭВМ.
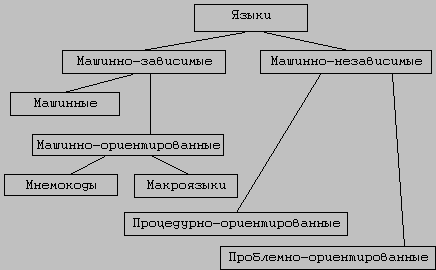
В настоящее время насчитывается несколько сотен различных языков программирования, которые классифицируются по разным признакам. Наиболее общей является классификация по степени зависимости языка от ЭВМ. По этому признаку языки делятся на две большие группы:
Машинно-зависимые языки,
Машинно-независимые языки.
Машинно-зависимые языки, в свою очередь, делят на машинные и машинно-ориентированные.
Машинно-ориентированные языки иногда называют автокодами. Различают два уровня машинно-ориентированных языков. К первому уровню относятся языки символьного кодирования, иначе называемые мнемокодами, а ко второму – макроязыки.
Мнемокод отличается от машинного языка соответствующей ЭВМ заменой цифровых кодов операций буквенными (мнемоническими), а цифровых адресов операндов – буквенными или буквенно-цифровыми. При переводе на язык ЭВМ каждая команда мнемокода заменяется соответствующей командой машинного языка (>).
Применение мнемокода позволяет автоматизировать работу программиста по распределению памяти, точнее, по присваиванию истинных адресов. Это особенно полезно при программировании для машин с переменным форматом команд. Кроме того, мнемокод существенно облегчает работу по составлению больших программ, когда отдельные сегменты (модули) программы составляются разными программистами и объединяются в единую программу на этапе загрузки.
Язык второго уровня – макроязык – наряду с символическими аналогами машинных команд, из которых состоит мнемокод, допускает также использование макрокоманд, не имеющих прямых аналогов в машинном языке. При трансляции каждая макрокоманда заменяется группой команд машинного языка (>). Применение макрокоманд сокращает программу, повышает производительность программиста. Программист, использующий машинно-ориентированный язык должен быть хорошо знакомым с особенностями устройства машины, для которой составляется программа.
Машинно-независимые языки также делятся на две группы по степени детализации программы. К первой группе относятся процедурно-ориентированнные языки, а ко второй проблемно-ориентированные.
Процедурно-ориентированные языки предназначены для описания алгоритмов (процедур) решения задач, поэтому их также называют алгоритмическими, хотя понятие алгоритмического языка не совпадает с понятием языка программирования. Если запись на алгоритмическом языке непосредственна, пригодна для ввода в ЭВМ и преобразования в готовую рабочую программу, то такой язык является одновременно языком программирования. Некоторые алгоритмические языки, строго говоря, не являются языками программирования, если не добавить к ним специальных средств. В частности, алгоритмический язык Алгол-60 становится языком программирования после включения в него операторов ввода и вывода и конкретизации способов выполнения некоторых других операций управления оборудованием ЭВМ.
Программа на процедурно-ориентированном языке почти не зависит от конкретной ЭВМ, на которой будет решаться задача. Слово “почти” следует понимать в том смысле, что в большинстве случаев программы решения одной и той же задачи для разных ЭВМ отличаются лишь некоторыми непринципиальными деталями внешнего оформления, которые при переходе от ЭВМ к ЭВМ заменяются механически.
Структура процедурно-ориентированных языков ближе к естественному языку, например русскому или английскому, чем к языку ЭВМ. Поэтому перевод с процедурно-ориентированного языка на машинный язык осуществляется по принципу «несколько в несколько». Иными словами, в большинстве случаев здесь можно установить соответствие лишь между группой элементарных конструкций языка и группой команд ЭВМ, подобно тому, как при переводе с английского языка на русский язык группы слов или даже группы предложений заменяют группой слов на другом языке. Пословный перевод здесь не возможен.
К проблемно-ориентированным языкам относят так называемые непроцедурные языки, то есть такие языки, которые не требуют подробной записи алгоритма решения задачи. Пользователь должен лишь указать формулировку задачи либо назвать последовательность задач из ранее подготовленного набора, указать исходные данные и требуемую форму выдачи результатов. Эта информация используется специальной программой – генератором для генерирования рабочей программы.
По отношению к транслятору все упоминавшиеся выше языки, кроме машинных языков, являются входными. В процессе трансляции программа на входном языке переводится на некоторый внутренний язык, более удобный для дальнейшей работы транслятора, а затем последовательно происходит несколько стадий обработки. На каждой стадии транслируемая программа представляется в некотором промежуточном языке. И, наконец, после обработки транслятором получается программа на выходном языке.
1.2. Сравнительная характеристика языков.
Машинно-ориентированные языки универсальны в той же степени, в которой универсален язык машины, поскольку в них содержаться средства программирования и решения на ЭВМ любых задач, с которыми ЭВМ может справиться по своим техническим возможностям. При программировании на этих языках можно учесть особенности системы команд и устройства ЭВМ, что позволяет создавать высококачественные программы. Однако машинно-ориентированные языки довольно трудны для изучения, а программировать на них трудно.
Машинно-независимые языки эффективны лишь для определенного класса задач. Вне этого класса задач применение большинства языков высокого уровня малоэффективно и вообще непригодно. Эти языки сравнительно легко изучать. Программирование на них значительно проще, чем на машинно-ориентированных языках.
Следует отметить, что в среде языков программирования наблюдается процесс сближения языков по своим возможностям. Например, Фортран дополнился операциями над строковыми и символическими данными, всякое новшество в Си повторяется в Паскале и т.п.
2. Трансляторы
2.1. Классификация
Любую программу, которая переводит произвольный текст на некотором входном языке в текст на другом языке, называют транслятором. В частности, исходным текстом может быть входная программа. Транслятор переводит её в выходную или объектную программу.
В смысле этого определения простейшим транслятором можно считать, загрузчик, который переводит программу в условных адресах, оформленную в виде модуля загрузки, в объектную программу в абсолютных адресах. В этом случае входной язык (язык загрузчика) и объектный язык (язык ЭВМ) являются языками одного уровня. Однако чаще входной и объектный языки относятся к разным уровням. Обычно уровень входного языка выше уровня объектного языка.
По уровню входного языка трансляторы принято делить на ассемблеры, макроассемблеры, компиляторы, генераторы.
Входным языком ассемблера является мнемокод, макроассемблера - макроязык, компилятора - процедурно-ориентированный язык, а генератора - проблемно – ориентированный язык. В связи с этим входной язык называют по типу транслятора: язык ассемблера, язык макроассемблера и т.д.
Программа, полученная после обработки транслятором, либо непосредственно исполняется на ЭВМ, либо подвергается обработке другим транслятором.
2.2. Компиляторы и интерпретаторы
Обычно процессы трансляции и исполнения программы разделены во времени. Сначала вся программа транслируется, а потом исполняется. Трансляторы, работающие в таком режиме, называют трансляторами компилирующего типа. Если входным языком такого транслятора является процедурно-ориентированный язык высокого уровня, то транслятор называют компилятором.
Существуют трансляторы, в которых трансляция и исполнение совмещены во времени, их называют интерпретаторами. В состав интерпретатора входит блок анализа, распознающий операторы входного языка, набор подпрограмм, соответствующих различным операторам, и блок, управляющий всей работой интерпретатора.
По указаниям управляющего блока, блок анализа просматривает операторы входной программы, распознает их тип и определяет возможность немедленного выполнения. Информация о возможности выполнения оператора передается управляющему блоку, который вызывает соответствующую подпрограмму, исполняющие действия, предписанные оператором.
Интерпретаторы часто применяются в качестве отладочных и диалоговых трансляторов, обеспечивающих работу пользователя с машиной в диалоговом режиме с дистанционного терминала. Кроме того, интерпретаторы используют для исполнения (интерпретации) на ЭВМ программ, составленных для другой ЭВМ, а иногда в качестве последнего блока транслятора компилирующего типа. В последнем случае транслятор состоит из двух частей: первой – компилятора, переводящего программу на промежуточный язык, являющимся входным языком интерпретатора; второй – интерпретатора, исполняющего программу на промежуточном языке.
В такой схеме компилятор можно сделать очень простым. Интерпретатор несколько проще компилятора, поскольку немедленное выполнение распознанных операторов входного языка делает ненужным действия, связанные с компоновкой объектной программы, оформлением её в единый модуль загрузки или в виде нескольких модулей, если она велика.
Недостаток интерпретатора заключается в неэффективном использовании машинного времени. Например, при выполнении циклических программ, один и тот же оператор приходится интерпретировать многократно. При повторном выполнении программы, интерпретацию приходится выполнять заново, в то время как транслятор компилирующего типа позволяет выполнить трансляцию один раз, а затем хранить программу в машинных кодах. По указанной причине интерпретаторы применяются относительно редко.
3. Язык блок-схем
В настоящее время огромное распространение получила тенденция к визуализации процесса программирования. Таким образом, создание транслятора с языка блок-схем является логическим продолжением развития технологии программирования. Кроме того, язык блок-схем незаменим в начальной стадии обучения программированию.
Такой язык является неформальным описанием алгоритма, он обладает повышенной наглядностью и обозримостью. Язык блок-схем используется при разработке системного математического и информационного обеспечения, а также при описании процессов функционирования отдельных блоков или устройств.
“Схемой алгоритма называется такое графическое представление алгоритма, в котором этапы процесса обработки информации и носители информации представлены в виде геометрических символов из заданного ограниченного набора, а последовательность процесса отражена направлением линий ” [1].
Приведенная в данной работе система трансляции с языка блок-схем включает следующие подзадачи:
Во-первых, несмотря на достаточно большое количество графических и текстовых редакторов (например: Page Maker, Corel Draw, Word и т.д.) нужны:
1. Свой графический редактор, так как настройка на внутренние форматы файлов этих систем приводит к неэффективному использованию ресурсов ЭВМ, Поэтому необходим эффективный, графический редактор, ориентированный только на объекты типа блоков.
Текстовый редактор, работающий в графическом режиме для редактирования текста внутри блоков.
Во-вторых, кроме редакторов (графического и текстового) необходимо создать интерпретатор, так как на его основе можно легко создать систему отладки алгоритмов.
Как уже говорилось выше у любого транслятора существует свой входной язык. В данной системе входной язык транслятора состоит из двух языков:
Язык блок-схем (“Графический” язык),
Язык функционального наполнения блок-схем.
Ниже приводится пример блок-схемы, реализующей выбор наибольшего числа из двух чисел. На рисунке 1 приводится пример блок схемы поиска максимального из двух значений.
3.1. Правила построения блок-схем
Блок-схема алгоритма описывает какой-то процесс или, точнее будет сказано, последовательность действий. Отсюда следует, что она должна иметь начало и конец. Особо следует отметить, что начало (блок начала программы) может быть только один, а выходов (блок конца программы) несколько.
У каждого символа, из которого строится блок-схема (далее будем называть блоки), своя функциональная нагрузка. В соответствии с ней блоки должны заполняться текстом.
Блоки в блок-схеме алгоритма соединяются стрелками в соответствии с последовательностью действий, которые реализуют этот алгоритм.
Необходимо придерживаться последовательности блоков в таких связках, как мультиветвление и безусловный переход. Об этих особенностях мы поговорим в параграфе 3.3.
![]()
![]()
![]()
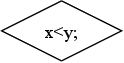
![]()


![]()
![]()


![]()
![]()
![]()
Рис.1. Пример блок - схемы алгоритма нахождения максимального из двух значений.
3.2. Блоки
Блок это минимальная единица интерпретации в языке блок-схем. Как было сказано выше, из блоков строится блок-схема алгоритма. Все они отличаются не только графическим изображением, но и действиями, выполняемыми во время выполнения каждого блока.
В таблице 1 приведен перечень блоков для построения блок-схем алгоритмов.
таблица 1.
|
Графический символ действия |
Идентификатор | Наименование действия |
|
|
BEGIN |
блок начала программы |
|
|
END |
блок конца программы |
|
|
AD |
блок автоматических действий |
|
|
PP |
Блок вызова подпрограммы |
|
|
IF |
блок условного перехода |
|
|
INPUT |
блок ввода данных |
|
|
OUTPUT |
блок вывода данных |
|
|
CASE |
блок ветвь |
|
|
SWITCH |
блок мультиветвления |
|
|
LABEL |
метка |
|
|
GOTO |
Безусловный переход на метку |

Рассмотрим функциональное назначение каждого блока.
“НАЧАЛО” С этого блока начинается исполнение блок-схемы. Присутствие этого блока обязательно. Необходимо заметить, что блок “НАЧАЛО” в блок схеме должен быть один.
“КОНЕЦ” После того, как обрабатывается этот блок, исполнение блок-схемы завершается. Присутствие данного блока также обязательно, но в отличие от предыдущего, блоков “КОНЕЦ” может быть несколько.
“АВТОМАТИЧЕСКИЕ ДЕЙСТВИЯ” Присутствие данного блока, как и всех последующих блоков, в схеме не обязательно. В блоке действий могут выполняться:
любые математические действия, согласно правилам математики;
стандартные функции, предоставленные системой “Блок-схема”;
инициализация переменных.
“ПОДПРОГРАММА” В этом блоке происходит вызов подпрограммы, которую составил сам пользователь.
“ВЕТВЛЕНИЕ ПО УСЛОВИЮ” В этом блоке проверяется заданное условие на истинность. И в зависимости от результата осуществляется ветвление.
“ВВОД / ВЫВОД” При помощи этих блоков организуется интерфейс пользователя с исполняемой схемой, то есть вводится и выводится информация.
“МЕТКА” Помечает позицию блока, на который происходит переход во время выполнения связки “БП”. В этом блоке указывается соответствующая метка. Данный блок является частью связки - “БП”.
“БЕЗУСЛОВНЫЙ ПЕРЕХОД НА МЕТКУ” В этом блоке указывается метка, на которую будет происходить переход. Этот блок является частью связки - “БП”.
Использование этих двух блоков не обязательно. Эти блоки введены с целью повышения наглядности блок-схем, так как в результате ввода этих блоков, отпадает необходимость указывать сложные соединения блоков (исчезает загромождённость схемы стрелками).
“МУЛЬТИВЕТВЛЕНИЕ” В этом блоке находится переменная, по которой будет происходить мультиветвление. Блок “мультиветвление” является частью связки с аналогичным названием (описание связок смотрите далее).
“ВЕТВЬ” Блок “ветвь” является частью связки “мультиветвление”. В блоке “ветвь” задается константа, с которой выполняется сравнение значения, полученного в блоке “мультиветвление.”
3.3. Связки
Связка - это такая последовательность блоков в блок- схеме, которой необходимо придерживаться при создании блок-схемы алгоритма.
Язык блок-схем располагает всего двумя связками:
“БП” - безусловный переход;
“Мультиветвление” – мультиветвление.
“БП” - представляет собой связку из двух блоков: “БЕЗУСЛОВНЫЙ ПЕРЕХОД НА МЕТКУ” и “МЕТКА”. Входящие в связку блоки должны содержать одну и ту же метку.
“МУЛЬТИВЕТВЛЕНИЕ” представляет собой связку из последовательности блоков, которая начинается с блока “мультиветвление”. Далее идет последовательность блоков “ветвь”. Заканчивается данная связка тогда, когда встречается блок отличный от блока “ветвь”.
3.4. Язык наполнения блок – схем
В данном параграфе мы рассмотрим, как следует заполнять текстом блоки в предложенной версии языка блок-схем. В основу этого языка положены два языка:
С (его упрощенный вариант);
Pascal (его упрощенный вариант).
“НАЧАЛО” С этим блоком связывается описание переменных. Переменные описываются следующим образом:
тип переменная 1, переменная 2, ... , переменная N;
тип переменная N+1, ...;
Множество типов в языке блок схем ограничено:
int - целое ;
long_int - длинное целое ;
float - вещественное ;
char - символьное .
Имя переменной - стандартный идентификатор имени в языке C, Pascal. Длина имени не ограничена.
“КОНЕЦ” Содержимое этого блока не просматривается.
“АВТОМАТИЧЕСКИЕ ДЕЙСТВИЯ” Здесь задаются выражения, строящиеся из переменных, констант, математических знаков, математических и стандартных функций:
+ сложение,
- вычитание,
* умножение,
/ деление,
= присвоение,
sin синус,
cos косинус,
tg тангенс,
ctg котангенс,
arcsin арксинус,
arccos арккосинус,
arсtg арктангенс,
arcctg арккотангенс,
ln натуральный логарифм,
lg десятичный логарифм,
abs абсолютное значение числа (модуль),
exp функция экспоненты,
mod взятие целой части при делении,
div взятие дробной части при делении,
^ возведение в степень,
sqrt нахождение квадратного корня,
sh гиперболический синус,
ch гиперболический косинус,
th гиперболический тангенс,
а также, стандартные функции, предоставляемые системой "Блок-схема":
randomize() инициализация датчика случайных чисел,
random() получение случайного числа,
clock() получение времени,
getch() получение кода нажатой клавиши,
kbhit() получение значения была ли нажата клавиша,
strlen() получение длины строки,
и т.д.
Список функций будет пополняться (полный список смотрите в приложении). Приоритет операций соответствует приоритетам языков Pascal и С (приоритеты операций смотрите в приложении). Предусмотрена возможность изменять приоритеты с помощью круглых скобок. Каждое выражение должно заканчиваться символом “;”
Н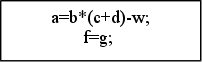 апример:
апример:
“ВЕТВЛЕНИЕ ПО УСЛОВИЮ” Текст этого блока должен представлять собой логическое условие, после которого ставится “;”. Условие может содержать логические связки И - &&, ИЛИ - ||, НЕ - !.
Например:
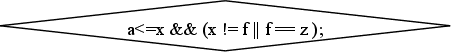
“ВВОД” В этом блоке через запятую указываются переменные значения которые вводит сам программист с терминала. После перечисления всех переменных ставится “;”
Н![]() апример:
апример:
“ВЫВОД” Текст этого блока имеет следующую структуру:
“текст”, переменная 1, “текст”, переменная 2, ... , переменная N;
“текст”, переменная N+1, ...;
то есть, текстовые константы чередуются через запятую с переменными, которые надо вывести на экран монитора. В конце ставится “;”.
Н апример:
апример:
“БЕЗУСЛОВНЫЙ ПЕРЕХОД НА МЕТКУ” Содержимым этого блока является имя метки с “;” на конце.
Например:

“МЕТКА” Определяется аналогично предыдущему блоку.

“ПОДПРОГРАММА” Содержится имя подпрограммы с параметрами.
Например:
![]()
“МУЛЬТИВЕТВЛЕНИЕ” Вариант оператора “switch” языка Си. В данном блоке содержится имя переменной, по которой будет выполняться ветвление.
Н апример:
апример:
“ВЕТВЬ” Блок “ветвь” может присутствовать только в связке “мультиветвление”. Отдельно не имеет смысла. В блоке “ветвь” задается константа, с которой выполняется сравнение значения, полученного в блоке “мультиветвление”.
![]()
Применение блоков продемонстрировано в примерах, приведённых в приложении.
4. Система программирования
4.1. Графический редактор
Г.Р. - это программа, позволяющая программисту “рисовать” новые и редактировать старые блок-схемы. Пользователю предлагается в режиме меню следующие возможности для редактирования блок-схем:
Удаление блоков
Установка блоков
Разметка планшета координатной сеткой
Скроллинг планшета
Выбор типа блоков (либо стрелки, либо сами блоки);
Автоматическое соединение двух выделенных блоков на планшете;
Изменение параметров планшета;
Изменение палитры планшета (цветов);
Возможности редактирования с помощью буфера обмена.
Все эти возможности можно выбирать либо посредством манипулятора мышь, либо с помощью клавиатуры.
Рассмотрим понятие ПЛАНШЕТ. Назовём поверхность, на которой выполняется рисование блок-схемы ПЛАНШЕТОМ. Будем считать, что размеры планшета не ограничены. В каждый текущий момент пользователь находится в позиции планшета с координатами (X,Y). Координаты (X,Y) задаются в Декартовой системе координат, начало координат (0,0) - это середина планшета (именно в этой точке находится пользователь при начальном запуске системы “Блок-схема”).
Планшет может быть размечен координатной сеткой (рис.2.).

рис.2.
Шаг на планшете выбран так, чтобы в клетку планшета вписывался один элемент блок-схемы.
В связи с тем, что всё пространство, на котором выполняется редактирование блок-схемы, невозможно отобразить на экране, то на экране в окне редактора выводится прямоугольная область, параллельная осям координат, размером N_X на N_Y, где N_X - количество шагов по оси X, а N_Y - количество шагов по оси Y.
Окном редактора называется та часть экрана, которая отводится для изображения этой прямоугольной области. Связь между областью планшета и окном редактора представляет схема 1.


![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()


![]()
![]() Y
X0
X1 640
Y
X0
X1 640
Y0
J
![]()
![]()
![]()
![]()
![]()
![]() N_Y
N_Y
![]()
Y1
J+N_Y N_X
X
I I+N_X 480
схема 1.
Рассмотрим процедуру размещения элементов блок-схемы в окне редактора. Так как разрабатываемая система опирается на графический драйвер, поддерживающий разрешение 640 на 480 pixel, а координатные оси на экране расположены так, как показано на схеме 1, то окно редактора - это прямоугольная область экрана с координатами верхнего левого угла (X0,Y0) и с координатами нижнего правого угла (X1,Y1).
Тогда, для того, чтобы отобразить некоторую часть планшета в окне редактора, необходимо выполнить преобразование координат планшета в экранные координаты. Они осуществляются следующим образом:
height =(Y1-Y0)/N_Y; это высота блока в экранных координатах
width =(X1-X0)/N_X; это ширина блока в экранных координатах
Далее установим соответствие между координатами блоков в координатной системе планшета и координатами блоков в экранной системе.
Будем считать, что существует другая система координат, в которой I~I’ и J~J’, и, зная, что координате (I,J) соответствует координата (X0,Y0), то, следовательно, I~I’=0 и J~J’=0. Аналогично для координат (I+N_X,J+N_Y), зная, что ей соответствует, координата (X1-width,Y1-height) будем иметь, что (I+N_X)~(I’+N_X)=N_X и (J+N_Y)~(J’+N_Y)=N_Y.
Таким образом для блока с координатами ( i , j), где ( i , j) принадлежит прямоугольнику [I,J,I+N_X,J+N_Y] будет иметь место следующее преобразование координат:
X = X0+(i-I)*width;
Y = Y0+(j-J)*height;
где X,Y экранные координаты блока (i , j). Когда выполнены эти преобразования, осуществляется вывод этой прямоугольной области в окно редактора. Вывод осуществляется последовательно, перебирая все элементы области.
Процедура отображения окна на планшете в окно вывода на дисплее присутствует практически во всех функциях графического редактора. Благодаря ей осуществляется связь пользователя со схемой, и отображаются все изменения, производимые пользователем над схемой.
Теперь рассмотрим другие функции графического редактора.
В системе “Блок-схема”, как и в любой другой интерактивной системе, заданы кодовые комбинации клавиш, благодаря которым можно не выполнять полный набор команды для выполнения какого-либо действия. Для этого достаточно нажать так называемые “горячие” клавиши. Информацию о них можно получить, выбрав соответствующий пункт в меню “СПРАВКА”.
По полю окна редактора движется специальный графический указатель, показывающий очередную позицию на планшете. Движение этого указателя организуется с помощью клавиш управления курсором или с помощью манипулятора мышь. Если указатель передвигается за пределы окна редактора, то осуществляется скроллинг окна по планшету. Организованна эта процедура следующим образом:
Так как окно редактора меньше планшета, то его (окно редактора) нужно перемещать по планшету - это называется скроллинг планшета. При выполнении этой функции изменяется всего лишь координата (I, J) верхнего левого угла области, которая отображается в окне редактора, а потом новая область заново выводится в окно редактора.
Выполняется эта процедура с помощью клавиш в MS-Dos:
- вверх
- вниз
- вправо
- влево
а также посредством манипулятора мышь при выборе соответствующих кнопок меню.
Выбор блока, который необходимо установить в данную позицию выполняется через пункт “БЛОКИ” или “СТРЕЛКИ” в подменю “РЕДАКТОР” главного меню. Выбранный блок прорисовывается, когда нажата клавиша или одновременно нажаты левая и правая клавиши манипулятора мышь, а также когда выбран пункт “УСТАНОВИТЬ” в подменю “РЕДАКТОР” главного меню.
Выбор типа блоков (либо стрелки, либо блоки) можно осуществлять посредством “горячих” клавиш:
- стрелки;
- блоки.
или выбирая соответствующие команды в главном меню.
Удаление блоков выполняется следующим образом: c помощью указателя выбирается блок, который нужно удалить, а потом нажимается клавиша , либо выбирается пункт “УДАЛИТЬ” в подменю “РЕДАКТОР” главного меню.
В Windows варианте эти возможности можно выбирать посредством манипулятора мышь или аналогичным образом с помощью клавиатуры. Кроме того, Windows вариант предусматривает соединение двух заданных блоков с помощью волнового алгоритма Ли[10].
4.2. Встроенный текстовый редактор
Текстовый редактор необходим системе для того, чтобы наполнять текстом блоки, создаваемые пользователем блок-схемы алгоритма.
Редактор для среды Windows по своим возможностям не уступает большинству современных текстовых редакторов, предоставляемых фирмой Borland. Редактор обладает следующими возможностями:
нет ограничения на размер текста внутри блока;
допускаются работа с буфером обмена;
существует возможность изменения шрифта текста;
два режима набора текста программы (режимы вставки и перезаписи);
поиск текста по заданному образцу;
замена заданного образца текста на заданный текст.
Редактор, предложенный в среде MS-Dos, является простейшим вариантом текстового редактора, в котором возможен лишь набор текста в режиме наложения текста на текст (режим перезаписи), также существует ограничение на размер текста. Он не должен превышать 1104 символа для каждого блока блок-схемы.
С помощью клавиш управления осуществляется перемещение курсора по окну редактора текста блока. А с помощью клавиш и осуществлять удаление текста со сдвигом строки.
4.3. Интерпретатор
Что такое интерпретатор? Как уже говорилось выше – это такой транслятор, в котором процессы трансляции и исполнения алгоритма совмещены во времени. В состав интерпретатора входит блок анализа, распознающий операторы входного языка, набор подпрограмм, соответствующих различным операторам и блок, управляющий порядком просмотра операторов и всей работы интерпретатора.
4.3.1. Этапы трансляции
Основой любого естественного или искусственного языка является алфавит, определяющий набор допустимых элементарных знаков (букв, цифр и служебных знаков). Знаки могут объединяться в слова – элементарные конструкции языка, рассматриваемые в данном тексте (программе) как неделимые символы, имеющие определенный смысл. Иногда символ обозначают одним знаком, который можно тоже считать словом. Например, в языке С++ словами (символами) являются основные символы, идентификаторы, числа и некоторые ограничители, в частности знаки операций и скобки. Словарный состав языка – набор допустимых слов (символов) – вместе с описанием способов их представления составляет лексику языка.
Слова могут объединяться в более сложные конструкции – предложения. В языке С++, например, простейшим предложением является оператор. Предложения строятся из слов (символов) и более простых предложений по правилам синтаксиса. Синтаксис языка представляет собой описание правильных предложений. Каждому правильному предложению языка приписывается некоторый смысл. Описание смысла предложений составляет семантику языка. Практически семантика языка программирования есть описание того, как каждое предложение следует выполнять на Э.В.М.
Алфавит, лексика и синтаксис полностью определяют набор допустимых конструкций языка и внутренние взаимоотношения между конструкциями. Семантика выражает связь между конструкциями в разных языках. Перевод программы с одного языка на другой в общем случае состоит в изменении алфавита, лексики и синтаксиса языка программы с сохранением семантики. В частных случаях могут меняться только некоторые элементы. Например, загрузчик изменяет лишь лексику, ассемблер – алфавит и лексику, а компилятор – алфавит, лексику и синтаксис языка программы.
Трансляция обычно происходит в несколько этапов, на каждом из которых выполняется вполне определенная работа.
Входная программа может быть подготовлена на разных внешних устройствах и для удобочитаемости может иметь неполные строки и другие индивидуальные особенности. Кроме того, слова входного языка обычно имеют неодинаковый формат, например идентификаторы, состоят из разного числа букв, числа – из разного числа цифр. Поэтому на первом этапе трансляции осуществляется лексический анализ, состоящий в приведении входной программы к стандартному виду – редактировании программы – и переводе ее на внутренний язык. Обычно на внутреннем языке все слова имеют одинаковый формат, что облегчает дальнейшую обработку. Одновременно с переводом на внутренний язык выполняется лексический контроль, выявляющий недопустимые слова.
Входная программа
![]()
![]()
![]()
Анализ
![]()
Трансляция
П![]() еревод
на внутренний
язык
еревод
на внутренний
язык
Оптимизация
![]()
Программа на внутреннем языке
![]()
![]()
![]()
Анализ
![]()
П
Трансляция
еревод на язык машины
![]()
Оптимизация
![]()
Программа на объектном (машинном) языке
На втором этапе трансляции выполняется синтаксический анализ, в задачу которого входит распознавание типа предложений и выявление структуры программы, а также синтаксический контроль, выявляющий синтаксические ошибки.
На третьем этапе производиться семантический анализ, в ходе которого проводится исследование каждого предложения и генерирование семантически эквивалентных предложений объектного языка. Иными словами, на третьем этапе выполняется собственно перевод.
Иногда вводят еще один этап, на котором производится оптимизация программы с целью сокращения времени ее выполнения и минимизации используемой программой памяти.
В трансляторах каждому из описанных этапов соответствует определенная часть транслятора. Иногда отдельные блоки выполняют одновременно несколько этапов, например семантический анализ, оптимизацию и генерирование предложений входного языка. Также существуют трансляторы, в которых описанная общая схема повторяется несколько раз, например, при переводе с выходного языка на внутренний, с внутреннего на промежуточный, выходной или объектный.
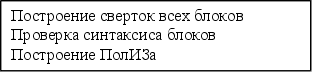
Транслятор, предложенный в данной работе, имеет следующую структуру:
![]()
![]()


![]()
![]()

![]()

![]()

Оптимизация не выполняется.
4.3.2. Лексический анализ
4.3.2.1. Задачи лексического анализа
Цель лексического анализа состоит в переводе исходной программы на стандартный, входной язык компилятора и преобразовании ее к виду, удобному для дальнейшей обработки на этапах синтаксического и семантического анализа.
В процессе лексического анализа обычно собираются из отдельных знаков (букв и цифр) простые синтаксические конструкции: идентификаторы, числа, а также служебные слова типа begin, end и другие. При дальнейшей обработке такие простые конструкции рассматриваются как неделимые, поэтому оставлять их распознавание и сборку до этапа синтаксического анализа невыгодно, прежде всего, с точки зрения общего времени и сложности алгоритмов трансляции.
В общем случае в процессе лексического анализа необходимо выполнить следующее:
перекодировать исходную программу, рассматриваемую как входная строка, и привести ее к стандартному входному языку;
выделить и собрать из отдельных знаков в слова идентификаторы и служебные слова (основные символы языка);
выделить и собрать из цифр, а также перевести в машинную форму числовые константы.
В некоторых компиляторах лексический анализ составляет отдельный этап и выполняется специальными блоками за один – два просмотра входной программы. В других компиляторах отдельные задачи лексического анализа решаются на разных этапах трансляции. Однако перекодирование входной программы и приведение ее к стандартному входному языку всегда выполняет первый блок компилятора.
В ходе лексического анализа помимо чисто лексического контроля (выявление недопустимых символов и служебных слов, а также ошибок записи идентификаторов и констант) иногда выполняют частичный синтаксический контроль. В частности, при лексическом анализе легко проверяется парность некоторых основных символов.
Другой вид контроля, иногда применяемый при лексическом анализе, - проверка сочетаемости стоящих рядом символов. Например, пары символов begin x и else begin – сочетаемы (допустимы), но те же символы, стоящие в обратном порядке: x begin и begin else – несочетаемы. В то же время пары +end, +/, *[ - несочетаемы ни в каком порядке. Основной (главной) частью лексического анализатора является сканер.
4.3.2.2. Сканер
Сканер – это часть компилятора, которая читает входную программу и формирует лексемы: константы, знаки операций и т.д. Он также выполняет лексический контроль. Синтаксис лексем прост, его можно задать автоматными грамматиками, так как его можно легко запрограммировать. Следовательно, сканер выделяют отдельным блоком.
Синтаксис каждой лексемы можно задать с помощью диаграммы состояний. Следовательно, алгоритм работы сканера можно задать с помощью правила анализа по диаграмме состояний. Заметим, что процедура анализа представляет собой восходящий анализ, основой на каждом шаге является текущий символ и текущее состояние. Поэтому диаграмма состояний представляет собой граф, подграфы которого это есть диаграммы состояний отдельных лексем.
Сканер программируется так, что на каждом шаге он выделяет одну лексему.
Пусть входная строка: s1, s2, s3,…, sn.
![]()
![]()
![]() s,i СКАНЕР
L,t
s,i СКАНЕР
L,t
где L – лексема, t – ее тип.
![]()
0, константа типа int
1, константа типа long_int
t= 2, константа типа float
3, константа типа char
4, идентификатор
-1, ошибка, не распознаваемый тип лексемы
Сканер в процессе своей работы распознает тип символа, то есть использует подпрограмму:
![]()
s![]()
![]() i класс
символа k
i класс
символа k
г![]() де
де
1, если si буква
2, если si цифра
3, если si `
k= 4, если si “ или ”
5, если si верный знак
0, если si ошибочный символ
Тогда диаграмма состояний имеет вид: (смотри в приложении).
![]()
![]()

![]()
![]()
![]()
![]()
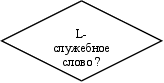


![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()

![]()
![]()
![]()
![]()
![]()

![]()
Рис.3. Блок схема лексического анализа.
ЗАМЕЧАНИЕ:
В каждом состоянии сканер может выполнять дополнительные действия по контролю правильности лексемы и преобразования во внутреннюю форму.
Сканер выделяет самую длинную лексему пока возможно, а при выходе указатель стоит на начале следующей лексемы.
Изобразим блок - схему работы лексического анализатора (рис.3.).
Так как сканер строится по диаграмме состояний, то для простоты программирования был построен конечный автомат. Матрица переходов состояний сканера приведена в приложении.
4.3.3. Синтаксический и семантический анализ
Анализаторы выполняют действительно сложную работу по расчленению исходной программы на составные части, формированию ее внутреннего представления и занесению информации в таблицу символов и другие таблицы. При этом также выполняется полный синтаксический и частичный семантический контроль программы.
Обычный анализатор представляет собой синтаксически управляемую программу. В действительности стремятся отделить синтаксис от семантики настолько, насколько это возможно. Когда синтаксический анализатор (распознаватель) узнает конструкцию исходного языка, он вызывает соответствующую семантическую процедуру, или семантическую программу, которая контролирует данную конструкцию с точки зрения семантики и затем запоминает информацию о ней в таблице символов или во внутреннем представлении программы. Например, когда распознается описание переменных, семантическая программа проверяет идентификаторы, указанные в этом описании, чтобы убедиться в том, что они не были описаны дважды, и заносит их вместе с атрибутами в таблицу символов.
Когда встречается инструкция присваивания вида:
=
семантическая программа проверяет переменную и выражение на соответствие типов и затем заносит инструкцию присваивания в программу во внутреннее представление.
Синтаксический анализ можно представить диаграммой состояний, так же как и сканер. Поэтому их частично объединяют и если возможно то совмещают полностью. В данной работе процесс лексического, синтаксического и семантического анализа для всех блоков разделен. Матрицы состояний конечных автоматов синтаксического анализа блоков приведены в приложении. Семантический анализ выполняется в процессе интерпретации.
4.3.4. Польская инверсная запись (ПолИЗ)
Первые процедурно-ориентированные языки программирования высокого уровня предназначались для решения инженерных и научно – технических задач, в которых широко применяются методы вычислительной математики. Значительную часть программ решения таких задач составляют арифметические и логические выражения. Поэтому трансляцией выражений занимались очень многие исследователи и разработчики трансляторов. На данное время разработано большое число таких трансляторов. Сейчас классическим стал метод трансляции выражений, основанный на использовании промежуточной обратной польской записи, названной так в честь польского математика Яна Лукашевича, который впервые использовал эту форму представления выражений в математической логике.
Цель польской инверсной записи – представить операции исходного выражения в порядке их выполнения (вычисления). В данной работе был использован алгоритм построения ПолИЗа, который был предложен Дейкстрой.
Пример ПолИЗа:
Исходное выражение : x=a+f*c;
Выражение на ПолИЗе :xafc*+=.
Очевидно, что обрабатывать такую последовательность операций значительно легче, так как они расположены в порядке их выполнения. Рассмотрим алгоритм Дейкстры для формирования ПолИЗа.
4.3.4.1. Алгоритм Дейкстры формирования ПолИЗа
ПРИОРИТЕТ ОПЕРАЦИИ – это целое число, означающее старшинство операции по отношению к другим операциям. Приоритет операций изменяется с использованием скобок ( и ).
Исходная последовательность просматривается слева на право, как входная последовательность элементов.
АЛГОРИТМ:
Если элемент операнд, то он заносится в ПолИЗ.
Если элемент операция, то она заносится в ПолИЗ через СТЕК по правилу.
2.1. Если СТЕК пуст, то знак операции заносится в СТЕК,
2.2. Иначе: если приоритет входного знака равен 0, то он заносится в СТЕК, иначе сравниваются приоритеты входного знака и знака в вершине СТЕКа.
2.3.Если приоритет входного знака больше приоритета знака в вершине СТЕКа, то он заносится в СТЕК.
2.4. Иначе из СТЕКа выталкиваются все знаки с приоритетом больше или равным приоритету входного знака в вершине СТЕКа и приписываются к ПолИЗу, затем входной знак заносится в СТЕК.
Особо обрабатываются ( и ).
( - имея приоритет 0 сразу же заносится в СТЕК по 2.2.
) – имея приоритет равный 1 выталкивает из СТЕКа все знаки до ближайшей открывающей скобки (, затем они взаимно уничтожаются.
При появлении признака конца выражения ( в нашем случае ;) СТЕК очищается : все оставшиеся знаки выталкиваются и приписываются к ПолИЗу.
Так же ПолИЗу соответствует так называемое дерево ПолИЗа.
Пример: (x+a)*(x-b)+3;
Дерево:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
x a x b
ПолИЗ: x a + x b - * 3 +.
Построение ПолИЗа по дереву осуществляется обходом дерева по правилу левое поддерево, правое поддерево, корень.
4.3.4.2. ПолИЗ выражений, содержащих переменные синтаксиса
Кроме операций сложения и умножения любая программа содержит операции вычисляющие адреса элементов массива в зависимости от индексных выражений. Например:
a[i+1]-b[i,j-1]*a[2*i+1]
![]()
![]()
![]()
Индексные выражения.
Выведем формулы вычисления адресов элементов массива.
Для одномерного массива а, описание которого на Паскале и Си имеет вид:
a: array [1..n] of integer; // Pascal
int a[n]; // C/C++
и каждый элемент имеет массива занимает k-байт.
Адрес первого элемента равен A . Выясним чему будут равны адреса других элементов. Для этого рассмотрим расположение элементов массива в физической памяти ЭВМ.
A![]()
![]()
![]()
![]()
![]()
![]() +k
+2k
+3k
A+k*(i-1)…
+k
+2k
+3k
A+k*(i-1)…
k байт
![]()
т![]()
![]() огда
a[i] А+k*(i-1)
для языка
программирования
Паскаль, а для
языка программирования
C/C++ a[i] A+k*i.
Тогда если
элемент занимает
k – байт, то
огда
a[i] А+k*(i-1)
для языка
программирования
Паскаль, а для
языка программирования
C/C++ a[i] A+k*i.
Тогда если
элемент занимает
k – байт, то
a[i] -----> A+k*(i-1) (1)
a[i] -----> A+k*i (1’)
Для двумерного массива:
b: array [1..m,1..n] of integer;// Pascal
int b[m][n];//Си
Адрес элемента с индексами i,j вычисляется по правилу:
b[i,j] -----> B+k*((i-1)*n+(j-1)) (2)
b[i,j] -----> B+k*(i*n+j) (2’)
Для формирования ПолИЗа введем операцию АЭМ (адрес элемента массива) с операндами:
Идентификатор массива, ему после распределения памяти транслятором будет соответствовать адрес первого элемента массива.
Индексное выражение.
Результат: адрес элемента массива вычисленный по формулам (1)-(2’).
ПолИЗ: a i 1 + А.Э.М. b i j 1 – А.Э.М. a 2 i * 1 + А.Э.М. * -
Анализ ПолИЗа говорит о том, что у операции АЭМ переменное число операндов и их количество надо задавать явно. Сделаем следующую замену: АЭМ – k], где k - количество операндов.
Тогда ПолИЗ: a i j + 2] b i j 1 – 3] a 2 i * 1 + 2] * -.
Изобразим дерево выражения: (смотри рисунок )
-![]()
![]()
![]()
![]()
![]()
А.Э.М. *
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() а + А.Э.М. А.Э.М.
а + А.Э.М. А.Э.М.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
i 1 b i – a +
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
i j * 1
![]()
![]()
![]()
![]()
2 i
Следовательно, алгоритм Дейкстры дополнится следующими правилами:
ПРАВИЛА:
[, имея приоритет 0 заносится в СТЕК [k, где k – минимальное число операндов операции А.Э.М.
, , имея приоритет 1 выталкивает из СТЕКа все ближайшие знаки до ближайшей [k и увеличивает k на 1: k=k+1; , никуда не заносится.
], имея приоритет 1 выталкивает из СТЕКа все знаки до ближайшей [k, которая удаляется из СТЕКа, а в ПолИЗ заносится k].
4.3.4.3. Алгоритм перевода ПолИЗа в машинные команды
Известно, что в обратной польской записи операнды располагаются в том же порядке, что и в исходном выражении, а знаки операций при просмотре записи слева направо встречаются в том порядке, в котором нужно выполнять соответствующие действия. Отсюда вытекает основное преимущество обратной польской записи перед обычной записью выражений со скобками: выражение можно вычислить в процессе однократного просмотра слева направо.
Правило вычисления выражения в обратной польской записи состоит в следующем. Обратная польская запись просматривается слева направо. Если рассматриваемый элемент – операнд, то рассматривается следующий элемент. Если рассматриваемый элемент – знак операции, то выполняется эта операция над операндами, записанными левее знака операции. Результат операции записывается вместо первого (самого левого) операнда, участвовавшего в операции. Остальные элементы (операнды и знак операции), участвовавшие в операции, вычеркиваются из записи. Просмотр продолжается.
В результате последовательного выполнения этого правила будут выполнены все операции, имеющиеся в выражении, и запись сократится до одного элемента – результата вычисления выражения.
Рассмотрим пример: a+b*c-d/(a+b)
ПолИЗ: abc*+dab+/-
Выполнение правила для нашего примера приводит к последовательности строк, записанных во второй графе таблицы № 2 (смотрите следующую страницу). Рассматриваемый на каждом шаге процесса элемент строки отмечен курсивом. В третьей графе таблицы записаны соответствующие действия, а в четвертой графе – эквивалентные команды трехадресной машины.
Результат выполнения операции фиксируется в виде рабочей переменной вида rj . После очередной операции рабочая переменная r1 или r2 вычеркивается, освободившуюся рабочую переменную можно использовать вновь для записи результата операции. Использование каждый раз свободной рабочей переменной с минимальным номером экономит количество занятых рабочих переменных. Такой пример экономии рабочих ячеек приведен в таблице № 2. Это же правило используют в трансляторах.
Аналогичным способом можно записывать и вычислять булевские выражения.
Последовательность машинных команд в таблице № 2 есть, по существу, результат трансляции выражения, записанного в обратной польской записи, в машинные команды. Если для каждого операнда, включая рабочие переменные rj, известен адрес, для получения окончательных машинных команд остается
Таблица № 2
| № | Состояние строки | Действие | Машинная команда |
| 1 | 2 | 3 | 4 |
| 1 |
a bc*+dab+/- |
Просмотреть следующий элемент | - |
| 2 |
a b c*+dab+/- |
Просмотреть следующий элемент | - |
| 3 |
ab c *+dab+/- |
Просмотреть следующий элемент | - |
| 4 |
abc * +dab+/- |
r1=b*c |
* b c r1 |
| 5 |
ar1 + dab+/- |
r1=a+ r1 |
+ a r1 r1 |
| 6 |
r1 d ab+/- |
Просмотреть следующий элемент | - |
| 7 |
r1d a b+/- |
Просмотреть следующий элемент | - |
| 8 |
r1da b +/- |
Просмотреть следующий элемент | - |
| 9 |
r1dab + /- |
r2=a+b |
+ a b r2 |
| 10 |
r1dr2 / - |
r2= d/r2 |
/ d r2 r2 |
| 11 |
r1 r2 - |
r1 =r1 –r2 |
- r1 r2 r1 |
| 12 |
rl |
- | - |
лишь заменить знаки операций машинными кодами операций, а операнды – адресами. Пример показывает, что в данном случае трансляция выполняется достаточно просто. Однако правило вычисления значения выражения по ПолИЗу, которое можно считать одновременно правилом трансляции выражения в машинные команды, недостаточно детализировано и формализовано для непосредственной реализацией на машине, хотя бы потому, что в нем не определен способ записи выражения в памяти машины и порядок использования рабочих ячеек. Для машинной реализации требуется более формальное правило.
В рассмотренном примере встречались двухместные операции. Каждая такая операция, как правило, заменяется одной или двумя машинными командами (в зависимости от адресации машины). В общем случае операция R может иметь k операндов (k1). На ЭВМ такая операция должна заменяться группой машинных команд. Будем считать, что к моменту генерирования машинных команд проведено распределение памяти, и каждый операнд представлен соответствующей ссылкой на таблицу имен, содержащую адрес операнда. Аналогично, для каждой рабочей переменной известен ее адрес.
Для трансляции выражений из обратной польской записи в машинные команды используется стек операндов (СО) с указателем i. В исходном состоянии стек операндов пуст, а указатель i=1. Будем также считать, что в исходном состоянии номер первой свободной рабочей переменной j=1.
Алгоритм трансляции состоит в следующем.
1. Взять очередной символ S из обратной польской записи выражения.
2. Если S – операнд, то занести S в СО[i] , выполнить i=i+1 и перейти к пункту 1, иначе к пункту 3.
3. Если S – не знак операции, то перейти к пункту 4, иначе, если S – знак операции R, выполнить следующее
Среди элементов стека СО[i-k], где k – число операндов операции R, найти рабочую переменную с минимальным номером l. Если в рассматриваемых элементах стека нет рабочих переменных, то положить l=j.
Записать машинные команды, реализующие оператор присваивания rl=R(СО[i-k],…,СО[i-1]). Здесь R(x1, … , xk) – результат выполнения операции R над операндами x1, … , xk.
Занести символ rl в СО[i-k].
Выполнить: i=i-k+1 и j=l+1. Перейти к пункту 1.
Если запись выражения исчерпана, то трансляция закончена. Стек операндов должен содержать только переменную rl, в противном случае нужно записать информацию об ошибке в таблицу ошибок.
Вход

![]()

![]()
![]()
![]()
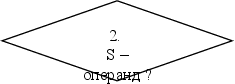
![]()
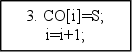
![]()



![]()
![]()
![]()
![]()
![]()
![]()

![]()
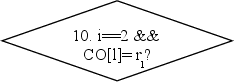
![]()
![]()
![]()
Рис.4. Блок-схема перевода обратной польской записи в машинные команды.
Для реализации пункта 3.2. приведенного алгоритма используются заранее подготовленные заготовки групп машинных команд, в которые требуется лишь подставить адреса операндов, взятые из стека операндов. Эту подстановку выполняет подпрограмма, соответствующая рассматриваемой операции R.
Надо, однако, отметить, что используемая подпрограмма определяется, не только знаком операции R, но и типом операндов. Например, одна подпрограмма соответствует операции сложения вещественных чисел, а другая – операции сложения целых. Иногда в пункте 3.2. приходится выполнять несколько подпрограмм. В частности, если один операнд целый, а другой вещественный, то в начале нужно привести операнды к одному типу, а затем выполнить подпрограмму формирования команды сложения. При несовместимости операндов или при несоответствии операндов знаку операции выдается информация об ошибке.
Блок-схема алгоритма перевода обратной польской записи в машинные команды приведена рисунке 4.
Заметим, что приведенный выше алгоритм пригоден для перевода в машинные команда не только арифметических и логических выражений, но и любых текстов, записанных в обратной польской записи с использованием произвольных операций, реализуемых машинными командами.
4.3.5. Общая схема работы интерпретатора
Рассмотрим, что же представляет собой программа, написанная на языке блок - схем с точки зрения интерпретатора. Это список структур следующего вида:
struct Blocks
{
int type; // тип блока
int x; // координаты блока на планшете по оси X
int y; // координаты блока на планшете по оси Y
int true_x; // координаты блока на планшете для перехода
int true_y; // по ИСТИНЕ (TRUE)
int false_x; // координаты блока на планшете для перехода
int false_y; // по ЛЖИ (FALSE)
char* text; // указатель на текст блока
struct Blocks far *next; // указатель на следующий блок в списке блоков
};
Минимальной единицей интерпретации в языке блок-схем является блок. Работой всего интерпретатора управляет функция, которая перемещает фокус интерпретации по блок-схеме, распознает тип блока, на который указывает фокус и запускает функцию обработки (интерпретации) соответствующего блока. После того как функция обработки блока отработает, она передает управление функции управляющей работой интерпретатора. Каждый тип блока имеет свою функцию обработки. Рассмотрим каждый блок по порядку.
НАЧАЛО – блок «НАЧАЛО» отвечает за описание переменных. Строка символов, принадлежащая этому блоку, переводится в список указателей (см. параграф «Структуры данных»). Затем происходит формирование таблицы переменных одновременно с лексической и семантической проверкой. Если функция блок отработала без ошибок, то процесс интерпретации продолжается, иначе нет.
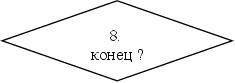
КОНЕЦ – Функция блока ничего не делает. После того, как она передаст управление функции управления интерпретацией, интерпретатор заканчивает свою работу.
АВТОМАТИЧЕСКИЕ ДЕЙСТВИЯ – Строка символов переводится в массив указателей. Затем этот массив переводится в обратную польскую запись (ПолИЗ) и выполняется. Предварительно производится лексический и синтаксический анализ. Если ошибок нет, то управление передается функции управления интерпретацией.
ПОДПРОГРАММА – Предварительно производится лексический и синтаксический анализ. Потом текст переводится в список дескрипторов ПолИЗа, и если ошибок нет, то управление передается функции управления интерпретацией.
ВЕТВЛЕНИЕ ПО УСЛОВИЮ – Сначала производится синтаксический и лексический анализ. Затем строка символов переводится в массив указателей, потом этот массив переводится в ПолИЗ и выполняется. После выполнения ПолИЗа осуществляется семантический анализ. Если ошибок не было, то в зависимости от результата анализа функции управления будет передана информация, как выполнять ветвление.
ВВОД\ВЫВОД – В этих блоках происходит семантический и лексический анализ. По результатам анализов происходит либо выдача сообщений в окно, либо вывод (ввод) значений переменных. Особенность возникает при обработке массивов, так как в этом случае необходимо вычислять адрес элемента массива. Для этого, выражение стоящие внутри квадратных скобок ( [ , ] ) переводится в обратную польскую запись и после обработки ПолИЗа, происходит либо ввод, либо вывод определенного элемента массива. По окончании работы функции обработки блоков, они передают управление функции управления интерпретацией.
МЕТКА – Обработка этого блока происходит в функции блока БЕЗУСЛОВНЫЙ ПЕРЕХОД НА МЕТКУ.
БЕЗУСЛОВНЫЙ ПЕРЕХОД НА МЕТКУ – Функция обработки этого блока ищет в списке структур блоков блок, содержащий такую же метку, которую содержит и он сам (блок). По окончанию работы функция обработки блока передает функции управления интерпретацией, на какой блок нужно осуществить переход для продолжения интерпретации программы.
МУЛЬТИВЕТВЛЕНИЕ При выполнение этого блока формируется константа с которой будет выполняться сравнение при встрече с блоком “ветвь.”
ВЕТВЬ Обработка данного блока происходит следующим образом: если константа, содержащаяся в этом блоке, совпадает с константой, которая была сформирована в блоке мультиветвление, то происходит переход по истине (true), иначе по лжи (false).
4.4. Оболочка системы
4.4.1. Работа с файлами
В нашей системе, как и в любой другой, работа с файлами просто необходима. Это, в первую очередь, связанно с тем, что пользователь, создав блок-схему, захочет ее сохранить, с той целью, чтобы использовать ее в дальнейшем.
В системе “Блок схема” для работы с файлами создана унифицированная и очень дружелюбная система диалогов с пользователем. Она позволяет легко сохранять схемы на внешнем запоминающем устройстве (дискета или винчестер) или считывать уже созданные. За основу диалогов системы взяты диалоги, разработанные фирмой Borland, и несколько модифицированы в варианте под операционную систему MS-Dos, а под Windows приняты стандартные диалоги в среде MS Windows 95. Схема, созданная в системе “Блок схема”, хранится на диске и имеет свое уникальное имя. Файл имеет расширение sch – MS-Dos и scw - Windows.
Файл схемы представляет собой последовательность следующих записей:
struct FILE_SCHEME
{
int type; // тип блока
int x; // координаты блока на планшете по оси X
int y; // координаты блока на планшете по оси Y
int true_x; // координаты блока на планшете для перехода
int true_y; // по ИСТИНЕ (TRUE)
int false_x; // координаты блока на планшете для перехода
int false_y; // по ЛЖИ (FALSE)
};
и строка, содержащая текст данного блока.
Эти записи строятся следующим образом. В поле type содержится тип, сохраняемого блока. В полях x,y – координаты блока на планшете. В полях true_x, true_y – координаты блока на планшете для перехода по истине. И соответственно, в полях false_x, false_y - координаты блока на планшете для перехода по условию ложь. В последнем поле содержится текст соответствующий данному блоку или текстовая константа NULL, если текста нет.
Последовательность записей создается сканированием списка структур блоков и переводом во внутреннее представление блок – схемы. Запись заканчивается, когда список структур будет полностью просканирован.
Кроме этого в Windows версии системы в файл блок схемы добавляются ключевые слова для того, чтобы при считывании блок-схем не было допущено ошибок и при обнаружении их можно было сообщить об этом пользователю.
4.4.2. Знакомство с системой
4.4.2.1. MS-Dos версия системы
Итак, Вы решили поработать с системой, предлагаемой в данной работе. Вы должны находиться в операционной системе MS-DOS 3.0 или Windows 3.1 и выше. Выбрав в диспетчере файлов имя программы MAIN_CURS.EXE, запустите ее. На мониторе компьютера появится главное окно программы, в котором будут указаны автор работы и его научный руководитель. После этого нужно нажать клавишу , либо подвести указатель манипулятора мышь на кнопку и нажать левую кнопку манипулятора.
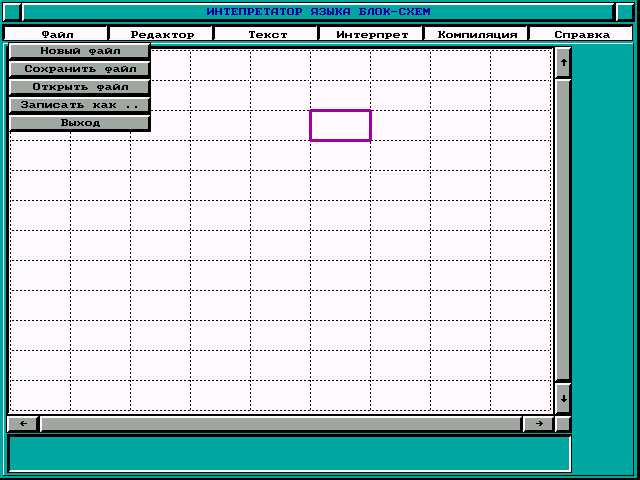
Пункты главного меню имеют следующее назначение:
Файл для того, чтобы создать блок-схему алгоритма, считать её с диска, записать на диск или выйти из системы.
Редактор подменю этого пункта предназначено для создания и редактирования блок-схем. Оно предоставляет набор блоков и стрелок для построения блок-схем, а также предоставляет возможности удалять блоки и производить разметку экрана координатной сеткой.
Текст этот пункт предназначен для набора и редактирования текста внутри блока.
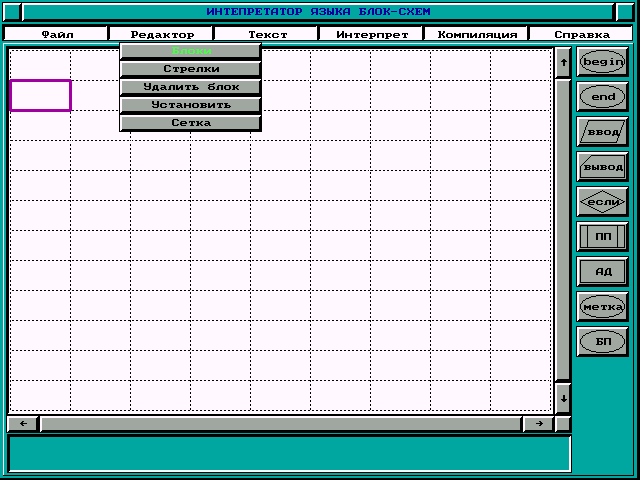
Интерпретация пункты этого меню позволяют запускать пошаговый отладчик, организуют просмотр таблицы переменных, а также запускают интерпретатор.
Справка здесь можно будет получать информацию о системе или о языке блок –схем.
Если Вы выберете пункт “новый файл”, то получите окно графического редактора блок-схем, который будет разбит координатной сеткой, а на поле редактора будет находиться графический указатель, указывающий текущее положение блока.
После выбора пунктов “Блоки” или “Стрелки” справа от поля графического редактора появляются либо стрелки, которыми соединяются блоки, либо непосредственно сами блоки. Перед Вами появилось окно графического редактора (в нем создается и редактируется блок-схема) с набором блоков, предназначенных для рисования блок схемы алгоритма.
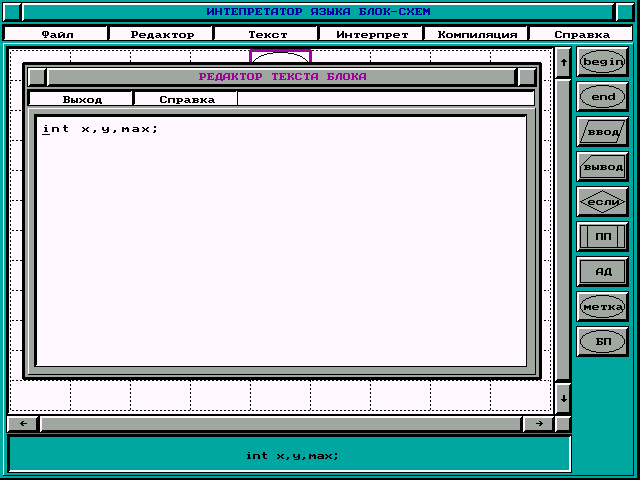
Если Вы нажмете комбинацию , то перед Вами появится окно текстового редактора. В нем Вы можете производить набор и редактирование текста, который принадлежит данному блоку. Для выхода из него надо нажать клавишу при этом текст данного блока будет автоматически сохранен.
Если Вы решили запустить программу на выполнение, то Вам нужно выбрать пункт “Интерпретация” в главном меню, а в нем пункт “выполнить”. После этого, перед Вами появится окно, которое сообщит Вам, были ли допущены Вами ошибки при создании программы. Если их не было, то перед Вами появится следующее окно, которое называется окном интерпретации.
После выполнения проверки и обнаружения ошибок выдается сообщение о наличии ошибок:
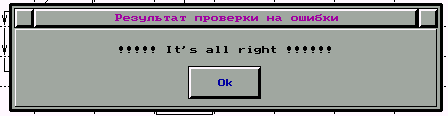
По окончании интерпретации Вам будет выдано сообщение об том, как прошел процесс интерпретации (успешно или нет). Сообщение выглядит следующим образом:
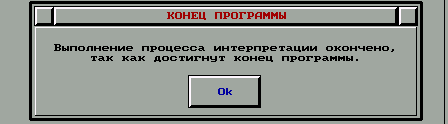
Для того чтобы посмотреть значения переменных надо в этом же подменю выбрать пункт таблица переменных. Выглядеть на мониторе компьютера это будет так:
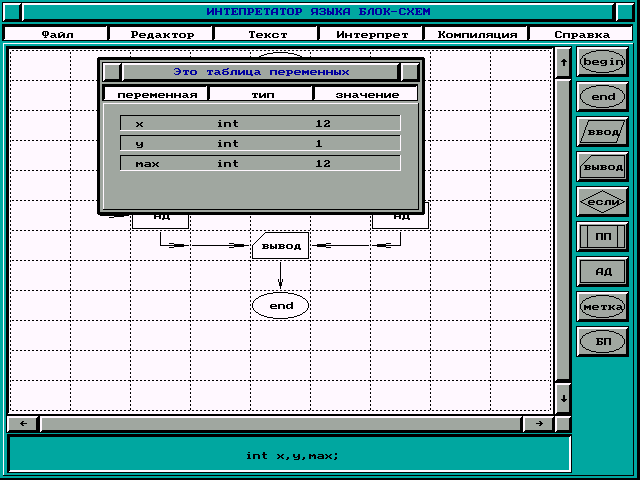
Чтобы выйти из системы нужно выбрать команду “выход” в меню файл или нажать клавиши: .
4.4.2.2. Windows версия системы
Для запуска системы под операционную систему Windows, Вы должны запустить файл “Блок-схема.exe”. На экране появится главное окно программы.
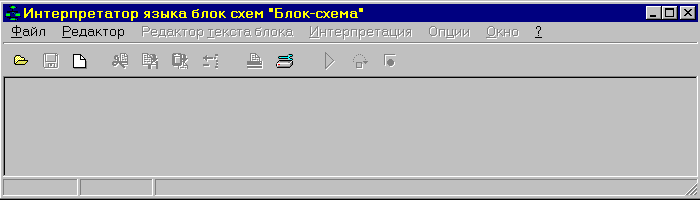
Пункты главного меню имеют следующее назначение:
Файл для того, чтобы создать блок-схему алгоритма, считать её с диска, записать на диск или выйти из системы.
Редактор подменю этого пункта предназначено для создания и редактирования блок-схем. Оно предоставляет панель инструментов - набор блоков и стрелок для построения блок-схем, а также предоставляет возможности удалять блоки и производить разметку экрана координатной сеткой, а также позволяет работать с буфером обмена.
Редактор текста блока этот пункт предназначен для набора и редактирования текста внутри блока.
Интерпретация пункты этого меню позволяют запускать пошаговый отладчик, организуют просмотр таблицы переменных, а также запускают интерпретатор.
Опции задание параметров системы и планшета.
Окно работа с окнами приложения.
Помощь здесь можно будет получать информацию о системе или о языке блок –схем.
При начальной загрузке отображается короткая панель инструментов, но после того как Вы создадите либо новую блок-схему, либо будете редактировать старую, появятся дополнительные панели инструментов. С их помощью работать с системой становится значительно проще.
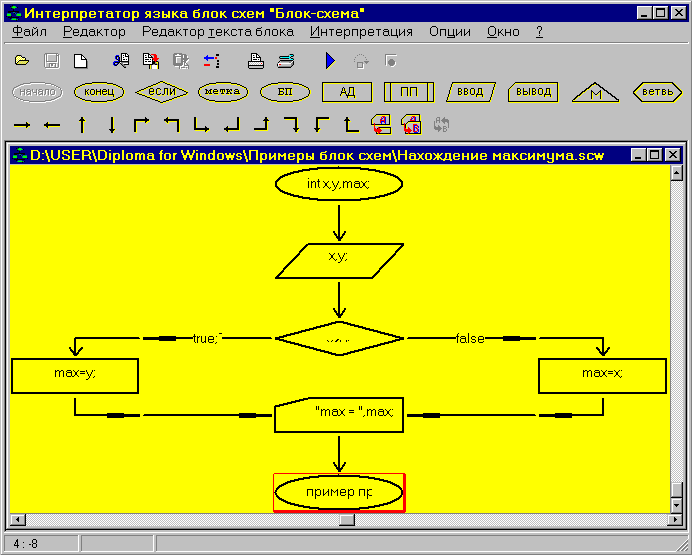
Если Вы активизируете любой нарисованный блок и выберете пункт меню “Редактор текста блока” или дважды щелкните левой клавишей мышки на соответствующем изображении блока, откроется окно текстового редактора.
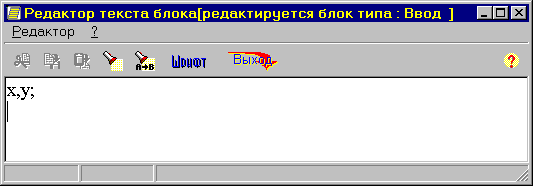
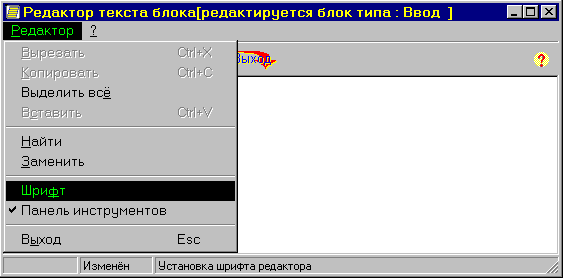
Текстовый редактор позволяет выполнять следующие действия:
Вырезать выделенный текст из текста блока и записать его в буфер обмена;
Вставить текст из буфера;
Изменить шрифт текста;
Разрешить или запретить доступ к панели инструментов;
Найти текст по заданому образцу;
Заменить заданный образец текста на новый текст.
Для выхода из редактора надо нажать клавишу , либо кнопку с надписью “Выход”.
Если Вы решили запустить программу на выполнение, то Вам нужно выбрать пункт “Интерпретация” в главном меню, а в нем пункт “выполнить”. После этого, перед Вами появится окно, которое сообщит Вам, были ли допущены Вами ошибки при создании программы. Если их не было, то программа запускается на исполнение, причем процесс выполнения отображается на блок-схеме.
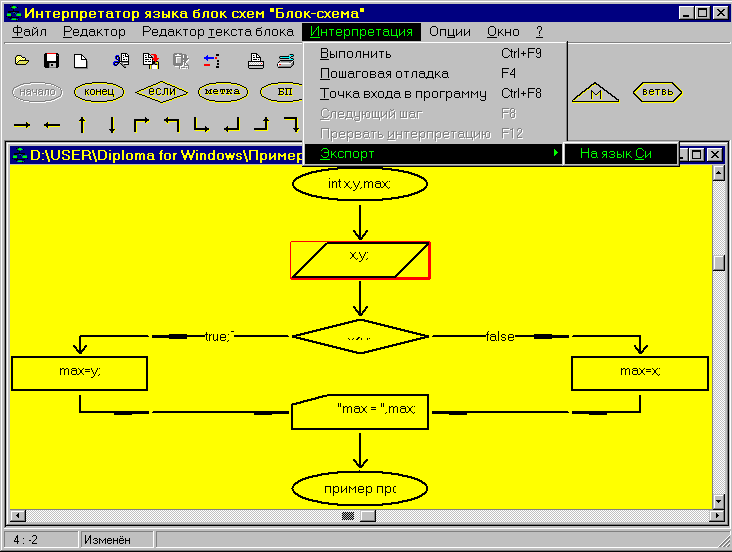
Кроме команды "выполнить" возможны следующие команды:
Пошаговая отладка;
Следующий шаг;
Прервать интерпретацию;
Установить точку входа в программу;
Экспорт на язык программирования Си.
Последние две команды можно выполнять только в режиме пошаговой трансляции.
Во время работы транслятора выдается следующее окно,
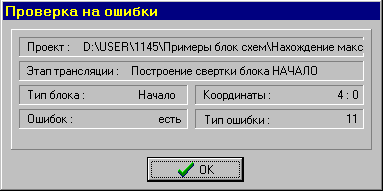
и при обнаружении ошибки выдается окно сообщений, в котором описана возможная ошибка. Например,

А в общем виде это будет выглядеть следующим образом:
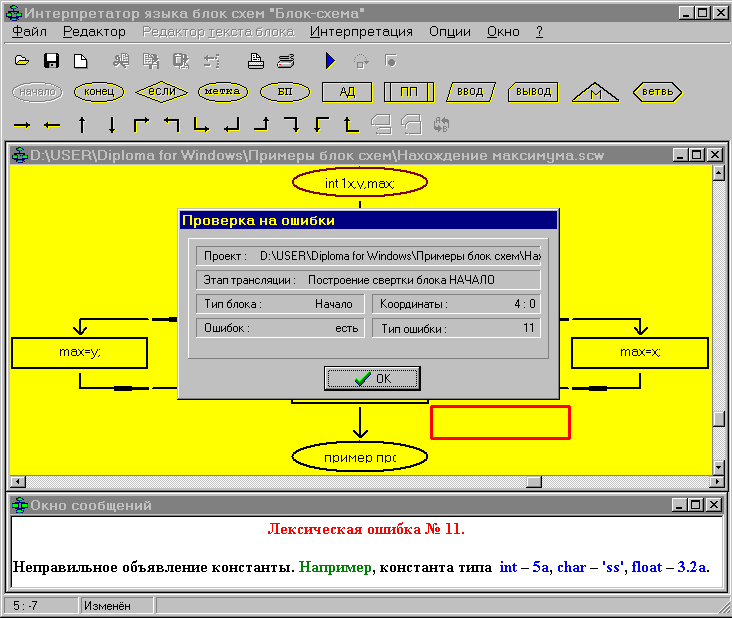
Если вы захотите изменить параметры планшета, то Вам нужно вызвать “свойства ” системы. Для этого Вам нужно один раз нажать правую кнопку мыши. После этого перед Вами появится контекстное меню со следующими пунктами:
Удалить блок;
Копировать блок;
Вставить блок;
Вырезать;
Свойства.
Нажав на пункт свойства, перед Вами появится следующее диалоговое окно:
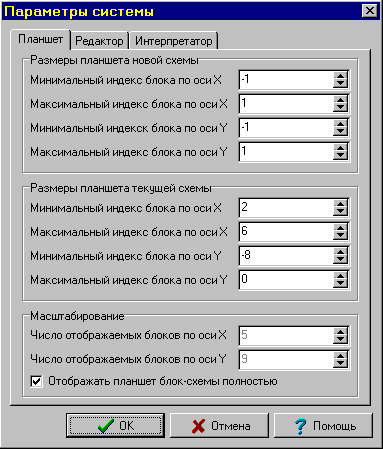
Закладка “Планшет” отвечает за свойства планшета. Закладка “Редактор” отвечает за свойства текстового и графического редакторов. Закладка “Интерпретатор” отвечает за параметры интерпретатора.
Для того, чтобы посмотреть значения переменных, надо в меню “Окно” выбрать пункт “ таблица переменных ”. Выглядеть на мониторе компьютера это будет так:
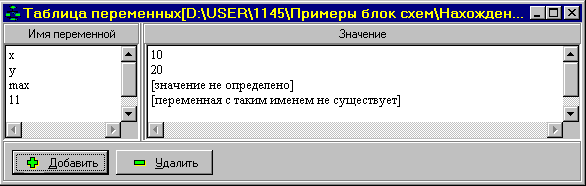
Здесь отображаются переменные и их значения. Кроме того, существует возможность редактирования списка переменных.
Чтобы закончить работу с системой нужно выбрать команду “выход” в меню “файл” или нажать клавиши: .
4.5. Внутреннее представление данных
Перечислим основные структуры данных, используемые в системе “Блок схема”.
Блок-схема алгоритма представляется как список структур следующего вида:
struct BLOCK
{
unsigned int type; // тип блока
int x; // координата блока по оси x
int y; // координата блока по оси y
char *text; // текст блока
int true_x; // переход по ИСТИНЕ по оси x на планшете
int true_y; // переход по ИСТИНЕ по оси y на планшете
int false_x; // переход по ЛЖИ по оси x на планшете
int false_y; // переход по ЛЖИ по оси y на планшете
struct BLOCK *next; // указатель на следующий элемент схемы
bool StopRun; // признак точки входа в программу
bool ErrorFlag; // признак наличия ошибок в данном блоке
bool RunBlock; // признак выполнения блока в текущий момент
struct SVERTKA* Poliz; // полиз текста блока
};
Файл схемы представляет собой последовательность следующих записей:
struct BLOCK
{
unsigned int type; // тип блока
int x; // координата блока по оси x
int y; // координата блока по оси y
char *text; // текст блока
int true_x; // переход по ИСТИНЕ по оси x на планшете
int true_y; // переход по ИСТИНЕ по оси y на планшете
int false_x; // переход по ЛЖИ по оси x на планшете
int false_y; // переход по ЛЖИ по оси y на планшете
};
Таблица переменных образованна следующим образом: она состоит из списка структур следующего вида:
struct VARIABLE
{
AnsiString Hint; // подсказка при индексации
char* name; // имя переменной
char type; // тип переменной
unsigned int Size; // размерность массива, если Size == 0,
// то это переменная
unsigned int* SizeN;// массив значений размерностей,
// если это переменная то SizeN == NULL
char* ready; // признак готовности к работе переменной
int* __int; // значение переменной типа int
long int* __long_int;// значение переменной типа long int
char* __char; // значение переменной типа char
float* __float; // значение переменной типа float
double* __double; // значение переменной типа double
struct VARIABLE* next;// указатель на следующий элемент таблицы
// переменной
};
Таблица констант также представлена списком структур следующего вида:
struct CONSTANTA
{
unsigned char type; // тип константы
int __long_int; // константа типа long int
int __int; // константа типа int
char __char; // константа типа char
float __float; // константа типа float
double __double; // константа типа double
char* __string; // константа типа string
struct CONSTANTA* next;// указатель на следующий элемент таблицы
};
Последовательность текста блока, как уже говорилось ранее, при трансляции переводится на внутренний язык транслятора. В данной системе это список сверток, которые имеют следующую структуру:
struct SVERTKA
{
unsigned char type; // тип свертки
unsigned char intype; // подтип свертки (номер операции, функции,
// процедуры в списке функций)
struct VARIABLE* variable;// если это не переменная то variable==NULL
// если переменной не существует в таблице
// переменных то variable == NULL
struct CONSTANTA* constanta;//указатель на таблицу констант
// если это не константа то constanta==NULL
// если такой константы не существует в таблице
// констант то constanta == NULL
struct SVERTKA* next; // указатель на следующий элемент свертки
int result; // счетчик числа операндов операций или функции
};
Заключение
Данная работа представляет собой транслятор с языка блок схем.
Система состоит из оболочки, графического редактора блок-схем, встроенного текстового редактора, интерпретатора, пошагового отладчика и конвертора на язык Си.
Система отлажена и протестирована на серии примеров. Система реализована в двух вариантах:
Под операционную систему MS-Dos,
Под операционные системы Windows NT, Windows 95, Windows 98.
Размер исполняемого файла в среде MS-Dos 300 Кбайт, в среде Windows 900 Кбайт.
Результаты данной работы были представлены на 6ой международной научно-практической конференции “Новые информационные технологии в университетском образовании”, которая проходила в городе Новосибирске с 17 по 19 марта 1999 года. На конференции был сделан доклад (тезисы опубликованы).
Система создавалась с целью обучения студентов первого курса ФПМиК основам программирования. Предполагается её активное использование.
Литература
Лебедев В.Н. Введение в системы программирования. - М: Статистика, 1975.-315с.
Грис Д. Конструирование компиляторов для цифровых вычислительных машин, - М: Мир, 1975.-544с.
Касьянов В.Н. , Поттосин И.В. Методы построения трансляторов.- Новосибирск: Наука, 1986. -343с.
Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции в 2-х томах. - М: Мир, 1978.
Соловьёв А.С. Интерпретатор языка блок-схем. // Материалы научно-практической конференции “Новые информационные технологии в университетском образовании”. - Новосибирск: Издательство ИДМИ, 1999.-227с.
Демин А.Ю., Гусев А.В. Визуальное программирование программ на основе блок-схем. // Материалы научно-практической конференции “Новые информационные технологии в университетском образовании” Новосибирск: Издательство ИДМИ, 1999.-227с.
Паронджанов В.Д. Язык программирования “ДРАКОН” // Программирование. – 1995. - №3.
Паронджанов В.Д. Учись рисовать ясные блок-схемы. - М: “Радио и связь”, 1995.
Рейсдорф Кент, Хендерсон Кен Освой самостоятельно Borland C++Builder. - Москва: ЗАО “Издательство БИНОМ”, 1998.-704с.
Lee C.Y. An algorithm for path connetion and its applications. // “IRE Trans.”, V.EC-10 - № 3.
Приложение
Приложение 1: Примеры блок-схем
MS-Dos версия:
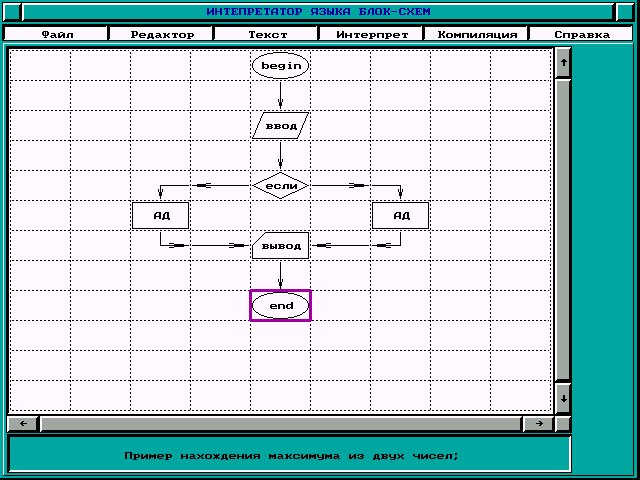
Windows версия:
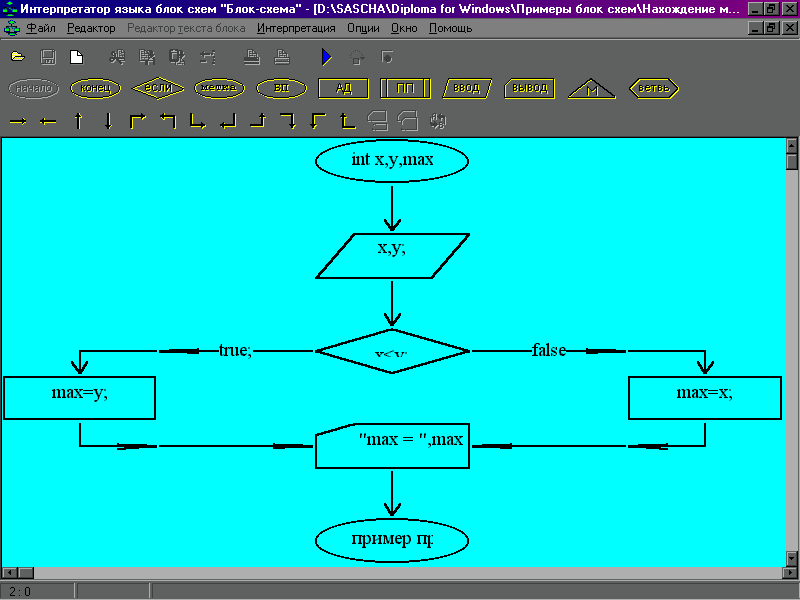
Пример 1. Нахождение максимума из двух чисел.
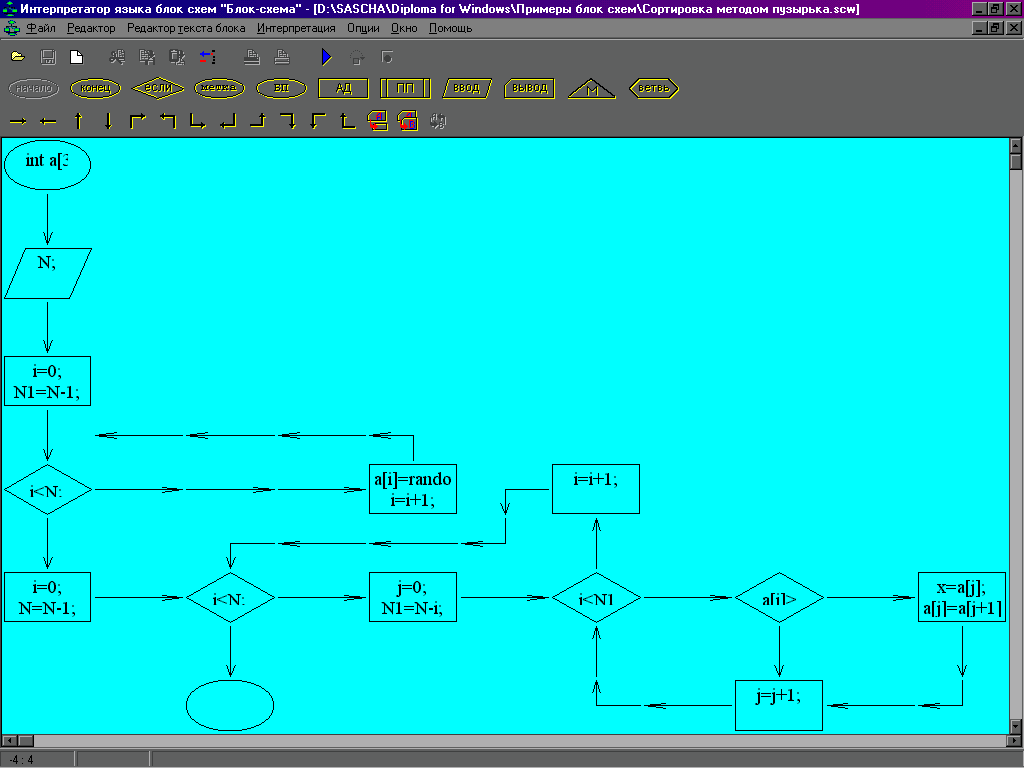
Пример 2. Сортировка методом пузырька (Windows версия).
Пример3. Вычислительная программа (MS-Dos версия)
Приложение 2: Матрицы переходов анализаторов
Матрица лексического анализатора (сканера)
| 0 | ( | ) | + | - | / | * |
|
> | = | ^ | | | ! | [ | ] | , | ; | & | . | | 0 | ‘’ | ‘ | “ | |
| 0 | 1 | 2 | 22 | 22 | 9 | 12 | 14 | 15 | 17 | 24 | 14 | 18 | 23 | 22 | 22 | 22 | 22 | 22 | 3 | -9 | E | 0 | 4 | 6 |
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1 | -1 | -1 | 0 | -1 | -1 |
| 2 | -1 | 2 | -1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1 | 0 | 0 | 0 | 0 | 3 | -1 | -1 | 0 | -1 | -1 |
| 3 | -1 | 3 | -1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1 | 0 | 0 | 0 | 0 | -1 | -1 | -1 | 0 | -1 | -1 |
| 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| 5 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 7 | -1 |
| 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | -1 | 6 | 6 | 8 |
| 7 | -1 | -1 | -1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1 | 0 | -1 | 0 | 0 | -1 | -1 | 0 | -1 | -1 |
| 8 | -1 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | 0 | -1 | -1 | -1 | -1 | 0 | -1 |
| 9 | 0 | 0 | 0 | -1 | 10 | -1 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | -1 |
| 10 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 | 0 | 0 | -1 | 0 | 0 | 0 | -1 | 0 | 0 | 0 | 0 | -1 | -1 | -1 | 0 | -1 |
| 11 | 0 | 0 | 0 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 12 | 0 | 0 | 0 | -1 | -1 | 13 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 13 | -1 | -1 | -1 | -1 | 0 | -1 | 0 | 0 | 0 | 0 | -1 | 0 | 0 | 0 | -1 | 0 | 0 | 0 | 0 | -1 | -1 | -1 | 0 | -1 |
| 14 | 0 | 0 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 15 | 0 | 0 | 0 | -1 | -1 | 0 | -1 | -1 | 16 | 0 | 11 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 16 | 0 | 0 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 |
| 17 | 0 | 0 | 0 | -1 | -1 | 0 | -1 | -1 | -1 | 16 | 11 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 18 | 0 | 0 | 0 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | 11 | -1 | 19 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 19 | 0 | 0 | 0 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 20 | 0 | 0 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | 21 | 0 | -1 | -1 | 0 | 0 |
| 21 | 0 | 0 | 0 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 23 | 0 | 0 | 0 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 24 | 0 | 0 | 0 | -1 | -1 | 0 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
Матрица синтаксических переходов блока “НАЧАЛО”
|
состояние |
Идентификатор |
Константа |
Int |
Long |
Char |
Float |
Double |
, |
; |
[ |
] |
NULL |
|
| 0 | -30 | -31 | 2 | 1 | 2 | 2 | 2 | -32 | -32 | -32 | -32 | Е | -32 |
| 1 | -30 | -31 | 2 | -30 | -30 | -30 | -30 | -32 | -32 | -32 | -32 | -32 | -32 |
| 2 | 3 | -33 | -33 | -33 | -33 | -33 | -33 | -32 | -32 | -32 | -32 | -32 | -32 |
| 3 | -32 | -32 | -32 | -32 | -32 | -32 | -32 | 2 | 0 | 4 | -32 | -32 | -32 |
| 4 | -34 | 5 | -34 | -34 | -34 | -34 | -34 | -34 | -34 | -34 | -34 | -34 | -34 |
| 5 | -34 | -34 | -34 | -34 | -34 | -34 | -34 | 4 | -34 | -34 | 6 | -34 | -34 |
| 6 | -34 | -34 | -34 | -34 | -34 | -34 | -34 | 2 | 0 | -34 | -34 | -34 | -34 |
Матрица синтаксических переходов блока “ВВОД”
|
Состояние |
идентификатор |
[ |
, |
; |
|
NULL |
| 0 | 1 | -35 | -35 | -35 | -35 | -35 |
| 1 | -35 | 1 \ 0 \-36 | 0 | 2 | -35 | -35 |
| 2 | 1 | -35 | -35 | -35 | -35 | Выход |
Матрица синтаксических переходов индексации массивов 1
|
состояние |
Идентификатор |
Константа |
Любая конст. |
[ |
] |
, |
+ |
- |
~ |
# |
* |
/ |
^ |
Mod |
Div |
( |
) |
|
NULL |
| 0 | 1 | . | 2 | . | . | . | . | . | 4 | 4 | . | . | . | . | . | 1\1 | . | . | . |
| 1 | . | . | . | 2\0 | . | . | 3 | 3 | . | . | 3 | 3 | 3 | 3 | 3 | . | Е | . | . |
| 2 | . | . | . | . | . | . | 3 | 3 | . | . | 3 | 3 | 3 | 3 | 3 | . | Е | . | . |
| 3 | 1 | . | 2 | . | . | . | . | . | . | . | . | . | . | . | . | 1\1 | . | . | . |
| 4 | 1 | . | 2 | . | . | . | . | . | . | . | . | . | . | . | . | 1\1 | . | . | . |
Матрица синтаксических переходов индексации массивов 2
|
состояние |
Идентификатор |
Константа |
Любая конст. |
[ |
] |
, |
+ |
- |
~ |
# |
* |
/ |
^ |
Mod |
Div |
( |
) |
|
NULL |
| 0 | 1 | . | 2 | . | . | . | . | . | 4 | 4 | . | . | . | . | . | 1\1 | . | . | . |
| 1 | . | . | . | 2\0 | Е | 0 | 3 | 3 | . | . | 3 | 3 | 3 | 3 | 3 | . | . | . | . |
| 2 | . | . | . | . | Е | 0 | 3 | 3 | . | . | 3 | 3 | 3 | 3 | 3 | . | . | . | . |
| 3 | 1 | . | 2 | . | . | . | . | . | . | . | . | . | . | . | . | 5\1 | . | . | . |
| 4 | 1 | . | 2 | . | . | . | . | . | . | . | . | . | . | . | . | 5\1 | . | . | . |
| 5 | . | . | . | . | Е | 0 | 3 | 3 | . | . | 3 | 3 | 3 | 3 | 3 | 5\1 | . | . | . |
Матрица синтаксических переходов функции strlen
|
состояние |
Идентифи-катор |
[ |
) |
|
NULL |
( |
Константа |
| 0 | . | . | . | . | . | 2 | . |
| 1 | . | 3 \ 0 | Выход | . | . | . | . |
| 2 | 1 | . | . | . | . | . | 4 |
| 3 | . | . | Выход | . | . | . | . |
| 4 | . | . | Выход | . | . | . | . |
Матрица синтаксических переходов блока “ВЫВОД”
|
состояние |
Константа str |
Константа |
1 |
2 |
5 |
Clock |
Strlen |
, |
( |
[ |
; |
Идентификатор |
|
NULL |
) |
| 0 | 1 | 2 | 5 | . | 4 | 6 | 2\2 | . | 2\3 | . | . | 9 | . | . | . |
| 1 | . | . | . | . | . | . | . | 0 | . | . | 10 | . | . | . | . |
| 2 | . | . | . | 3 | . | . | . | 0 | . | . | 10 | . | . | . | . |
| 3 | . | 2 | . | . | 4 | 6 | 2\2 | . | 2\3 | . | . | 9 | . | . | . |
| 4 | . | . | . | . | . | . | . | . | 2\3 | . | 10 | . | . | . | . |
| 5 | . | 2 | . | . | 4 | 6 | 2\2 | . | 2\3 | . | . | 9 | . | . | . |
| 6 | . | . | . | . | . | . | . | . | 7 | . | . | . | . | . | . |
| 7 | . | . | . | . | . | . | . | . | . | . | . | . | . | . | 8 |
| 8 | . | . | . | 3 | . | . | . | 0 | . | . | 10 | . | . | . | . |
| 9 | . | . | . | 3 | . | . | . | 0 | . | 2\0 | 10 | . | . | . | . |
| 10 | 1 | 2 | 5 | . | 4 | 6 | 2\2 | . | 2\3 | . | . | 9 | . | Е | . |
Матрица синтаксических переходов блока “Автоматические действия”
|
Состояние |
Константа str |
Константа |
Идентифик. |
( |
[ |
; |
1 |
2 |
3 |
5 |
Clock |
Getch |
Kbhit |
Strlen |
) |
|
NULL |
| 0 | . | . | 1 | . | . | . | . | . | . | . | . | . | . | . | . | . | . |
| 1 | . | . | . | 2\0 | . | . | . | 3 | . | . | . | . | . | . | . | . | . |
| 2 | . | . | . | . | . | . | . | 3 | . | . | . | . | . | . | . | . | . |
| 3 | . | 4 | 5 | 4\3 | . | . | 6 | . | . | 8 | 13 | 10 | 13 | 4\2 | . | . | . |
| 4 | . | . | . | . | . | 9 | . | 7 | . | . | . | . | . | . | . | . | . |
| 5 | . | . | . | . | 4\0 | 9 | . | 7 | . | . | . | . | . | . | . | . | . |
| 6 | . | 4 | 5 | 4\3 | . | . | . | . | . | 8 | 13 | . | 13 | 4\2 | . | . | . |
| 7 | . | 4 | 5 | 4\3 | . | . | . | . | . | 8 | 13 | . | 13 | 4\2 | . | . | . |
| 8 | . | . | . | 4\3 | . | . | . | . | . | . | . | . | . | . | . | . | . |
| 9 | . | . | 1 | . | . | . | . | . | . | . | . | . | . | . | . | . | Е |
| 10 | . | . | . | 11 | . | . | . | . | . | . | . | . | . | . | . | . | . |
| 11 | . | . | . | . | . | . | . | . | . | . | . | . | . | . | 12 | . | . |
| 12 | . | . | . | . | . | 9 | . | . | . | . | . | . | . | . | . | . | . |
| 13 | . | . | . | 14 | . | . | . | . | . | . | . | . | . | . | . | . | . |
| 14 | . | . | . | . | . | . | . | . | . | . | . | . | . | . | 4 | . | . |
Матрица синтаксических переходов математического выражения
|
состояние |
идентификатор |
Константа str |
Константа |
1 |
2 |
5 |
Clock |
Strlen |
( |
[ |
) |
|
NULL |
| 0 | 1 | . | 3 | 4 | . | 5 | 6 | 3\2 | 3\3 | . | . | . | . |
| 1 | . | . | . | . | 2 | . | . | . | . | 3\0 | Е | . | . |
| 2 | 1 | . | 3 | . | . | 5 | 6 | 3\2 | 3\3 | . | . | . | . |
| 3 | . | . | . | . | 2 | . | . | . | . | . | Е | . | . |
| 4 | 1 | . | 3 | . | . | 5 | 6 | 3\2 | 3\3 | . | . | . | . |
| 5 | . | . | . | . | . | . | . | . | 3\3 | . | . | . | . |
| 6 | . | . | . | . | . | . | . | . | 7 | . | . | . | . |
| 7 | . | . | . | . | . | . | . | . | . | . | 3 | . | . |
Матрица синтаксических переходов блока “Подпрограмма”
|
Состояние |
Константа str |
идентификатор |
[ |
; |
, |
2 |
Programm |
|
NULL |
| 0 | . | 1 | . | . | . | . | 4 | . | . |
| 1 | . | . | 2 \ 0 | . | . | 3 | . | . | . |
| 2 | . | . | . | . | . | 3 | . | . | . |
| 3 | . | . | . | . | . | . | 4 | . | . |
| 4 | 6 | 5 | . | . | . | . | . | . | . |
| 5 | . | . | . | . | 4 | . | . | . | . |
| 6 | . | . | . | 7 | . | . | . | . | . |
| 7 | . | . | . | . | . | . | . | . | Выход |
Матрица синтаксических переходов блоков “Метка” и “Безусловный переход”
|
Состояние |
Константа |
; |
|
NULL |
| 0 | 1 | . | . | . |
| 1 | . | 2 | . | . |
| 2 | . | . | . | Выход |
Матрица синтаксических переходов блока “Ветвление по условию”
|
состояние |
Константа str |
Константа |
Идентификатор |
( |
[ |
! |
4б |
; |
|
NULL |
| 0 | . | 1 | 2 | 3 \ 4 | . | 4 | . | . | . | . |
| 1 | . | . | . | . | . | . | 5 | 6 | . | . |
| 2 | . | . | . | . | 3 \ 0 | . | 5 | 6 | . | . |
| 3 | . | . | . | . | . | . | 5 | 6 | . | . |
| 4 | . | . | 2 | . | . | . | . | . | . | . |
| 5 | . | 1 | 2 | 1 \ 4 | . | 4 | . | . | . | . |
| 6 | . | . | . | . | . | . | . | . | . | Выход |
Вспомогательная матрица синтаксических переходов блока
“ Ветвление по условию ”
|
состояние |
Константа str |
Константа |
идентификатор |
( |
[ |
! |
4б |
) |
|
NULL |
| 0 | . | 1 | 2 | 3 \ 4 | . | 4 | . | . | . | . |
| 1 | . | . | . | . | . | . | 5 | Выход | . | . |
| 2 | . | . | . | . | 3 \ 0 | . | 5 | Выход | . | . |
| 3 | . | . | . | . | . | . | 5 | Выход | . | . |
| 4 | . | . | 2 | . | . | . | . | . | . | . |
| 5 | . | 1 | 2 | 1 \ 4 | . | 4 | . | . | . | . |
Матрица синтаксических переходов блока “Стрелка”
|
состояние |
true |
false |
; |
|
NULL |
| 0 | 1 | 1 | . | . | Выход |
| 1 | . | . | 2 | . | . |
| 2 | . | . | . | . | Выход |
Матрица синтаксических переходов блока “Мультиветвление”
|
Состояние |
Идентификатор |
; |
|
NULL |
| 0 | 1 | . | . | . |
| 1 | . | 2 | . | . |
| 2 | . | . | . | Выход |
Матрица синтаксических переходов блока “Конец”
|
состояние |
Return |
; |
( |
|
NULL |
| 0 | 1 | . | . | . | . |
| 1 | . | 3 | 2 \ 3 | . | . |
| 2 | . | 3 | . | . | . |
| 3 | . | . | . | . | Выход |
Приложение 3: Текст основных классов программы
Описание класса блок-схемы алгоритма:
файл описание класса ClassScheme (класс схемы)
разработан для языка блок схем, который используется
в интерпретаторе Basic Block for Windows 95 ver. 2.0.
Copyright(c) by Соловьев А.С., 1998 г., ТГУ, ФПМК,
кафедра программирования
#ifndef __CLASS_SCHEME
#define __CLASS_SCHEME
#ifndef __STRUCT_FILE
#include "struct.h"
#endif
// подключаемые библиотеки
#include
#include
#include
#include
// описатели типов блоков
#define BEGIN_BLOCK 0// блок типа начало
#define END_BLOCK 1// блок типа конец
#define IF_BLOCK 2// блок типа если
#define INPUT_BLOCK 3// блок типа ввод
#define OUTPUT_BLOCK 4// блок типа вывод
#define PP_BLOCK 5// блок типа подпрограмма
#define AD_BLOCK 6// блок типа автоматические действия
#define LABEL_BLOCK 7// блок типа метка
#define BP_BLOCK 8// блок типа безусловный переход на метку
#define MULTI_BLOCK 9// блок типа мультиветвление
#define VETV_BLOCK 10// блок типа ветвь
#define UP_BLOCK 11// блок стрелка вверх
#define DOWN_BLOCK 12// блок стрелка вниз
#define UP_RIGHT_BLOCK 13// блок стрелка вверх и направо
#define UP_LEFT_BLOCK 14// блок стрелка вверх и налево
#define DOWN_LEFT_BLOCK 15// блок стрелка вниз и налево
#define DOWN_RIGHT_BLOCK 16// блок стрелка вниз и направо
#define LEFT_BLOCK 17// блок стрелка налево
#define RIGHT_BLOCK 18// блок стрелка направо
#define RIGHT_UP_BLOCK 19// блок стрелка направо и вверх
#define LEFT_UP_BLOCK 20// блок стрелка налево и вверх
#define LEFT_DOWN_BLOCK 21// блок стрелка налево и вниз
#define RIGHT_DOWN_BLOCK 22// блок стрелка направо и вниз
// описатели типов стрелок
class ClassScheme
{
public:
bool TypeOfProgramm;// тип программы (подпрограмма==true)
char *FileNameScheme;// имя файла с которым мы работаем
struct BLOCK* HeapBlock;// указатель на вершину списка блоков схемы
struct SVERTKA* SvertkaBlock;// указатель на свертку блока
struct BLOCK* Buffer;// указатель на блок сидящий в буффере
struct VARIABLE* HeapVariable;// указатель на вершину таблицы переменных
struct CONSTANTA* HeapConst;//указатель на таблицу констант
struct Rects RectPl;// параметры планшета схемы
struct CONSTANTA* MultiConst;// свертка блока мультиветвления
bool FlagRun;// признак выполняется программа или нет
// вспомогательные функции
int Poisk_Function(char *,int ,char* []);//поиск функции//Ok
void DeleteVariable(struct VARIABLE* );//удалить таблицу переменных//Ok
void DeleteSvertka(struct SVERTKA*);//удалить свертку//Ok
void DeleteConst(struct CONSTANTA* );//удалить таблицу констант//Ok
int ClassSimbol(const char&);//класс символа//Ok
int LenTextBlock(char*);//длинна текста блока// Ok
void DeleteScheme(struct BLOCK*); //Удалить схему// Ok
void CopyStrToStr(char *,char *); //Копировать строку в строку//Ok
int AddStringToTextBlock(struct BLOCK *,char *);//Добавить строку к
//тексту блока//Ok
void GetsStringFromFile(FILE *,char *);//Прочитать строку из файла//Ok
// конструкторы
ClassScheme();
// функции для чтения записи схемы
unsigned char LoadFromFile(char *);// функция для считывания файла
// с диска //Ok
unsigned char SaveToFile(char *); // функция для записи файла на
// диск // Ok
// функции для интерпретации блок-схемы
struct VARIABLE* PoiskVar(char* );//поиск переменной по имени//Ok
struct VARIABLE* CreateVar(char*, char,unsigned int,unsigned int*,int);
//создать переменную с параметрами//Ok
struct CONSTANTA* CreateConst(unsigned char,char*);//создание константы//Ok
unsigned char TextBlockToSvertka(char *, int);//функция для построения
// свертки блока//Ok
int ClassSvertka(struct SVERTKA* ,int [][2],int ,int ,int );// класc свертки//Ok
void UnarOperation(struct SVERTKA*);// определяет унарные
// операции которые обозначены как n-арные(+,-)//Ok
struct SVERTKA* Insetr(struct SVERTKA* ,unsigned char);//вставка
// оператора в начала последовательности и после ';' //Ok
unsigned char Sintacsis(struct SVERTKA*,int [][2],int,int,int,int*,
int*);// проверка синтаксиса свертки//Ok
struct SVERTKA* SintacsisHelp(struct SVERTKA*,int [][2],int,int,int,
int*,int*);// проверка синтаксиса свертки//Ok
struct SVERTKA* Polis(struct SVERTKA*);//построение полиза//Ok
struct SVERTKA* Stek(struct SVERTKA* ,int);//поиск элемента стека если
// его нет то создание его//Ok
struct SVERTKA* Run(unsigned char,int&,struct SVERTKA*,int,
struct SVERTKA*);//
// выполнение конкретной операции
unsigned char Run(struct SVERTKA* );//функция выполнения
//команд полиза//Ok
unsigned char RunBegin(struct SVERTKA*);//выполнение команд блока начало//Ok
unsigned char Translation1(void);//Первый этап трансляции//Ok
unsigned char Translation2(void);//второй этап трансляции//Ok
unsigned char Translation3(void);//Третий этап трансляции
struct BLOCK* BpFunction(struct BLOCK*);//выполнение связки БП//Ok
float Trigonometria(struct SVERTKA*,int&);
// обработчик тригонометрических функций//Ok
struct SVERTKA* NewSvertka(int&,unsigned char,unsigned char);
// построение новой свертки//Ok
// функции поиска блока
struct BLOCK *Poisk(struct BLOCK *);// поиск блока по адресу//Ok
struct BLOCK *Poisk(int,int);// поиск блока по заданным координатам//Ok
struct BLOCK *Poisk(unsigned int);// поиск блока по типу блока//Ok
// функции создания, добавления, вырезания и удаления блока из схемы
void Add(struct BLOCK*);//добавить блок к схеме//Ok
struct BLOCK *Create(unsigned int,int,int,int,int,int,int,char *);
// создать блок по параметрам//Ok
struct BLOCK* Cut(struct BLOCK* );//вырезать блок из схемы//Ok
void DelBlock(struct BLOCK* );//удалить блок из схемы по адресу//Ok
void DelBlock(int ,int );//удалить блок из схемы по координатам//Ok
// функции для работы с буфером обмена блоков схемы
void CopyBuffer(struct BLOCK*);//скопировать блок в буфер обмена
//по адресу//Ok
void CopyBuffer(int x,int y);//скопировать блок в буфер обмена
//по заданным координатам//Ok
void CutBuffer(struct BLOCK*);//вырезать блок из схемы и занести
//в буффер обмена по адресу //Ok
void CutBuffer(int x, int y);//вырезать блок из схемы и занести
//в буффер обмена по координатам //Ok
void PasteFromBuffer(int, int);//добавить блок в схему в позицию x,y/Ok
// функции вычисления размеров планшета(минимальных)
void SizeOfPlanhet( void );//Ok
// Функции алгоритма Ли
void AddNumber(int*,int,int,int,int,int);//добавить число//Ok
int Maximum(int*,int,int,int,int);//найти максимум//Ok
float Rastoanie(int,int,int,int);//Вычислить расстояние//Ok
void Index(int*,int,int,int,int,int,int,int,int &,int &);//Определение
//индекса//Ok
bool Algoritm(int*,int,int,int,int,int,int);//Алгоритм//Ok
int* MatrLee( int&,int&,int,int,int,int);// построение матрицы//Ok
bool StartLee(int,int,int,int);//стартовая функция Ли//Ok
// деструкторы
~ClassScheme();
};
#endif
Файл объявления основных структур программы:
Файл описание основных структур используемых интерпретатором
языка блок-схем Basic Block for Windows 95 ver 2.0.
Copyright(c) 1998, Соловьев А.С. 1998/1999 гг.
#ifndef __STRUCT_FILE
#define __STRUCT_FILE
struct NameOfVar
{
char* name;
struct NameOfVar* next;
};
struct Rects
{
int Left;
int Top;
int Right;
int Bottom;
};
struct BLOCK
{
unsigned int type; // тип блока
int x; // координата блока по оси x
int y; // координата блока по оси y
char *text; // текст блока
int true_x; // переход по ИСТИНЕ по оси x на планшете
int true_y; // переход по ИСТИНЕ по оси y на планшете
int false_x;// переход по ЛЖИ по оси x на планшете
int false_y;// переход по ЛЖИ по оси y на планшете
struct BLOCK *next; // указатель на следующий элемент схемы
bool StopRun;// прнизнак точки входа в программу
bool ErrorFlag;// признак наличия ошибок в данном блоке
bool RunBlock;// признак выполнимого блока в текущий момент
struct SVERTKA* Poliz;// полиз текста блока с учетом свертки
};
struct VARIABLE
{
AnsiString Hint; // подсказка при индексации
char* name; // имя переменной
char type; // тип переменной
unsigned int Size; // размерность массива если Size == 0,
// то это переменная
unsigned int* SizeN; // массив значений размерностей,
// если это переменная то SizeN == NULL
char* ready; // признак готовности к работе переменной
int* __int; // значение переменной типа int
long int* __long_int; // значение переменной типа long int
char* __char; // значение переменной типа char
float* __float; // значение переменной типа float
double* __double; // значение переменной типа double
struct VARIABLE* next;// указатель на следующий элемент таблицы
// переменной
};
struct CONSTANTA
{
unsigned char type;// тип константы
int __long_int; // константа типа long int
int __int; // константа типа int
char __char; // константа типа char
float __float; // константа типа float
double __double; // константа типа double
char* __string; // константа типа string
struct CONSTANTA* next;// указатель на следующий элемент таблицы
};
struct SVERTKA
{
unsigned char type; // тип свертки
unsigned char intype; // подтип свертки (номер операции, функции,
// процедуры в списке функций)
struct VARIABLE* variable;// если это не переменная то variable==NULL
// если переменной не существует в таблице
// переменных то variable == NULL
struct CONSTANTA* constanta;//указатель на таблицу констант
// если это не константа то constanta==NULL
// если такой константы не существует в таблице
// констант то constanta == NULL
struct SVERTKA* next; // указатель на следующий элемент свертки
int result; // счетчик числа операндов операции или функции
};
#endif