
Рефераты по рекламе
Рефераты по физике
Рефераты по философии
Рефераты по финансам
Рефераты по химии
Рефераты по хозяйственному праву
Рефераты по цифровым устройствам
Рефераты по экологическому праву
Рефераты по экономико-математическому моделированию
Рефераты по экономической географии
Рефераты по экономической теории
Рефераты по этике
Рефераты по юриспруденции
Рефераты по языковедению
Рефераты по юридическим наукам
Рефераты по истории
Рефераты по компьютерным наукам
Рефераты по медицинским наукам
Рефераты по финансовым наукам
Рефераты по управленческим наукам
Психология и педагогика
Промышленность производство
Биология и химия
Языкознание филология
Издательское дело и полиграфия
Рефераты по краеведению и этнографии
Рефераты по религии и мифологии
Рефераты по медицине
Рефераты по сексологии
Рефераты по информатике программированию
Краткое содержание произведений
Реферат: Генетический алгоритм глобальной трассировки
Реферат: Генетический алгоритм глобальной трассировки
О.Б. Лебедев
1 Введение
Основной целью задачи глобальной трассировки является равномерное и целесообразное распределение ресурсов коммутационного поля для создания благоприятных условий для последующей детальной трассировки.
Большинство алгоритмов, глобальной трассировки осуществляют последовательное построение соединений на укрупненной модели КП (волновые, лучевые, базирующиеся на построении деревьев Штейнера). [1,2,3,4,5,6,7]. Хотя на каждом шаге для каждого текущего состояния среды алгоритмы дают неплохие результаты, «камнем преткновения» является последовательность трассируемых соединений. Цепи, проложенные раньше ,могут блокировать цепи ,прокладываемые позже.
Другим недостатком является то, что большинство алгоритмов используют критерии в большей степени учитывающие параметры соединений (например: общая длина) и в меньшей степени параметры коммутационного поля, что не совсем согласуется с главной целью глобальной трассировки.
Исходя из этих соображений, в работе используется комбинаторный подход, основанный на методах генетической адаптации, при котором в один и тот же момент времени рассматриваются все соединения, а критерий учитывает распределение ресурсов КП.
При разработке генетических процедур основное влияние уделялось разработке с учетом знаний о предметной области методов кодирования решений, модификации генетических операторов и организации эволюционного процесса.
2. Проблемная формулировка, термины и обозначения
Для решения задачи глобальной трассировки используется графовая модель G = (X, U). Коммутационное поле разбивается на области. Вершины графа xi Î Х соответствуют областям на КП. Если области соседние, то вершины xi и xк, соответствующие этим областям, связываются ребром uj. Пусть задано множество цепей Т=ti. Для каждой цепи определяется множество областей, в которых существуют контакты, связываемые этой цепью. На графовой модели G, множеству областей, связываемых цепью xi, соответствует подмножество вершин Хi Ì Х. Для каждого ребра ui, связывающего вершины, задается вес aj, равный пропускной способности между областями, соответствующими вершинам xi и xk. Будем считать, что граф G метризирован, то есть каждая вершина имеет координаты. Координаты вершины принимаются равными координатам центра соответствующей области. Если области имеют один и тот же размер, то граф G представляет собой ортогональную решетку.
Далее для каждой цепи ti на множестве вершин Хi графа G строится минимальное связывающее дерево Di с помощью алгоритма Прима Di=rk , где rk – ребро минимального связывающего дерева.
Для каждого ребра rk ÎDi формируется набор Vk вариантов vik маршрутов, связывающих на графе G соответствующие вершины. Формирование возможных маршрутов осуществляется следующим образом. Для ребра rkÎDi, связывающего xnÎG и xmÎG, определяется множество вершин Хk Ì X, смежных вершинам хn и хm ребра rk,. Через множество вершин Хк , а так же через вершины xn и xm проводятся новые вертикальные и горизонтальные линии.Отметим, что эти линии проходят по ребрам ортогонального графа G. В узлах пересечения этих линий лежат некоторые вершины хi Î Х. Эти вершины являются узловыми для формирования вариантов. Будем считать, что варианты маршрутов проходят по тем ребрам графа G, которые лежат на этих линиях, рис 1.
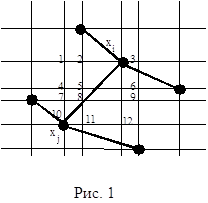
Например: сформируем набор вариантов для ребра гк, связывающего вершины хi и хj. Пронумеруем узлы пересечения вертикальных и горизонтальных линий. Вершина хi лежит в узле 3, а вершина хj в узле 10. Для данного ребра гk существует 10 вариантов прохождения маршрута Vk = {vk1, vk2, vk3, vk4, vk5, vk6, vk7, vk8, vk9, vk10}
vk1 = {3, 2, 5, 8, 11, 10}; vk2 = {3, 6, 5, 8, 11, 10}; vk3 = {3, 6, 9, 8, 11, 10}; vk4 = {3, 6, 9, 12, 11, 10}; vk5 = {3, 2, 1, 4, 7, 10}; vk6 = {3, 2, 5, 4, 7, 10}; vk7 = {3, 6, 5, 4, 7, 10}; vk8 = {3, 2, 5, 8, 7, 10}; vk9 = {3, 6, 5, 8, 7, 10}; vk10 = {3, 6, 9, 8, 7, 10}
Такой способ обеспечивает максимальное совпадение вариантов реализации ребра rk с вариантами ребер, смежных ребру rk. Формирование варианта осуществляется из следующих соображений:
вариант формируется таким образом, чтобы он был минимальной длины.
варианты формируются, чтобы обеспечивалось максимально возможное совпадение вариантов различных ребер одной цепи друг с другом.
Пусть имеется некоторое решение задачи глобальной трассировки, заключающееся в том, что для всех ребер гk всех МСД-цепей, выбраны варианты их реализации. Введем некоторые обозначения. Обозначим через bi число цепей, проходящих по ребру ui графа G. Для каждого ребра ui графа G введем параметр сi, равный сi = ai - bi.
Найдем в графе G ребро, у которого сi имеет минимальное значение, и обозначим его через сmin, то есть cmin ® "i[cmin £ ci].
Для нашей задачи цель оптимизации – максимизация параметра сmin. При перезагрузках параметр сmin может принимать отрицательное значение. Для оценки качества удобнее использовать критерий, который имеет только положительные значения. Обозначим через am – максимально возможное значение показателя ai среди всех ребер ui графа G, т.е. am ® ("i)[ am ³ ai]. В силу этого величина am – cmin никогда не может быть отрицательной, т.е. am – cm ³ 0. Отметим, что am является константой.
В качестве фитнесса (оценки качества) индивидуальности будет использоваться критерий
![]()
Цель оптимизации – максимизация F1.По своей сути максимизация F1 совпадает с максимизацией cmin.
В качестве другого критерия оптимизации можно использовать другую характеристику. Обозначим через g число ребер графа G для которых ci имеет отрицательное значение. Очевидно, что целью генетического поиска должен быть поиск решения (индивидуальности) у которого g имеет минимальное значение.
Пусть m – число всех ребер графа G. Введем фитнесс F2=m - g.
Цель оптимизации в таком случае – максимизация F2
Если при оптимизации по критерию F1 не удается найти такого решения при котором у всех ребер ui Î G, соответствующие им сi имеют положительные значения, то оптимизация по критерию F2 минимизирует число таких ребер. Это делается из следующих соображений: чтобы обеспечить 100% реализацию (разводки) соединений, потребуется меньшее число деформаций областей или границ.
Обозначим через j число ребер всех цепей, для которых выбранные и реализованные варианты соединений включают ребра ui графа G с отрицательными значениями сi.
Пусть Nd – общее число ребер всех максимальных связывающих деревьев.
Введем третий критерий оптимизации: F3=Nd - j
Цель оптимизации заключается в максимизации F3. Это обеспечивает минимальное число соединений, требующих перетрассировки, т.е. оптимизация по F3 уменьшает число перетрассируемых соединений. Если при оптимизации по F1, имеются ребра с отрицательными сi, то в зависимости от метода дотрассировки, деформации областей или границ, используется критерий F2 или F3.
3. Разработка генетических процедур для задачи глобальной трассировки
3.1. Кодирование и декодирование хромосом
Для решения задачи глобальной трассировки используются генетические методы оптимизации. Представим решение в виде хромосомы. Кодирование осуществляется следующим образом. Хромосома состоит из генов. Количество генов в хромосоме Hi равно количеству ребер минимальных связывающих деревьев для всех цепей, расположенных на КП. Значением гена является номер варианта из заданного набора вариантов маршрутов, связывающих на графе G соответствующие вершины.
Например, дано КП, на котором расположено множество цепей Т = {t1, t2, t3} , рис. 2.
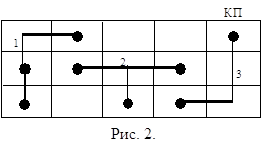
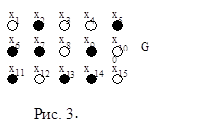
Так как мы используем графовую модель, то КП можно представить соответственно рис. 3.
Для цепи t1 множество связуемых вершин – Х1 = {x6, x2, х11}. Для цепи t2 множество связуемых вершин – Х2 = {x7, x9, x13 }. Для цепи t3 множество связуемых вершин – Х3 = {x5, x14}. С помощью алгоритма Прима для каждой цепи строится минимальное связывающее дерево МСД. Для каждой из цепей это выглядит так:рис. 4.
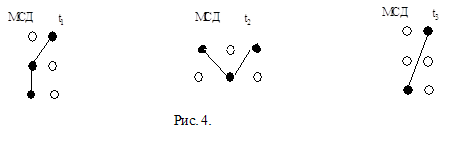 После этого для
каждого ребра rij МСД формируется набор вариантов
маршрутов, связывающих на графе G соответствующие вершины.
После этого для
каждого ребра rij МСД формируется набор вариантов
маршрутов, связывающих на графе G соответствующие вершины.
Ребро г11 (то есть первое ребро МСД для цепи 1) имеет два варианта прохождения маршрута r11 = {v111, v112}: v111={x6,x1,x2}, v112={x6,x7,x2}.
Ребро r12 (второе ребро цепи 1) имеет один вариант V121={x6,x11}
Ребро г21 (то есть первое ребро МСД для цепи 2) имеет два варианта прохождения маршрута r21={v211,v212} : v211={x7,x8,x13} v212={x7,x12,x13}.
Ребро r22 имеет два варианта v221={x13,x8,x9}, v222={x13,x14,x9}.
Ребро г31 (то есть первое ребро МСД для цепи 3) имеет три варианта прохождения маршрута, r31 = {v311, v312, v313}, v311={x5,x10,x9,x14}; v312={x5,x4,x9,x14}; v313={x5,x10,x15,x14}.
Для решения представленного на рис. 2. структура хромосомы имеет вид рис. 5
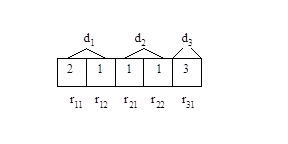
Рис. 5
Число генов равно 5. Гены g1 и g2 соответствуют ребрам r11 и r12 дерева D1; g3 и g4 соответствуют ребрам r21 и r22 дерева D2; g5 соответствует ребру r31 дерева D3. Значение g1 равно 2, т.к. для реализации r11 выбран вариант V112. g2 равно 1, т.к. r12 реализован вариантом V121. Аналогично, т.к. r21,r22 и r31 реализованы соответственно вариантами V211, V221 и V313, то g3=1, g4=1, g5=3.
Отметим, что между структурой и видом хромосомы с одной стороны и решением (распределением соединений на КП) с другой стороны существует взаимно - однозначное соответствие. Отличительной особенностью предложенной структуры хромосомы является то, что отсутствует какая либо зависимость между генами, обусловленная самой структурой. Это свойство исключает возможность появления нелегальных хромосом, подобно тому, как это происходит с хромосомами, представляющими собой списковые структуры. В свою очередь это упрощает реализацию рассматриваемых ниже генетических операторов.
Пусть L – число всех
ребер всех МСД. L= число выводов – число цепей. Тогда объем V1 ОЗУ, необходимой
для хранения информации об вариантах реализации ребер МСД, будет ![]() , где nv – число
вариантов реализации одного ребра.
, где nv – число
вариантов реализации одного ребра.
Объем V2 ОЗУ необходимый
для одной хромосомы ![]() . К2
помимо всего прочего учитывает необходимость хранения фитнесса хромосомы.
. К2
помимо всего прочего учитывает необходимость хранения фитнесса хромосомы.
Для популяции
состоящей из М хромосом ![]() .
.
Таким образом,
общий объем памяти ![]() имеет линейную
зависимость и при заданных параметрах nv и M
пространственная сложность алгоритма ~
O(L).
имеет линейную
зависимость и при заданных параметрах nv и M
пространственная сложность алгоритма ~
O(L).
3.2 Формирование исходной популяции
Для организации генетического поиска формируется исходная популяция особей P=Hi, где М размер популяции. Популяция Р- представляет собой репродукционную группу – совокупность индивидуальностей, любые две из которых HiÎP и HjÎP, i ¹ j могут размножаться выступая в роли «родителей». Предварительно с помощью процедуры FORM осуществляется разбиение КП на области и формирование модели КП в виде графа W=(X,U). Далее для каждой цепи ti Î Т строится алгоритмом Прима один из вариантов минимального связывающего дерева Di={ri, li=1, … ni}
Затем для каждого rij синтезируется набор Vij вариантов маршрутов в ортогональном графе G, реализующих ребро rij. Пусть nij=| Vij | - число вариантов реализации ребра rij.
Определяется длина L хромосомы, являющейся носителем информации о конкретном решении:
![]()
Параметр L определяет число генов в хромосоме. С помощью графика соответствия Q устанавливается соответствие Г(G, Q, R) между генами хромосомы и ребрами минимальных связывающих деревьев для всех цепей.
G= n=1, 2,… ,L; R= i=1, 2, … ,ni, j=1,2, … ni
Образом Г(rij) является ген gn. Прообразом Г-1(gn) является ребро rij Значением гена gn, будет номер варианта реализации ребра rij=Г-1(gn) .
Ген gn может принимать любое значение от 1 до nij.
В работе используется принцип случайного формирования исходной популяции.
Для этого в пределах каждой хромосомы Нк каждый ген gn принимает случайное значение в пределах от 1 до nij , где nij число вариантов реализации ребра rij=Г-1(gn).
Управляемыми
параметрами при формировании популяции является М - размер популяции, nmax - максимальное
число вариантов реализации ребер, т.е. ("ij) [nij![]() nmax]. Если
возможное число вариантов nij больше nmax то возникает
возможность формирования альтернативных наборов вариантов Vij для rij. Кроме того
существует возможность построения альтернативных МСД Di для одной и той
же цепи ti.
nmax]. Если
возможное число вариантов nij больше nmax то возникает
возможность формирования альтернативных наборов вариантов Vij для rij. Кроме того
существует возможность построения альтернативных МСД Di для одной и той
же цепи ti.
Все это дает возможность для комбинирования при синтезе исходной популяции. Известно, что для выхода из локальных оптимумов используется механизм смены исходных популяций.
В простейшем случае это можно реализовать с помощью повторной, случайной генерации.
3.3 Генетические операторы
Для получения нового решения (индивидуальности) используются генетические операторы: кроссинговер и мутация.
Кроссинговер заключается во взаимном обмене генами между «родителями» - хромосомами предварительно выбранной пары.
В нашем случае все хромосомы гомологичны, т.к. имеют одну и ту же структуру, одну и ту же длину и несут информацию об одном и том же наборе МСД. Гены, расположенные в одном и том же локусе хромосом, гомологичны, т.к. несут информацию об одном и том же ребре хромосомы.
Предварительно задается величина PK – вероятность кроссинговера и вводится флажок FG с двумя состояниями «выполнять», «не выполнять». Исходное состояние FG «не выполнять». При выполнении кроссинговера последовательно просматриваются локусы выбранной пары хромосом. С вероятностью Pk «флажок» FG переходит в состояние «выполнять». Если FG перешел в состояние «выполнять», то производится обмен генами между парой хромосом в текущем локусе, далее «флажок» переходит в состояние «не выполнять», а затем осуществляется переход к следующему локусу.
Такой алгоритм кроссинговера обеспечивает мультиобмен. Число пар обменивающихся генов определяется параметром Pk.
Операция мутации заключается в изменении значения гена. Алгоритм мутации реализуется следующим образом.
Предварительно,
для каждого гена gn, определяется диапазон его возможных
значений от 1 до yn, где yn – число
сформированных вариантов реализации ребра ![]() .
.
Задается параметр PM – вероятность мутации и «флажок» FG с двумя состояниями «выполнять» и «не выполнять». Исходное состояние FG – «не выполнять».
Последовательно выбираются хромосомы из текущей популяции. В пределах выбранной хромосомы последовательно просматриваются гены. После перехода к очередному гену, FG с вероятностью PM переходит в состояние «выполнять». Если FG перешел в состояние «выполнять», то случайным образом ген gn принимает одно из значений в заданном диапазоне, за исключением значения, которое ген имеет перед мутацией. Далее FG переходит в состояние «не выполнять» и выбирается следующий ген хромосомы, или следующая хромосома.
Для улучшения
процесса поиска лучшего решения введем дифференцируемое значение показателя ![]() , принимающего различные
значения в зависимости от значения гена.
, принимающего различные
значения в зависимости от значения гена.
Введем для гена gn оценку ![]() , где ln – число ребер ui, входящих в
маршрут vijk реализующий ребро
, где ln – число ребер ui, входящих в
маршрут vijk реализующий ребро
![]() , соответствующее гену gn.
, соответствующее гену gn. ![]() - число таких ui,, входящих в vijk ,для которых
показатель загрузки ci имеет отрицательное значение.
- число таких ui,, входящих в vijk ,для которых
показатель загрузки ci имеет отрицательное значение.
Кn меняется от 0 до 1. Чем больше Kn, тем “хуже” маршрут vijk, и тем больше оснований к его смене.
Значение
показателя ![]() с учетом Кn для гена gn определяется
следующим образом
с учетом Кn для гена gn определяется
следующим образом
![]()
параметр D связан с Pm следующим соотношением
![]() ,
,
т.е. D меняется от 0 до (1-Pm).
В предельном случае
![]()
Как видно из
алгоритмов, реализующих процедуры кроссинговера и мутации, временная сложность
операторов кроссинговера и мутации применительно к одной хромосоме имеют
линейную зависимость, ![]() , где L – длина
хромосомы.
, где L – длина
хромосомы.
3.4 Общая структура генетического поиска для глобальной
трассировки
В соответствии с методикой описанной выше на первых подготовительных этапах осуществляется разбиение КП на плоскости. Для всех цепей строятся минимальные связывающие деревья. Для всех ребер МСД формируются наборы вариантов реализующих их соединений. Управляющими параметрами генетической адаптации являются: М – размер исходной популяции, Т – число генераций, PK – вероятность кроссинговера, Pm – вероятность мутации.
После сформирования исходной популяции Пи для каждой индивидуальности рассчитывается фитнесс.
Алгоритм расчета
фитнесса имеет следующий вид: в качестве исходных данных используется вектор
А=al, где al – пропускная
способность ребра ul. Для расчета фитнесса используется
вектор B, имеющий ту же
размерность, что и вектор А. Вначале элементы ![]() имеют нулевое
значение. Вектор В служит для учета загрузки ребер Ur всеми цепями.
имеют нулевое
значение. Вектор В служит для учета загрузки ребер Ur всеми цепями.
Значения ![]() растут последовательно и,
после просмотра всех генов, bl является
значением числа цепей, проходящих через ul.
растут последовательно и,
после просмотра всех генов, bl является
значением числа цепей, проходящих через ul.
Имея вектора А и В, рассчитываются значения показателей cl=al-bl для каждого ребра ul. На основании значений cl расcчитываются критерии F1, F2 и F3.
Если учесть, что число вариантов имеет фиксированное значение и обычно, не превышает 4-6, то трудоемкость подсчета вектора В линейна и пропорциональна длине хромосом. Трудоемкость процедуры поиска cmin также линейна. В связи с этим трудоемкость tф расчета фитнесса для одной хромосомы имеет линейную зависимость от длины хромосомы tф~O(L).
После расчета фитнесса для исходной популяции применяется оператор кроссинговера.
Селекция родительских пар хромосом осуществляется либо на основе «принципа рулетки», либо на основе рейтинга популяции.
С этой целью все хромосомы популяции сортируются в соответствии с рассчитанными значениями фитнесса. После этого осуществляется селекция пары родственных хромосом по правилу: i - я с i+1 – ой.
Для каждой новой индивидуальности, образованной в результате кроссинговера, расчитывается фитнесс. После кроссинговера текущая популяция ПТ включает исходную ПИ и популяцию ПК , образовавшуюся в результате выполнения кроссинговера.
ПТ=ПИ+ПК.
Далее ко всем индивидуальнастям ПТ применяется оператор мутации. Для всех индивидуальностей популяции ПМ , образовавшихся в результате мутации расчитывается фитнесс. Заключительным этапом в пределах одного поколения является процесс редукции популяции ПТ=ПИ+ПК+ПМ до размеров ПИ на основе селективного отбора. Селекция осуществляется на основе “принципа рулетки”.
Вероятность выбора индивидуальности определяется как:
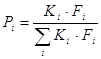
С помощью коэффициентов Кi, которые для «лучших» индивидуальностей имеют большие значения, чем у «худших», достигаются увеличение вероятности выбора «лучших» индивидуальностей.
Временная сложность алгоритма определяется общими (подготовительными) затратами to и затратами в пределах каждого поколения td . Общие затраты складываются из затрат на построении минимальных связывающих деревьев td ,формирование вариантов реализации ребер tb ,и формирования исходной популяции tи: to=td+tb+tи.
Затраты на построение МСД находятся в зависимости от числа МСД. С другой стороны при построении конкретного МСД затраты пропорциональны квадрату числа связываемых вершин . Учитывая , что число ребер n всех МСД пропорционально числу МСД , можно считать, что оценка ВСА tо лежит в пределах О(n)-O(n2), причем чем больше n тем ближе к О(n).
Затраты в пределах поколения tn складываются из затрат на операторы кроссинговера tк , мутации tm ,расчета фитнесса tф и селекции tс .
Как уже указывалось выше затраты tк ,tм и tф при обработке одной хромосомы имеют линейную зависимость от n . tс имеет линейную зависимость от объема популяции М . Тогда временные затраты в пределах поколения имеют оценку О(n×M). Для Т генераций временная сложность алгоритма имеет оценку О(n×M×T) . Учитывая что параметры М и Т сравнимы или значительно меньше n, можно считать , что оценка временной сложности всего алгоритма в целом лежит в пределах О(n2)-O(n3).
4. Экспериментальные исследования генетического алгоритма глобальной трассировки
Алгоритм глобальной трассировки был реализован на языке С++, экспериментальные исследования проводились на ЭВМ типа IBM PC/AT Pentium 133.
При проведении экспериментальных исследований преследовались две цели:
Первой целью являлось исследование механизмов генетического поиска для задачи глобальной трассировки. Для достижения этой цели исследовалось влияние управляющих операторов, таких как: размер популяции М, число поколений Т, вероятность мутации РМ, вероятность кроссинговера РК. В результате этих исследований определялось такое сочетание значений этих параметров, которое обеспечивает наивысшую эффективность генетических процедур для задачи глобальной трассировки.
Второй целью являлось исследование собственно, эффективности разработанного генетического алгоритма. Исследовались влияния таких параметров, как число вариантов маршрутов для каждого ребра.
Для проведения исследований были синтезированы 5 тестовых примеров.
Основные характеристики примеров.
Использовалось КП с размерами 10*10 (10 дискретов по горизонтали и 10 дискретов по вертикали). Выводы, связываемые цепями, размещались внутри дискретов. В каждом дискрете только один вывод одной цепи. Число выводов, связываемых одной цепью - от 2 до 5. В один дискрет назначалось до 10 выводов. Среднее число цепей - 200 -250. Назначение выводов в дискреты осуществлялось случайным образом.
Оптимизация проводилась по критерию:
F1=![]() ("i)[Cmin£Ci=ai-bi]
("i)[Cmin£Ci=ai-bi]
Если оказывалось, что Сmin<0, то оптимизация автоматически переключалась на критерий F2 = m - g, где g- число ребер, проходящих через грани с отрицательным значением Сmin.
Для нахождения наилучшего сочетания таких параметров, как Рм, Рк, М и Т, а также для выбора последовательности и типа генетических операторов экспериментальные исследования проводились следующим образом:
Для каждого примера сначала фиксировался параметр Рм и изменялись параметры Рк и М. Проводилась серия из десяти экспериментов для каждого фиксированного набора параметров. Затем фиксировался параметр Рк. Формирование исходной популяции осуществлялось следующим образом. Для каждой цепи строилось МСД. Если в процессе его построения возможно несколько альтернатив, то выбиралась первая. Для каждого ребра каждого дерева формировался набор вариантов маршрутов. Для каждой хромосомы исходной популяции выбор вариантов осуществлялся случайным образом.
При проведении испытаний для каждого эксперимента фиксировался номер генерации, после которой не наблюдалось улучшения оценки. В каждой серии из десяти испытаний фиксировались минимальные, максимальные и средние числа генераций.
Для каждой серии испытаний определялось лучшее решение, которое фактически являлось оптимальным. Затем фиксировалось число испытаний, при которых были получены оптимальные решения, число испытаний при которых были получены решения отличающиеся от оптимальных менее чем на 5%, и число испытаний, при которых решения отличались от оптимального более чем на 5%.
Экспериментальные исследования показали, что наилучшим является следующее сочетание управляющих параметров: Рм=0.2, Рк=0.4.
На основе обработки экспериментальных исследований была построена зависимость качества решений от числа генераций.
В качестве аналога для сравнения выбран алгоритм WRST [7], основанный на последовательном построении взвешенных деревьев Штейнера. В алгоритме WRST также как и в рассмотренном в статье, каждая цепь представляется в виде связывающего дерева, построенного алгоритмом Прима, на основе которого последовательно строится дерево Штейнера с учетом веса ребер и динамически изменяющейся в процессе построения среды (коммутационного поля).
В таблице 1. представлены результаты сравнения экспериментальных данных с аналогом для пяти примеров.
В колонках F приводятся усредненные значения критерия F для генетического алгоритма (ГА) и для алгоритма WRST.
В колонке å L приводится суммарная длина, а в колонке t время работы алгоритма.
Как видно из таблицы генетический алгоритм обеспечивает более качественное решение, причем время решения на 10-40% меньше.
Сравнение с алгоритмами, использующими идею волнового алгоритма Ли, не проводилось, так как они дают худшие результаты, чем WRST[83].
Таблица 1.
| № | F | å L | T | |||
| WRST | WRST | WRST | ||||
| 1 | +2 | 0 | 4212 | 4570 | 33 | 37 |
| 2 | +3 | 0 | 3870 | 4610 | 31 | 34 |
| 3 | +1 | -2 | 5180 | 5900 | 57 | 69 |
| 4 | +3 | +1 | 4256 | 4570 | 59 | 61 |
| 5 | +2 | 0 | 3650 | 4220 | 29 | 34 |
5. Заключение
Приведена формулировка задачи глобальной трассировки. Определены перспективные критерии оптимизации. Разработана структура хромосомы, принципы ее кодирования и декодирования, использующие знания о задаче глобальной трассировки, исключающие возникновение неэффективных решений и повышающих скорость проектирования. Модернизированы и реализованы новые механизмы генетических процедур кроссинговера, мутации, смены популяций. Разработан генетический алгоритм глобальной трассировки на базе новых структур хромосом и модифицированных генетических процедур. Проведены экспериментальные исследования генетического алгоритма глобальной трассировки. Определены оптимальные сочетания значений управляющих параметрами М, Т, Рм, Рк. Проведено сравнение с аналогом показавшее, что разработанный алгоритм позволяет сократить сроки проектирования на 10-40%.
Список литературы
J.Soukup. Fast wise router .Proceedings of 15th Design Automation Conference, pages 100-102 ,1972.
J.Heisterman and T.Lengauer .The efficient solution of integer programs for hierarchical global routing . IEEE Transactions on Computer-Aided Design, CAD 10(6): 748-753, Jane 1991.
C.Chang , M.Sarrafzadeh ,and C.K. Wong .A powerful global router :Based on sterner min-max trees .Proceedings of IEEE International Conference on Computer-Aided Design, pages 2-5 , November 7-10 1989.
S.Burman , H .Chen ,and N. Sherwani . Improved global routing using l- geometry .Proceedings of 29th Annual Allerton Conference on Communications , Computing , and Control .October 1991 .
J.M. Ho , G. Vijayan , and C. K . Wong . A new approach to the rectilinear Sterner tree problem . IEEE Transactions on Computer -Aided Design , 9(2): 185-193 , February 1985 .
Селютин В.А. Автоматизированное проектирование топологии БИС .-М.:Радио и связь , 1983,-112 с .C.Chiang, M.Sarrafradeh, C.K.Wong. A Weighted-Steiner-Tree-Based Global Router, Manuscript, 1992.