
Рефераты по рекламе
Рефераты по физике
Рефераты по философии
Рефераты по финансам
Рефераты по химии
Рефераты по хозяйственному праву
Рефераты по цифровым устройствам
Рефераты по экологическому праву
Рефераты по экономико-математическому моделированию
Рефераты по экономической географии
Рефераты по экономической теории
Рефераты по этике
Рефераты по юриспруденции
Рефераты по языковедению
Рефераты по юридическим наукам
Рефераты по истории
Рефераты по компьютерным наукам
Рефераты по медицинским наукам
Рефераты по финансовым наукам
Рефераты по управленческим наукам
Психология и педагогика
Промышленность производство
Биология и химия
Языкознание филология
Издательское дело и полиграфия
Рефераты по краеведению и этнографии
Рефераты по религии и мифологии
Рефераты по медицине
Рефераты по сексологии
Рефераты по информатике программированию
Краткое содержание произведений
Реферат: Билеты на государственный аттестационный экзамен по специальности Информационные Системы
Реферат: Билеты на государственный аттестационный экзамен по специальности Информационные Системы
1 Кибернетический подход к информационной системе как системе управления. Понятие кибернетической системы связано с процессами управления и переработки данных. Процесс управления рассматривается как процесс взаимодействия двух систем – управляющей и управляемой, в которой X – входные параметры о состоянии объектов управления, Y – выходные параметры, по которым судится о том, достигнута ли цель управления. Обратная связь – обеспечивает передачу данных в управляющую систему, по которым судят о рассогласовании цели и получаемых результатов.Управляющие или управленческие воздействия - среда. Процесс управления содержит следующие этапы:
Обязательным элементом любой системы управления является информационная система – это коммуникационная система сбора, передачи, переработки данных об объекте управления. Данная система снабжает работников различного уровня информацией для реализации функций управления. Информационные системы могут быть – прочными, автоматизированными и автоматическими. Данная классификация учитывает пропорции ведения данных между человеком и вычислительным устройством.
ВУ – вычислительное устройство
Если в системе есть человек, то система называется автоматизированной. ИС сама по определению является тоже системой управления. Определение ИС включает:
|
2 Трехзвенная архитектура информационных систем. Трехуровневая (распределенная) архитектура включает в себя сервер, приложения-клиенты, сервер приложений. Сервер приложений является промежуточным уровнем, обеспечивающим организацию взаимодействия клиентов и сервера, например выполнение соединения с сервером, разграничение доступа к данным и реализацию бизнес-правил. Сервер приложений реализует работу с клиентами, расположенными на различных платформах, т.е. функционирующими на компьютерах различных типов и под управлением различных ОС. Основные достоинства 3-х звенной архитектуры клиент-сервер:
Технологии программной реализации трехзвенной ИС в Delphi. Поскольку в трехзвенной архитектуре клиент и сервер приложений в общем случае располагается на разных машинах, связь клиента с сервером приложений реализуется с помощью той или иной технологии удаленного доступа: Модель DCOM позволяет использовать объекты, расположенные на другом компьютере. ОС Windows NT Server или Windows 2000 Server Сервер MTS (сервер транзакций Microsoft)- дополнения к технологии COM, и предназначенная для управления транзакциями. По сравнению с DCOM, MTS обеспечивает следующие дополнительные возможности:
Модель СОМ+ (усовершенствованная объектная модель компонентов) фирмы Microsoft введена в Windows2000 и интегрирует технологии MTS в стандартные службы COM. Сокеты TCP/IP (транспортный протокол/ протокол Интернета) используется для соединения компьютеров в различных сетях, в том числе в Интернете. CORBA (общедоступная архитектура с брокером- (сервер приложений) при запросе объекта) позволяет организовать взаимодействие между объектами, расположенными на различных платформах. SOAP ( простой протокол доступа к объектам) служит универсальным средством обеспечения взаимодействия с клиентами и серверами Web-служб на основе кодирования XML и передачи данных по протоколу HTTP. Главные особенности трехуровнего приложения связаны с созданием сервера приложений и клиентского приложения, а также с организацией взаимодействия между ними. Для разработки многоуровневых приложений в Delphi используются удаленные модули данных и компоненты, размещенные на странице DataSnap палитры компонентов. |
3 База данных как независимое хранилище данных и бизнес-правил. БД – это совокупность данных и описаний свойств этих данных, предназначенных для машинной обработки, которая служит для удовлетворения нужд многих пользователей. Проектирование БД – это процесс разработки структуры БД в соответствии с требованиями пользователя. Бизнес-процесс – это формализованное описание заданного набора управленческих процедур, включающее как выполняемые этим набором функции, так и используемые им данные и взаимоотношение, затрагиваемых им организационных подразделений и единиц. Бизнес-правила – это набор существующих правил, необходимых для организации бизнеса. Предметная область (ПО) – это часть реального мира, подлежащая автоматизации. (институт, завод и т. п.). Система управления базами данных (СУБД) – это обобщенный инструмент для манипулирования данными. База данных – это триединая концепция, которая включает: 1) совместно используемый механизм, предоставляющий общее хранилище взаимосвязанных и управляемых данных. 2) инструментальные средства поиска, анализа отображения данных. 3) обширная модель для представления состояния бизнеса, как в кратковременном, так и долговременном аспекте. Три этих аспекта – суть базы данных. Помимо основных концепций БД включает в себя определенную технологию (хранение, поиск, отображение данных). В БД существуют независимо друг от друга данные и бизнес-правила. Концептуальная стадия – первая в проекте: обзор требований и разработка общего проекта. В слое документов рассматриваются обширные потоки работ от офиса к офису, от службы к службе, от сотрудника к сотруднику. На уровне процессов выявляются термины, описывающие бизнес-правила, алгоритмы. Рассматривается высокоуровневая интегрированная основа модели предприятия, подразделения. Логическая стадия. Принимаем во внимание детальные правила бизнеса: разработка последовательности детализированных форм, необходимых для реализации задач; детализация процессов взаимодействия объектов. Разработка диаграмм "Запрос - действие". Разрабатывается высокоуровневая модель "сущность-связь", которая показывает потенциальную схему БД. В ней учитываются основные вопросы согласованности и содержательности БД. Физическая стадия. Проектируются формы, бизнес-правила описываются в виде программных кодов, БД нормализованы, упорядочены. При проектировании и реализации БД необходимо учитывать потенциальные требования пользователей, что актуально с первого этапа работы |
|
1 Краткосрочное прогнозирование. Доверительный интервал. Для осуществления прогноза на несколько шагов вперед достаточно взять очередные значения аргумента: t = n+ l,n + 2,..., n+i,... , где i = 1,2,... - номера шагов прогноза, и произвести экстраполяцию тренда
Получим
так называемые
точки прогноза
(точечный прогноз)
Исследования показали, что возможные расширения случайной зоны можно измерить с помощью специального коэффициента K(i), где i - номер шаг; прогноза. Такой коэффициент рассчитан дли наиболее популярных трендов . Линии тренда позволяют графически отображать тенденции данных и прогнозировать их дальнейшие изменения. Подобный анализ называется также регрессионным анализом (регрессионный анализ – форма статистического анализа, используемого для прогнозов; Регрессионный анализ позволяет оценить степень связи между переменными, предлагая механизм вычисления предполагаемого значения переменной из нескольких уже известных значений.). Используя регрессионный анализ, можно продлить линию тренда в диаграмме за пределы реальных данных для предсказания будущих значений. Скользящее среднее. Можно вычислить скользящее среднее (скользящее среднее – последовательность средних значений, вычисленных по частям рядов данных; На диаграмме линия, построенная по точкам скользящего среднего, позволяет построить сглаженную кривую, более ясно показывающую закономерность в развитии данных.), которое сглаживает отклонения в данных и более четко показывает форму линии тренда. Точность аппроксимации. Линия тренда в наибольшей степени приближается к представленной на диаграмме зависимости, если значение R-квадрат (значение R в квадрате – число от 0 до 1, которое отражает близость значений линии тренда к фактическим данным; линия тренда наиболее соответствует действительности, когда значение R в квадрате близко к 1; оно также называется квадратом смешанной корреляции) равно или близко к 1. При аппроксимации данных с помощью линии тренда в Microsoft Excel значение R-квадрат рассчитывается автоматически. ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ - вероятность, с которой можно утверждать, что ошибка выборки не превысит некоторую заданную величину, называют доверительной вероятностью. Обычно в социальных и маркетинговых исследованиях значения доверительной вероятности принимают равным 95%. Пределы, в которых с доверительной вероятностью может находиться значение характеристики генеральной совокупности, называют доверительным интервалом. |
2 Общая классификация компонентов языка программирования среды Delphi. Компонент – специальным образом оформленный программный код, который доступен разработчику на этапе проектирования: через кнопки быстрого доступа (палитры компонентов), или через список компонентов. Сам код располагается в специальным образом структурированных динамических библиотеках – пакетах. Необходимо различать: - Class – объектный тип Object Pascal. - Component – объектный тип (Class) Delphi. - Control – (элемент управления) – подмножество компонентов, которые, как правило, являются визуальными и соответствуют стандартам элементов управления Windows. Компоненты можно классифицировать по их отношению к OC Windows. К этой группе относятся все компоненты, которые инкапсулируют поведение основных элементов Windows (Standart, Addition, Win32). Альтернативная группа – компоненты разработанные пользователем. Визуальные, не визуальные компоненты. Графические элементы. Условно все описанные компоненты объединяют логическим понятием VCL. Tlist – список не потоковых данных, созданных через ссылочные типы. Tstring – универсальный список и как тип используется для многих свойств потоковых классов. Tcanvas, Tgraphic, Tgraphicobject, Tpicture – типы графической системы Tpersistent – наделяет своих потомков методами потоковых классов. Компоненты могут использовать комбинацию классов. графические элементы, которые не способны принять фокус ввода и используются для оформления. - оконные элементы, которые способны принять фокус ввода - Визуальные компоненты. Tcomponent – наделяет своих потомков основными свойствами:
|
3 Модели процессоров, их характеристики, динамика развития Центральный процессор (CPU, от англ. Central Processing Unit) — это основной рабочий компонент компьютера, который выполняет арифметические и логические операции, заданные программой, управляет вычислительным процессом и координирует работу всех устройств компьютера. Центральный процессор в общем случае содержит в себе: арифметико-логическое устройство; шины данных и шины адресов; регистры; счетчики команд; кэш — очень быструю память малого объема (от 8 до 512 Кбайт); математический сопроцессор чисел с плавающей точкой. Современные процессоры выполняются в виде микропроцессоров. Физически микропроцессор представляет собой интегральную схему — тонкую пластинку кристаллического кремния прямоугольной формы площадью всего несколько квадратных миллиметров, на которой размещены схемы, реализующие все функции процессора. Кристалл-пластинка обычно помещается в пластмассовый или керамический плоский корпус и соединяется золотыми проводками с металлическими штырьками, чтобы его можно было присоединить к системной плате компьютера. Наиболее известны модели Intel - 8088, 80286, 80386SX, 80386, 80486 и Pentium1-4, Athlon, Duron, Celeron, Cyrix, AMD . Одинаковые модели микропроцессоров могут иметь разную тактовую частоту - чем выше тактовая частота, тем выше производительность и цена микропроцессора. Тактовая частота - указывает, сколько элементарных операций (тактов) микропроцессор выполняет в одну секунду. Тактовая частота измеряется в мегагерцах (МГц). Чем выше модель микропроцессора, тем, как правило, меньше тактов требуется для выполнения одних и тех же операций. Процессоры развиваются в соответствии с законом Мура, согласно которому производительность процессоров удваивается каждые полтора-два года. Закон соблюдается с 1965 г., но в последнее время все чаще утверждают, что производительность процессоров стала возрастать быстрее. Основные направления совершенствования процессоров. Уменьшение размеров и увеличение плотности элементов. Увеличение разрядности. Параллельное исполнение команд. Развитие системы команд. Оптимизация кэш-памяти. Чем меньше размеры процессора, тем он быстрее, потому что меньше расстояние между элементами и электроны проходят его быстрее. Поэтому все время идут работы по разработке технологий более плотного размещения элементов в процессорах. Важным направлением совершенствования процессоров является повышение их разрядности. Разрядность процессора – это число двоичных разрядов, одновременно обрабатываемых при выполнении одной команды.Обработка большего числа разрядов может выполняться за несколько приемов. Разрядность определяет также величину информационной единицы обмена данными внутри ЭВМ. Чем больше разрядность процессора или канала обмена данными, тем обычно выше производительность компьютерной системы. Первые микропроцессоры были 4-разрядными, то есть за одной командой могли обрабатывать не более 4 двоичных разрядов. Для обработки более длинных чисел нужно было применять несколько команд. Первые массово производимые ПК в конце 70х гг. использовали 8-разрядные МП. Первые ПК фирмы IBM использовали 16-разрядные МП. Начиная с МП Intel 80386, МП стали полностью 32-разрядными, но для совместимости с программами, разработанными для младших моделей МП содержали набор 16-разрядных команд. Нынешние процессоры фирмы Intel уже частично 64-разрядные, то есть имеют команды, рассчитанные на работу с 64-разрядными данными. Адресное пространство – максимальный объем памяти, доступный процессору. Параллельное исполнение команд основано на том, что каждая команда исполняется процессором за несколько внутренних циклов работы. Поэтому когда исполнение одной команды переходит к следующему циклу, процессор одновременно может начать обрабатывать другую команду. За счет организации конвейера команд скорость работы процессора намного возрастает. Развитие системы команд предполагает, что в процессоры встраиваются дополнительные команды, реализующие сложные действия по обработке данных. Например, в процессорах Pentium III-IV, AMD Athlon имеются команды, выполняющие очень сложные действия по обработке звуковых или видеоданных, для реализации которых в предшествующих моделях процессоров нужно было создавать программу, включающую несколько десятков или сотен машинных команд. Кэш-память – быстродействующая память, предназначенная для ускорения доступа к данным, размещенным в памяти, обладающей меньшим быстродействием. В процессорах кэш-память используется для ускорения доступа к данным, размещенным в ОЗУ. С каждым новым поколением процессоров кэш-память увеличивается. Обычно в процессорах используется кэш-память первого и второго уровня. Кэш-память первого уровня имеет меньший объем, чем кэш-память второго уровня, но она размещается непосредственно в процессоре и потому намного быстрее. Различия между процессорами Pentium II-III-IV и Celeron состоит, главным образом, в том, что у первых размеры кэш-памяти существенно больше. Следует иметь ввиду, что процессоры AMD и Intel требуют использования разных материнских плат, поскольку устанавливаются на нее через разъемы разного типа. |
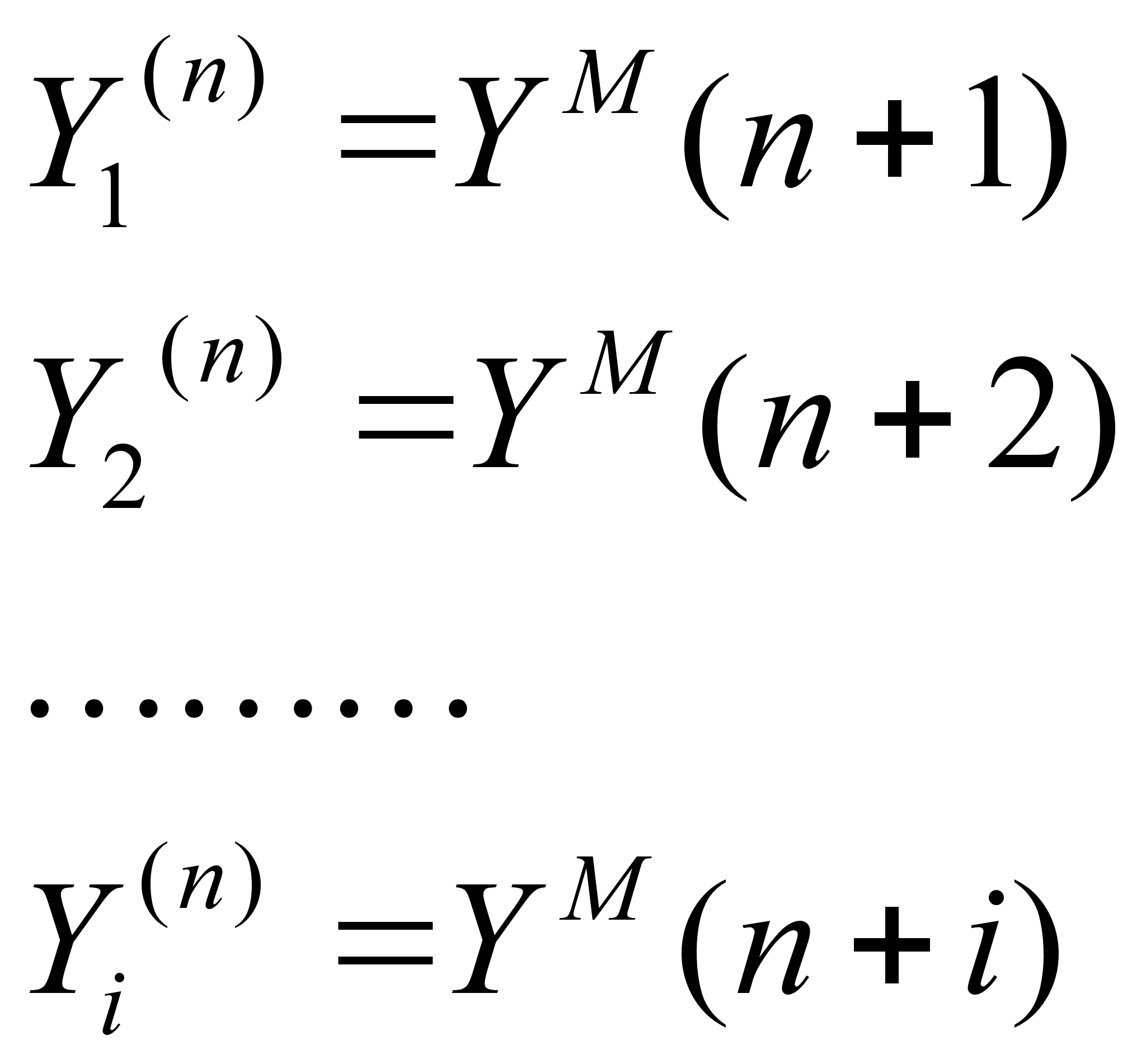
|
1 Статистические методы моделирования (метод Монте-Карло). По способам отражения фактора времени модели делятся на статистические и динамические. В статистических моделях все зависимости относятся к одному моменту или периоду времени. Динамические модели характеризуют изменения экономических процессов во времени. Метод Монте-Карло (метод статистических испытаний) – численный метод решения математических задач при помощи моделирования случайных чисел. Суть метода: посредством специальной программы на ЭВМ вырабатывается последовательность псевдослучайных чисел с равномерным законом распределения от 0 до1. Затем данные числа с помощью специальных программ преобразуются в числа, распределенные по закону Эрланга, Пуассона, Релея и т.д. Полученные таким образом случайные числа используются в качестве входных параметров экономических систем. При многократном моделировании случайных чисел определяем математическое ожидание функции и, при достижении средним значением функции уравнения не ниже заданного, прекращаем моделирование. Статистические испытания (метод Монте-Карло) характеризуются основными параметрами: - заданная точность моделирования; P – вероятность достижения заданной точности; N – количество необходимых испытаний для получения заданной точности с заданной вероятностью. Определим необходимое число реализаций N, тогда (1 - ) будет вероятность того, что при одном испытании результат не достигает заданной точности ; (1 - ) N – вероятность того, что при N испытаниях мы не получим заданной точности . Тогда вероятность получения заданной точности при N испытаниях можно найти по формуле
Формула (19) позволяет определить заданное число испытаний для достижения заданной точности с заданной вероятностью Р.Случайные числа получаются в ЭВМ с помощью специальных математических программ или спомощью физических датчиков. Одним из принципов получения случайных чисел является алгоритм Неймана, когда из одного случайного числа последовательно выбирается середина квадрата. Кроме того данные числа проверяются на случайность и полученные числа заносятся в базу данных. Физические датчики разрабатываются на электронных схемах и представляют собой генераторы белого (нормального) шума, то есть когда в спектральном составе шума имеются гармоничные составляющие с частотой F . Из данного белого шума методом преобразования получаются случайные числа. |
2 СОМ – технология. Понятие интерфейса СОМ объекта. СОМ – технология. В технологии СОМ приложение предоставляет для использования свои службы, применяя для этого объекты СОМ. Одно приложение содержит как минимум один объект. Каждый объект имеет один или несколько интерфейсов. Каждый интерфейс объединяет методы объекта, которые обеспечивают доступ к свойствам (данным) и выполнение операций. Обычно в интерфейсе объединяются все методы, выполняющие операции одного типа или работающие с однородными свойствами Клиент получает доступ к службам объекта только через интерфейс и его методы. Этот механизм является ключевым. Клиенту достаточно знать несколько базовых интерфейсов, чтобы получить исчерпывающую информацию о составе свойств и методов объекта. Поэтому любой клиент может работать с любым объектом, независимо от их среды разработки. Согласно спецификации СОМ, уже созданный интерфейс не может быть изменен ни при каких обстоятельствах. Это гарантирует постоянную работоспособность приложений на основе СОМ, невзирая на любые модернизации. Объект всегда работает в составе сервера СОМ. Сервер может быть динамической библиотекой или исполняемым файлом. Объект может иметь собственные свойства и методы или использовать данные и службы сервера. Для доступа к методам объекта клиент должен получить указатель на соответствующий интерфейс. Для каждого интерфейса существует собственный указатель. После этого клиент может использовать службы объекта, просто вызывая его методы. Доступ к свойствам объектов осуществляется только через его методы. Предположим, что объект СОМ встроен в электронную таблицу и обеспечивает доступ к математическим операциям. Будет логично разделить математические функции на группы по типам и создать для каждой группы собственный интерфейс. Взаимодействие между клиентом и объектом обеспечивается базовыми механизмами СОМ. При этом от клиента скрыто, где именно расположен объект: в адресном пространстве того же процесса, в'другом процессе или на другом компьютере. Поэтому с точки зрения разработчика клиентского ПО использование функций электронной таблицы выглядит как обычное обращение к методу объекта. Механизм обеспечения взаимодействия между удаленными элементами СОМ называется маршалингом (marshalling). Сначала клиент обращается к библиотеке СОМ, передавая ей имя требуемого класса и необходимого в первую очередь интерфейса. Библиотека находит нужный класс и сначала запускает сервер, который затем создает объект — экземпляр класса. После этого библиотека возвращает клиенту указатели на объект и интерфейс. В последующей работе клиент может обращаться непосредственно к объекту и его интерфейсам. После создания наступает очередь инициализации — объект должен загрузить необходимые данные, считать настройки из системного реестра и т. д. За это отвечают специальные объекты СОМ, которые называются моникерами (monikers). Они работают скрытно от клиента. Обычно моникер создается вместе с классом. Довольно реальной представляется ситуация, когда одновременно несколько клиентов обращаются к одному объекту. При соответствующих настройках для каждого клиента создается отдельный экземпляр класса. За выполнение этой операции отвечает специальный объект СОМ, который называется фабрикой класса. Понятие интерфейса СОМ объектаИнтерфейс является средством, которое позволяет клиенту правильно обратиться к объекту СОМ, а объекту ответить так, чтобы клиент его понял. Для идентификации каждый интерфейс имеет два атрибута. Во-первых, это его имя, составленное из символов в соответствии с правилами используемого языка программирования. Каждое имя должно начинаться с символа "I". Это имя используется в программном коде. Во-вторых, это глобальный уникальный идентификатор (Globally Unique IDentifier, GUID), который представляет собой гарантированно уникальное сочетание символов, практически не повторяемое ни на одном компьютере в мире. Для интерфейсов такой идентификатор носит название IID (Interface Identifier). В СОМ описана реализация интерфейса на основе стандартного двоичного формата. Это обеспечивает независимость от языка программирования. Каждый объект СОМ обязательно имеет интерфейс lUnknown. Этот интерфейс имеет всего три метода, но они играют ключевую роль в функционировании объекта. Метод Queryinterface возвращает указатель на интерфейс объекта, идентификатор IID которого передается в параметре метода. Если такого интерфейса объект не имеет, метод возвращает Null. Интерфейс IUnknown обеспечивает работу еще одного важного механизма объекта СОМ — механизма учета ссылок. Объект должен существовать до тех пор, пока его использует хотя бы один клиент. При этом клиент не может самостоятельно уничтожить объект, ведь с ним могут работать и другие клиенты. Поэтому при передаче наружу очередного указателя на интерфейс, объект увеличивает специальный счетчик ссылок на единицу. Если один клиент передает другому указатель на интерфейс этого объекта, то клиент, получающий указатель, обязан еще раз инкрементировать счетчик ссылок. Для этого используется метод AddRef интерфейса lunknown. При завершении работы с интерфейсом клиент обязан вызвать метод Release интерфейса lunknown. Этот метод уменьшает счетчик ссылок на единицу. После обнуления счетчика объект уничтожает себя. |
3 Хараткристика принципа кэширования памяти: назначение и определение буфера и буферизации данных и команд. Кэш-память (Cache Memory) – это сверхоперативная память, отличающаяся высоким быстродействием, являющаяся буфером между процессором и RAM. Назначение кэш-памяти – сократить время ожидания процессора при обращении к относительно медленной памяти на микросхемах DRAM (сократить значение параметра Wait State). Кэш хранит копии блоков RAM (ОЗУ), к которым происходили последние обращения. В случае последующего обращения к этим блокам информация берется непосредственно из кэш-памяти. Кэш-память реализуется на микросхемах SRAM, характеризуемых временем доступа порядка 5-20 нс. Но т.к. статическая память построена, как и процессор, на триггерных ячейках, эти микросхемы дороги и ограничены по информационной емкости (до 512 Кбайт). Компромиссом для построения экономичных и производительных систем явился иерархический способ построения оперативной памяти, пришедший в архитектуру PC с появлением процессора 386. Идея этого способа заключается в сочетании основной памяти большого объема на DRAM с относительно небольшой кэш-памятью на быстродействующих микросхемах SRAM. В современных ПК кэш-память организуется по двухуровневому принципу. Внешняя кэш-память (L2 Cache – Level 2 Cache – кэш второго уровня) размещается на материнской плате (исключением является ПК на базе Pentium Pro, где синхронный L2 Cache интегрирован в одном корпусе с процессором). Внешний кэш строится на микросхемах SRAM и берет свое начало от материнской платы с процессором i80386, где он был единственным уровнем кэш-памяти. В современных ПК он может иметь объем до 2 Мбайт.Внутренняя кэш-память (L1 Cache – Level 1 Cache – кэш первого уровня) находится в составе процессора (начиная с i80486 и некоторых моделей i80386) и может иметь емкость 8, 16, 32 Кбайт. Ее назначение – согласовать по скорости работу процессора и внешней кэш-памяти Существуют два основных алгоритма записи данных из кэша в основную память: 1.Алгоритм сквозная запись WT – обеспечивает выполнение каждой операции записи (даже однобайтной), попадающей в кэшированный блок, одновременно и в строку кэша, и в основную память. При этом процессору при каждой операции записи придется ожидать окончания относительно длительной записи в основную память. Алгоритм достаточно прост в реализации и легко обеспечивает целостность данных за счет постоянного совпадения копий данных в кэше и основной памяти. 2. Алгоритм обратная запись WB позволяет уменьшить количество операций записи на шине основной памяти. Если блок памяти, в который должна производиться запись, отображен и в кэше, то физическая запись сначала будет произведена в эту действительную строку кэша, и она будет отмечена как грязная (dirty), или модифицированная, то есть требующая выгрузки в основную память. Только после этой выгрузки (записи в основную память) строка станет чистой (clean), и ее можно будет использовать для кэширования других блоков без потери целостности данных. В основную память данные переписываются только целой строкой или непосредственно перед ее замещением в кэше новыми данными. Данный алгоритм сложнее в реализации, но существенно эффективнее, чем WT. В зависимости от способа определения взаимного соответствия строки кэша и области основной памяти различают три архитектуры кэш-памяти: кэш прямого отображения (direct-mapped cache), полностью ассоциативный кэш (fully associative cache) и их комбинация — частично- или наборно-ассоциативный кэш (set-associative cache). 1. кэш прямого отображения – адрес памяти, по которому происходит обращение, однозначно определяет строку кэша, в которой может находиться требуемый блок. Память тегов должна иметь количество ячеек, = кол-ву строк кэша, а ее разрядность - достаточной, чтобы вместить старшие биты адреса кэшированной памяти. 2. полностью ассоциативный кэш – любая строка памяти может отображать любой блок памяти. Это увеличивает эффективность работы кэша. Все биты адреса кэшированного блока хранятся в памяти тега. 3. наборно-ассоциативный кэш – каждый блок кэшируемой памяти может претендовать на одну из нескольких строк кэша, объединенных в набор. Контроллер кэша принимает решение, в какую из строк набора поместить очередной блок данных. Для управления кэшированием на аппаратном уровне введены регистры, которые выполняют аппаратное управление кэшированием, и управление изменением порядка записи для определения областей памяти. С помощью этих регистров физической памяти может быть определено образование адресов с одинаковыми битами кэширования. Такое распределение позволяет оптимизировать операции с ОЗУ и с видеопамятью, с постоянной памятью и с адаптерами ввода-вывода. |
|
1 Парадигма системы. Понятие системы и ее элементов. Система – это средство достижения цели, однако, соответствие цели и системы неоднозначно (в чём-то разные системы могут быть ориентированы на 1 цель, либо 1 система может иметь несколько разных целей). Парадигма системы С позиции общей теории систем можно выделить инженерный подход определения системы как совокупности элементов и взаимосвязей (отношений между элементами), обеспечивающих достижение поставленной цели. Элементы + Связь = Цель С позиции конструкт вида деятельности система – это совокупность методов и средств, обеспечивающих разработку и выполнение конкретной задачи. Необходимыми условиями наличия системы являются:
Система – это отображение на множество языка наблюдателя множества свойств объекта, а также отношение между этими свойствами с позиции решения поставленной задачи. S n L ( l, r ) P S - система; n - наблюдатель; L – язык; - отображение; ( l, r ) – множество подобъектов; P – цель. По сути отображения определяют 3 вида систем:
По замкнутости объекта могут быть:
Понятие системы и ее элементов При рассмотрении любой системы прежде всего обнаруживается то, что её целостность и обособленность, отображённые в модели черного ящика, выступают как внешние свойства, внутренность же ящика оказывается неоднородной, что позволяет различать составные элементы системы, которые при более детальном рассмотрении могут быть в свою очередь разбиты на составные части. Те части системы, которые мы рассматриваем как неделимые, будем называть элементами. Элемент – это предел членения системы с точки зрения аспекта рассмотрения системы, которая решает конкретную задачу. Сложные системы принято вначале делить на подсистемы, а если эти системы также трудно поделить, то составляющие промежуточных уровней называют компонентами системы. Части системы, состоящие более, чем из 1 элемента, называют подсистемами. В результате получается модель состава системы, описывающая из каких элементов и подсистем она состоит. Модель состава ограничивается снизу тем, что называется «элемент», а сверху – границей системы. Как эта система, так и границы разбиения на подсистемы определяются целями построения системы. Понятие «связь» входит в любое определение системы и обеспечивает возникновение и сохранение целостных её свойств. Связь – это ограничение степени свободы элемента. Элемент, вступая в связь с другим, утрачивает часть своих свойств, которыми они потенциально обладали в свободном состоянии. Переменные системы, параметры, входы и выходы Перейдём от 1-го определения системы (система – это средство достижения цели, однако, соответствие цели и системы неоднозначно - в чём-то разные системы могут быть ориентированы на 1 цель, либо 1 система может иметь несколько разных целей) к её визуальному эквиваленту.
В определении системы косвенно говорится о том, что хотя ящик и обособлен, выделен из среды, он полностью не изолирован. Система связана со средой с помощью выходов системы. Выходы системы в данной графической модели соответствуют слову цель в словесной модели системы. В определении имеется указание и на наличие связей другого типа. Система является средством, поэтому должны существовать и возможности её использования, воздействия на неё, то есть и такие связи со средой, которые направлены извне в систему – это входы системы. Очень важную роль играет понятие «обратной» связи. Обратная связь может быть положительной, то есть сохраняющей тенденции происходящих в системе изменений того или иного выходного параметра, и отрицательной, то есть противодействующей этой тенденции, или направленной на сохранение параметра. Переменные системы – величины, которые характеризуют любой элемент или совокупность элементов системы, и может принимать значения на определённом для неё множестве значений в соответствии с выбранным языком. Параметры системы - те переменные системы, значение которых является неизменным при решении задач. |
2 Технология Automation. Интерфейсы диспетчеризации. OLE (Automation) – объект автоматизации который представляет собой определённый внутри приложения экземпляр класса, который помощи интерфейсов автоматизации предоставляет свое свойства и методы другим приложениям и инструментальным средствам программирования.
COM Automation IUnKnow IDispatch Приложения или инструментальные средства программирования, которые имеют доступ к управлению программными объектами, содержатся в сервере автоматизации, называются контроллерами автоматизации диспетчерами. Управление программными проектами осуществляется с помощью специального языка программирования серверов автоматизации, который в общем случае не совпадает с языком программирования приложений. Idispatch – интерфейс диспетчеризации. Основная функция Invoke. Function Invoke (DispId: integer; Const Iid: TGId; Locale ID: integer; Flags: word; var params; var Result, ExceptInfo, ArgErr: Point):Integer; ,где DispId – число, которое называется идентификатором диспетчера, указывающий какой именно метод должен использовать сервер. LocaleId – локальный Id. Flags – признак как вызывается метод. Метод доступа к свойству или метод действия. Params – указатель на массив TdispParams который хранит параметры вызова метода. VarResult – указатель на область OLEVariant в которой размещаются возвращаемые методам данные. Exceptinfo – указатель на запись с информацией о возникшей исключительной ситуации, если метод возвращает DispEException. ArgErr – указатель на число, равно порядковому номеру параметра в вызове при обработке которого возникло исключение. |
3 Задача линейного и нелинейного программирования. Уравнение регрессии – ур-ие, связывающее между собой фактор признаки и результативные признаки. Ур-ие регрессии бывают линейные и нелинейные. Сама регрессия бывает парная (зависимость между 1-им фактор признаком и результатом) и множественная. y = y(x) (1) (з. между 1-им ф. признаком и рез-ом) y = a + bx (2)(парная линейная регрессия, т.к. х и у участвуют в 1-ой степени, а и b – параметры регрессии имеющие экономический смысл). Чтобы учесть возникающие помехи (погрешности в уравнении (2)) обычно пишут: у = a + bx + e, где e – искажение модели, учитывающее ряд других фактор признаков не явно участвующих в процессе. Существуют и другого вида регрессии:
Нелинейные задачи математического программирования. Постановка задачи. Найти такой план X=(x1, x2, ..., xn), при котором функция f=f(x1, x2, ..., xn) достигает максимума (минимума) при условии, что переменные x1, x2, ..., xn удовлетворяют дополнительным условиям g1(x1, x2, ..., xn)=0, ... , gn(x1, x2, ..., xn)=0. В математическом анализе такая задача, называется задачей на условный экстремум. Она сводится к построению функции Лагранжа F=f(x1, x2, ..., xn)+1g1+2g2+...+mgm, где 1, 2, ..., m – множители Лагранжа. С помощью функции Лагранжа задача на поиск условного экстремума для функции сводится к задаче на поиск безусловного экстремума для функции F. В этом случае вместе с переменными x*1, x*2, ..., x*n доставляющими оптимальное решение всей задачи отыскиваются оптимальные коэффициенты *1, *2, ..., *m, которые определяют оптимальные (теневые) цены (оценки) ограничений. В Microsoft Excel такие задачи решаются с помощью программы Поиск решения. В диалоговом окне Поиск решения после нажатия кнопки Параметры активизируется либо метод Ньютона, либо градиентный метод. Запись функции цели, диапазона искомых переменных и ограничений производится аналогично использованию симплексного метода в категории Линейные задачи (см. предыдущие лабораторные работы). Определение оптимальных значений *1, *2, ..., *m множителей Лагранжа находится параллельно с нахождением оптимальных значений x*1, x*2, ..., x*n плана задачи, и выдается одновременно по окончании решения задачи в отчете по устойчивости. Общая задача нелинейного интервального программирования имеет вид
с
нелинейными
детерминированными
нижними и верхними
граничными
функциями.
Для решения
задач надо
уметь сравнивать
интервальные
значения ее
целевой функции
Когда целевая (производственная) функция и ограничения нелинейные и для поиска точки экстремума нельзя или очень сложно использовать аналитические методы решения, тогда для решения задач оптимизации применяются методы нелинейного программирования. Как правило, при решении задач методами нелинейного программирования используются численные методы с применением ЭВМ. В основном методы нелинейного программирования могут быть охарактеризованы как многошаговые методы или методы последующего улучшения исходного решения. В этих задачах обычно заранее нельзя сказать, какое число шагов гарантирует нахождение оптимального значения с заданной степенью точности. Кроме того, в задачах нелинейного программирования выбор величины шага представляет серьезную проблему, от успешного решения которой во многом зависит эффективность применения того или иного метода. Разнообразие методов решения задач нелинейного программирования как раз и объясняется стремлением найти оптимальное решение за наименьшее число шагов. Большинство методов нелинейного программирования используют идею движения в n-мерном пространстве в направлении оптимума. Линейное программирование (эффективность производства) |
|
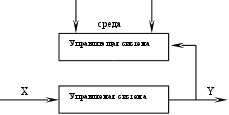
1 Декомпозиция системы на управляющую и управляемую системы. Понятие кибернетической системы связано с процессами управления и переработки данных. Процесс управления рассматривается как процесс взаимодействия двух систем – управляющей и управляемой, в которой X – входные параметры о состоянии объектов управления, Y – выходные параметры, по которым судится о том, достигнута ли цель управления. Обратная связь – обеспечивает передачу данных в управляющую систему, по которым судят о рассогласовании цели и получаемых результатов. Управляющие или управленческие воздействия - среда. Управление Информация
Процесс управления содержит следующие этапы:
Управление – это целенаправленное информационное воздействие одной системы на другую, стремящейся изменить состояние последней в соответствии с выбранными критериями эффективности функционирования. (пример ИС – управление предприятием). Основные направления совершенствования систем управления:
Обязательным элементом любой системы управления является информационная система – это коммуникационная система сбора, передачи, переработки данных об объекте управления. Данная система снабжает работников различного уровня информацией для реализации функций управления. Определение ИС включает: структуру системы, как множество элементов и взаимоотношения, состав, описание функций, описание входов и выходов, как для системы в целом, так и для каждого элемента; цели, ограничения и критерии; архитектура системы |
2 Двойственная задача линейного программирования. Анализ эффективности производства основан на принципе двойственности линейного программирования. Двойственность в линейном программировании имеет несколько аспектов: - измерительный аспект; - принцип предельного компромисса; - принцип дефицитности; - глобальный экономический аспект. Все аспекты двойственности связаны с производственной оценкой ресурсов, т.е. с получением теневых цен ресурсов при различных состояниях производства. Можно установить прямую зависимость между уровнем эффективности производства и значением теневых цен ресурсов. Задача, двойственная к исходной, строится следующим образом: 1) Исходная задача – на минимум, следовательно, двойственная задача – на максимум. 2) Матрица коэффициентов системы ограничений будет представлять собой транспонированную матрицу соответствующих коэффициентов исходной задачи. При этом все ограничения должны быть одного типа, например "больше или равно". 3)
Число переменных
в двойственной
задаче равно
числу ограничений
в исходной
задаче, и наоборот,
число ограничений
в двойственной
задаче равно
числу переменных
в исходной.
Переменная
4)
Коэффициентами
при переменных
а правыми
частями ограничений
двойственной
задачи являются
коэффициенты
целевой функции
исходной задачи,
т.е. вектор
5) Если все
переменные
исходной задачи
неотрицательны,
то все ограничения
двойственной
задачи будут
неравенствами
типа « |
3 Средства синхронизации потоков: события, взаимные исключения, критические секции, семафоры. Синхронизация – если создаваемый поток не взаимодействует с ресурсами других потоков и не обращается к VCL. Главные понятия для понимания механизмов синхронизации – функции ожидания и объекты синхронизации. Ряд функций, позволяющих приостановить выполнение вызвавшего эту функцию потока вплоть до того момента, как будет изменено состояние какого-то объекта, называемого объектом ожидания. Событие – объект типа событие - простейший выбор для задач синхронизации. Он подобен дверному звонку –звенит до тех пор, пока его кнопка находится в нажатом состоянии, извещая об этом факте окружающих. Аналогично, и объект может, находится в 2х состояниях, а «слышать» его могут многие потоки сразу. Класс TEvent имеет 2 метода переводящих объект в активное и пассивное состояние (Set Event и Reset Event). Взаимные исключения - позволяет только одному потоку в данное время владеть им. Если продолжать аналогии, то этот объект можно сравнить с эстафетной палочкой. Программист может использовать взаимное исключение, чтобы избежать считывания и записи общей памяти несколькими потоками одновременно. Критические секции(область глобальной памяти, кторая требует защиты при обращении к нему нескольких потоков одновременно, может выполняться в рамках одного потока, все остальные блокируются.)– подобны взаимным исключениям по сути, однако, между ними существуют 2 главных отличия:
Критические секции, более эффективны, чем взаимные исключения, так как используют меньше системных ресурсов. И являются системными объектами и подлежат обязательному освобождению. Семафор – подобен взаимному исключению. Разница между ними в том, что семафор может управлять количеством потоков, которые имеют к нему доступ. Семафор устанавливается на предельное число потоков, которым доступ разрешен. Когда это число достигнуто, последующие потоки будут приостановлены, пока один или более потоков не отсоединятся от семафора и не освободят доступ. Основные методы управления:
Constructor create – получает параметр creat Suspended , если его зн=true, то вновь созданный поток не выполняется дотех пор, пока не будет сделан вызов метода Resume. Если false конструктор завершается и только затем поток начинает исполнение. |
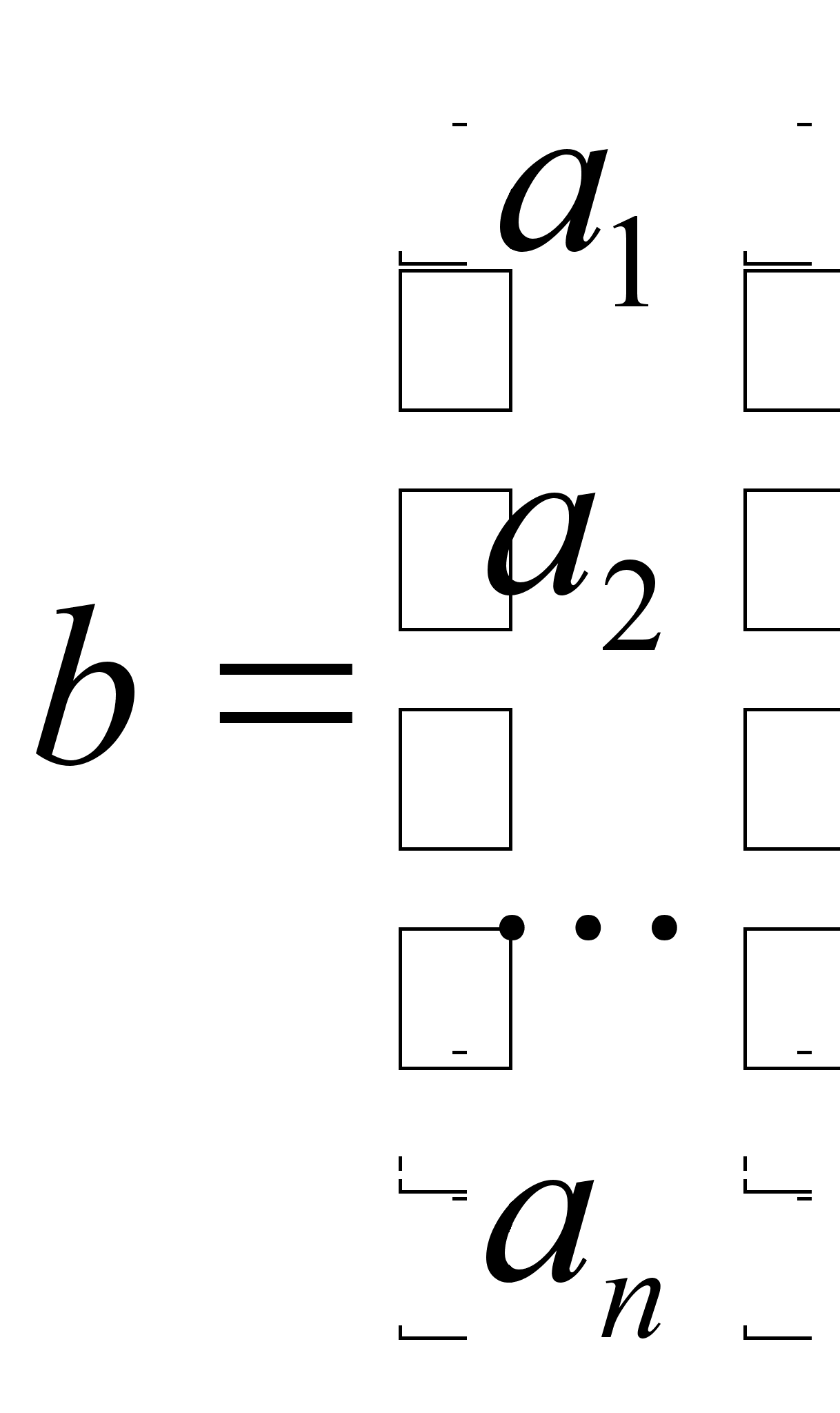
|
1 Теория функциональных зависимостей. Тривиальные и нетривиальные зависимости. Формальное определение функциональной зависимости: Даны атрибуты X и Y, атрибут Y функционально зависит от X, если в каждый момент времени каждому значению X соответствует одно и то же значение Y. (X -> Y) Для каждого отношения существует вполне определенное множество функциональных зависимостей между атрибутами. Аксиомы ФЗ позволяют из одной ФЗ вывести другие также присущие данному отношению. Аксиомы:
Каждое из этих трех правил может быть непосредственно доказано на основе определения ФЗ (первое из них – просто определение тривиальной зависимости). Типы функциональных зависимостей:
Функциональная зависимость XY называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости XZ и ZY и отсутствует функциональная зависимость ZX. Зависимость называется тривиальной, если она не может не выполняться. Зависимость является тривиальной тогда и только тогда, когда правая часть ее правой записи является подмножеством левой части. ( S#, P#) -> S#. Нетривиальные зависимости являются реальными ограничениями целостности. |
2 Характеристика механизма прерываний: определение и обработка прерываний, система прерываний, обслуживание прерываний, программные и аппаратные прерывания. Прерыванием называется временное прекращение выполнения текущей программы, которое вызвал внешний сигнал. Микропроцессор при этом переходит к выполнению специальной подпрограммы обработки прерывания. Использование прерываний позволяет сократить время реакции ЭВМ на внешнее событие и увеличить гибкость ее работы, особенно это проявляется в случаях, когда требуется обеспечить обмен информации с большим числом асинхронно работающих внешних устройств. Существуют два способа организации прерываний от нескольких источников:
Часто требуется иметь возможность игнорировать запросы на прерывание - маскировать их, например, когда запрос на прерывание может приходить одновременно от нескольких источников, необходимо устанавливать приоритеты прерываний и обеспечивать маскирование прерываний с низшим приоритетом. Семейство микропроцессоров Intel 80x86 поддерживает 256 уровней приоритетных прерываний, вызываемых событиями трех типов:
Внутренние аппаратные прерывания, иногда называемые отказами (faults), генерируются определенными событиями, возникающими в процессе выполнения программы, например попыткой деления на нуль. Закрепление за такими событиями опреденных номеров прерываний зашито в процессоре и не может быть изменено. Внешние аппаратные прерывания инициируются контроллерами периферийного оборудования или сопроцессорами (например, 8087/80287). Источники сигналов прерываний подключаются либо к выводу немаскируемых прерываний процессора (NMI) либо к выводу маскируемых прерываний (INTR). Линия NMI обычно предназначает для прерываний, вызываемых катастрофическими событиями, такими, как ошибки четности памяти или авария питания. Вместо непосредственного подключения к ЦП прерывания от внешних устройств могут поступать в процессор через специальное устройство - программируемый контроллер прерываний (РIС) 8259А. ЦП управляет контроллером через набор портов ввода-вывода, а контроллер в свою очередь сигнализирует процессору через вывод INTR. РIС предоставляет возможность программно разрешать и запрещать прерывания от конкретных устройств, а также назначать им приоритеты. Программные прерывания. Любая программа может инициировать синхронное программное прерывание просто путем выполнения команды INT. MS-DOS использует для взаимодействия со своими модулями и прикладными программами прерывания от 20Н до 3FH. Программы BIOS, хранящиеся в ПЗУ, и прикладные программы IBM PC используют другие прерывания, с большими или меньшими номерами. Это распределение номеров прерываний условно и никаким образом не закреплено аппаратно. Обслуживание прерываний. ЦП, обнаружив сигнал прерывания, помещает в машинный стек слово состояния программы (определяющее различные флаги ЦП), регистр программного сегмента (CS) и указатель команд (IP) и блокирует систему прерываний. Затем ЦП с помощью 8-разрядного числа, установленного на системной магистрали прерывающим устройством, извлекает из таблицы векторов адрес обработчика и возобновляет выполнение с этого адреса. Состояние системы в момент передачи управления обработчику прерываний совершенно не зависит от того, было ли прерывание возбуждено внешним устройством или явилось результатом выполнения программой команды INT. Это обстоятельство удобно использовать при написании и тестировании обработчиков внешних прерываний, отладку которых можно почти полностью выполнить, возбуждая их простыми программными средствами. |
3 Многопоточные приложения. Процессы и потоки. Использование многопоточного приложения оправдано:
Замечание.
Потоки – это наборы команд, которые могут получать время процессора. Время процессора выделяется квантами. Квант времени – это минимальный интервал, в течение которого только один поток использует процессор. Кванты выделяются не программам или процессам, а именно порожденным потокам. Как минимум, каждый процесс имеет хотя бы один (главный) поток, но операционные системы, начиная с Windows 95 и Windows NT позволяют запустить в рамках процесса произвольное число потоков. Потоки дают современному программному обеспечению новые специфические возможности. К примеру, пакеты из состава MS Office задействуют по несколько потоков. Word может одновременно корректировать грамматику и печатать, при этом осуществляя ввод данных с клавиатуры и мыши; программа Excel способна выполнять фоновые вычисления и печатать. Потоки упрощают жизнь тем программистам, которые разрабатывают приложения в архитектуре клиент/сервер. Когда требуется обслуживание нового клиента, сервер может запустить специально для этого отдельный поток. Также потоки – основная единица диспетчеризации вычисляемого процесса. Процесс состоит из виртуальной памяти, исполняемого кода, потоков и данных. Процесс может содержать много потоков, но обязательно содержит, по крайней мере, один. Поток зависит от процесса, который и распоряжается виртуальной памятью, кодом, данными, файлами и другими ресурсами ОС. Переключение между процессами – значительно более длительная операция, чем переключение между потоками, поэтому мы используем потоки вместо процессов.Типичные ошибки при использовании потоков.
|
1 Объекты математического моделирования.В книге Р.Абдеева «Философия информационной цивилизации» названы главные стороны прогресса- самоорганизация материи и нелинейность процессов, где главным объектом исследования названа открытая самоорганизующая система, как первичная элементарная структура материи. Будем считать объектом математического моделирования такую систему. Объектом математического моделирования кроме системы могут быть ее фрагменты и простейшие ее элементы. (все, что поддается счету, измерению, группировке, сравнению т.е. это все то, что имеет форму и суть меры). Все что создано в математике можно рассматривать либо как объект, либо как инструмент моделирования. Под математической моделью данного объекта можно понимать математическую структуру, являющуюся результатом идентификации и снабженную правилами дальнейшей идентификации и интерпретации ее компонентов Рассмотрим два случая: 1) система имеет простейший замкнутый контур (А,В,С,Д,Е) с обратной связью (ОС), с обычным регулятором, реагирующим лишь на текущее взаимодействие. Цель системы – самосохранение. 2) система имеет сложный контур, состоящий из первичного контура ОС и вторичного контура ОС (А,В, F,G,C,D,E). Во втором контуре осуществляется отбор полезной информации из первого контура. Эта информация накапливается, формируя опыт, знания, синтезируется в определенные структуры, повышая уровень организации, активность и живучесть системы. Цель системы – самоорганизация и саморазвитие. Две характеристики системы: цель и отклонение реакция на внешнее воздействие. При математическом моделировании цель системы выделяется и измеряется вместе с параметрами системы, те переменные системы, значение которых является неизменным при решении задач. При математическом моделировании цель системы выделяется и измеряется вместе с параметрами системы, которые чаще всего заданы в виде отклонений от параметров среднего состояния системы. Значения параметров могут измеряться и иными способами, всё зависит от точки отсчёта измерений и от единиц измерения. Которые чаще всего заданы в виде отклонений от параметров среднего состояния системы. Значения параметров могут изменятся и иными способами, все зависит от точки отсчета измерений и от единицы измерения. Объектом математического моделирования кроме системы могут быть ее фрагменты и простейшие ее элементы. (все, что поддается счету, измерению, группировке, сравнению т.е. это все то, что имеет форму и суть меры). Все что создано в математике можно рассматривать либо как объект, либо как инструмент моделирования. Под математической моделью данного объекта можно понимать математическую структуру, являющуюся результатом идентификации и снабженную правилами дальнейшей идентификации и интерпретации ее компонентов. Математическая модель реализует тот или иной измерительный способ совокупной исходной информации, измерительным инструментом которого является сама математическая модель. |
2 Технология OLE DB. Стандарт ADO.Концепция открытых систем, положенная в основу архитектуры среды разработки, обеспечивает реализацию наиболее распространенных механизмов доступа к данным (Universal Data Access, UDA), к которым относятся: стандарт Microsoft Open DataBase Connectivity, ODBC; низкоуровневый интерфейс доступа к данным OLE DB; интерфейс прикладного программирования доступа к данным Microsoft ActiveX Data Objects, ADO. (Object Linking and Embedding DataBase — связывание и встраивание объектов баз данных) является более универсальной технологией для доступа к любым источникам данных через стандартный интерфейс СОМ (Component Object Model -- модель компонентных объектов). Данные могут быть представлены в любом виде и формате (например, реляционные БД, электронные таблицы, документы в rtf-формате и т. д.). В интерфейсе OLE DB используется механизм провайдеров, под которыми понимаются поставщики данных, находящиеся в надстройке над физическим форматом данных. Такие провайдеры еще называют сервис-провайдерами, благодаря им можно объединять в однотипную совокупность объекты, связанные с разными источниками данных. Кроме того, различают OLE DB-провайдер, который реализует интерфейс доступа OLE DB поверх конкретного сервис-провайдера данных. При этом поддерживается возможность многоуровневой системы OLE DB-провайдеров, когда OLE DB-провайдер может находиться поверх группы OLE DB-провайдеров или сервис-провайдеров. Интерфейс OLE DB может использовать для доступа к источникам данных интерфейс ODBC. В этом случае применяется OLE DB-провайдер для доступа к ODBC-данным. Таким образом, интерфейс OLE DB не заменяет интерфейс ODBC, а позволяет организовывать доступ к источникам данных через различные интерфейсы, в том числе и через ODBC. ADO – это объектно-ориентированный интерфейс фирмы Мicrosoft для работы с базами данных и другими аналогичными источниками данных – объектам данных АctiveХ (АctiveХ Data Оbject – АDО). АDО содержит описание объектов, которые можно использовать для работы с данными многих различных типов приложений. АDО опирается на интерфейс Соmmоn Оbjесt Моdel (СОМ), содержащий объекты, доступные для широкого спектра языков программирования, включая Visual С++, Visual Basic, Visual Basic for Applications (VВА), VBScript и JavaScript. АDО также можно использовать в серверных или приложениях промежуточного типа, особенно при работе с Active Server Page компании Мicrosoft. Модель объекта ADO не содержит ни совокупности таблиц, ни среды, ни процессора БД или исполняющей машины (DataBase Access Engine), а включает объекты, представленные на рисунке 9, к которым относятся: Сonnection. Используется для представления связи с источником данных, а также для обработки некоторых команд и транзакций. Сommand. Используется для работы с командами, отправляемыми источнику данных. Rесоrdset. Используется для работы с табличными данными, в том числе для извлечения и модификации данных. Field. Используется для представления информации о столбце в наборе записей, включая значения этого столбца и другую информацию. Раrаmeter. Используется для обмена данными с командами, отправляемыми источнику данных. Рrореrtу. Используется для манипулирования определенными свойствами других объектов, используемых в АDО. Еrrоr. Используется для получения более конкретной информации о возможных ошибках. Стандарт ADO в среде Delphi поддерживается рядом компонентов (TADOConnection, TADODataSet, TADOTable, TADOQuery,TADOStoredProc и TADOCommand), с помощью которых можно подключаться к любым наборам данных (информационным ресурсам - data store), которые поддерживают данную технологию Microsoft. Для того, чтобы подключиться к БД через ADO можно использовать стандартный метод ADO и стандартный метод Delphi. В первом случае ADO компоненты используют свойство ConnectionString для прямого обращения к данным. Во втором случае используется специальный компонент TADOConnection, который обеспечивает расширенное управление соединением и позволяет обращаться к данным нескольким ADO компонентам. Определить параметры подключения можно: предварительно создав специальные файлы конфигурации *.udl; формировав параметры строки подключения «на лету» во время выполнения приложения. Создание файла конфигурации осуществляется с помощью команды Создать/ Microsoft Data Link проводника Windows. Файл конфигурации *.udl рекомендуется размещать в папке C:\Program Files\Common\ SYSTEM\ole db\Data Links, которая создается при инсталляции Delphi с установкой OLE DB. После создания udl-файла и появления иконки (рисунок 10) с помощью опции Свойства всплывающего меню осуществляется настройка свойств соединения. В первую очередь осуществляется выбор провайдера (Provider) или поставщика услуг в соответствии с выбранным источником данных. Для ранее приведенного примера подсоединения к таблицам БД Visual FoxPro необходимо выбрать Microsoft OLE DB Provider ODBC Drivers, далее выбрать зарегистрированное в администраторе ODBC имя User DSN, и указать его в качестве источника данных на странице Подключение. На этой же странице указываются имя пользователя и пароль для входа в сервер, начальный каталог. |
3 Транзакции. Свойства транзакций. Уровни изоляции. Транзакция – это логическая единица работы (чаще всего это последовательность из нескольких таких операций). Система, поддерживающая обработку транзакций, гарантирует, что если во время выполнения неких обновлений произойдёт ошибка, то все эти обновления будут отменены. Системный компонент, обеспечивающий атомарность (или её подобие) называется менеджером транзакций (TP monitor), а ключевыми элементами её выполнения служат операторы:
ACID – свойства транзакций
Уровни изоляции Уровень изоляции включает уровень завершенного считывания (READ COMMITTED), повторяемого считывания (REPEATABLE READ) и способности к упорядочиванию (SERIALIZABLE). По умолчанию устанавливается SERIALIZABLE, хотя, если задан один из трёх перечисленных уровней, всегда можно использовать более высокий уровень. Приоритет уровней: SERIALIZABLE> REPEATABLE READ> READ COMMITTED> READ UNCOMMITTED. Если все транзакции выполняются на уровне способности к упорядочению (принятых по умолчанию), то чередующееся выполнение любого множества параллельных транзакций может быть упорядочено. Однако, если любая транзакция выполняется на более низком уровне изоляции, то существует множество различных методов нарушения способности к упорядочению. В данном стандарте указано три особых нарушения способности к упорядочению, а именно:
Фиктивные элементы. Допустим, что транзакция T1 извлекает множество всех строк, которые удовлетворяют некоторому условию. Допустим, что транзакция T2 вставляет новую строку, которую удовлятворяет тому же условию. Если транзакция T1 вновь повторит эту же операцию извлечения что и раньше, то ею будет обнаружена ранее отсутствовавшая строка – «фиктивная строка». Различные уровни изоляции определяются на основе приведённых выше случаев нарушения способности к упорядочению. Система может предотвратить появление «фиктивных элементов», если в ней предусмотрена блокировка пути доступа к этим данным. |
|
1 Задача оптимального программирования производства при ограниченных ресурсах. Рассмотрим проблему оптимального использования ресурсов с целью максимизации валовой прибыли, путем подбора ассортимента выпускаемой продукции. Любое производство нуждается в определенном наборе, количестве и качестве ресурсов(сырье, энергия..) Как правило рынок ресурсов является весьма ограниченным, и на нем побеждает тот покупатель, который способен за преобретен.ресурсов заплатить больше. Поэтому каждый производитель заинтересован в том, чтобы приобретенные ресурсы, запущенные в его технологию, принисли бы мах прибыль после их переработки в готовую продукцию и ее реализации. Каждое производство способно выпускать строго определенный ассортимент изделий причем каждое изделие в данный момент времени имеет на рынке готовой продукции свою определенную цену. Производство того или иного изделия нуждается в потреблении тех или иных ресурсов в определенном соотношении. Итак некоторое предприятие способно выпускать некоторую продукцию видов 6, перед собой имеет цель-используя имеющиеся запасы ресурсов получить мах валовую прибыль. Предприятие имеет в своем распоряжении три вида ресурсов: сырье, топливо и деньги. Цель- мах-ть прибыль от реализации готовой продукции. Понятно, что прибыль зависит от цены, установивш.на кажд.из видов продукции, и от кол-ва реализованных изделий. Прибыль F=а1х1+а2х2+..а6х6, где х1..х6 кол-во реализ.изделий по цене а1..а6 за 1 шт..Данное выражение наз.целевой функцией и решение задачи сводится к поиску мах ее значения путем нахожд.перемен.х1..х6. Выбор количества выпускаемых единиц продукции х1..х6 ограничен имеющ.ресурсами Ограничения: по топливу Т1х1+…Т6х6≤Тзап., по сырью С1х1..С6х6≤ Сзап., по деньгам Д1х1..Д6х6≤Дзап. Решение произв. в ЕХЕIIE. Заносим исходные данные в ЕХЕЛЬ, после заполнения таблиц исходных данных оформляем целевую функцию задачи, используя функцию СУММПРОИЗВ из категории математич, мы можем найти сумму произведений элементов двух диапазонов ячеек «х(количество)» и «а(прибыль)». Т.к. «х(количество)» пока не заполнен то равен 0, знач.целевой функции=0. Формулы ограничен.тоже составл. СУММПРОИЗВ и равны пока 0 т.к. «х(количество)» пока не заполнен. После того как формы будут заполнены из «Сервис» пункт «Поиск решения» возникает окно «Поиск решения». В качестве целевой ячейки поиска решения, курсором мыши укажем ячейку целевой функции (F13 например). После этого в окне ввода «установить целевую ячейку» появится ссылка на нее. Установим текущий курсор в окно «Ограничения» и нажмем кнопку «добавить». Используя возникшее окно «добавление ограничений» внесем ограничения по первому ресурсу (по топливу). После этого нажав кнопку «добавить» окна «добавления ограничен.», внесем ограничения по остальным ресурсам, после нажмем «ОК». Теперь нужно проконтролировать чтобы использовался симплексный метод, нажмем кнопку «Параметры..» окна «Поиск реш» – наличие пометки «Линейная модель» – «ОК» и в окне «Поиск реш.» – «Выполнить». В рез-те найдено мах. значен. целевой функции, необходимый для этого набор выпускаемых изделий и значений ограничений. |
2 Синтаксис реляционной алгебры. В реализациях конкретных реляционных СУБД сейчас не используется в чистом виде ни реляционная алгебра, ни реляционное исчисление. Фактическим стандартом доступа к реляционным данным стал язык SQL (Structured Query Language). Язык SQL представляет собой смесь операторов реляционной алгебры и выражений реляционного исчисления, использующий синтаксис, близкий к фразам английского языка и расширенный дополнительными возможностями, отсутствующими в реляционной алгебре и реляционном исчислении. Вообще, язык доступа к данным называется реляционно полным, если он по выразительной силе не уступает реляционной алгебре (или, что то же самое, реляционному исчислению), т.е. любой оператор реляционной алгебры может быть выражен средствами этого языка. Именно таким и является язык SQL. Реляционная алгебра представляет собой набор операторов, использующих отношения в качестве аргументов, и возвращающие отношения в качестве результата. Таким образом, реляционный оператор f выглядит как функция с отношениями в качестве аргументов: R=f(R1, R2, R3…Rn) Реляционная алгебра является замкнутой, т.к. в качестве аргументов в реляционные операторы можно подставлять другие реляционные операторы, подходящие по типу: Теоретико-множественные операторы: Объединение, Пересечение, Вычитание, Декартово произведение Специальные реляционные операторы: Выборка, Проекция, Соединение, Деление Объединением двух совместимых по типу отношений A и B называется отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих или A, или B, или обоим отношениям. Синтаксис операции объединения: A UNION B SELECT * FROM A UNION SELECT * FROM B; Пересечением двух совместимых по типу отношений A и B называется отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих одновременно обоим отношениям A и B. A INTERSECT B SELECT * FROM A INTERSECT SELECT * FROM B; Вычитанием двух совместимых по типу отношений A и B называется отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих отношению A и не принадлежащих отношению B. A MINUS B Оператор SQL:SELECT * FROM A EXCEPT SELECT * FROM B Декартово произведение двух отношений должно быть множеством упорядоченных пар кортежей. Декартово произведение двух отношений А и В, где А и В не имеют общих имен атрибутов, определяется как отношение с заголовком, который представляет собой сцепление двух заголовков исходных отношений А и В, и телом, состоящим из множества всех кортежей t, таких, что t представляет собой сцепление кортежа а, принадлежащего отношению А, и кортежа b, принадлежащего отношению В. Кардинальное число результата равняется произведению кардинальных чисел исходных отношений А и В, а степень равняется сумме их степеней. A TIMES B SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, … FROM A, B; или SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, … FROM A CROSS JOIN B; Выборкой (ограничением, селекцией) на отношении A с условием C называется отношение с тем же заголовком, что и у отношения A, и телом, состоящем из кортежей, значения атрибутов которых при подстановке в условие Cдают значение ИСТИНА. Cпредставляет собой логическое выражение, в которое могут входить атрибуты отношения Aи (или) скалярные выражения. В
простейшем
случае условие
Cимеет
вид
Синтаксис операции выборки: A WHERE C, или A WHERE X@Y Оператор SQL: SELECT * FROM A WHERE c; Проекцией отношения A по атрибутам X,Y…Z, где каждый из атрибутов принадлежит отношению A, называется отношение с заголовком (X,Y…Z )и телом, содержащим множество кортежей вида (x,y…z ), таких, для которых в отношении Aнайдутся кортежи со значением атрибута Xравным x, значением атрибута Yравным y, …, значением атрибута Zравным z. Синтаксис операции проекции: A[X,Y…Z] SELECT DISTINCT X, Y, …, Z FROM A; СоединениеОперация соединения отношений, наряду с операциями выборки и проекции, является одной из наиболее важных реляционных операций. Обычно
рассматривается
несколько
разновидностей
операции
соединения:
Общая операция
соединения,
Наиболее важным из этих частных случаев является операция естественного соединения. Все разновидности соединения являются частными случаями общей операции соединения. Общая операция соединенияОпределение 8. Соединением отношений A и Bпо условию C называется отношение (A TIMES B) WHERE C Cпредставляет собой логическое выражение, в которое могут входить атрибуты отношений A и B и (или) скалярные выражения. Таким образом, операция соединения есть результат последовательного применения операций декартового произведения и выборки. Если в отношениях A и B имеются атрибуты с одинаковыми наименованиями, то перед выполнением соединения такие атрибуты необходимо переименовать. |
3 Средства повышения надежности работы приложений. Исключительные ситуации. Надежность программного изделия, как любого изделия этапа проектирования определяется надежностью всех видов обеспечения и ошибками проекта. Типичные ошибки проектирования программных проуктов:
Повышает надежность обработка исключительных ситуаций. Exception (иск. ситуация) –это ошибки времени выполнения В Delphi введен специальный класс Exceptions который инкапсулирует основные характеристики и методы доступа Exception TObjection | Exception |_Eabaut (скрытое исключение) |_EInOutError(ввода вывода) |_EIndError(ошибки при выполнении целочисленных опрераций) Исключительная ситуация или исключение – это ошибки времени выполнения, переполнение, деление на 0, невозможность приведения экземпляра класса к указанному типу, не готовность устройства. В приложениях D5 можно использовать спец. класс Exception. Он инкапсулирует основные характеристики и методы доступа к этим характеристикам. При возникновении исключ. ситуации создается экземпляр класса соответствующего исключения Raise. Происходит вызов стандартной процедуры Raise, которая помещает исключения в фрэйм исключений. В SysUtils описана глобальная переменная отражаемая содержимое фрэйма. Использование экземпляра новых классов исключений осуществляется с помощью 2ух основных конструкций:
{что защищаем} finally {код завершения что делаем если возникла ИС} end;
{-------------} except {обработка ИС} end. Если за время выполнения операторов следующих за try не возникло исключений то выполняется оператор следующий за try end. Если м/у try и finally произошло исключение то управление немедленно передается первому оператору следующему за finally. Блок finally называют блоком очистки или освобождения системных ресурсов, а try - finally защиты ресурсов. Первая конструкция не позволяет идентифицировать возникшее исключение а следов-но обработать его, конструкция то-ко выявляет ИС. В отличие от 1-ой когда блок finally выполняется всегда, except выполняется лишь в случае возникновения ИС. Отсеить предполагаемые ошибки можно с помощью конструкции ON…do. Каждая директива связывает ситуацию ON c группой операций Do. Если возникло исключение не обозначенное On…Do то вызывается стандартный обработчик исключений. После обработки ИС происходит выход из защищенного блока и управление в секцию try не передается. Конструкции 1 и2 могут быть вложены. Отсеивание возникшей ИС каскадом except осущ-ся последовательно, но необходимо точно представлять место в классе исключения в иерархии, отключающее системное средство подхватывающее исключение по умолчанию. Помимо каскада ON Do исп-ся else: --- try ----- except On EoutOfMemory do Shomessage(‘Мало памяти’) On EoutOfResources do showmessage(Мало ресурсов) else showmessage(‘не знаю ’) end; ---. Для обращения к методам и свойствам исключений можно использовать невидимую и автоматически создаваемую переменную E определяемую экземпляр класса. Try …except On E:EmyException do showmessage(E.message) end. Где Е переменная, область видимости которой ограничена оператором do.Поэтому можно использовать в showmessage(E.message) это св-во исключения E.message.Если необходимо повторно возбудить ИС то после обработки on..do вызывается процедура Raise. Исключение определяемое пользователем:EmyException=class(Exception) public ErrorNumber:integer; constructor create(Const Msg:string;ErrorNum:integer) end. При описании конструктора begin inherited create(Msg) ErrorNumber:=ErrorNum;end; Обращение Raise EmyException.Create(). |
|
1 Модели реализации данных в информационной системе. Существует большое разнообразие сложных типов данных, но исследования, проведенные на большом практическом материале, показали, что среди них можно выделить несколько наиболее общих. Обобщенные структуры называют также моделями данных, т.к. они отражают представление пользователя о данных реального мира. Любая модель данных должна содержать три компоненты: структура данных - описывает точку зрения пользователя на представление данных. набор допустимых операций, выполняемых на структуре данных. ограничения целостности - механизм поддержания соответствия данных предметной области на основе формально описанных правил. Общеизвестны иерархическая, сетевая и реляционная модели, в последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных. Модель основана на математическом понятии отношения (relation) + терминология + развитие теории. Часто выражается через элементы множества нормальных форм (normal form), хотя это не обязательно. Общая структура данных может быть представлена в виде таблицы, в которой каждая строка значений (кортеж) соответствует логической записи, а заголовки столбцов являются названиями полей (элементов) в записях. Основной принцип реляционной модели (информационный принцип): все данные в реляционной системе задаются явными значениями. В кортеже содержатся данные, отражающие свойства либо «реального мира», либо связи между несколькими объектами. Для явного выражения связи используют граф или диаграмму связей между объектами. Домены. 1) Скаляр – наименьшая семантическая единица данных, она атомарна и неделима, у неё нет внутренней структуры (цвет, номер, вес). Домен – именованное множество скалярных значений одного типа, общая совокупность значений, из которых берутся реальные значения атрибутов. Каждый атрибут определяется на единственном домене. 2) Домены ограничивают сравнения (соединения, объединения и др. операции). Такая система предотвращает грубейшие нарушения. 3) С точки зрения программистов домен – это тип данных, многие СУБД поддерживают домены в примитивном виде типов данных. 4) Домены и именованные отношения имеют уникальные имена в БД, атрибуты имеют уникальные имена в одном и том же отношении, имена доменов и атрибутов могут совпадать. Отношение. Переменная отношения – именованный объект, значения которого может изменяться во времени. Значение отношения – значение переменной в любой момент времени (просто отношение). Отношение, определенное на множестве доменов, содержит две части:
Предикат является критерием возможности обновления записи в БД. В реляционной модели данных определены два базовых требования обеспечения целостности: целостность ссылок, целостность сущностей. Целостность сущностей. Требование целостности сущностей заключается в следующем: каждый кортеж любого отношения должен отличатся от любого другого кортежа этого отношения (т.е. любое отношение должно обладать первичным ключом). Вполне очевидно, что если данное требование не соблюдается (т.е. кортежи в рамках одного отношения не уникальны), то в базе данных может хранится противоречивая информация об одном и том же объекте. Целостность ссылок Сложные объекты реального мира представляются в реляционной базе данных в виде кортежей нескольких нормализованных отношений, связанных между собой. При этом: Связи между данными отношениями описываются в терминах функциональных зависимостей. Для отражения функциональных зависимостей между кортежами разных отношений используется дублирование первичного ключа одного отношения (родительского) в другое (дочернее). Атрибуты, представляющие собой копии ключей родительских отношений, называются внешними ключами. Требование целостности по ссылкам состоит в следующем: для каждого значения внешнего ключа, появляющегося в дочернем отношении, в родительском отношении должен найтись кортеж с таким же значением первичного ключа. Первичный ключ – уникальный идентификатор некоторого отношения. Потенциальный ключ – подмножество множества атрибутов отношения, обладающего свойствами: уникальности; неизбыточности.
значение внешнего ключа данного множества совпадает со значением первичного ключа другого какого-либо множества. Формальное определение функциональной зависимости: Даны атрибуты X и Y, атрибут Y функционально зависит от X, если в каждый момент времени каждому значению X соответствует одно и то же значение Y. (X -> Y) Для каждого отношения существует вполне определенное множество функциональных зависимостей между атрибутами. Аксиомы ФЗ позволяют из одной ФЗ вывести другие также присущие данному отношению. Аксиомы:
3 Свойство транзитивности, если A -> B и B -> C, то A -> C. |
2 Тренды. Краткосрочное прогнозирование. Под трендом понимается изменение, определяющее общее направление развития, основную тенденцию временных рядов. Линии тренда позволяют графически отображать тенденции данных и прогнозировать их дальнейшие изменения. Подобный анализ называется также регрессионным анализом (регрессионный анализ – форма статистического анализа, используемого для прогнозов; Регрессионный анализ позволяет оценить степень связи между переменными, предлагая механизм вычисления предполагаемого значения переменной из нескольких уже известных значений.). Используя регрессионный анализ, можно продлить линию тренда в диаграмме за пределы реальных данных для предсказания будущих значений. Например, приведённый выше рисунок использует простую линейную линию тренда, которая является прогнозом на четыре квартала вперед, для демонстрации тенденции увеличения дохода. Скользящее среднее. Можно вычислить скользящее среднее (скользящее среднее – последовательность средних значений, вычисленных по частям рядов данных; На диаграмме линия, построенная по точкам скользящего среднего, позволяет построить сглаженную кривую, более ясно показывающую закономерность в развитии данных.), которое сглаживает отклонения в данных и более четко показывает форму линии тренда. Точность аппроксимации. Линия тренда в наибольшей степени приближается к представленной на диаграмме зависимости, если значение R-квадрат (значение R в квадрате – число от 0 до 1, которое отражает близость значений линии тренда к фактическим данным; линия тренда наиболее соответствует действительности, когда значение R в квадрате близко к 1; оно также называется квадратом смешанной корреляции) равно или близко к 1. При аппроксимации данных с помощью линии тренда в Microsoft Excel значение R-квадрат рассчитывается автоматически. |
3 Создание OLAP-средств на стороне сервера и на стороне клиента. Многомерный анализ данных может быть произведен с помощью различных инструментальных средств, которые условно можно разделить на клиентские и серверные OLAP-средства. Клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение, при этом сами агрегатные данные содержатся в кэше внутри адресного пространства такого OLAP-средства. Если исходные данные содержатся в локальной СУБД, вычисление агрегатных данных производится самим OLAP-средством. Если же источник исходных данных — серверная СУБД, многие из клиентских OLAP-средств посылают на сервер SQL-запросы, содержащие оператор GROUP BY, и в результате получают агрегатные данные, вычисленные на сервере. Как правило, OLAP-функциональность реализована в средствах статистической обработки данных (из продуктов этого класса на российском рынке широко распространены продукты компаний StatSoft и SPSS) и в некоторых электронных таблицах. В частности, развитыми средствами многомерного анализа обладает Microsoft Excel 2000. С помощью этого продукта можно создать и сохранить в виде файла небольшой локальный многомерный OLAP-куб и отобразить его двух- или трехмерные сечения. Многие инструментальные средства разработки содержат библиотеки классов или компонентов, позволяющие создавать приложения, реализующие простейший OLAP-сервис (такие, например, как компоненты DecisionCube в Borland Delphi и Borland C++Builder). Клиентские OLAP-средства применяются, как правило, при малом числе измерений (обычно рекомендуется не более шести) и небольшом разнообразии значений этих параметров, — ведь полученные агрегатные данные должны умещаться в адресном пространстве подобного средства, а их количество растет экспоненциально при увеличении числа измерений. Поэтому даже самые примитивные клиентские OLAP-средства, как правило, позволяют произвести предварительный подсчет объема требуемой оперативной памяти для создания в ней многомерного куба. Многие (но не все!) клиентские OLAP-средства позволяют сохранить содержимое кэша с агрегатными данными в виде файла, что, в свою очередь, позволяет не производить их повторное вычисление. Идея сохранения кэша с агрегатными данными в файле получила свое дальнейшее развитие в серверных OLAP-средствах, в которых сохранение и изменение агрегатных данных, а также поддержка содержащего их хранилища осуществляются отдельным приложением или процессом, называемым OLAP-сервером. Клиентские приложения могут запрашивать подобное многомерное хранилище и в ответ получать те или иные данные. Некоторые клиентские приложения могут также создавать такие хранилища или обновлять их в соответствии с изменившимися исходными данными. Преимущества применения серверных OLAP-средств по сравнению с клиентскими OLAP-средствами сходны с преимуществами применения серверных СУБД по сравнению с локальными: в случае применения серверных средств вычисление и хранение агрегатных данных происходят на сервере, а клиентское приложение получает лишь результаты запросов к ним, что позволяет в общем случае снизить сетевой трафик, время выполнения запросов и требования к ресурсам, потребляемым клиентским приложением. Средства анализа и обработки данных масштаба предприятия, как правило, базируются именно на серверных OLAP-средствах, например, таких как Oracle Express Server, Microsoft SQL Server 2000. Многие клиентские OLAP-средства (в частности, Microsoft Excel 2000 и др.) позволяют обращаться к серверным OLAP-хранилищам, выступая в этом случае в роли клиентских приложений, выполняющих подобные запросы. Помимо этого имеется немало продуктов, представляющих собой клиентские приложения к OLAP-средствам различных производителей. |
|
1 Системная интерпретация модели - черный ящик. Простейшей моделью системы явл-ся модель «черный ящик». Так называют систему, о которой внешнему наблюдателю доступны только лишь входные и выходные параметры, а внутренняя структура системы и процессы в ней неизвестны. Входные параметры можно рассматривать как управляющие воздействия, а желательные значения выходных – как цель управления. Ряд важных выводов о поведении системы можно сделать, наблюдая только ее реакцию на воздействия, т.е. наблюдая зависимости м/у изменениями входных и выходных параметров. Такой подход открывает возможности изучения систем, устройство которых либо совсем неизвестно, либо слишком сложно для того что бы можно было по свойствам составных частей и связям м/у ними сделать выводы о поведении системы в целом. Поэтому понятие «черный ящик» широко применяется при решении задач идентификации и моделировании реакции на управляющее воздействие в АСУ сложными объектами управления. Если схему моделирования системы «черным ящиком» изобразить в виде: То можно определить два ее основн.свойства: целостность и обособленность от среды. Взаимодействие со средой осуществляется лишь на входе в систем, куда поступают средства, необходимые для обеспечения цели, котор.на рис.обозначены выходной стрелкой. В экономике производственные системы, как правило, технологически закрыты и моделируются «черным ящиком». В этом случае, известны лишь внешние поступления ресурсов (средств) и выход готовой продукции (цель). Такие системы в математическом представлении могут быть даны так: Здесь х1,х2,хn – измеренные объемы ресурсов. Они называются аргументами-факторами. Y – измеренный валовый доход, называется функцией. Сама математическая модель записывается в виде формулы Y= f(x1,x2…xn). В экономике такую функцию называют производ-ственной. |
2 OLAP-технология. Состав аналитической информационной системы. В области информационных технологий можно выделить два класса систем:
Основная идея OLAP-технологии заключается в построении многомерных кубов данных, которые в дальнейшем можно использовать для реализации аналитических пользовательских запросов. Исходные данные для построения OLAP-кубов обычно хранятся в реляционных базах данных, называемых также хранилищами данных (Data Warehouse). В отличие от оперативных баз данных, с которыми работают приложения ведения данных, хранилища данных предназначены исключительно для обработки и анализа информации, поэтому проектируются они таким образом, чтобы время выполнения запросов к ним было минимальным. Обычно данные копируются в хранилище из оперативных баз данных согласно определенному регламенту, например, раз в месяц, квартал или год. Типичная структура хранилища данных существенно отличается от структуры обычной реляционной БД. Как правило, эта структура денормализована (это позволяет повысить скорость выполнения запросов), поэтому может допускать избыточность данных. Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables). Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся: факты, связанные с транзакциями. Они основаны на отдельных событиях (например, телефонный звонок); факты, связанные с «моментальными снимками». Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за; факты, связанные с элементами документа. Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки); факты, связанные с событиями или состоянием объекта. Представляют возникновение события без подробностей о нем. Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений, чаще всего это целочисленные значения либо значения типа «дата/время». Так как таблица фактов может содержать сотни тысяч записей, то хранить в ней повторяющиеся текстовые описания, как правило, невыгодно — лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые не ключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные. Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В подавляющем большинстве случаев эти данные представляют собой по одной записи для каждого элемента нижнего уровня иерархии в измерении. Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем элемента измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для однозначной идентификации элемента измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного элемента в этой иерархии. Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов. Скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов; например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее. Одно измерение куба может содержаться как в одной таблице, так и в нескольких связанных таблицах, соответствующих различным уровням иерархии в измерении. Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда». Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка». Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами. Традиционно даже при наличии иерархических измерений с целью повышения скорости выполнения запросов к хранилищу данных предпочтение отдается схеме «звезда». С общей позиции обработки данных можно выделить два доминирующих класса информационных систем: системы, ориентированные на операционную (транзакционную) обработку данных (On-Line Transaction Processing, OLTP-системы), часто их определяют как системы обработки данных (СОД); системы, ориентированные на аналитическую обработку данных (Decision Support Systems, DSS), или системы поддержки принятия решений (СППР). СОД обеспечивают процессы повседневной рутинной обработки данных на конкретных рабочих местах или производственных участках. СППР – являются вторичными по отношению к СОД и призваны осуществлять анализ результатов деятельности за различные периоды времени, оценку эффективности работы отдельных подразделений или сотрудников и другие аналитические процедуры. Дальнейшее развитие аналитических информационных систем связано с технологией оперативной аналитической обработки данных (On-Line Analytical Processing, OLAP-системы), в основе концепции которой лежит многомерное представление данных. В среде Delphi многомерные данные представляются в виде метакуба, где каждому фактору соответствует свое измерение. В конкретной ячейке, как правило, представляются агрегированные данные – сумма, среднее, максимальное значение – или новые многомерные данные (кубы). Как правило для формирование набора данных из совокупности связанных таблиц используется компонент TDecisionQuery, SQL оператор к-го содержит оператор Select. TdecisionCube - реализует многомерный куб. Соединяется с набором данных при помощи сво-ва DataSet. TdecisionGrid – показывает данные из многомерного куба. TdecisionGraph – предназначен для показа графиков, источником к-х служат многомерные данные. |
3 Кибернетический подход к информационной системе как системе управления. Понятие кибернетической системы связано с процессами управления и переработки данных. Процесс управления рассматривается как процесс взаимодействия двух систем – управляющей и управляемой, в которой X – входные параметры о состоянии объектов управления, Y – выходные параметры, по которым судится о том, достигнута ли цель управления. Обратная связь – обеспечивает передачу данных в управляющую систему, по которым судят о рассогласовании цели и получаемых результатов.Управляющие или управленческие воздействия - среда. Процесс управления содержит следующие этапы:
Обязательным элементом любой системы управления является информационная система – это коммуникационная система сбора, передачи, переработки данных об объекте управления. Данная система снабжает работников различного уровня информацией для реализации функций управления. Информационные системы могут быть – прочными, автоматизированными и автоматическими. Данная классификация учитывает пропорции ведения данных между человеком и вычислительным устройством.
ВУ – вычислительное устройство
Если в системе есть человек, то система называется автоматизированной. ИС сама по определению является тоже системой управления. Определение ИС включает:
|
.
|
1 Реляционная модель данных. Нормальные формы высших порядков. Реляционная модель данных - это такая модель, которая представлена в виде совокупности отношений, совокупности кортежей. В основе реляционной модели использовано понятие отношения представляющего собой подмножество декартова произведения доменов. Домен-это некоторое множество элементов(например, множество 2целых чисел или множество допустимых значений, которые может принимать объект по некоторому свойству). Элементами отношения являются кортежи. Арность кортежа определяет арность отношения. Отношения арности 1 часто называют унарным, арности 2-бинарным, арности 3-тернарым, арности n-n-арными. В отношении не должны встречаться одинаковые кортежи, и кроме того, порядок кортежей в отношении несуществ-и. Строка-кортеж Столбец-домен или атрибут Таблица, представляющая К-арное отношение R, обладает следующими свойствами: каждая строка представляет собой кортеж и R значений, принадлежащих R столбцам; Порядок столбцов фиксирован; порядок строк безразличен; любые две строки различаются хотя бы одним элементом Строки и столбцы могут обрабатываться в любой последовательности определенной применяемыми операционной обработки. Атрибуты отношений - это столбцы отношений Схема отношений - список именных атрибутов Схема реляционной БД-набор схем отношений. Облегчает установление связей, дает возможность легко и быстро установить новую связь, позволяет оптимальным образом осуществить доступ к данным любого уровня. Все СУБД, работающие на ПК, поддерживают эту модель. Преимущества модели: гибкость модели объясняется наличием математического аппарата нормализации отношений; наличие внешних ключей; использование языка структурированных запросов. В основу реляционной модели положен теоретико-множественный подход, базирующийся на понятии отношения. В основе отношения – таблица (плоский файл). Набор отношений может быть использован для хранения данных конкретной ПО. Нормальная форма Каждая НФ во-первых, ограничивает определенный тип ФЗ, во-вторых, устраняет соответствующие аномалии при выполнении операций над отношениями. 1НФ: Отношение находится в 1НФ если значения всех его атрибутов атомарны. 2НФ: Отношение находится во 2НФ, если оно находится в 1НФ и каждый неключевой атрибут функционально полно зависит от ключа. 3НФ: отношение находится в 3НФ, если оно находится во 2НФ и в нем отсутствуют транзитивные зависимости неключевых атрибутов от ключа. 3НФ освобождает от избыточности и аномалий выполнения операций включения, удаления и обновления. НФ Бойса-Кодда: Отношение находится в НФБК, если оно находится в 3НФ и отсутствует зависимость ключей от ключевых атрибутов. 4НФ: если в нем присутствуют многозначные ФЗ. Переменная-отношения R нах. в 4НФ, если существуют множества А и В атрибутов этой переменной отношения R, для которых выполняется нетривиальная многозначная зависимость А -> В , все атрибуты отношения R также функционально зависят от атрибута. 5НФ: отношение нах. в 4НФ, декомпозируется в 5НФ так, чтобы результат удовлетворял сохранению зависимости по соединению. Переменная-отношения R нах. в 4НФ, которую иногда иначе называют проекционно-соединительной НФ, если каждая нетривиальная зависимость соединения в переменной-отношении R подразумевается ее потенциальными ключами. |
2 Технология OLE. Механизм, называемый OLE-автоматизацией (automation) предназначен для предоставления одними приложениями своих сервисов другим приложениям. Приложение, предоставляющее сервисы, называют сервером автоматизации. Приложение, использующее сервис, называют клиентом или контроллером автоматизации. Каждый сервер автоматизации обладает уникальным идентификатором GUID (Global Unique Identifier), информация о котором хранится в системном реестре. Сервер автоматизации предоставляет своим клиентам для доступа объект специального типа - dispatch object. При этом в адресном пространстве приложения-котроллера, управляющего сервером, присутствует вариантная переменная, содержащая интерфейс IDispatch, предоставляющий контроллеру доступ к этому объекту. Для создания экземпляра объекта автоматизации в Delphi используется функция function CreateOleObject (const ClassName:string):IDispatch. Данная функция создает экземпляр объекта и возвращает указатель на его интерфейс. В качестве параметра функции передается имя класса, который должен быть зарегистрирован в системном реестре. Например, для использования сервисов, предоставляемых редактором Word, в приложении Delphi необходимо создать объект автоматизации следующим способом: uses ComObj; var WD: Variant; WD:=CreateOleObject(‘Word.Application.8’); Наличие тех или иных возможностей управления сервером зависит от того, какие объекты, свойства и методы сервера предоставлены разработчиками сервера для автоматизации внешних приложений. Описание всех констант, свойств и методов, предоставляемых для автоматизации с помощью внешних приложений, хранится в библиотеке типов. Для открытия библиотеки типов в среде Delphi необходимо:
Type Library (*.tlb, *.dll, *.ocx, *.exe, *.olb)
для Excel - c:\Program Files\ Microsoft Office\Office\excel8.olb для Word - c:\Program Files\ Microsoft Office\Office\msword8.olb |
3 Интерфейсы материнской платы и стандарты шин: ISA, EISA, PCI, AGP. Материнская плата сопрягается с внешними устройствами линиями обмена данными. В их качестве выступают шины и порты ввода-вывода. Шина – совокупность проводок и разъемов, обеспечивающих взаимодействие устройств компьютера. С момента начала использования ПК применялись различные стандарты шинной архитектуры (ISA, EISA, MCA, VLB, PCI, AGP). Интерфейс — это средство сопряжения двух устройств, в котором все физические и логические параметры согласуются между собой. Для согласования интерфейсов периферийные устройства подключаются к шине не напрямую, а через свои контроллеры (адаптеры) и порты примерно по такой схеме: Устройство – контроллер (или адаптер) – Порт – Шина Каждый из функциональных элементов (память, монитор или другое устройство) связан с шиной определённого типа — адресной, управляющей или шиной данных. Для подключения дочерних плат используются шины стандартов EISA, ISA, PCI, AGP. Шина ISA (Industry Standard Architecture) в первой своей версии (шина IBM/PC) имела тактовую частоту 4,7 МГц, выполняла роль единой системной шины в первых персональных компьютерах. В следующей версии (шина PC/AT) путем добавления 36-контактного гнезда для подачи дополнительных сигналов была сохранена совместимость снизу вверх. Шина тактировалась частотой 8,33 МГц. С переходом к 32-разрядному процессору i80836 шина ISA не претерпела изменений. Поэтому производительность компьютеров снизилась. Скорость передачи данных была порядка 5 Мбайт/с (максимальная пропускная способность – 16,7 Мбайт/с). Было ограниченным адресное пространство. Как следствие, шину ISA была расширена для эффективного применения в 32-разрядной вычислительной системе и сохранилась при этом возможность использования плат расширения стандарта ISA. В результате появилась шина EISA (Extended ISA) с двухэтажными слотами, по форме и длине соответствующими слотам шины ISA. В новом слоте дополнительные контакты для плат EISA находятся ниже (глубже) обычных контактов ISA. EISA имеет 32-битовую ширину данных и адреса, допускает автоматическое конфигурирование плат EISA, отличая их от плат ISA (каждая плата EISA имеет свое кодовое число, по которому система ее идентифицирует (узнает) и устанавливает оптимальную конфигурацию). Максимальная скорость передачи данных по шине EISA – 33,3 Мбайт/c при частоте шины 8,33 МГц. Наиболее распространенным является подключение дочерних плат через шину стандарта PCI (Peripheral Component Interconnect). Здесь передача данных и адресов происходит по одним и тем же линиям. При работе на частоте 66 МГц и передаче 64 битов за цикл пропускная способность шины составляет 528 Мбайт/с. Данная шина в состоянии распознавать аппаратные средства и анализировать конфигурацию системы. Она была разработана в основном фирмой Intel для процессора Pentium. Шина PCI является промежуточным звеном между локальной шиной процессора и шиной ISA/EISA. Соединение ее с шиной центрального процессора осуществляется через мост PCI (Host Bridge). Мост согласует шину центрального процессора с шиной PCI, обеспечивая в дальнейшем возможность ее стыковки с процессорами следующих поколений. Одна шина PCI может обслуживать не более четырех устройств (4 слота). Мосты, расположенные вокруг шины PCI программируются и выполняют маршрутизацию обращений по связанным шинам. Возможны два типа устройств стандарта PCI: целевое и ведущее. Целевое способно воспринимать команды ведущего устройства, которое может обрабатывать информацию независимо от шины и других подключенных к ней устройств (оно может выступать целевым устройством для другого ведущего устройства). Шина AGP (Advanced Graphic Port) предназначена для обмена информацией с видеоадаптером. Наряду с повышением пропускной способности шины применяются меры по уменьшению потока данных, передаваемых по шине при графических построениях. Для этого графические адаптеры снабжаются акселераторами, а также увеличивается объем их буферной памяти (видеопамяти). При этом высокоэффективный поток данных в основном циркулирует внутри графической карты и только в самых сложных построениях выходит на шину PCI. AGP – это новый стандарт подключения графических адаптеров, по составу сигналов напоминающий PCI. Его основные особенности: -конвейеризация обращений к памяти (может ставить в очередь до 256 запросов); -сдвоенная передача данных при частоте 66 МГц обеспечивает пропускную способность до 532 Мбайт/с. Шина USB (Universal Serial Bus) разработана в середине 90-х годов коллективными усилиями многих компаний (Compaq, DEC, IBM, Intel, Microsoft и др.) для подключения к шинам ISA и PCI низкоскоростных периферийных устройств. Эта шина состоит из центрального хаба (hab – концентратор), называемого еще корневым концентратором. Центральный хаб содержит разъемы для кабелей, посредством которых к нему могут подсоединяться устройства ввода-вывода или дополнительные хабы для обеспечения большего количества разъемов. Получается древовидная структура с корнем в центральном хабе, который вставляется в разъем шины ISA или PCI. Общая пропускная способность шины – 1,5 Мбайт/с. |
|
1. Методы анализа информационных потоков и структуризации предметной области. Процесс потребления информационных ресурсов реализуется информационными потоками или потоками данных. Анализ информационных потоков осуществляется с целью:
Программа обследования должна включать следующие разделы:
На первом этапе обследования разрабатывается структурно-функциональная схема (декомпозиция ИС по структурно-функциональному признаку). Для предприятия.
Выбор функциональных задач осуществлён с учётом основных фаз управления:
Реализация каждой из этих функций в условиях функционирования ИС связано с выбором варианта, эффективность которого оценивается критерием целей управления. Следовательно, одни и те же задачи реализуются с привлечением математической модели и методов (МО). Поиск наилучшего варианта связан со сложностью алгоритма (временная и ёмкостная сложность) возможен на соответствующем варианте технического обеспечения. |
2. Получение аналитических показателей близости и адекватности при построении трендов и производственных функций. Независимо от вида и способа построения экономико-математической модели вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т.е. соответствия модели исследуемому процессу или объекту. Так как полного соответствия модели реальному процессу или объекту быть не может, адекватность — в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые считаются существенными для исследования. Трендовая модель ŷt конкретного временного ряда г/( считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента ε=yt-ŷt (t=1, 2. ...,n) удовлетворяла свойствам случайной компоненты временного ряда: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. |
3. Парадигма объектно-ориентированного программирования. Объектно-ориентированное программирование - это методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования. Программа будет считаться объектно-ориентированной только при соблюдении следующих трех требований: 1. Данный подход использует в качестве базовых элементов объекты, а не переменные, функции или алгоритмы. 2. Каждый объект является экземпляром определенного класса. 3. Классы организованы в иерархию. В соответствии с определением не все языки программирования можно считать объектно-ориентированными. Язык можно отнести к таковым, если он имеет средства поддержки объектно-ориентированного стиля и использование этого стиля в языке естественно и не требует искусственных усилий. Парадигма объектно-ориентированного программирования может быть сформулирована следующим образом: Реши, какие требуются классы; обеспечь полный набор операций для каждого класса; явно вырази общность через наследование. Сущность ООП заключается в использовании объектов. ООП представляет собой расширение языков программирования (Object Pascal), новым структурированным типом данных – классом. ООП позволяет программировать в терминах классов:
Класс описывает свойства (атрибуты) объекта и его методы (включая обработчики событий) . При создании объекта он наследует структуру (переменные) и поведение (методы класса). В свою очередь, класс, называемый потомком, производным или дочерним классом (подклассом), также может быть создан на основе другого родительского класса (предка) и при этом наследует его структуру и поведение. Любой компонент (элемент управления) или объект в Делфи всегда является экземпляром класса. Программно объект представляет собой переменную объектного типа. Для каждого компонента Делфи существует свой класс, наследуемый от ТComponent . Предком всех объектов, включая компоненты, является класс ТObject . Наследование (inheritance) - это процесс, посредством которого один объект может приобретать свойства другого. Точнее, объект может наследовать основные свойства другого объекта и добавлять к ним черты, характерные только для него. Наследование является важным, поскольку оно позволяет поддерживать концепцию иерархии классов (hierarchical classification). Применение иерархии классов делает управляемыми большие потоки информации. Инкапсуляция - это создание защищённых объектов, доступ к свойствам и методам, которых разрешён через определённые разработчиком “точки входа”. Иначе говоря, инкапсуляция – это предоставление разработчику конкретного набора свойств и методов для управления поведением и свойствами объекта, определяемыми внутри класса. Полиморфизм (polymorphism) (от греческого polymorphos) - это свойство, которое позволяет одно и то же имя использовать для решения двух или более схожих, но технически разных задач. Целью полиморфизма, применительно к объектно-ориентированному программированию, является использование одного имени для задания общих для класса действий. Выполнение каждого конкретного действия будет определяться типом данных. Под объектной моделью любой среды разработки программных продуктов понимается реализация принципов ООП т.е. объектная модель – реал-я принципов ООП в языке представления (описания) объектов и правил использования объектов Любая современная среда разработки программного продукта СУБД VFP6/0 и др. Visual Basic, Java имеют свои правила реализации объектной модели. Понятие объекта включено в ОС Windows любой компонент которого сопровождается многостраничным объектом свойств. DELPHI –интегрированная среда разработки программного продукта язык прогр. – Object Pascal. Объектный тип определяется типом class. Под объектной моделью понимают воплощение основных принципов объектно-ориентированного программирования (инкапсуляция + наследование + полиморфизм) в языке представления и правилах использования объектов. Ключевым в понимании полиморфизма является то, что он позволяет вам манипулировать объектами различной степени сложности путём создания общего для них стандартного интерфейса для реализации похожих действий. |
|
1 Системный принцип моделирования. Цель и средства. Системный принцип моделирования - представление системы в виде черного ящика, то есть когда известны параметры на входе и выходе системы. Входные параметры можно рассматривать как управляющие воздействия, а желательные значения выходных – как цель управления. Цель и средства Цель исследования определить цель построения модели. Модели могут строить и для других целей:
|
2 Структура процессора, определение и назначение основных функциональных узлов: АЛУ, УУ, регистровой памяти. Процессор является центральной частью ЭВМ, обеспечивает обработку цифровой информации в соответствии с программой, при этом он непрерывно взаимодействует с операционной памятью, получая из нее команды и операнды и отправляя в память результаты вычислений, организует выполнение операций ввода-вывода. Процессор обеспечивает совместную и согласованную работу всех частей, а именно, как и в любом вычислительном устройстве, - операционной и управляющей. Обобщенная структурная схема процессора:
клава запрос ОЗУ, ПЗУ прерывание Операционная часть: АЛУ – Арифметическое Логическое Устройство, реализует выполнение команд, составляющих программу, используя предусмотренный в нем набор базовых операций (арифметических, логических, условного перехода и т.п.). Вырабатывает сигналы, необходимые для организации вычислительного процесса. По форме представления чисел: АЛУ для чисел с фиксир.точкой, с плавающей, для двоично кодированных десятичных. По принципу действий: АЛУ последовательного действия с поразрядной обработкой информации и АЛУ параллельного действия с одновременной обработкой По степени использования: блочные и универсальные АЛУ БРП – Блок Регистровой Памяти – является местной памятью процессора, имеет небольшую емкость, но более быстродействующая по сравнению с ОЗУ. Используется для повышения быстродействия процессора. В БРП входят: регистры общего назначения (для выполнения арифметических операций с фиксированной точкой и процедур выполнения логических операций; в них хранятся и изменяются базовые адреса и индексы), регистры с плавающей точкой (для выполнения арифметических операций с плавающей точкой, применяются для нормализации полученного результата.) Организующая часть: УУ – Устройство Управления – 1. обеспечивает выполнение команд программ в заданной последовательности, выполнение каждой текущей команды и соответствующей операции в АЛУ
БУР – Блок Управляющих Регистров – является рабочей памятью, недоступной программе, и включает в себя счетчики и регистры для временного хранения управляющей информации. К ним относятся: регистр команд, регистр или счетчик адреса команд, буферные регистры для хранения адресов и слов. Интерфейс процессора – обеспечивает необходимое сопряжение проца с другими устройствами, прежде всего с оперативной памятью и периферией. В целом процессор представляет собой группу устройств, обеспечивающих автоматическую обработку информации и программное управление вычислительными процессами. |
3 Статический и динамический обмен данными. Канал DDE. Статический обмен данными Буфер обмена – совокупность функций ядра ОС и области глобальной памяти.БО доступен всем приложениям, которые обладают функциями как системными, так и собственными способными разделять данные из выделяемой памяти. Инкапсулирует TClipBoard --- ClipBoard --- ClipBrd – модуль Приложения могут помещать выделенные данные в буфер обмена и извлекать их только в соответствии определённых фрагментов. Для обмена текстовыми данными используется методы CopyToClipBoard CutToClipBoard для данных не превышающих 255 символов. Для обмена графическими данными (cf_BitMap, cf_MeFilePict,...) в формате которых хранятся компоненты Tgraphic, TbitMap, Tpicture, TmetaFile и др. Глобальная переменная ClipBoard автоматически открывает - закрывает канал обмена, ведя учёт количества операции обмена. Для того чтобы программно очистить буфер обмена используется метод Clear. Предварительно проверить содержимое данных в ClipBoard позволяет метод: Function EmptyClipBoard: boolean; Динамический обмен данными DDE (Dinamic Data Exchange) – предназначен для оперативной передачи и синхронизации данных в различных приложениях и их системным приложением. Был разработан для реализации свойств проводника. Поддерживает форматы всех данных зарегистрированных в буфере обмена. По протоколу обмена все приложения подразделяются на клиентов и серверов. Оба участника обмена входят в соглашение (SetLink) и осуществляют контакты (Conversations) по определённым темам (Topic) в рамках которых происходит обмен элементами данных (Item). Устанавливает контакты клиент, он отправляет запрос, содержащий имя сервера, имя контакта и тему. После установления контакта всякие изменения элемента данных на сервере (Item) автоматически передаются Item клиенту. При этом у Item клиента возникает событие OnChange. Канал DDE инкапсулирует парой компонентов: TDDEServerConv – пассивный компонент, указывает имя одной из поддерживаемых сервером тем. TDDEClientConv – активный компонент, назначение: установка и разрыв контакта. Через установленный компонент можно создать несколько контактов. TDDEClientItem TDDEServerItem – каждый компонент Item указывает на контакт к которому он привязан и в их состав входят свойства, обеспечивающих передачу и синхронизацию текстовых данных. TDDEServerConv. Свойство Name совпадает с именем тем, которую он поддерживает. Это имя должен знать клиент, как и имя приложения сервера. В момент установления и разрыва контакта возникает событие OnOpenOnClose. |
|
1 Использование теории бизнес-процессов и бизнес-правил. В экономике бизнес-функция это набор средств, правил т.д. направленных на выполнение одной цели. Так и в теории проектирования это список задач, требований, общее описание технологии достижения результата. Бизнес-функция описывает общие средства и технологию достижения цели, поставленной перед ИС. Бизнес-процесс – это описание технологии достижения результата в определенном функциональном базисе. Также это формализованное описание заданного управляемых процедур, включая как выполненные этим набором функции, так и используемые им данные. Состав и взаимоотношения затрагиваемых им организационных подразделений и единиц. Из этих определений можно сделать вывод, что бизнес-процесс является составной частью бизнес-функции. Им описываются более конкретные задачи проекта (ИС). Множество процессов, объединенных одной функцией решают множество задач, что обеспечивает достижение единой цели, стоящей перед ИС. Для обеспечения целостности данных и согласованности процессов в ИС необходимо соблюдать некоторые ограничения, обеспечивающие механизм управления процессами и операциями над данными. Бизнес-правило – это механизм управления БД и предназначено для поддержания БД в целостном состоянии, а также для выполнения других действий, например, накапливания статистики работы с БД. Организуют следующие ограничения:
Бизнес-правила можно организовать как на физическом, так и на программном уровне. В первом случае эти правила задаются при создании таблиц и входят в структуру БД. Действие правил на программном уровне распространяется только на приложение, в котором они реализованы. Для программирования в приложении бизнес-правил используются компоненты и предоставляемые ими средства БИЗНЕС - ПРАВИЛА Бизнес-правила (БП) задают ограничения на значения данных в БД. Они также определяют механизмы, согласно которым при изменении одних данных изменяются и связанные с ними данные в той же или других таблицах БД. Таким образом, бизнес-правила определяют условия поддержания БД в целостном состоянии. Идеология архитектуры «клиент-сервер» требует переноса максимально возможного числа БП на сервер. К преимуществам такого подхода относятся: • гарантия целостности БД, поскольку БП сосредоточены в едином месте (в базе данных); • автоматическое применение БП, определенных на сервере БД, для любых приложений; • отсутствие различных реализаций БП в разнотипных клиентских приложениях, работающих с БД; • быстрое срабатывание БП, поскольку они реализуются на сервере и, следовательно, нет необходимости посылать данные клиенту, увеличивая при этом сетевой трафик; • доступность изменений, внесенных в БП на сервере, для всех клиентских приложений, работающих с настоящей БД, и отсутствие необходимости повторного распространения измененных приложений клиентов среди пользователей. К недостаткам хранения бизнес-правил на сервере можно отнести: • отсутствие у клиентских приложений возможности реагировать на некоторые ошибочные ситуации, возникающие на сервере при реализации БП (например, игнорирование приложениями, написанными на Delphi, ошибок при выполнении хранимых процедур на сервере); • ограниченность возможностей SQL и языка хранимых процедур и триггеров для реализации всех возникающих потребностей определения БП. На практике в клиентских приложениях реализуют лишь такие бизнес-правила, которые трудно или невозможно реализовать с применением средств сервера. Все остальные БП переносятся на сервер. |
2 Построение регрессий. Регрессия – зависимость среднего значения к-л величины от некоторой другой величины или от нескольких величин. Регрессионная модель анализа позволяет количественно выразить взаимосвязь между показателями. Необходимые условия регрессионного анализа:
Регрессия – линия, построенная по атрибуту по принципу обратного использования обратной информации (кусок прямой, параболы). Аргументы (в произв. Функции-факторы) у=а0+а1t+a2t^2 – линейная регрессия (t1, t2- факторы). Накапливаются результаты наблюдений, а затем складываются. Уравнение регрессии – ур-ие, связывающее между собой фактор признаки и результативные признаки. Ур-ие регрессии бывают линейные и нелинейные. Метод регрессии заключатся в построении и решении системы нормальных уравнений. Необходимыми условиями регрессионного анализа является наличие достаточно большого количества наблюдений по совокупности однородных объектов; факторы подверженные исследованию должны иметь количественное измерение; абсолютное измерение, т.е. определить, на сколько единиц изменится величина результативного показателя, при изменении факторного на единицу; установление относительной степени зависимости результативного показателя от каждого фактора. |
3 Стандарты и методики разработки программ. Виды стандартов. Одним из важных условий эффективного использования информационных технологий яв-ся внедрение корпоративных стандартов. Корпоративные стандарты представляет собой соглашение о единых правилах организации технологии или управление. При этом за основу корпоративных могут приниматься отраслевые6 национальные и даже международные стандарты. Однако высокая динамика развития инф-х тех-ий приводит к быстрому устареванию сущ-щих станд-в и методики разработки ИС. Полезны в этом отношении стандарты открытых систем (в первую очередь стандарты на интерфейсы различных видов6 включая лингвистическое, и на протоколы взаимодействия). Однако разработка систем в новых условиях требует также новых методов проектирования и новой организации проектных работ. Проектирование и методическая поддержка организации разработки ИС (включая ПО, и базы данных) традиционно поддерживаются многими стандартами и фирменными методиками. Вместе с тем известно, что требуется адаптивное планирование разработки, в том числе в динамике процесса ее выполнения. Одним из способов адаптивного проектирования яв-ся разработка и применение профилей жизненного цикла ИС и прогр. Обесп. Корпоративные стандарты образуют целостную систему, которая включает три вида стандартов:
Существующие на сегодняшний день стандарты можно несколько условно разделить на несколько групп по следующим признакам:
Ниже мы рассмотрим след. Стандарты и методики, касающиеся организации жизненного цикла ИС и ПО:
|
|
1 Сложные вероятностные системы. Параметры систем. Всякую систему можно характеризовать следующими ее свойствами: - система имеет определенную структуру; - зависит от внешней среды и сама влияет на эту среду; имеет внутренние количественные характеристики, которые полностью определяют все возможные состояния системы в каждый момент времени; - определены все переходы состояний системы во времени; - среди количественных характеристик и функций переходов состояний могут быть случайные величины и случайные функции. В системном анализе такие системы называют открытыми вероятностными системами, взаимодействующими с внешней средой как одно целое и обладающие свойствами самоорганизации и саморазвития. Такие системы, как правило, имеют ту или иную совокупность целевых установок, которые формируют определенный управляющий механизм, а он в свою очередь вырабатывает оптимальное поведение системы. Например, в основе экономических систем заложены законы получения общественных благ при использовании ограниченных ресурсов. Две основные характеристики системы: цель и отклонение реакция на внешнее воздействие. При математическом моделировании цель системы выделяется и измеряется вместе с параметрами системы, те переменные системы, значение которых является неизменным при решении задач. Параметры чаще всего заданы в виде отклонений от параметров среднего состояния системы. Параметры систем- Каждая из систем определяется своим набором основных параметров, наиболее общими для всех являются следующие: Тип системы: открытая (закрытая) система; Наличие входов системы; Наличие выходов системы 2 Классы локальных вычислительных сетей. Одноранговые ЛВС - нет деления на серверы и клиенты, каждый компьютер рассматривается как «Отдельный гражданин», компьютер в такой сети считается равноправным. Может предоставлять доступ к своим периферийным устройствам и файлам и одновременно иметь доступ к другим совместно используемым ресурсам сети. Иерархические ЛВС - существует чёткое разграничение компьютера-сервера и компьютера-клиента. Такая сеть называется сетью с выделенным сервером. Компьютер выполняющий роль выделенного сервера , предоставляет для совместного использования принтеры, файлы , приложения . Компьютеры- клиенты пользуются ресурсами предоставленными сервером и в сети никогда не выступают в роли сервера. |
3 Организация доступа к данным в приложениях Delphi. Иерархия компонентов доступа и управления данными. Технология разработки приложений баз данных, реализованная в Delphi, характеризуется следующими основными положениями:
Концепция открытых систем, положенная в основу архитектуры среды разработки, обеспечивает реализацию наиболее распространенных механизмов доступа к данным (Universal Data Access, UDA), к которым относятся:
А также для доступа к данным специально разработан процессор баз данных (Borland DataBase Engine, BDE). ODBC, OLE DB и ADO являются промышленными стандартами. BDEэто оригинальная разработка фирмы Borland, предназначенная для использования в программных продуктах фирмы (Paradox, Delphi/C++Builder). Открытые средства связи с базами данных ODBC, представляют собой широко используемый пользовательский интерфейс, который отвечает требованиям стандартов ANSI и ISO, предъявляемых к интерфейсу на уровне обращений к базам данных. OLE DB и ADO являются частью UDA, предназначенного для доступа ко всем источникам данных, в том числе и нереляционным, таким как файловые системы, сообщения электронной почты, многомерные базы данных и другие. Архитектура средств доступа к БД и механизмы его организации приведены на рисунке 1. Состав и структура приложений БД проектируются с учетом общих требований. Во-первых, все компоненты работы с локальными и серверными БД подразделяются на три группы:
Во-вторых, наборы данных и, связанные с ними источники, помещаются в специальный контейнер - модуль данных (Date Module) ), а элементы управления размещаются на формах (строительных площадках окон, входящих в состав пользовательского интерфейса) разрабатываемых приложений. |
|
1 Кибернетический подход к информационной системе как системе управления. Понятие кибернетической системы связано с процессами управления и переработки данных. Процесс управления рассматривается как процесс взаимодействия двух систем – управляющей и управляемой, в которой X – входные параметры о состоянии объектов управления, Y – выходные параметры, по которым судится о том, достигнута ли цель управления. Обратная связь – обеспечивает передачу данных в управляющую систему, по которым судят о рассогласовании цели и получаемых результатов.Управляющие или управленческие воздействия - среда. Процесс управления содержит следующие этапы:
Обязательным элементом любой системы управления является информационная система – это коммуникационная система сбора, передачи, переработки данных об объекте управления. Данная система снабжает работников различного уровня информацией для реализации функций управления. Информационные системы могут быть – прочными, автоматизированными и автоматическими. Данная классификация учитывает пропорции ведения данных между человеком и вычислительным устройством.
ВУ – вычислительное устройство
Если в системе есть человек, то система называется автоматизированной. ИС сама по определению является тоже системой управления. Определение ИС включает:
|
2 Классификация информационных систем По размеру ИС подразделяются на след. группы: одиночные, групповые, корпоративные. Одиночные ИС реализуются на автономном персональном компьютере (сеть не используется).такая система может содержать несколько простых приложений, связанных общим информ.фондом, и рассчитана на работу одного пользователя или группы пользователей, разделяющих по времени одно рабочее место Среди локальных СУБД наиболее известными явл. FoxPro, Paradox, dBase, Access. Групповые ИС ориентированны на коллективное использование информации членами группы и чаще всего строятся на базе локальной выч.сети. при разработке таких приложений используются серверы БД (называемые также SQL-серверами) для рабочих групп. Это – SQL Server, InterBase и т.д. Корпоративные ИС явл.развитием систем для рабочих групп, они ориентированны на крупные компании и могут поддерживать территориально разнесенные узлы или сети. В основном они имеют иерархическую структуру на нескольких уровней. Для таких систем характерна архитектура клиент-сервер со специализацией серверов или же многоуровневая архитектура. Эффективное использование корпоративных ИС позволяет делать более точные прогнозы и избегать возможных ошибок в управлении. Разработка систем автоматизации бух. учета является весьма трудоемкой. Это связано с тем, сто к системам бух.учета предъявляются повышенные требования в отношении надежности и максимальной простоты и удобства в эксплуатации. ИС, решающая задачи оперативного управления предприятием, строится на основе БД, в которой фиксируется вся возможная информация о предприятии. Такая ИС является инструментом для управления бизнесом и обычно называется корпоративной ИС. Различают три основных вида СУБД: промышленные универсального назначения, промышленные специального назначения и разрабатываемые для конкретного заказчика. Специализированные СУБД создаются для управления базами данных конкретного назначения – бухг., складские, банковские. Универсальные СУБД рассчитаны на все случаи жизни, и достаточно сложны и требут от пользователя специальных знаний. Как специализ-ные, так и универсальные относительно дешёвы, отлажены и готовы к немедленной работе, в то время как заказные СУБД требуют существенных затрат, а их подготовка к работе и отладка занимают значительный период. Однако в отличие от промышленных заказные СУБД в максимальной степени учитывают специфику работы заказчика, их интерфейс обычно интуитивно понятен пользователям и не требует от них специальных знаний. |
3 Элементы управления и объекты в СУБД Visual FoxPro В диалоговом окне Create указать имя создаваемой БД. В окне Конструктора БД (Database Designer) и с использованием соответствующей панели инструментов начать описание структуры таблиц. Назначение вкладок Конструктора таблиц: Fields – предназначена для описания атрибутов полей таблицы и правил работы с данными этих полей; Indexes – предназначена для создания или изменения индексов таблиц; Table – предназначена для описания правил работы с данными, хранящимися в таблице. Физический порядок следования полей можно изменить, используя кнопки слева от названия полей. Поля, используемые для индексации, целесообразно располагать наверху списка. В блоке Display указываются атрибуты, связанные с режимом вывода данных поля. Заголовок поля Caption может эффективно использоваться с целью вывода при просмотре полного имени поля (например, в окне Browse, в форме и т.п.) В блоке Field validation определяются правила проверки данных при вводе и редактировании. Например, табельный номер не может быть отрицательным числом и числом больше тысячи. Для задания этого условия необходимо в Rule указать выражение: таб_ном > 0 .and. таб_ном < 1000. В Message (в кавычках) можно определить сообщение об ошибке. Значение по умолчанию, которое автоматически будет присваиваться при добавлении новой записи, можно указать в Default value. Например, в поле, в котором записывается дата и время редактирования записи, в качестве значения по умолчанию можно указать функцию DATETIME(). Тем самым при добавлении в таблицу новой записи в это поле автоматически будет записываться текущая дата и время. Кнопка справа от каждого атрибута в этом блоке вызывает Expression Builder (Рис. 2), с помощью которого можно построить выражение любой степени сложности, использую при этом все доступные функции Visual FoxPro 5.0 (строковые, математические, логические, даты), а также наборы полей активной таблицы и переменные СУБД (глобальные и локальные). В блоке Map field type to classes можно задать для поля класс элемента управления, с помощью которого будут отображаться данные при работе с формой. Такая возможность существенно облегчает процесс разработки пользовательского интерфейса. В блоке Field comment для полей таблицы записывается комментарий, который может пригодиться при разработке или модернизации приложения. Кнопки Insert и Delete предназначены для добавления или удаления полей. Вкладка Indexes Конструктора таблиц позволяет создавать только теги структурного составного индекса. Для создания других видов индексов необходимо использовать соответствующие команды. Для создания связей необходимо выбрать таблицу, которая имеет первичный индекс, удерживая кнопку мыши на нем, переместить указатель мыши на соответствующую таблицу (она должна обязательно содержать индексный тег любого типа по соответствующему полю). В окне Конструктора таблиц созданные связи отображаются визуально, их легко изменить, установить новые, удалить (клавиша Del). |
|
1 Многозвенные информационные системы. Модель распределённого приложения БД называется многозвенной и её наиболее простой вариант – трёхзвенное распределённое приложение. Тремя частями такого приложения являются:
Все они объединены в единое целое единым механизмом взаимодействия (транспортный уровень) и обработки данных (уровень бизнес-логики). Компоненты и объекты Delphi, обеспечивающие разработку многозвенных приложений, объединены общим названием MIDAS. Многозвенная архитектура приложений баз данных вызвана к жизни необходимостью обрабатывать на стороне сервера запросы от большого числа удалённых клиентов. В рамках многозвенной архитектуры “тонкие” клиенты (клиенты, выполняющие минимум операций) представляют собой простейшие приложения, обеспечивающие лишь передачу данных, их локальное кэширование, представление средствами пользовательского интерфейса, редактирование и простейшую обработку. Клиентские приложения обращаются не к серверу БД напрямую, а к специализированному ПО промежуточного слоя. Это может быть и одно звено (простейшая трёхзвенная модель) и более сложная структура. Клиенты многозвенных приложений обеспечивают выполнение следующих функций:
В Delphi многозвенные ИС разрабатываются на основе технологии MIDAS(Multi-tier distributed application services – служба многоуровневых распределённых приложений). Технология Midas включает в себя основные элементы, приведённые ниже. -Удалённый брокер данных (Remote Data Broker) – обеспечивает интерфейс для обмена данными между сервером приложений и клиентом. -Брокер бизнес-объектов (Business Objects Broker) – cсовместно с технологией Borland OLEnterprise позволяет размещать сервер приложений одновременно на нескольких компьютерах. -Брокер ограничений (Constraints Broker) –обеспечивает распределение ограничений, применяемых к данным, между отдельными уровнями ИС. Среда разработки Delphi поддерживает следующие технологии для реализации трехзвенной архитектуры:
Сервер приложений создаётся на основе удалённого модуля данных, который служит для размещения компонентов, а также для обеспечения взаимодействия с сервером и клиентами. Для создания различных серверов приложений предназначены следующие разновидности удалённых модулей данных: RemoteDataModule для технологии DCOM, TCP/IP. MTSDataModule и TCorbaDataModule для MTS и CORBA соответственно. Каждый компонент реализуется как окно - контейнер для помещения в него компонент для работы с БД (TDataBase, TTable, TQuery, TStoredProc). А также, если необходимо, обработчиков событий этих компонентов и объектов полей соответствующих НД. Для каждого компонента источника в модуль помещается компонент TDataSetProvider. Он служит связующим звеном между сервером приложений и клиентским набором данных. Именно к нему привязывается клиентский набор данных, реализуемый компонентом TCientDataSet посредством коммуникационного компонента TXXXConnection. |
2 Получение аналитических показателей близости и адекватности при построении трендов и производственных функций. Независимо от вида и способа построения экономико-математической модели вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т.е. соответствия модели исследуемому процессу или объекту. Так как полного соответствия модели реальному процессу или объекту быть не может, адекватность — в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые считаются существенными для исследования. Трендовая модель ŷt конкретного временного ряда г/( считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента ε=yt-ŷt (t=1, 2. ...,n) удовлетворяла свойствам случайной компоненты временного ряда: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. 3 Объектная модель Visual FoxPro. С версии 3.0 VFP представляет собой принципиально новый продукт в классе СУБД, которая является объектно-ориентированной, визуально программируемой средой, управляемой событиями. Событие - это действие, активизирующее стандартную реакцию объекта. Событие возникает в среде и направлено →объект Объект активизирует соответствующий метод реализации события. 1. Классы. Идентификация объектов. Основой об.-ор. программирования являются классы объектов. Класс содержит информацию об объекте (св-ва об-в) и определяет выполняемые действия. Классы подразделяются на базовые и новые, создаваемые классы. Каждый класс обладает наборами свойств, методов и событий. Базовые классы – это стандартные наборы шаблонов или проект, в к-м описаны хар-ки, определяющие поведение и внешний вид объекта. Описание класса не является исполняемым программным кодом. Представляет собой некоторую структуру, в которой записываются конкретные значения свойств, событий и методов, присущих данному классу. Классы подразделяются на визуальные и не визуальные. Визуальные – это прообразы объектов, созданного пользовательского интерфейса. Не визуальные м/б видны только в момент проектирования на их основе объектов, к-е будут не видны в процессе работы программы. Как правило, объекты визуальных классов создаются и управляются программно с помощью определенных команд и функций. Классы хранятся в библиотеках классов(файл с расширением .VCX). Преимущества работы с классами 1) повышение скорости разработки приложения 2) многократное использование однажды разработанного кода 3) поддержка и модификация нескольких приложений ч/з общие классы. 4) Простая возможность защиты программного кода от изменений. 5) возможность создания подклассов на основе базовых. (Checkbox, Combobox) Объектная модель VFP базируется на об.-ор. парадигме, имеющей в своей основе 3 основных понятия: 1)инкапсуляция 2)полиморфизм 3)наследование |
|
1 Детерминированные автоматы и индикаторы. Обслуживаемая система включает совокупность источников требований и водящего потока требований. Требование -каждый отдельный запрос на выполнение какой-либо работы (на производство услуги). Источник требования - объект (человек, механизм и т.д.), который может послать в обслуживающую систему одновременно только одно требование Обслуживающая система состоит из накопителя и механизма обслуживания. Обслуживанием считается удовлетворение поступившего запроса на выполнение услуги. Механизм обслуживания состоит из нескольких обслуживаюших аппаратов. Обслуживающий аппарат - это часть механизма обслуживания. которая способна удовлетворить одновременно только одно требование (ремонтный рабочий или бригада, кран, экскаватор, пост мойки и т.д.). После окончания обслуживания требования покидают систему, образуя выходящей поток требований. Для моделирования СМОРС должны быть известны четыре ее параметра λ - плотность входящего потока, показывающая среднее число требований, поступающих в СМО в час (параметр загрузки). В те такты времени, когда обслуживающий аппарат будет занят обслуживанием (b>1) и появится сигнал х=1, что означает появление новой заявки, система обслуживания такие заявки должна потерять. Детерминированный автомат. В более сложных автоматных системах присутствуют детерминированные автоматы. Эти автоматы отличаются от вероятностных автоматов тем, что их выходные сигналы совпадают со значениями их внутренних состояний. Для того чтобы построить систему обслуживания с ожиданием необходимо предусмотреть накопитель. В этом случае часть заявок, получивших отказ, могут ожидать обслуживание, оставаясь в накопителе. Пусть накопитель имеет емкость для М заявок. Для
моделирования
накопителя
как раз и служит
детерминированный
автомат D.
Его внутреннее
состояние
можно записать
в таком виде
. Запишем блок-схему функционирования СМО с накопителем: Блок 1 1.1 Если a>1, то а=а-1; х=0 1.2 Если а=1, то а=∆t; х=1 Б Блок 3 В этой блок-схеме в Блоке 2 с помощью символов max и min записаны логические скобки изменения емкости накопителя «не менее» 0 и «не более» М. Выходной сигнал х формирует накопление заявок, которые в обязательном порядке проходят через накопитель. В операторе 3.2 проверка логического условия окончания обслуживания и наличия очередной заявки организована не с помощью выходного сигнала х, как в предыдущем примере, а с помощью выходного сигнала d, детерминированного автомата. Если в накопителе есть хотя бы одна заявка (d>0) и обслуживающий аппарат в следующем такте свободен (b≤1), то автомат В вырабатывает для поступающей из накопителя заявки интервал обслуживания ∆τ. Выдает сигнал у=1, и одновременно уменьшает емкость накопителя на одну единицу. Автоматы индикаторы относятся к детерминированным автоматам, они предназначены для «внешнего» обслуживания системы. С помощью индикаторов формируются выходные характеристики системы. Эти числовые характеристики как правило имеют статистическую природу и получаются на основе использования вероятностных законов больших чисел. При эргодических Марковских процессах, протекающих в системах, когда число состояний системы конечно при достаточно больших интервалах автоматного времени G, формируются вероятностные распределения состояний, а также другие усредненные показатели, такие как среднее число занятых или свободных элементов системы. Пропускные способности, время задержек и т.д. Имитационная модель одноканальной системы массового обслуживания с накопителем и индикатором закона распределения состояний. |
2 Многопроцессорные вычислительные системы В мультипроцессорных компьютерах имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В мультипроцессоре существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Взаимодействие между отдельными процессорами организуется наиболее простым способом - через общую оперативную память. Сам по себе процессорный блок не является законченным компьютером и поэтому не может выполнять программы без остальных блоков мультипроцессорного компьютера - памяти и периферийных устройств. Все периферийные устройства являются для всех процессоров мультипроцессорной системы общими. Территориальную распределенность мультипроцессор не поддерживает - все его блоки располагаются в одном или нескольких близко расположенных конструктивах, как и у обычного компьютера. Основное достоинство мультипроцессора - его высокая производительность, которая достигается за счет параллельной работы нескольких процессоров. Так как при наличии общей памяти взаимодействие процессоров происходит очень быстро, мультипроцессоры могут эффективно выполнять даже приложения с высокой степенью связи по данным. Структура таких компьютеров представлена на рис.
|
3 Аппарат поддержания целостности данных. Триггеры. Для поддержания целостности данных объектно – ориентированный подход предлагает: Автоматическое поддержание отношений наследования Возможность объявить некоторые поля данных как скрытые , такие поля и методы используются только методами самого объекта Создание процедур контроля целостности внутри объекта Операции над данными. Динамические свойства модели выражаются множеством операций над данными. Реализация любой операции включает селекцию данных, т.е. выделение из всей совокупности именно данных, над которыми должна быть выполнена операция. Условия селекции специфицируются в виде некоторого критерия отбора данных. Селекция выполняется любым способом с использованием логической позиции данного в значении и в связи между данными. По характеру действия выделяют следующие виды операций: идентификация данного и нахождение его позиции Выборка данного Запись данного Удаление данного Модификация данного По характеру способа получения результата различают: Навигационные операции Спецификационные операции Способ навигации – результат получения через прохождение по связям, реализованным в БД. Результат навигации – единичный объект БД. Пример: экземпляр записи. Способ спецификации – применяется в том случае, если выдвигаются требования к результату, но не задаётся способ его получения. Т.о. в начале осуществляется селекция требуемых данных, затем вид «операция». Создание триггеров. Типы триггеров. Триггер – специальный механизм для реализации ограничения целостности и позволяющий управлять изменениями в таблицах, имеющих связи. Триггеры м.б. созданы в конструкторе таблиц и использоваться для: Учёта изменений выполняемых с данными Реализации механизма поддержания целостности данных. Триггеры хранятся в хранимых процедурах. Триггеры, созданные через вкладку «таблицы», д.б. написаны разработчиком. Более удобный способ создания триггеров – использование построителя триггеров, к которому можно обратиться через системное меню или контекстное меню на связи между таблицами. Виды триггеров Для каждого отношения можно выбрать тип триггера: - cascade (предполагает изменение данных в дочерней таблице с изменением в родительской); - restrict (запрет на изменение , если есть зависимые записи в дочерней таблице); - ignore (разрешает изменение и допускает появление несвязанных дочерних записей). Эти триггеры работают на update, delete, insert, но insert может работать только с restrict и ignore. Тело триггера при использовании построителя м.б. просмотрено и изменено. При создании отчётов, форм, где используются связанные таблицы , наличие триггеров обязательно. Это упрощает проверки , исключает написание дополнительных процедур и обеспечивает целостность и логику связи. |
|
1 Реляционное исчисление. Грамматика. Переменные-кортежи. Кванторы. Реляционное исчисление – это система обозначений, для определения необходимого отношения в терминах данных отношений. Формулировка запроса в терминах исчисления носит описательный характер, а алгебраическая формулировка – предписывающий. Каждому выражению в алгебре соответствует эквивалентное ему исчисление и наоборот. Реляционное исчисление основано на разделе математической логики, который называется исчислением предикатов. Основным средством исчисления является понятие переменной кортежа. Переменная кортежа – это переменная, которая “изменяется на” некотором отношении, т.е. переменная, допустимые значения которой – кортежи данного отношения. Если переменная кортежа T изменяется в пределах отношения R, то в любое данное время переменная T представляет некоторый кортеж t отношения R. Поэтому рел. исчисление называют исчислением кортежей. Существует альтернативная версия исчисления доменов, где переменные кортежа заменены переменными доменов, т. е. переменными изменяемыми на доменах, а не на отношениях. Переменная кортежа определяется следующим образом: Range of R is x1, x2, …,xn T – определяемая переменная кортежа xi(i=1,2,…,n) – либо имя отношения, либо выражение исчисления кортежей. Если xi – это отношение Ri(i=1,2,…,n), то отношения R1,R2,…,Rn должны д/б совместимы по типу, тогда переменная кортежа T изменяется на объединении этих отношений. Каждый экземпляр переменной в правильно построенной формуле (WFF) является или свободным или связанным. Под экземпляром переменной кортежа в WFF понимают наличие имени переменной в WFF.
Кванторы EXIXSTS – существует одно такое значение переменной x, что вычисление формулы WFF дает значение истина. FORALL – для всех значений переменной x вычисление формулы WFF дается значение истина. Язык как средство связи задачи наблюдателя и объекта характеризуется совокупностью понятий конкретной предметной области (тезаурус) + системы символов или знаков + правила соотношения понятий и знаков и их конструкций. Язык = тезаурус + словарь + грамматика |
2 Процедурный язык для разработки триггеров. Для определения тела триггера используется процедурный язык. В него добавляется возможность доступа к старому и новому значениям столбцов изменяемой записи OLD и NEW - возможность, недоступная при определении тела хранимых процедур. Для написания тела хранимой процедуры применяют особый алгоритмический язык. Объявление локальных переменных. Локальные переменные, если они определены в процедуре, имеют срок жизни от начала выполнения процедуры и до ее окончания. Вне процедуры такие локальные переменные неизвестны, и попытка обращения к ним вызовет ошибку. Локальные переменные используют для хранения промежуточных значений. Формат объявления локальных переменных: DECLARE VARIABLE ; Пример объявления: CREATE PROCEDURE FULL_ADR (TOVARCHIK VARCHAR(20)) RETURNS (GOROD_ADRES VARCHAR(40)) AS DECLARE VARIABLE NAIDEN_POKUPATEL VARCHAR(20); DECLARE VARIABLE MAX_KOLVO INTEGER; BEGIN END Операторные скобки BEGIN... END, во-первых, ограничивают тело процедуры, а во-вторых, могут использоваться для указания границ составного оператора. Под простым оператором понимается единичное разрешенное действие, например: РОК = "Покупатель не указан"; Под составным оператором понимается группа простых или составных операторов, заключенная в операторные скобки BEGIN... END. Оператор присваивания служит для занесения значений в переменные. Его формат: Имя переменной = выражение; где в качестве выражения могут выступать переменные, арифметические и строковые выражения, в которых можно использовать встроенные функции, функции, определенные пользователем, а также генераторы. Пример: OUT_TOVAR = UPPER(TOVAR); Условный оператор IF. . . THEN. . . ELSE имеет такой же формат, как и в Object Pascal: IF () THEN < оператор 1> [ELSE < оператор 2>] В случае, если условие истинно, выполняется оператор 1, если ложно - оператор 2. В отличие от Object Pascal условие должно заключаться в круглые скобки. Оператор SELECT используется в хранимой процедуре для выдачи единичной строки. По сравнению с синтаксисом обычного оператора SELECT в процедурный оператор добавлено предложение INTO :переменная [, переменная...] Оно служит для указания переменных или выходных параметров, в которые должны быть записаны значения, возвращаемые оператором SELECT (те результирующие значения, которые перечисляются после ключевого слова SELECT). Приводимый ниже оператор SELECT возвращает среднее и сумму по столбцу KOLVO и записывает их соответственно в AVG_KOLVO и SUM_KOLVO, которые могут быть как локальными переменными, так и выходными параметрами процедуры. Расчет среднего и суммы по столбцу KOLVO производится только для записей, у которых значение столбца TOVAR совпадает с содержимым IN_TOVAR (входной параметр или локальная переменная). SELECT AVG(KOLVO), SUM(KOLVO) FROM RASHOD WHERE TOVAR = :INJTOVAR INTO :AVG_KOLVO, :SUM_KOLVO; Оператор FOR SELECT ...DO имеет следующий формат: FOR DO < оператор>; Оператор SELECT представляется в расширенном синтаксисе для алгоритмического языка хранимых процедур и триггеров, то есть в нем может присутствовать предложение INTO. Алгоритм работы оператора FOR SELECT. . . DO заключается в следующем. Выполняется оператор SELECT, и для каждой строки полученного результирующего набора данных выполняется оператор, следующий за словом DO. Этим оператором часто бывает SUSPEND (см. ниже), который приводит к возврату выходных параметров в вызывающее приложение. Следующая процедура выдает все расходы конкретного товара, определяемого содержимым входного параметра INJTOVAR. CREATE PROCEDURE RASHOD_TOVARA(IN_TOVAR VARCHAR(20)) RETURNS (OUT_DAT DATE, OUT_POKUP VARCHAR(20), OUT_KOLVO INTEGER) AS BEGIN FOR SELECT DAT_RASH, POKUP, KOLVO FROM RASHOD WHERE TOVAR = :INJTOVAR INTO :OUT_DAT, :OUT_POKUP, :OUT_KOLVO DO SUSPEND; END Рассмотрим логику работы оператора FOR SELECT. .. DO этой процедуры. Сначала выполняется оператор SELECT, который возвращает дату расхода, наименование покупателя и количество расхода товара для каждой записи, у которой столбец TOVAR содержит значение, идентичное значению во входном параметре IN_TOVAR. Указанные значения записываются в выходные параметры (соответственно OUT_DAT, OUTJPOKUP, OUT_KOLVO). Имени параметра в этом случае предшествует двоеточие. После выдачи каждой записи результирующего НД выполняется оператор, следующий за словом DO. В данном случае это оператор SUSPEND. Он возвращает значения выходных параметров вызвавшему приложению и приостанавливает выполнение процедуры до запроса следующей порции выходных параметров от вызывающего приложения. Такая процедура является процедурой выбора, поскольку она может возвращать множественные значения выходных параметров в вызывающее приложение. Обычно запрос к такой хранимой процедуре из вызывающего приложения осуществляется при помощи оператора SELECT, например: SELECT MAX_KOLVO FROM FIND_MAX_KOLVO("Сахар") Оператор WHILE ... DO WHILE () DO < оператор> Алгоритм выполнения оператора: в цикле проверяется выполнение условия; если оно истинно, выполняется оператор. Цикл продолжается до тех пор, пока условие не перестанет выполняться. Рассмотрим процедуру SUM_0_N, которая подсчитывает сумму всех чисел от 0 до числа, определяемого входным параметром N. Вычисление суммы реализовано в цикле с использованием оператора WHILE...DO. CREATE PROCEDURE SUM_0_N (N INTEGER) RETURNS(S INTEGER) AS DECLARE VARIABLE TMP INTEGER; BEGIN S = 0; TMP = 1; WHILE (TMP |
3 Локальные представления – составная часть базы данных. Типы связей в представлениях. Представление – составная часть базы данных. Источники данных для представления. Типы объединения. Передача данных между представлениями и запросами. Представления могут быть: Local View – локальные Remove View – удаленные Источники данных для представления
Представление – составная часть БД. Они позволяют объединить вместе информацию из различных таблиц, БД, свободных таблиц и ранее созданных представлений как локальных так и удаленных. Основное назначения представления Создание набора логически связанных полей для обеспечения максимально удобной работы с данными и обеспечение синхронного изменения данных в представлении и источнике данных, поля из которых включены в представление. Представления в VFP играют роль буфера между пользователем, приложением и данными. В этом случае для приложения нет необходимости определить где физически располагаются данные, в каком формате они хранятся и могут быть созданы. |
|
1 Задача линейного и нелинейного программирования. Уравнение регрессии – ур-ие, связывающее между собой фактор признаки и результативные признаки. Ур-ие регрессии бывают линейные и нелинейные. Сама регрессия бывает парная (зависимость между 1-им фактор признаком и результатом) и множественная. y = y(x) (1) (з. между 1-им ф. признаком и рез-ом) y = a + bx (2)(парная линейная регрессия, т.к. х и у участвуют в 1-ой степени, а и b – параметры регрессии имеющие экономический смысл). Чтобы учесть возникающие помехи (погрешности в уравнении (2)) обычно пишут: у = a + bx + e, где e – искажение модели, учитывающее ряд других фактор признаков не явно участвующих в процессе. Существуют и другого вида регрессии:
Нелинейные задачи математического программирования. Постановка задачи. Найти такой план X=(x1, x2, ..., xn), при котором функция f=f(x1, x2, ..., xn) достигает максимума (минимума) при условии, что переменные x1, x2, ..., xn удовлетворяют дополнительным условиям g1(x1, x2, ..., xn)=0,... , gn(x1, x2, ..., xn)=0. В математическом анализе такая задача, называется задачей на условный экстремум. Она сводится к построению функции Лагранжа F=f(x1, x2, ..., xn)+1g1+2g2+...+mgm, где 1, 2, ..., m – множители Лагранжа. С помощью функции Лагранжа задача на поиск условного экстремума для функции сводится к задаче на поиск безусловного экстремума для функции F. В этом случае вместе с переменными x*1, x*2, ..., x*n доставляющими оптимальное решение всей задачи отыскиваются оптимальные коэффициенты *1, *2, ..., *m, которые определяют оптимальные (теневые) цены (оценки) ограничений. В Microsoft Excel такие задачи решаются с помощью программы Поиск решения. В диалоговом окне Поиск решения после нажатия кнопки Параметры активизируется либо метод Ньютона, либо градиентный метод. Запись функции цели, диапазона искомых переменных и ограничений производится аналогично использованию симплексного метода в категории Линейные задачи (см. предыдущие лабораторные работы). Определение оптимальных значений *1, *2, ..., *m множителей Лагранжа находится параллельно с нахождением оптимальных значений x*1, x*2, ..., x*n плана задачи, и выдается одновременно по окончании решения задачи в отчете по устойчивости. Общая задача нелинейного интервального программирования имеет вид
с
нелинейными
детерминированными
нижними и верхними
граничными
функциями.
Для решения
задач надо
уметь сравнивать
интервальные
значения ее
целевой функции
Когда целевая (производственная) функция и ограничения нелинейные и для поиска точки экстремума нельзя или очень сложно использовать аналитические методы решения, тогда для решения задач оптимизации применяются методы нелинейного программирования. Как правило, при решении задач методами нелинейного программирования используются численные методы с применением ЭВМ. В основном методы нелинейного программирования могут быть охарактеризованы как многошаговые методы или методы последующего улучшения исходного решения. В этих задачах обычно заранее нельзя сказать, какое число шагов гарантирует нахождение оптимального значения с заданной степенью точности. Кроме того, в задачах нелинейного программирования выбор величины шага представляет серьезную проблему, от успешного решения которой во многом зависит эффективность применения того или иного метода. Разнообразие методов решения задач нелинейного программирования как раз и объясняется стремлением найти оптимальное решение за наименьшее число шагов. Большинство методов нелинейного программирования используют идею движения в n-мерном пространстве в направлении оптимума. Линейное программирование (эффективность производства) |
2 Стандартизация в области создания вычислительных систем: характеристика эталонной модели взаимодействия открытых систем. В компьютерных сетях идеологической основой стандартизации является многоуровневый подход к разработке средств сетевого взаимодействия. Именно на основе этого подхода была разработана стандартная семиуровневая модель взаимодействия открытых систем, ставшая своего рода универсальным языком сетевых специалистов. Организация взаимодействия между устройствами в сети является сложной задачей. Как известно, для решения сложных задач используется универсальный прием - декомпозиция, то есть разбиение одной сложной задачи на несколько более простых задач-модулей. Процедура декомпозиции включает в себя четкое определение функций каждого модуля, решающего отдельную задачу, и интерфейсов между ними. В результате достигается логическое упрощение задачи, а кроме того, появляется возможность модификации отдельных модулей без изменения остальной части системы. При декомпозиции часто используют многоуровневый подход. Он заключается в следующем. Все множество модулей разбивают на уровни. Уровни образуют иерархию, то есть имеются вышележащие и нижележащие уровни. Множество модулей, составляющих каждый уровень, сформировано таким образом, что для выполнения своих задач они обращаются с запросами только к модулям непосредственно примыкающего нижележащего уровня. С другой стороны, результаты работы всех модулей, принадлежащих некоторому уровню, могут быть переданы только модулям соседнего вышележащего уровня. Такая иерархическая декомпозиция задачи предполагает четкое определение функции каждого уровня и интерфейсов между уровнями. Интерфейс определяет набор функций, которые нижележащий уровень предоставляет вышележащему. В результате иерархической декомпозиции достигается относительная независимость уровней, а значит, и возможность их легкой замены. 3 Этап машинного проектирования базы данных. Этап машинного проектирования включает разработку пользовательского интерфейса, под которым принято понимать видимые и невидимые компоненты, с помощью которых пользователь взаимодействует с приложением: ввод, корректировка данных, реализация запросов пользователей, распечатка форм, управление последствию действий, архивирование, актуализация данных. Состав: Создание проекта и определение его состава выбор технологии хранения и обработки д-х (локальная, распределенная) создание БД описание структуры таблиц и установление связи м/у ними разработка системы, поддержание целостности д-х разработка схем алгоритмов реализации бизнес – правил (запросов пользователей) реализация запросов пользователей. Выбор средств (sql, языковые конструкций V.F.P) выбор элементов и проектирования интерфейсный части приложения БД (элементы управления типы форм, способы набигаций, цвет, размер, шрифт) Этап машинного проектирования базируется на 2-х основных принципах: Пользователи могут участвовать в разработке концепции интерфейса; Пользователь может и должен управлять диалогом. |
|
1Одноканальная система массового обслуживания с накопителем, многоканальная система массового обслуживания с накопителем. Р 3.1 Если b>1, то b=b-1 и y=0 3.2 Если (b≤1)∩d>0, то b=∆τi ; y=1; d=d-1 3.3 Если (b≤1)∩d=0, то b=0 и y=1 ассмотрим общую схему системы массового обслуживания для разомкнутых смешанных систем. Она состоит из обслуживающей и обслуживаемой систем. Обслуживаемая система включает совокупность источников требований и водящего потока требований. Требование -каждый отдельный запрос на выполнение какой-либо работы (на производство услуги). Источник требования - объект (человек, механизм и т.д.), который может послать в обслуживающую систему одновременно только одно требование Обслуживающая система состоит из накопителя и механизма обслуживания. Обслуживанием считается удовлетворение поступившего запроса на выполнение услуги. Механизм обслуживания состоит из нескольких обслуживаюших аппаратов. Обслуживающий аппарат - это часть механизма обслуживания. которая способна удовлетворить одновременно только одно требование (ремонтный рабочий или бригада, кран, экскаватор, пост мойки и т.д.). После окончания обслуживания требования покидают систему, образуя выходящей поток требований. Для моделирования СМОРС должны быть известны четыре ее параметра λ - плотность входящего потока, показывающая среднее число требований, поступающих в СМО в час (параметр загрузки). Поток заявок простейший. μ -среднее число заявок обслуживаемых одним аппаратом в час (параметр разгрузки). Распределение интервалов обслуживания подчиняется показательному распределению N - чисто обслуживающих аппаратов. Будем полагать, что аппараты имеют одинаковую производительность обслуживания μ требований/час. М - максимальное число требований, которое может быть размещено в накопителе при ожидании обслуживания. Будем считать, что если очередное требований поступающее в СМО в состоянии, когда буду т заняты все аппараты и все места в накопителе то требовании получает отказ в обслуживании и покидает систему массового обслуживания не обслуженным. В системе массового обслуживания постоянно протекают два случайные процесса: - процесс загрузки обуотовтенный параметром λ - процесс разгрузки обуотовтенный параметром μ В результате чего СМО меняет свои состояния Для расчета вероятностей состояний используется формула связывающая вероятности двух соседних состояний из графа состояний по следующему правилу: вероятность Рi равна вероятности предыдущего состояния Рi-1 умноженной на отношение показателя загрузки к показателю разгрузки Si-1 состояния.
Все вероятности связаны между собой, поэтому выразим их через Ро
Воспользуемся формулой:
Получим уравнение с одним неизвестным Ро. из которого и определим
1.1 Если a>1, то а=а-1 и х=0 1.2 Если а=1, то а=∆t и х=1 (5) |
2 Технологии проектирования многозвенных информационных систем. Модель распределённого приложения БД называется многозвенной и её наиболее простой вариант – трёхзвенное распределённое приложение. Тремя частями такого приложения являются:
Все они объединены в единое целое единым механизмом взаимодействия (транспортный уровень) и обработки данных (уровень бизнес-логики). Компоненты и объекты Delphi, обеспечивающие разработку многозвенных приложений, объединены общим названием MIDAS. Многозвенная архитектура приложений баз данных вызвана к жизни необходимостью обрабатывать на стороне сервера запросы от большого числа удалённых клиентов. В рамках многозвенной архитектуры “тонкие” клиенты (клиенты, выполняющие минимум операций) представляют собой простейшие приложения, обеспечивающие лишь передачу данных, их локальное кэширование, представление средствами пользовательского интерфейса, редактирование и простейшую обработку. Клиентские приложения обращаются не к серверу БД напрямую, а к специализированному ПО промежуточного слоя. Это может быть и одно звено (простейшая трёхзвенная модель) и более сложная структура. Клиенты многозвенных приложений обеспечивают выполнение следующих функций: соединение с сервером приложений, приём и передача данных, отображение средствами пользовательского интерфейса, простейшие операции редактирования, сохранение локальных копий данных. В Delphi многозвенные ИС разрабатываются на основе технологии MIDAS(Multi-tier distributed application services – служба многоуровневых распределённых приложений). Технология Midas включает в себя основные элементы, приведённые ниже. -Удалённый брокер данных (Remote Data Broker) – обеспечивает интерфейс для обмена данными между сервером приложений и клиентом. -Брокер бизнес-объектов (Business Objects Broker) – cсовместно с технологией Borland OLEnterprise позволяет размещать сервер приложений одновременно на нескольких компьютерах. -Брокер ограничений (Constraints Broker) –обеспечивает распределение ограничений, применяемых к данным, между отдельными уровнями ИС. Среда разработки Delphi поддерживает следующие технологии для реализации трехзвенной архитектуры:
Сервер приложений создаётся на основе удалённого модуля данных, который служит для размещения компонентов, а также для обеспечения взаимодействия с сервером и клиентами. Для создания различных серверов приложений предназначены следующие разновидности удалённых модулей данных: RemoteDataModule для технологии DCOM, TCP/IP. MTSDataModule и TCorbaDataModule для MTS и CORBA соответственно. Каждый компонент реализуется как окно - контейнер для помещения в него компонент для работы с БД (TDataBase, TTable, TQuery, TStoredProc). А также, если необходимо, обработчиков событий этих компонентов и объектов полей соответствующих НД. Для каждого компонента источника в модуль помещается компонент TDataSetProvider. Он служит связующим звеном между сервером приложений и клиентским набором данных. Именно к нему привязывается клиентский набор данных, реализуемый компонентом TCientDataSet посредством коммуникационного компонента TXXXConnection. |
3 Установление связей между таблицами. Типы связей, поддерживаемые СУБД Visual FoxPro. Установление связей между таблицами. 1 визуально в конструкторе БД от ключа
TN Prim TN Regul Визуальные связи используется: а) для отображения ER модели в машинном представлении; в) используется при создании представлений Local View 2 В диалоговом окне DataSession. Установление связей осуществляется в Конструкторе таблиц. Обязательным условием установления связей между таблицами является наличие ранее созданных индексных тегов. Для создания связей необходимо выбрать таблицу, которая имеет первичный индекс, удерживая кнопку мыши на нем, переместить указатель мыши на соответствующую таблицу (она должна обязательно содержать индексный тег любого типа по соответствующему полю). В окне Конструктора таблиц созданные связи отображаются визуально, их легко изменить, установить новые, удалить (клавиша Del). |
|
1 Аксиомы системного анализа. Аксиомы системного анализа
|
2 Трехзвенная архитектура информационных систем Трехуровневая (распределенная) архитектура включает в себя сервер, приложения-клиенты, сервер приложений. Сервер приложений является промежуточным уровнем, обеспечивающим организацию взаимодействия клиентов и сервера, например выполнение соединения с сервером, разграничение доступа к данным и реализацию бизнес-правил. Сервер приложений реализует работу с клиентами, расположенными на различных платформах, т.е. функционирующими на компьютерах различных типов и под управлением различных ОС. Основные достоинства 3-х звенной архитектуры клиент-сервер:
Технологии программной реализации трехзвенной ИС в Delphi. Поскольку в трехзвенной архитектуре клиент и сервер приложений в общем случае располагается на разных машинах, связь клиента с сервером приложений реализуется с помощью той или иной технологии удаленного доступа: Модель DCOM позволяет использовать объекты, расположенные на другом компьютере. ОС Windows NT Server или Windows 2000 Server Сервер MTS (сервер транзакций Microsoft)- дополнения к технологии COM, и предназначенная для управления транзакциями. По сравнению с DCOM, MTS обеспечивает следующие дополнительные возможности:
Модель СОМ+ (усовершенствованная объектная модель компонентов) фирмы Microsoft введена в Windows2000 и интегрирует технологии MTS в стандартные службы COM. Сокеты TCP/IP (транспортный протокол/ протокол Интернета) используется для соединения компьютеров в различных сетях, в том числе в Интернете. CORBA (общедоступная архитектура с брокером- (сервер приложений) при запросе объекта) позволяет организовать взаимодействие между объектами, расположенными на различных платформах. SOAP ( простой протокол доступа к объектам) служит универсальным средством обеспечения взаимодействия с клиентами и серверами Web-служб на основе кодирования XML и передачи данных по протоколу HTTP. Главные особенности трехуровнего приложения связаны с созданием сервера приложений и клиентского приложения, а также с организацией взаимодействия между ними. Для разработки многоуровневых приложений в Delphi используются удаленные модули данных и компоненты, размещенные на странице DataSnap палитры компонентов. |
3 Обзор языка программирования в СУБД Visual FoxPro Visual FoxPro отличается высокой скоростью, имеет встроенный объектно-ориентированный язык программирования с использованием DBase и SQL, диалекты которых встроены во многие СУБД. Имеет высокий уровень объектной модели. Объектно-ориентированное программирование - это методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования. Основой об.-ор. программирования являются классы объектов. Класс содержит информацию об объекте (св-ва об-в) и определяет выполняемые действия. Классы подразделяются на базовые и новые, создаваемые классы. Каждый класс обладает наборами свойств, методов и событий. Команды и функции объектно-ориентированного программирования Для создания объекта используется функция Createobject (имя класса [,параметр 1, параметр 2,…]). Данная функция возвращает идентификатор созданного объекта, который понадобится для определения свойств объекта, а также выполнения над ними действия. Для получения полной информации о всех активных объектах и значениях их свойств и методов, можно использовать команду Display Objects, которая имеет синтаксис:Устанавливать свойства объектов (или определенной группы объектов) можно с помощью With … Endwith Команда Mouse позволяет программным путем имитировать события Click, Double Click, MouseMove, DragDrop Любая ИС может считаться эффективной если выборка данных осуществляется быстро, качественно и в требуемом объёме. Наиболее эффективным решением этой проблемы является возможность построения запросов средствами команд SQL. Язык SQL в отличии от существующих команд языка СУБД является множественно-ориентированным языком и направлен на получение готовых таблиц с результатами запроса. Особенности SQL: команда SQL работает с данными на уровне машинного представления поэтому скорость обработки возрастает в сотни раз по сравнению с традиционными командами СУБД. Ком. SQL самостоятельно выполняют создание индексов и ключей при необходимости, это экономит место на диске и затраты ресурсов на поддержание целостности структуры индексов. Каждая СУБД имеет свой собственный диалект по SQL, который отличается полнотой поддержки стандарта и некоторыми незначительными отличиями синтаксиса. Для построения запроса в диалоговом режиме может быть использован конструктор запросов. Где генерируется тело команды SQL и создаётся файл с .qpr. Этот файл можно выполнить используя команду DO имя запроса .QPR. Сгенерировать код команды SQL возможно также в дизайнере представлений, однако в том и другом случае в дизайнерах не могут быть реализованы все сложные синтаксические конструкции SQL , поэтому один з вариантов может быть следующим: в конструкторе создаётся тело SQL и вручную дополняются тонкие настройки. Обобщённый алгоритм построения запроса
Описание полей данных в результате
Список источников данных Условия
связи между
разл *Усл.
от
*Усл. Суммирования данных *Задание порядка записей в результате * - необязательные блоки алгоритма Т.о Select SQL является наиболее мощной и удобной командой для получения выборок. Позволяет выполнить запрос к одной или более таблицам, направляя при этом результат в курсор или таблицу, в график, на принтер. Команда Select SQL поддерживает функции агрегирования. |
|
1 Архитектура и структура информационных систем.
Имеется компьютер с базами данных, процессором баз данных (BDE) и клиентским Delphi-приложением, имеющим доступ к базам данных через SQL-запросы и BDE. 2. Файл – серверная Состав (На сервере БД, на клиентской машине BDE и клиентское приложение. Целостность БД обеспечивается клиентским приложением) Имеется компьютер с сервером баз данных. На компьютере пользователя находятся процессор баз данных (BDE) и клиентское Delphi-приложение, имеющее доступ к серверным базам данных через SQL-запросы и BDE. 3. Клиент – серверная (2-х звенная). На сервере расположена БД и СУБД. Там же обеспечивается разграничение прав пользователей, поддержание целостности БД. На клиентской машине расположено BDE и клиентское приложение. 4. 3-х звенная (Распределенная)(На сервере расположены: БД, сервер БД, BDE, сервер приложений – на клиентской машине - клиентское приложение Internet Explorer). Имеется компьютер с сервером баз данных. Имеется компьютер с сервером приложений и процессором баз данных (BDE). На компьютере пользователя находится клиентское Delphi-приложение, имеющее доступ к серверным базам данных через SQL-запросы, реализуемые наборами данных сервера приложений. Архитектура файл-сервер не имеет сетевого разделения компонентов диалога PS (Средства представления) и PL (Логика представления) и использует компьютер для ф-ций отображения, что облегчает построение графического интерфейса. Файл –сервер только извлекает данные из файлов, так что дополнительные пользователи и приложения добавляют лишь незначительную нагрузку на центр. процессор. Объектами разработки в файл-серверном приложении явл. компоненты приложения, определяющие логику диалога PL, а также логику обработки BL и управления данными DL разработанное приложение реализуется либо в виде законченного загрузочного модуля, либо в виде специального кода для интерпретации. Недостатки: при выполнении некоторых запросов к базе данных клиенту могут передаваться большие объемы данных, загружая сеть и приводя к непредсказуемости времени реакции. Архитектура клиент-сервер предназначена для разрешения проблем файл-серверных приложений путем разделения компонентов приложения и размещения их там, где они будут функционировать наиболее эффективно. Особенностью архитектуры клиент-сервер является использование выделенных серверов БД, понимающих запросы на языке структурированных запросов SQL и выполняющих поиск, сортировку и агрегирование информации. Отличительная черта серверов БД-наличие справочника данных, в котором записана структура БД, ограничения целостности данных, форматы и даже серверные процедуры обработки данных по вызову или по событиям в программе. Объектами разработки в таких приложениях помимо диалога и логики обработки являются, прежде всего, реляционная модель данных и связанный с ней набор SQL –операторов для типовых запросов к БД. Многоуровневая архитектура стала развитием архитектуры клиент-сервер и в своей классической форме состоит из 3 уровней: -нижний уровень представляет собой приложения клиентов, выделенные для выполнения функций и логики представлений PS и PL и имеющие программный интерфейс для вызова приложения на среднем уровне; - средний уровень представляет собой сервер приложений, на котором выполняется прикладная логика BL и с которого логика обработки данных DLвызывает операции с базой данных DS; - верхний уровень представляет собой удаленный специализированный сервер БД, выделенный для услуг обработки данных DS и файловых операций FS (без риска использования хранимых процедур). |
2 Определение и основные типы типологий локальных вычислительных сетей. Топология сети – Схема, включающая узлы сети и соединения между ними. В настоящее время доминируют 3 сетевые топологии – шинная, звездообразная и кольцевая. Шинная- каждый узел подсоединяется к единому сетевому кабелю называемому шиной . На каждый конец шины устанавливается устройство (terminator) которое не позволяет отражаться данным в шину и вызывать ошибки. Звездообразная – каждый узел подсоединяется к центральному устройству известному как концентратор (hub). Кольцевая – непрерывное кольцо узлов. Как правило, каждый узел при этом непосредственно соединяется с двумя соседними узлами. Иными словами кольцо это замкнутая шина, оба конца соединены между собой 3 Производственные функции как инструменты управления производственными процессами Любой производственный процесс представляет собой технологию (набор технологий) для «переработки» ресурсов в готовую продукцию. Ресурсы (средства, запасы, источники средств). Приобретение ресурсов связано с затратами. Применительно к реальному производству под затратами можно понимать: расход денежных средств на приобретение сырья, оплата труда персоналу, налоговые отчисления. Одна из задач определение доли каждого из видов затрат в готовой продукции. Результатом моделирования является производственная функция, устанавливающая влияние каждого из видов производственных затрат на выпуск готовой продукции. При моделировании используется регрессионный метод, суть которого заключается в том, что делается попытка математического описания реального явления по его результатам или проявлениям. Ур-ие искомой функции имеет вид: У=а0+а1х1+…аnхn, где У стоимость готовой продукции, а0 -денежное выражение постоянно присутствующих, не изменяющихся затрат (начальный капитал, земельный налог, амортизационные отчисления и т.п.) а1..аn денежное выражение единицы соответствующего вида затрат х1..хn. В результате решения задачи должны получиться числовые значения коэф.а0…аn. Процесс моделирования базируется на исходных данных, полученных в рез-те нескольких наблюдений за производственным процессом. |
|
1 Дерево целей, дерево критериев, дерево проблем Для достижения ряда практических целей достаточно модели черного ящика или модели состава. Однако есть вопросы, решить которые таким методом невозможно. Необходимо правильно соединить эл-ты между собой или установить между ними информационные связи. Структура системы - совокупность необходимых и достаточных для достижения цели отношений между элементами.При рассмотрении некоторой совокупности объектов подсистемы в модель структуры, то есть в список отношений включается конечное число связей, на наш взгляд наиболее значимых для достижения цели. Связь между понятиями «отношение» и «свойство»: В отношении участвует не менее 2-х объектов, а свойством мы называем некий атрибут одного объекта. Пусть Е – любое свойство, которым может обладать элемент х € Е (элемент х прин-т св-ву Е) , задано некое подмножество А € Е всех эл-тов, обладающих этим св-вом Содержательная связь между свойством и отношением: - любое свойство объекта проявляется в процессе взаимодействия с другими объектами, то есть в результате установления какого-либо отношения; - можно утверждать, что свойство – свернутое отношение, а если использовать понятие модели, то свойство – это модель отношения. СИСТЕМА – совокупность взаимосвязанных элементов, обособленная от среды и взаимодействующая с ней как единое целое. Это определение охватывает модели черного ящика, состава и структуры. Все вместе они образуют модель – структурная схема системы. Все структурные схемы – это схемы, в которых обозначается только наличие элементов и связей между ними, а также разница между элементами и связями. Такая схема называется графом. Наиболее распространенным способом представления целей является иерархическая структура – «Дерево целей», основные закономерности построения которого: 1) Приемы, применяемые при построении: - формирование сверху - методы декомпозиции и целенаправленный подход - формирование снизу – метод языка системы. 2) в иерархической структуре цели нижних уровней всегда можно рассматривать как средство для достижения цели вышележащего уровня. 3) По мере перехода цели с верхнего уровня на нижние верхняя цель - направление переходит в нижнюю – ожидание результатов конкретной работы с указанием критерием их оценки. 4) на практике ограничивается развертывание общей цели до 5-7 уровней 5) Любую цель или подцель можно представить различными иерархическими структурами. 6) Требования к структуре цели: - На каждом уровне деление соразмерно и ветви по возможности конечны и независимы. Для наглядности рекомендуется на каждом уровне иерархии количество подчиненных ветвей не более 9, а так же не более 9 уровней во всем дереве. При применении дерева для определения и уточнения функций управления говорят о дереве «целей и функций». При стр. цели тематики пользуются термином «дерево проблем». При использовании метода ”дерево целей” (Метод, направленный на активизацию использования интуиции и опыта спец-ов ) в качестве следствия принятия решения часто выводится термин «дерево решений». При применении дерева для выявления и уточнения функций управления говорят о дереве цели и функции. При структуризации тематики научно-исследовательской организации удобнее пользоваться термином «дерево проблем», а при прогнозах – «дерево направления развития» или «прогноз данных». Метод «дерево цели» ориентирован на получение полной, относительно устойчивой структуры, которая на протяжении какого-то периода времени мало изменялась при неизбежном изменении, происходящем в любой развивающейся системе. |
2 Назначение и преимущества использования механизма хранимых процедур при разработке многозвенных информационных систем Хранимые процедуры представляют собой группы связанных операторов SQL. Использование ХП обеспечивает дополнительную гибкость при работе с БД, т.к. выполнить хранимую процедуру обычно гораздо проще, чем последовательность отдельных операторов SQL.ХП могут получать входные параметры, возвращать значения приложению и могут быть вызваны явно из приложения или подстановкой вместо имени таблицы в инструкции SELECT. Основные преимущества, которые дает использование ХП, заключается в следующем: - ХП процедуры позволяют внести часть логики на сервер БД. Это ослабляет зависимость БД ИС от клиентской части; - ХП обеспечивают модульность проекта: они могут быть общими для клиентских приложений, которые обращаются к одной и той же БД, что позволяет избегать повторяющегося кода и уменьшает размер приложений; - ХП упрощают сопровождение приложений: при обновлении процедур изменения автоматически отражаются во всех приложениях, которые их используют, без необходимости повторной компиляции и сборки; - ХП повышают эффективность работы ИС: они выполняются сервером, а не клиентом, что снижает сетевой трафик; - скорость выполнения ХП выше, чем для последовательности отдельных операторов SQL. Это связано с тем, что ХП хранятся на сервере в откомпилированном виде. |
3 Организация и обработка данных в СУБД Visual FoxPro VFP система организации данных, наиболее близка к теоретическим основам реляционной модели и позволяет выполнять операции реляционной алгебры.
Сх. хранения и работа с данными Основная таб. DBF входит в состав DBC. Все таб. Объединяются в БД DBC. Кол-во таб. В DBC неограниченная. Организация и хранения в таком виде позволяет выполнить следующее: - все связи установленные м/у полями отдельных таб. - правило проверки которое будет определить реакцию системы на внесение., добавление, удаление. - правило проверки целостность данных - запросы QPR используются для хранения выборки данных из БД или свободных таб. Свободные таб. DBF не входят в состав БД, работают локально, могут быть использованы одновременно несколь-ми БД, которые используются в приложениях. Вкл. их в БД загромождает её. В состав БД на ряду с таб. входят: Локальные представления – это сохраненный запрос к результатам которого доступ осуществ-я как к таб. В состав локал. предст. могут входить данные таб. БД и ранее созданные. Представление удобно ипольз-ть с формами и учетами. Хранимые проц. – это спец. образом организованный программ. код отвечающий за реализацию проверок вопросах целостности данных, правил проверки атрибутов и др. Соединение. В VFP предусмотрено использование технологии OLE autom. Для этого необходимо создать соединение для работы с др. формами. Эта ед. хранения находится в DBC. Используется для SQL сквозных запросов. В БД хранение внешнее представление. Их работа аналогична локал new, однако используется на др. форматах. Т.о. БД VFP это основной элемент БД, который помимо формирования структур данных выполняет функции словаря данных за счет подержания следующих функций: 1. Допустимая длина имени таб. с использованием кириллицы. Однако при работе SQL (локал. или внеш.) представлены и др. операции выполняемые некорректно, в этой связи рационально использовать в именах полей латиницу. 2. Каждому полю можно задавать комментарий. Для каждого поля можно использовать заголовок. Правило проверки при вводе и изменения. Для каждого поля можно устанавливать класс на основе которого будет создаваться объект в форме для работы с данными хранения в этом поле. Используют триггеры для поддержки целостности данных. Устанавливаются постоянные связи м/у таб. БД 3. Имеются процедуры для описания сложных условий, правил, проверки. 4. Возможность использование соединений для связи с внешними источниками данных. |
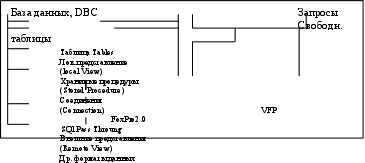
|
1 Функциональная и обеспечивающая подсистемы информационной системы. Состав информационной системы. Функциональная часть – описание задач Обеспечивающая часть – аппаратное и программное обеспечение ФЧ фактически является моделью системы управления объектом. Состав подсистем ФЧ определяется признаком декомпозиции. Из- за многофункциональности ЭИС может быть декомпозирована по разным признакам. Признаком структуризации могут служить функции управления объектом. ЭИС состоит из функциональных подсистем. Это не всегда удовлетворяет проектировщиков ЭИС. Поэтому разработаны и другие системы управления, используемые, как правило, в комбинации с функциональным признаком. Это: уровень управления (высший, средний, оперативный); вид управляемого ресурса (основные фонды, материальные, трудовые, финансовые и информационные ресурсы); сфера применения (банковские …); функции управления и период управления. Выбор признаков декомпозиции ИС зависит от специфики объекта управления и целей ее создания. Трансформация целей управления в функции, а функций – в подсистемы ИС позволяет проводить дальнейшую декомпозицию. Каждую подсистему можно делить на подфункции или задачи (комплексы задач). Обеспечивающая часть:
Администраторы - администрирование серверов информационной системы — информационного сервера, сервера базы данных и, наконец, операционной системы и сети. Функциональные обязанности: предотвращение и устранение последствий нештатных ситуаций; обучение пользователей; управление пользовательскими учетными записями, учетными записями групп; конфигурирование и обслуживание пользовательских настольных систем; резервное копирование данных, анализ производительности, обеспечение защиты; обслуживание аппаратных и программных средств сервера и сети; резервное копирование и восстановление данных; планирование действий в аварийных ситуациях; планирование расширения системы. Операторы - эксплуатация операторских рабочих мест, то есть в своевременном заполнении локальных баз данных первичными данными с соблюдением всех правил и отсылки отчетов на сервер согласно графику, составленному администратором. Пользователи - Выделением прав доступа пользователя к информационной системе занимается администратор. В общем можно лишь сказать, что пользователь не может иметь доступа к хранящимся на сервере базы данных первичным данным.
И другие виды обеспечения (например, лингвистическое). |
2 Имитационное моделирование простейших систем массового обслуживания. Для моделирования СМО должны быть известны 4 ее параметра λ-плотность вводящего потока, показывающая среднее чисто требований, поступающих в СМО в час (параметр загрузки). Поток заявок простейшкй μ-среднее число заявок, обслуживаемых одним аппаратом в час (пар-р загрузки). Распределение интервалов обслуживания подчиняется показательному распределению. N-число обслуж. аппаратов. Будем полагать что аппараты имеют одинаковую производительность обслуживания μ требований в час. М - максимальное число требований, которое может быть размещено в накопителе при ожидании обслуживания. Будем считать, что если очередное требование, поступающее в СМО в состоянии, когда будут заняты все аппараты и все места в накопителе то требование получает отказ в обслуживании и покидает СМО не обслуженным. В СМО постоянно протекают 2 случайных процесса: процесс загрузки, обусловленный параметром λ и процесс разгрузи, обуслов. параметром μ. В рез-те СМО имеет свои состояния. Опишем и обозначим эти состояния. S0-состояние когда в СМО нет ни одного требования, накопитель свободен, аппараты свободны, S1-когда а в СМ О одно требование, один аппарат занят, накопитель свободен, S2-в системе 2 требования, SN -в системе N требований, все аппараты загружены, накопитель свободен, SN+1|-в системе N+1 требований, все аппараты замяты, одно место в накопителе занято, SN+M—в системе N+М требований, все аппараты заняты, накопитель полностью загружен. В простейших системах, когда заявки поступают на обслуживание по одной и также после обслуживания по одной покидают. Смо, все состояния можно выстроить в одну динамическую цепочку, что удобно изобразить графически. К Хар-ки СМО. Средняя длина оч ф,еци ТМ=M0P0+M1P1+...+MnPn где Mn -количество занятых мест в накопителе в каждом из состояний S0Sn. Вероятность отказа очередному клиенту определяется как вероятность максимально загруженного состояния системы. Относительная пропускная способность ОПС=1-Ротк . Абсолютный отказ (заявок/час) А0=λ Ротк Абсолютная пропускная способность (заявок/час) АПС= Ротк *ОПС. Среднее время ожидания в накопителе (час) WМ:=ТМ/АПС. Среднее время нахождения заявки в СМО (ч ас) WS=WM+1/μ. Средняя длина очереди мастеров ТМ=N0P0+N1P1+...+NnPn Среднее число занятых мастеров ZN=N-TN. Среднее суммарное число заявок в СМО ТS=ТМ+ZК |
3 Конструкции языка SQL. Любая ИС может считаться эффективной если выборка данных осуществляется быстро, качественно и в требуемом объёме. Наиболее эффективным решением этой проблемы является возможность построения запросов средствами команд SQL. Язык SQL в отличии от существующих команд языка СУБД является множественно-ориентированным языком и направлен на получение готовых таблиц с результатами запроса. Особенности SQL: команда SQL работает с данными на уровне машинного представления поэтому скорость обработки возрастает в сотни раз по сравнению с традиционными командами СУБД. Ком. SQL самостоятельно выполняют создание индексов и ключей при необходимости, это экономит место на диске и затраты ресурсов на поддержание целостности структуры индексов. Каждая СУБД имеет свой собственный диалект по SQL, который отличается полнотой поддержки стандарта и некоторыми незначительными отличиями синтаксиса. Для построения запроса в диалоговом режиме может быть использован конструктор запросов. Где генерируется тело команды SQL и создаётся файл с .qpr. Этот файл можно выполнить используя команду DO имя запроса .QPR. Сгенерировать код команды SQL возможно также в дизайнере представлений, однако в том и другом случае в дизайнерах не могут быть реализованы все сложные синтаксические конструкции SQL , поэтому один из вариантов может быть следующим: в конструкторе создаётся тело SQL и вручную дополняются тонкие настройки. Обобщённый алгоритм построения запроса ---- Описание полей данных в результате---- Список источников данных----Условия связи между различными источниками данных----*Усл. отбора данных-----*Усл. Суммирования данных *Задание порядка записей в результате * - необязательные блоки алгоритма Т.о Select SQL является наиболее мощной и удобной командой для получения выборок. Позволяет выполнить запрос к одной или более таблицам, направляя при этом результат в курсор или таблицу, в график, на принтер. Команда Select SQL поддерживает функции агрегирования. |

|
1 Краткосрочное прогнозирование. Доверительный интервал. Для осуществления прогноза на несколько шагов вперед достаточно взять очередные значения аргумента: t = n+ l,n + 2,..., n+i,... , где i = 1,2,... - номера шагов прогноза, и произвести экстраполяцию тренда
Получим
так называемые
точки прогноза
(точечный прогноз)
Исследования показали, что возможные расширения случайной зоны можно измерить с помощью специального коэффициента K(i), где i - номер шаг; прогноза. Такой коэффициент рассчитан дли наиболее популярных трендов . Линии тренда позволяют графически отображать тенденции данных и прогнозировать их дальнейшие изменения. Подобный анализ называется также регрессионным анализом (регрессионный анализ – форма статистического анализа, используемого для прогнозов; Регрессионный анализ позволяет оценить степень связи между переменными, предлагая механизм вычисления предполагаемого значения переменной из нескольких уже известных значений.). Используя регрессионный анализ, можно продлить линию тренда в диаграмме за пределы реальных данных для предсказания будущих значений. Скользящее среднее. Можно вычислить скользящее среднее (скользящее среднее – последовательность средних значений, вычисленных по частям рядов данных; На диаграмме линия, построенная по точкам скользящего среднего, позволяет построить сглаженную кривую, более ясно показывающую закономерность в развитии данных.), которое сглаживает отклонения в данных и более четко показывает форму линии тренда. Точность аппроксимации. Линия тренда в наибольшей степени приближается к представленной на диаграмме зависимости, если значение R-квадрат (значение R в квадрате – число от 0 до 1, которое отражает близость значений линии тренда к фактическим данным; линия тренда наиболее соответствует действительности, когда значение R в квадрате близко к 1; оно также называется квадратом смешанной корреляции) равно или близко к 1. При аппроксимации данных с помощью линии тренда в Microsoft Excel значение R-квадрат рассчитывается автоматически. ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ - вероятность, с которой можно утверждать, что ошибка выборки не превысит некоторую заданную величину, называют доверительной вероятностью. Обычно в социальных и маркетинговых исследованиях значения доверительной вероятности принимают равным 95%. Пределы, в которых с доверительной вероятностью может находиться значение характеристики генеральной совокупности, называют доверительным интервалом. |
2 Параллельные вычислительные системы. Многомашинные вычислительные системы. Многомашинная система - это вычислительный комплекс, включающий в себя несколько компьютеров (каждый из которых работает под управлением собственной операционной системы), а также программные и аппаратные средства связи компьютеров, которые обеспечивают работу всех компьютеров комплекса как единого целого. Работа любой многомашинной системы определяется двумя главными компонентами: 1. высокоскоростным механизмом связи процессоров 2. системным программным обеспечением, которое предоставляет пользователям и приложениям прозрачный доступ к ресурсам всех компьютеров, входящих в комплекс. В состав средств связи входят программные модули, которые занимаются распределением вычислительной нагрузки, синхронизацией вычислений и реконфигурацией системы. Если происходит отказ одного из компьютеров комплекса, его задачи могут быть автоматически переназначены и выполнены на другом компьютере. Если в состав многомашинной системы входят несколько контроллеров внешних устройств, то в случае отказа одного из них, другие контроллеры автоматически подхватывают его работу. Таким образом, достигается высокая отказоустойчивость комплекса в целом. Помимо повышения отказоустойчивости, многомашинные системы позволяют достичь высокой производительности за счет организации параллельных вычислений. По сравнению с мультипроцессорными системами возможности параллельной обработки в многомашинных системах ограничены: эффективность распараллеливания резко снижается, если параллельно выполняемые задачи тесно связаны между собой по данным. Это объясняется тем, что связь между компьютерами многомашинной системы менее тесная, чем между процессорами в мультипроцессорной системе, так как основной обмен данными осуществляется через общие многовходовые периферийные устройства. Территориальная распределенность в многомашинных комплексах не обеспечивается, так как расстояния между компьютерами определяются длиной связи между процессорным блоком и дисковой подсистемой. Кластер - многомашинная вычислительная система, представляющая совокупность относительно автономных систем с общей дисковой памятью (общей файловой системой), средствами межмашинного взаимодействия и поддержания целостности баз данных. Использование кластеров увеличивает производительность и надежность системы, так как в случае сбоя одного компьютера его работу берет на себя другой, т. е. с точки зрения пользователя кластер выглядит как единая система. При работе на параллельных ЭВМ пользователь имеет возможность запускать программу или на всех процессорах сразу, или на ограниченном их числе. Поскольку все процессоры в параллельных ЭВМ одинаковые (в составе параллельной ЭВМ могут работать еще и специализированные процессоры ввода/вывода, но на них счет не проводится), то можно ожидать, что программа будет выполняться во столько раз быстрее, сколько процессоров будут проводить вычисления. 3 Команды и функции объектно-ориентированного программирования в Visual FoxPro Для создания объекта используется функция Createobject (имя класса [,параметр 1, параметр 2,…]). Данная функция возвращает идентификатор созданного объекта, который понадобится для определения свойств объекта, а также выполнения над ними действия. Для получения полной информации о всех активных объектах и значениях их свойств и методов, можно использовать команду Display Objects, которая имеет синтаксис:Устанавливать свойства объектов (или определенной группы объектов) можно с помощью With … Endwith Команда Mouse позволяет программным путем имитировать события Click, Double Click, MouseMove, DragDrop |
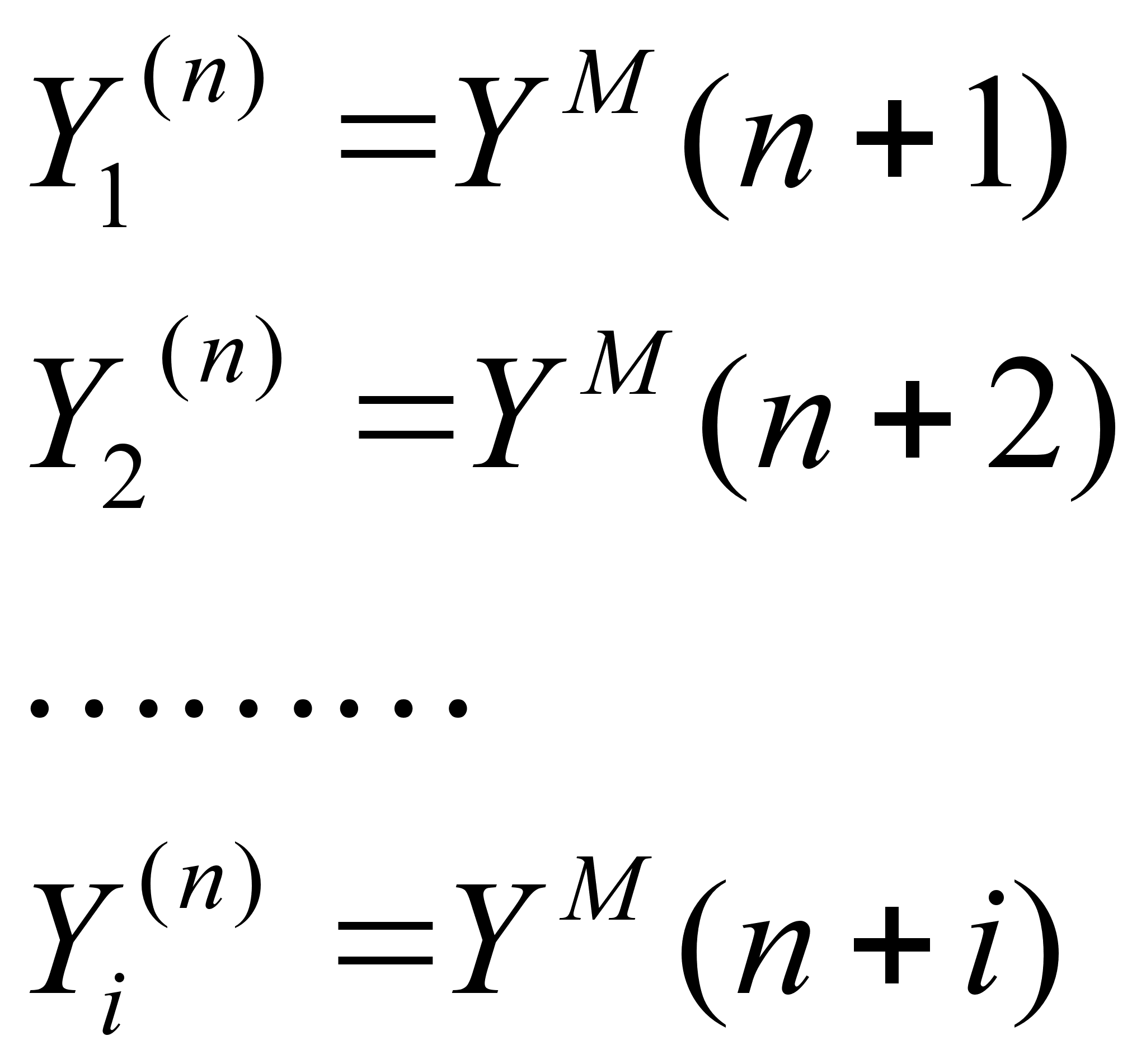
|
1 Методы моделирования временных рядов. Поле корреляции. Моделирование временного ряда Динамические процессы, происходящие в экономических системах, чаще всего проявляются в виде ряда последовательно расположенных в хронологическом порядке значений того или иного показателя, который в своих изменениях отражает ход развития изучаемого явления в экономике. Эти значения, в частности, могут служить для обоснования (или отрицания) различных моделей социально-экономических систем. Они служат также основой для разработки прикладных моделей особого вида, называемых трендовыми моделями. Последовательность наблюдений одного показателя (признака), упорядоченных в зависимости от последовательно возрастающих или убывающих значений другого показателя (признака), называют динамическим рядом, или рядом динамики. Если в качестве признака, в зависимости от которого происходит упорядочение, берется время, то такой динамический ряд называется временным рядом. Так как в экономических процессах, как правило, упорядочение происходит в соответствии со временем, то при изучении последовательных наблюдений экономических показателей все три приведенных выше термина используются как равнозначные. Если во временном ряду проявляется длительная («вековая») тенденция изменения экономического показателя, то говорят, что имеет место тренд. Таким образом, под трендом понимается изменение, определяющее общее направление развития, основную тенденцию временных рядов. Отличие временных экономических рядов от простых статистических совокупностей заключается прежде всего в том, что последовательные значения уровней временного ряда зависят друг от друга. Поэтому применение выводов и формул теории вероятностей и математической статистики требует известной осторожности при анализе временных рядов, особенно при экономической интерпретации результатов анализа. Поле корреляции Корреляционный анализ применяется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Коэффициент корреляции выборки представляет отношение ковариации двух наборов данных к произведению их стандартных отклонений. Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция). |
2 Технология Automation. Интерфейсы диспетчеризации. OLE (Automation) – объект автоматизации который представляет собой определённый внутри приложения экземпляр класса, который помощи интерфейсов автоматизации предоставляет свое свойства и методы другим приложениям и инструментальным средствам программирования.
динамические библиотеки и другие источники, которые отображают объекты автоматизации и делают их доступными для других приложений, называются --- серверами автоматизации. Приложения или инструментальные средства программирования, которые имеют доступ к управлению программными объектами, содержатся в сервере автоматизации, называются контроллерами автоматизации диспетчерами. Управление программными проектами осуществляется с помощью специального языка программирования серверов автоматизации, который в общем случае не совпадает с языком программирования приложений. Idispatch – интерфейс диспетчеризации. Основная функция Invoke. Function Invoke (DispId: integer; Const Iid: TGId; Locale ID: integer; Flags: word; var params; var Result, ExceptInfo, ArgErr: Point):Integer; ,где DispId – число, которое называется идентификатором диспетчера, указывающий какой именно метод должен использовать сервер. LocaleId – локальный Id. Flags – признак как вызывается метод. Метод доступа к свойству или метод действия. Params – указатель на массив TdispParams который хранит параметры вызова метода. VarResult – указатель на область OLEVariant в которой размещаются возвращаемые методам данные. Exceptinfo – указатель на запись с информацией о возникшей исключительной ситуации, если метод возвращает DispEException. ArgErr – указатель на число, равно порядковому номеру параметра в вызове при обработке которого возникло исключение. |
3 Выявление информационных объектов и связей между ними. Выявление информационных объектов и связей между ними – это второй шаг первого этапа проектирования. Он состоит: в выборе информационных объектов; в задании необходимых свойств для объекта; в выявлении связей между объектами; в определении ограничений, накладываемых на информационные объекты, типы связей и свойства объектов; ПО считается определенной, если известны существующие в ней объекты, их свойства и отношения (связи между ними). В основе инфологического подхода лежит идея установления соответствия между состоянием ПО, его восприятием и представлением в базе данных. Согласно инфологическому подходу, необходимо различать: явления реального мира; информацию об этих явлениях; представление этой информации посредствам данных. В соответствии с этой концепцией выделяют: реальный мир; информационную сферу; датологическую сферу. Объектная система имеет следующие составляющие: "Объект – Свойства - Связь". Объект может быть единичным или составным. Выбор объектов производится в соответствии с целевым назначением базы данных. Каждый объект в конкретный момент времени характеризуется определенным состоянием, которое описывается с помощью ограниченного набора свойств. Свойства объекта могут быть: не зависящими от его отношений с другими объектами; зависящими (локальными)…; |
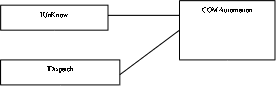
|
1 Статистические методы моделирования (метод Монте-Карло). По способам отражения фактора времени модели делятся на статистические и динамические. В статистических моделях все зависимости относятся к одному моменту или периоду времени. Динамические модели характеризуют изменения экономических процессов во времени. Метод Монте-Карло (метод статистических испытаний) – численный метод решения математических задач при помощи моделирования случайных чисел. Суть метода: посредством специальной программы на ЭВМ вырабатывается последовательность псевдослучайных чисел с равномерным законом распределения от 0 до1. Затем данные числа с помощью специальных программ преобразуются в числа, распределенные по закону Эрланга, Пуассона, Релея и т.д. Полученные таким образом случайные числа используются в качестве входных параметров экономических систем.При многократном моделировании случайных чисел определяем математическое ожидание функции и, при достижении средним значением функции уравнения не ниже заданного, прекращаем моделирование. Статистические испытания (метод Монте-Карло) характеризуются основными параметрами: - заданная точность моделирования; P – вероятность достижения заданной точности; N – количество необходимых испытаний для получения заданной точности с заданной вероятностью. Определим необходимое число реализаций N, тогда (1 - ) будет вероятность того, что при одном испытании результат не достигает заданной точности ; (1 - ) N – вероятность того, что при N испытаниях мы не получим заданной точности . Тогда вероятность получения заданной точности при N испытаниях можно найти по формуле
Формула (19) позволяет определить заданное число испытаний для достижения заданной точности с заданной вероятностью Р.Случайные числа получаются в ЭВМ с помощью специальных математических программ или спомощью физических датчиков. Одним из принципов получения случайных чисел является алгоритм Неймана, когда из одного случайного числа последовательно выбирается середина квадрата. Кроме того данные числа проверяются на случайность и полученные числа заносятся в базу данных. Физические датчики разрабатываются на электронных схемах и представляют собой генераторы белого (нормального) шума, то есть когда в спектральном составе шума имеются гармоничные составляющие с частотой F . Из данного белого шума методом преобразования получаются случайные числа. |
2 Модели данных. Структура, операции, ограничения модели. При описании ПО используется инфологическая модель, модель «сущность-связь». При описании данных используются соответствующие модели данных. Модель данных – это форматы данных и состав операции выполняемых над этими данными. В настоящее время существуют следующие модели данных: сетевые; иерархические; реляционные; объектно-ориентированные. Иерархическая модель. Представляет собой взаимосвязанный набор иерархий, т.е. расположение данных в определенной последовательности и зависимости. Пример - организационная структура предприятия. Особенность иерархической модели заключается в однонаправленном движении по иерархии. Сетевая модель. Позволяет сохранять концептуальную простоту иерархического подхода и добавляет ему гибкость, позволяя ему работать со многими иерархиями одновременно. На практике примером этой модели служит модель графика строительства объекта, (движения транспорта, изготовления изделия и т.п.): выбрать котлован — заложить фундамент — поставить стены - заложить перекрытия. В иерархической модели каждое данное находится на определенном уровне, взаимосвязь можно представить в виде диаграммы. В сетевой модели допускается одновременное наличие однотипных данных на различных уровнях. Здесь каждая запись может быть связана с любой другой. Реляционная модель. Облегчает установление связей, дает возможность легко и быстро установить новую связь, позволяет оптимальным образом осуществить доступ к данным любого уровня. Все СУБД, работающие на ПК, поддерживают эту модель. гибкость модели объясняется наличием математического аппарата нормализации отношений; наличие внешних ключей; использование языка структурированных запросов. Структура, операции, ограничения модели Построение структуры данных каждой конкретной модели не может выполняться произвольным образом. Это связано с ограничениями вытекающими из особенностей использующих в модели типов структуры данных и операции над данными. Исходя из вытекающего в качестве основных компонентов модели данных рассматриваются структуры данных, операции и ограничении целостности данных. Основные компоненты модели тесно взаимосвязаны между собой и в различных моделях могут быть реализованы различными способами. Ограничения модели. Это логические ограничения, которые накладываются на данные. Ограничения могут быть явные и внутренние. Внутренние представлены в модели данных правилами композиции допустимых структур данных в конкретной схеме БД. Находят свое отражения в структурных спецификациях и в правилах выполнения операции. Это явные ограничения специфицируются явным образом с помощью специальных конструкции языки описанных данных. В современных СУБД имеются собственные аппараты по проверке непротиворечивости данных, которые в свою очередь обеспечивают целость данных. Операции над данными. Динамические свойства модели данных выражается множеством операции над данными. Реализация любой конкретной операции над данными включает в себя селекцию, то есть выделение из всей совокупности именно технические данные над которыми должна быть выполнена операция. Условия селекции специфицируется в виде некоторого критерия отбора данных. Селекция выполняется любым способом с использованием логические позиции данного, значений данного и связей между данными. Например: выполнять селекцию из общего набора данных. Условия: в результате выборки по характеру производимого действия различают следующие виды операции: Идентификация данного и нахождение его позиции, выборка данных, включающий запись данного, удаление данного, модификация данного. По характеру способа получения результата различают: навигационные операции; спецификационные операции. Навигационные операции: результат операции получатся путем прохождения по связям реализованным в структуре БД. Результат навигации единичный объект БД. Например: экземпляр записи. Спецификационные операции: если определятся только требования к результату, но не задается способ его получения. Например: Спецификация требований может выполняться с использованием формул исчисления предикатов, что имеет место в реляционной модели. Результатом является: множество объектов БД. То есть в начале осуществляется селекция требуемых данных, затем вид операции. Структура данных. Структирование данных базируется на основных концепции, агрегации и обобщения. Например: в файловых системах, которое реализует модель плоский файл понимательный базис состоит из 4-х основных типов логических структур данных. Поле, наименьшая поименованная единица данных; Запись, поименованная совокупность полей; Файл, поименованная совокупность экземпляров записи одного типа; Набор файлов, поименованная совокупность файлов обрабатывающих в системе. В этой модели агрегация используется для компиляции полей в запись, а обобщения для представления множества экземпляров записей одного типа, одной общей структурой более высокого уровня. |
2 Структура процессора, определение и назначение основных функциональных узлов: АЛУ, УУ, регистровой памяти. Процессор является центральной частью ЭВМ, обеспечивает обработку цифровой информации в соответствии с программой, при этом он непрерывно взаимодействует с операционной памятью, получая из нее команды и операнды и отправляя в память результаты вычислений, организует выполнение операций ввода-вывода. Процессор обеспечивает совместную и согласованную работу всех частей, а именно, как и в любом вычислительном устройстве, - операционной и управляющей. Обобщенная структурная схема процессора:
клава запрос ОЗУ, ПЗУ прерывание Операционная часть: АЛУ – Арифметическое Логическое Устройство, реализует выполнение команд, составляющих программу, используя предусмотренный в нем набор базовых операций (арифметических, логических, условного перехода и т.п.). Вырабатывает сигналы, необходимые для организации вычислительного процесса. По форме представления чисел: АЛУ для чисел с фиксир.точкой, с плавающей, для двоично кодированных десятичных. По принципу действий: АЛУ последовательного действия с поразрядной обработкой информации и АЛУ параллельного действия с одновременной обработкой По степени использования: блочные и универсальные АЛУ БРП – Блок Регистровой Памяти – является местной памятью процессора, имеет небольшую емкость, но более быстродействующая по сравнению с ОЗУ. Используется для повышения быстродействия процессора. В БРП входят: регистры общего назначения (для выполнения арифметических операций с фиксированной точкой и процедур выполнения логических операций; в них хранятся и изменяются базовые адреса и индексы), регистры с плавающей точкой (для выполнения арифметических операций с плавающей точкой, применяются для нормализации полученного результата.) Организующая часть: УУ – Устройство Управления – 1. обеспечивает выполнение команд программ в заданной последовательности, выполнение каждой текущей команды и соответствующей операции в АЛУ
БУР – Блок Управляющих Регистров – является рабочей памятью, недоступной программе, и включает в себя счетчики и регистры для временного хранения управляющей информации. К ним относятся: регистр команд, регистр или счетчик адреса команд, буферные регистры для хранения адресов и слов. Интерфейс процессора – обеспечивает необходимое сопряжение проца с другими устройствами, прежде всего с оперативной памятью и периферией. В целом процессор представляет собой группу устройств, обеспечивающих автоматическую обработку информации и программное управление вычислительными процессами. |
|
1 Использование скалярного произведения при определении ковариации и парного коэффициента корреляции двух векторных величин. В силу того, что на основании парных коэффициентов корреляции основывается обоснованный выбор исходных данных для моделирования производственной функции, их нужно определять перед моделированием. В реальном производстве размеры затрат х1-Хn всегда, некоторым образом, связаны друг с другом. Например, увеличение потребления сырья неизбежно влечет за собой увеличение транспортных расходов, затрат на хранение и т. д. Если изменение одного вида затрат влечёт за собой пропорциональное (или близкое к пропорциональному) изменение других затрат, то моделирование производственной функции становится невозможным (или, по крайней мере, весьма затруднительным). Термины «проекция», «проектирование» имеют определенный «узкий» математический смысл. Эти же термины встречаются и в системном анализе, где имеют «широкий» системный смысл. Координатный методКоординаты вектора суммы двух векторов равны сумме координат слагаемых. а=(ах, ау), b=(bx,by), а + b = с=(сх, су) сх = ах + bx ; су = ау + by Для векторов выполняется правило перестановки слагаемых, т.е. а + b= b + а= c Скалярное произведение имеет два эквивалентных определения. Геометрическое. Скалярным произведением двух векторов называется число, равное произведению модулей этих векторов, умноженное на косинус угла между нами. а
∙ b=|a||b|cosφ
φ b Алгебраическое. Пусть а=(ах, ау), b=(bx,by). Тогда скалярным произведением назовем число, равное сумме произведений соответствующих координат. а ∙ b = ах bx + ау by При анализе экономических явлений на основе экономико-математических методов особое место занимают модели, выявляющие количественные связи между изучаемыми показателями и влияющими на них факторами. При рассмотрении моделей прогноза особое внимание уделяется регрессионной и факторной моделям. Регрессионная модель анализа позволяет количественно выразить взаимосвязь между показателями. Необходимые условия регрессионного анализа:
Регрессия – линия, построенная по атрибуту по принципу обратного использования обратной информации (кусок прямой, параболы). Аргументы (в произв. Функции-факторы) у=а0+а1t+a2t^2 – линейная регрессия (t1, t2- факторы). Накапливаются результаты наблюдений, а затем складываются. Уравнение регрессии – ур-ие, связывающее между собой фактор признаки и результативные признаки. Ур-ие регрессии бывают линейные и нелинейные. Метод регрессии заключатся в построении и решении системы нормальных уравнений. Необходимыми условиями регрессионного анализа является наличие достаточно большого количества наблюдений по совокупности однородных объектов; факторы подверженные исследованию должны иметь количественное измерение; абсолютное измерение, т.е. определить, на сколько единиц изменится величина результативного показателя, при изменении факторного на единицу; установление относительной степени зависимости результативного показателя от каждого фактора. |
2 Основные функции администрирования SQL – сервера. Создание триггеров, индексов, ограничений, домены, функции пользователя, хранимые процедуры, привилегии, исключения. Функции, определяемые пользователемФункции, определяемые пользователем, представляет собой обычную функцию, написанную на алгоритмическом языке, например, Pascal. Созданная функция оформляется в виде динамической библиотеке DLL, откуда может быть вызвана обычным способом. В общем случае библиотека содержит несколько функций.Достоинства применения функций, определяемых пользователем:
Порядок действий при работе при работе с пользовательской функцией следующий:
3 Технология dbExspress. Тех. Dbexppress включает:
Технология характеризуется:
Базовый интерфейс ISQLConnection. 1) ISQLDriver 2)ISQLConnection 3) ISQLCommand 4)ISQLCursor SQLConnection - соединение с базой данных при помощи драйверов DBExpress SQLDataSet - показывает SQL запрос, который надо выполнить или таблицу. DataSetProvider - извлекает данные из компонента SQLDataSet и может генерировать нужные инструкции обновления SQL ClientDataSet – КЭШИРУЕТ ДАННЫЕ читает данные из поставщика данных и сохраняет все данные в память (если св-во PacketRecords установлено в -1). Для отправки данных серверу метод ApplyUpdates. SQLClientDataSet - три в одном (SQLDataSet, поставщик, ClientDataSet ), но не содержит всех свойств. |
 а
а|
1 Разыгрывание дискретной случайной величины с заданным законом распределения. ЭВМ позволяет легко получать псевдослучайные числа (при решении задач их применяют вместо случайных чисел). Это привело к широкому внедрению этого метода во многие области современной науки и техники (статическая физика, теория массового обслуживания, теория игр и т.д.). Поскольку метод Монте-Карло требует проведения большого числа испытаний, его часто называют методом статистических испытаний. Отыскание возможных значений случайной величины Х (моделирование) называют «разыгрыванием случайной величины». Обозначим через R непрерывную случайную величину, распределённую равномерно в интервале (0, 1). Случайными числами называют возможные значения r непрерывной случайной величины R, распределённой в равномерном интервале (0, 1). В действительности пользуются не равномерно распределённой случайной величиной R, возможные значения, которой имеют бесконечное число десятичных знаков, а квазиравномерной случайной величиной R*, возможные значения которой имеют конечное число знаков. В результате замены R на R* разыгрываемая величина имеет не точно, а приближённо заданное распределение. Правило. Для того чтобы разыграть дискретную случайную величину, заданную законом распределения надо:
Если r попало в частичный интервал Δi, то разыгрываемая дискретная случайная величина приняла возможное значение xi. Разыгрывать псевдослучайные величины в соответствии с законами распределения позволяет Microsoft Excel. 2 Определение и основные типы топологий локальных вычислительных сетей. Топология сети – Схема, включающая узлы сети и соединения между ними. В настоящее время доминируют 3 сетевые топологии – шинная, звездообразная и кольцевая. Шинная- каждый узел подсоединяется к единому сетевому кабелю называемому шиной . На каждый конец шины устанавливается устройство (terminator) которое не позволяет отражаться данным в шину и вызывать ошибки. Звездообразная – каждый узел подсоединяется к центральному устройству известному как концентратор (hub). Кольцевая – непрерывное кольцо узлов. Как правило, каждый узел при этом непосредственно соединяется с двумя соседними узлами. Иными словами кольцо это замкнутая шина, оба конца соединены между собой. |
3 Разработка форм. Выбор типа пользовательского интерфейса в Visual FoxPro. Разработка форм Форма используется для объединение элементов управления с целью достижения требований функциональности при решении задачи. Специальное свойство элементов в управлении. I кл. – внешний вид II кл. – расположение на экране III кл. – использование меню IV кл. - управление V кл. – работа с данными Св-во по управлению. Active.Propery [=Valne] определяет ссылку на активный элемент управления на form для изменения значения его св-ва. Active Form.Method или Active Form.Poperty[=Setting] позволяет узнать заданное в property св-ва или выполнить метод Method. Control – позволяет возвращать число объектов. Controls (nIndex).Property [=Expression] позволяет сослаться на конкретный объект. Key Preview [=lExpr] прерывает события Keypress в форме, если Т, то события Keypress получает форма, а затем элемент управления, если F (использует его по умолчанию). События Keypress получает только активный элемент управления. Release Type возвращает идентификатор способа выхода из формы. 0 –удалена ссылка , 1 – закрыта форма, 2 – закрыто приложение. Show Tips [=lExpr] определяет появится ли подсказка для эл-та управления лог. Т – отображается , лог. F – не отображ. по умолчанию. Tool Tip Text [= cExpr] текст для подсказки. Многоинтерактивный документ MDI – предполагает создание главного окна приложения в приделах которого могут размещены др. приложения. CDI – один документный интерфейс. Подразумевает создание одного или нескольких окон, которые может свободно располагать на экране. Объединение двух типов интерфейсов смешанный интерфейс. Типы форм 1) Тип подчиненная форма Show window = 0 MDI form = лог. Т. Подчиненная форма может размещена в приделах гл-го кона приложения или формы верхнего уровня, когда Show window = 1. Гл. форма определяет в момент запуска подчиненные формы, пи этом она должна быть активна и видима. Это основной тип форм используется MDI. Установленное св-во MDI = лог Т позволяет получить стиль интерфейса Microsoft, когда окно формы макс. размера будет составлять единое целое с гл-м окном. 2) Свободная форма Show window = 0 desktop = T. Может размещена в любом месте экрана независимо от расположения гл-го окна приложения или полного верхнего уровня. Но поведения формы зависит от гл-го кона. 3) Форма верхнего уровня Show window = 2. Имеет статус приложения windows со всеми особенностями поведения. Служит основным средством создания одно – документного интерфейса и может выполнять функции в гл-й форме, по отношению свободной и подчиненной формы. |
|
1 Метод наименьших квадратов Метод наименьших квадратов - статистический прием, с помощью которого неизвестные параметры модели оцениваются путем минимизации суммы квадратов отклонений действительных (эмпирических) значений от теоретических. Основная идея метода наименьших квадратов сводится к тому, чтобы в качестве оценочного неизвестного параметра принималось значение, которое минимизирует сумму квадратов отношений между оценкой и параметром всех наблюдений. Этот метод является одним из наиболее распространенных приемов статистической обработки экспериментальных данных, относящихся к различным функциональным зависимостям физических величин друг от друга. В том числе, он применим к линейной зависимости и позволяет получить достоверные оценки ее параметров a и b, а также оценить их погрешности. |
2 Характеристика методов доступа в локальных вычислительных сетях распространенных архитектур: Ethernet, Arcnet и др. Ethernet - это самый распространенный на сегодняшний день стандарт локальных сетей. Общее количество сетей, работающих по протоколу Ethernet в настоящее время, оценивается в 5 миллионов, а количество компьютеров с установленными сетевыми адаптерами Ethernet - в 50 миллионов. Когда говорят Ethernet, то под этим обычно понимают любой из вариантов этой технологии. В более узком смысле Ethernet - это сетевой стандарт, основанный на экспериментальной сети Ethernet Network, которую фирма Xerox разработала и реализовала в 1975 году. На основе стандарта Ethernet DIX был разработан стандарт IEEE 802.3, который во многом совпадает со своим предшественником, но некоторые различия все же имеются. В зависимости от типа физической среды стандарт IEEE 802.3 имеет различные модификации 10Base-5, 10Base-2, 10Base-T, 10Base-FL, 10Base-FB Физические спецификации технологии Ethernet на сегодняшний день включают следующие среды передачи данных.
Число
10 в указанных
выше названиях
обозначает
битовую скорость
передачи данных
этих стандартов
-10Мбит/с Сети Token Ring, так же как и сети Ethernet, характеризует разделяемая среда передачи данных, которая в данном случае состоит из отрезков кабеля, соединяющих все станции сети в кольцо. Кольцо рассматривается как общий разделяемый ресурс, и для доступа к нему требуется не случайный алгоритм, как в сетях Ethernet, а детерминированный, основанный на передаче станциям права на использование кольца в определенном порядке. Это право передается с помощью кадра специального формата, называемого маркером или токеном (token). Сети Token Ring работают с двумя битовыми скоростями - 4 и 16 Мбит/с. Смешение станций, работающих на различных скоростях, в одном кольце не допускается. Сети Token Ring, работающие со скоростью 16 Мбит/с, имеют некоторые усовершенствования в алгоритме доступа по сравнению со стандартом 4 Мбит/с. Технология Token Ring является более сложной технологией, чем Ethernet. Она обладает свойствами отказоустойчивости. В сети Token Ring определены процедуры контроля работы сети, которые используют обратную связь кольцеобразной структуры - посланный кадр всегда возвращается в станцию - отправитель. В некоторых случаях обнаруженные ошибки в работе сети устраняются автоматически, например может быть восстановлен потерянный маркер. В других случаях ошибки только фиксируются, а их устранение выполняется вручную обслуживающим персоналом. В общем случае сеть Token Ring имеет комбинированную звездно-кольцевую конфигурацию. Конечные узлы подключаются к MSAU по топологии звезды, а сами MSAU объединяются через специальные порты Ring In (RI) и Ring Out (RO) для образования магистрального физического кольца. Все станции в кольце должны работать на одной скорости - либо 4 Мбит/с, либо 16 Мбит/с. Кабели, соединяющие станцию с концентратором, называются ответвительными (lobe cable), а кабели, соединяющие концентраторы, - магистральными (trunk cable). Технология Token Ring позволяет использовать для соединения конечных станций и концентраторов различные типы кабеля: STP Type I, UTP Type 3, UTP Type 6, а также волоконно-оптический кабель. |
3 Технология и методы проектирования информационных систем. Методология создания ИС заключается в организации процесса построения ИС и обеспечения управления этим процессом для того, чтобы гарантировать выполнение требований как к самой системе, так и к хар-ам процесса разработки. Методология, технология и инструментальные средства проектирования составляют основу любой ИС. Методология реализуется через конкретные технологии и поддерживающие их стандарты, методики и инструментальные средства, которые обеспечивают выполнение процессов жизненного цикла ИС. Основное содержание технологии проектирования составляют технологические инструкции, состоящие из описания последовательности технологических операций, условий, в зависимости от которых выполняется та или иная операция, и описаний самих операций. Технология проектирования может быть представлена как совокупность 3 составляющих: - заданной последовательности выполнения технологических операций проектирования; - критериев и правил, используемых для оценки результатов выполнения тех.операций; - графических и текстовых средств, используемых для описания проектируемой системы. |
|
1 Элементы понятийного аппарата общей теории систем и системного анализа в теории информационных систем. Система – совокупность взаимодействующих элементов, реализующих поставленный процесс для достижения заданной цели. Цель – это субъективный образ или абстрактная модель несуществующего, но желаемого состояния среды, которое решило бы возможную проблему. Структура системы – множество элементов и элементарных взаимодействий. В каждом элементе системы может протекать какой-то процесс, и эти процессы объединяются в процесс системы за счет элементов взаимодействия. Понятие системы в теоретико-познавательном смысле есть способ мышления или способ постановки и упорядочивания проблем. Системность есть свойство материи, а, следовательно, человеческой практики и мышления. Под элементом системы будем понимать неделимую мельчайшую часть системы с точки зрения конкретной экономической и любой другой задачи. Взаимодействия между двумя элементами системы назовем элементарным взаимодействием. Цель любой искусственной системы определяется как желаемый образ результата ее деятельности. Всякая система создается для достижения этой цели. Примеры систем: Цель: в Система связана со средой и с помощью этих связей воздействует на среду. Продукты работы системы, предназначенные для потребления вне ее, называются выходами системы.
Среда Система является средством, поэтому должны существовать и возможности ее использования, воздействия на нее, т.е. и такие связи со средой, которые направлены извне системы – входы системы. Таким образом, мы построили модель «черного ящика». Пример: телевизор, где входы: антенна, ручки настройки выход: экран, звуковые колонки Внутренность ящика оказывается неоднородной, что позволяет различать составные части самой системы, которые при более детальном рассмотрении могут быть в свою очередь разбиты на составные части. Те части системы, которые рассматривают как неделимые, будем называть элементами. Понятие связь входит в любое определение системы и характеризует и строение (статику) и функционирование (динамику). Связь – это ограничение степени свободы элементов. Элементы, вступая в связь друг с другом, утрачивают часть своих свойств, которыми они потенциально обладали в свободном состоянии. Связи можно охарактеризовать: по направлению, по силе, по характеру(подчинения, порождения (генетические), одноправления (безразличные), управления ) Важную роль в моделировании систем играет понятие обратной связи. Она может быть положительной, т.е. сохраняющей тенденции и происходящие в системе изменения того или иного выходного параметра; и отрицательной, т.е. противодействующая тенденция изменения выходного параметра, т.е. направлена на сохранение требуемого значения этого параметра. |
2 Получение аналитических показателей близости и адекватности при построении трендов и производственных функций. Независимо от вида и способа построения экономико-математической модели вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т.е. соответствия модели исследуемому процессу или объекту. Так как полного соответствия модели реальному процессу или объекту быть не может, адекватность — в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые считаются существенными для исследования. Трендовая модель ŷt конкретного временного ряда г/( считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента ε=yt-ŷt (t=1, 2. ...,n) удовлетворяла свойствам случайной компоненты временного ряда: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. |
3 Средства синхронизации потоков: события, взаимные исключения, критические секции, семафоры. Синхронизация – если создаваемый поток не взаимодействует с ресурсами других потоков и не обращается к VCL. Главные понятия для понимания механизмов синхронизации – функции ожидания и объекты синхронизации. Ряд функций, позволяющих приостановить выполнение вызвавшего эту функцию потока вплоть до того момента, как будет изменено состояние какого-то объекта, называемого объектом ожидания. Событие – объект типа событие - простейший выбор для задач синхронизации. Он подобен дверному звонку –звенит до тех пор, пока его кнопка находится в нажатом состоянии, извещая об этом факте окружающих. Аналогично, и объект может, находится в 2х состояниях, а «слышать» его могут многие потоки сразу. Класс TEvent имеет 2 метода переводящих объект в активное и пассивное состояние (Set Event и Reset Event). Взаимные исключения - позволяет только одному потоку в данное время владеть им. Если продолжать аналогии, то этот объект можно сравнить с эстафетной палочкой. Программист может использовать взаимное исключение, чтобы избежать считывания и записи общей памяти несколькими потоками одновременно. Критические секции(область глобальной памяти, кторая требует защиты при обращении к нему нескольких потоков одновременно, может выполняться в рамках одного потока, все остальные блокируются.)– подобны взаимным исключениям по сути, однако, между ними существуют 2 главных отличия:
Критические секции, более эффективны, чем взаимные исключения, так как используют меньше системных ресурсов. И являются системными объектами и подлежат обязательному освобождению. Семафор – подобен взаимному исключению. Разница между ними в том, что семафор может управлять количеством потоков, которые имеют к нему доступ. Семафор устанавливается на предельное число потоков, которым доступ разрешен. Когда это число достигнуто, последующие потоки будут приостановлены, пока один или более потоков не отсоединятся от семафора и не освободят доступ. Основные методы управления:
|
|
1 Кибернетический подход к информационной системе как системе управления Понятие кибернетической системы связано с процессами управления и переработки данных. Процесс управления рассматривается как процесс взаимодействия двух систем – управляющей и управляемой, в которой X – входные параметры о состоянии объектов управления, Y – выходные параметры, по которым судится о том, достигнута ли цель управления. Обратная связь – обеспечивает передачу данных в управляющую систему, по которым судят о рассогласовании цели и получаемых результатов.Управляющие или управленческие воздействия - среда. Процесс управления содержит следующие этапы:
Обязательным элементом любой системы управления является информационная система – это коммуникационная система сбора, передачи, переработки данных об объекте управления. Данная система снабжает работников различного уровня информацией для реализации функций управления. Информационные системы могут быть – прочными, автоматизированными и автоматическими. Данная классификация учитывает пропорции ведения данных между человеком и вычислительным устройством.
ВУ – вычислительное устройство
Если в системе есть человек, то система называется автоматизированной. ИС сама по определению является тоже системой управления. Определение ИС включает:
|
2 Имитационное моделирование простейших систем массового обслуживания. Для моделирования СМО должны быть известны 4 ее параметра λ-плотность вводящего потока, показывающая среднее чисто требований, поступающих в СМО в час (параметр загрузки). Поток заявок простейшкй μ-среднее число заявок, обслуживаемых одним аппаратом в час (пар-р загрузки). Распределение интервалов обслуживания подчиняется показательному распределению. N-число обслуж. аппаратов. Будем полагать что аппараты имеют одинаковую производительность обслуживания μ требований в час. М - максимальное число требований, которое может быть размещено в накопителе при ожидании обслуживания. Будем считать, что если очередное требование, поступающее в СМО в состоянии, когда будут заняты все аппараты и все места в накопителе то требование получает отказ в обслуживании и покидает СМО не обслуженным. В СМО постоянно протекают 2 случайных процесса: процесс загрузки, обусловленный параметром λ и процесс разгрузи, обуслов. параметром μ. В рез-те СМО имеет свои состояния. Опишем и обозначим эти состояния. S0-состояние когда в СМО нет ни одного требования, накопитель свободен, аппараты свободны, S1-когда а в СМ О одно требование, один аппарат занят, накопитель свободен, S2-в системе 2 требования, SN -в системе N требований, все аппараты загружены, накопитель свободен, SN+1|-в системе N+1 требований, все аппараты замяты, одно место в накопителе занято, SN+M—в системе N+М требований, все аппараты заняты, накопитель полностью загружен. В простейших системах, когда заявки поступают на обслуживание по одной и также после обслуживания по одной покидают. Смо, все состояния можно выстроить в одну динамическую цепочку, что удобно изобразить графически. Квадраты изображают состояние СМО, астрелки: верхние затрузку, нижние разгрузу
Хар-ки СМО. Средняя длина оч ф,еци ТМ=M0P0+M1P1+...+MnPn где Mn -количество занятых мест в накопителе в каждом из состояний S0Sn. Вероятность отказа очередному клиенту определяется как вероятность максимально загруженного состояния системы. Относительная пропускная способность ОПС=1-Ротк . Абсолютный отказ (заявок/час) А0=λ Ротк Абсолютная пропускная способность (заявок/час) АПС= Ротк *ОПС. Среднее время ожидания в накопителе (час) WМ:=ТМ/АПС. Среднее время нахождения заявки в СМО (ч ас) WS=WM+1/μ. Средняя длина очереди мастеров ТМ=N0P0+N1P1+...+NnPn Среднее число занятых мастеров ZN=N-TN. Среднее суммарное число заявок в СМО ТS=ТМ+ZК. |
3 OLAP- технология и аналитические информационные системы Основная идея OLAP-технологии заключается в построении многомерных кубов данных, которые в дальнейшем можно использовать для реализации аналитических пользовательских запросов. Исходные данные для построения OLAP-кубов обычно хранятся в реляционных базах данных, называемых также хранилищами данных (Data Warehouse). В отличие от оперативных баз данных, с которыми работают приложения ведения данных, хранилища данных предназначены исключительно для обработки и анализа информации, поэтому проектируются они таким образом, чтобы время выполнения запросов к ним было минимальным. Обычно данные копируются в хранилище из оперативных баз данных согласно определенному регламенту, например, раз в месяц, квартал или год. Типичная структура хранилища данных существенно отличается от структуры обычной реляционной БД. Как правило, эта структура денормализована (это позволяет повысить скорость выполнения запросов), поэтому может допускать избыточность данных. Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables). Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся: факты, связанные с транзакциями. Они основаны на отдельных событиях (например, телефонный звонок); факты, связанные с «моментальными снимками». Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за; факты, связанные с элементами документа. Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки); факты, связанные с событиями или состоянием объекта. Представляют возникновение события без подробностей о нем (например, просто факт продажи). С общей позиции обработки данных можно выделить два доминирующих класса информационных систем: системы, ориентированные на операционную (транзакционную) обработку данных (On-Line Transaction Processing, OLTP-системы), часто их определяют как системы обработки данных (СОД); системы, ориентированные на аналитическую обработку данных (Decision Support Systems, DSS), или системы поддержки принятия решений (СППР). СОД обеспечивают процессы повседневной рутинной обработки данных на конкретных рабочих местах или производственных участках. Системы поддержки принятия решений – являются вторичными по отношению к системы обработки данных и призваны осуществлять анализ результатов деятельности за различные периоды времени, оценку эффективности работы отдельных подразделений или сотрудников и другие аналитические процедуры. Дальнейшее развитие аналитических информационных систем связано с технологией оперативной аналитической обработки данных (On-Line Analytical Processing, OLAP-системы), в основе концепции которой лежит многомерное представление данных. Обработка многомерных данных в приложениях Delphi. Правила проектирования. Графич-е средства анализа данных в приложениях. В среде Delphi многомерные данные представляются в виде метакуба, где каждому фактору соответствует свое измерение. В конкретной ячейке, как правило, представляются агрегированные данные – сумма, среднее, максимальное значение – или новые многомерные данные (кубы). Как правило для формирование набора данных из совокупности связанных таблиц используется компонент TDecisionQuery, SQL оператор к-го содержит оператор Select. Правила: В Select первыми перечисляются поля по которым перечисляются измерения; Агрегирование осуществляется по указанным ранее измерениям; GroupBy используется для всех полей. Select P.Gorod, R.Pocup, T.Type_tovar, R.Tovar, R.Mes, Sum(R.Kol * T.Zena), AVG(R.Kolvo * T.Zena) from “Rashod.db” R, “Tovar.db”T, ”Pocup.db” P Where R.Tovar = T.Tovar and R.Pocup = P.Pocup GroupBy P.Gorod, R.Pocup, T.Type_tovar, R.Tovar, R,Mes TdecisionCube - реализует многомерный куб. Соединяется с набором данных при помощи сво-ва DataSet. TdecisionGrid – показывает данные из многомерного куба. TdecisionGraph – предназначен для показа графиков, источником к-х служат многомерные данные. |

|
1 Элементы понятийного аппарата общей теории систем и системного анализа в теории информационных систем. Система – совокупность взаимодействующих элементов, реализующих поставленный процесс для достижения заданной цели. Цель – это субъективный образ или абстрактная модель несуществующего, но желаемого состояния среды, которое решило бы возможную проблему. Структура системы – множество элементов и элементарных взаимодействий. В каждом элементе системы может протекать какой-то процесс, и эти процессы объединяются в процесс системы за счет элементов взаимодействия. Понятие системы в теоретико-познавательном смысле есть способ мышления или способ постановки и упорядочивания проблем. Системность есть свойство материи, а, следовательно, человеческой практики и мышления. Под элементом системы будем понимать неделимую мельчайшую часть системы с точки зрения конкретной экономической и любой другой задачи. Взаимодействия между двумя элементами системы назовем элементарным взаимодействием. Цель любой искусственной системы определяется как желаемый образ результата ее деятельности. Всякая система создается для достижения этой цели. Примеры систем: Цель: в Система связана со средой и с помощью этих связей воздействует на среду. Продукты работы системы, предназначенные для потребления вне ее, называются выходами системы.
Среда Система является средством, поэтому должны существовать и возможности ее использования, воздействия на нее, т.е. и такие связи со средой, которые направлены извне системы – входы системы. Таким образом, мы построили модель «черного ящика». Пример: телевизор, где входы: антенна, ручки настройки выход: экран, звуковые колонки Внутренность ящика оказывается неоднородной, что позволяет различать составные части самой системы, которые при более детальном рассмотрении могут быть в свою очередь разбиты на составные части. Те части системы, которые рассматривают как неделимые, будем называть элементами. Понятие связь входит в любое определение системы и характеризует и строение (статику) и функционирование (динамику). Связь – это ограничение степени свободы элементов. Элементы, вступая в связь друг с другом, утрачивают часть своих свойств, которыми они потенциально обладали в свободном состоянии. Связи можно охарактеризовать: по направлению, по силе, по характеру(подчинения, порождения (генетические), одноправления (безразличные), управления ) Важную роль в моделировании систем играет понятие обратной связи. Она может быть положительной, т.е. сохраняющей тенденции и происходящие в системе изменения того или иного выходного параметра; и отрицательной, т.е. противодействующая тенденция изменения выходного параметра, т.е. направлена на сохранение требуемого значения этого параметра. |
2 Характеристика интерфейсов ЭВМ. Устройства вычислительной системы соединяются друг с другом с помощью унифицированных систем связи, называемых интерфейсом. Интерфейс представляет собой систему шин, согласующих устройств, алгоритмов обеспечи-вающих связь всех частей ЭВМ между собой. От характеристик интерфейса зависит быстродействие и надежность ЭВМ. Интерфейс должен быть стандартизирован с тем, чтобы он обеспечивал связь процессора и оперативной памяти с любым периферийным устройством (ПУ). Необходимое преобразование формата данных должно производиться в ПУ. Алгоритмы функционирования интерфейса и управляющего сигнала также должны быть стандартизированы. Схемы интерфейса обычно располагаются в самих связываемых устройствах. Типы интерфейса: 1. Интерфейс ОЗУ - через него производится обмен данными между ОЗУ и процессором, между ОЗУ и каналами ввода - вывода. Ведущим в обмене данными, т.е. начинающим операцию обмена, является процессор и каналы ввода - вывода, а исполнителем - ОЗУ. Этот интерфейс является быстродействующим. Информация через него передается словами и полусловами. 2. Интерфейс с процессором - через него происходит обмен информацией между процессором и каналами ввода - вывода. Ведущий - процессор, исполнитель - каналы. Интерфейс является быстродействующим. Обмен информацией через него происходит словами и полусловами. 3. Интерфейс ввода - вывода. Через него происходит обмен информацией между каналами ввода - вывода и устройствами управления ПУ. Обмен информацией производится байтами. Его быстродействие меньше, чем у первых двух типов. 4. Интерфейс периферийных аппаратов (ПА). Через него происходит обмен информацией между устройствами управления ПА и самими ПА. Он не может быть стандартизирован, т.к. ПА очень разнообразны. Интерфейсы могут быть односвязными и многосвязными. При односвязном интерфейсе общие для всех устройств шины используются всеми устройствами, подключенными к данному интерфейсу, на основе разделения времени. При многосвязном интерфейсе одно устройство связывается с другими устройствами по нескольким независимым магистралям. Односвязный интерфейс применяется в малых и микро ЭВМ, а многосвязный - в средних и больших ЭВМ. Многосвязный интерфейс характеризуется тем, что каждое устройство снабжается одной выходной магистралью для выдачи информации и несколькими входными для приема информации от других устройств. При неисправности какой - либо входной шины или сопряженных с ней согласующих устройств, оказывается отключенным только одно периферийное устройство. Интерфейс автоматически определяет неисправное ПУ и выбирает исправные и незанятые магистрали. МП в зависимости от заданной программы выбирает последовательность опроса датчиков, т.е. вырабатывает управляющие сигналы обмена информацией по выбранному каналу и осуществляет сбор и обработку данных. По цифровому каналу связи сигнал может передаваться параллельно или последовательно. Параллельная передача цифрового сигнала требует отдельные линии для каждого разряда, но является более быстродействующей. При последовательной передаче цифровые сигналы передаются последовательно по одной линии связи. По способу передачи информации во времени интерфейс может быть синхронный и асинхронный. Синхронный характерен постоянной временной привязкой, а асинхронный - без постоянной временной привязки. При синхронной передаче данных синхронизирующие сигналы МП задают временной интервал, в течении которого считывается информация с одного датчика. Временной интервал определяется наибольшим временем задержки в системе передачи данных и максимальным временем преобразования аналогового сигнала в цифровой. Асинхронная передача данных характеризуется наличием управляющих сигналов: "Готовность к обмену", вырабатываемый датчиком исходной информации; "Начало обмена", "Конец обмена", "Контроль обмена", вырабатываемые МП. При такой организации обмена автоматически устанавливается рациональное соотношение между скоростью передачи данных и величинами задержки сигналов в канале связи. |
3 Обзор языка структурированных запросов SQL. Любая ИС может считаться эффективной если выборка данных осуществляется быстро, качественно и в требуемом объёме. Наиболее эффективным решением этой проблемы является возможность построения запросов средствами команд SQL. Язык SQL в отличии от существующих команд языка СУБД является множественно-ориентированным языком и направлен на получение готовых таблиц с результатами запроса. Особенности SQL: команда SQL работает с данными на уровне машинного представления поэтому скорость обработки возрастает в сотни раз по сравнению с традиционными командами СУБД. Ком. SQL самостоятельно выполняют создание индексов и ключей при необходимости, это экономит место на диске и затраты ресурсов на поддержание целостности структуры индексов. Каждая СУБД имеет свой собственный диалект по SQL, который отличается полнотой поддержки стандарта и некоторыми незначительными отличиями синтаксиса. Для построения запроса в диалоговом режиме может быть использован конструктор запросов. Где генерируется тело команды SQL и создаётся файл с .qpr. Этот файл можно выполнить используя команду DO имя запроса .QPR. Сгенерировать код команды SQL возможно также в дизайнере представлений, однако в том и другом случае в дизайнерах не могут быть реализованы все сложные синтаксические конструкции SQL , поэтому один з вариантов может быть следующим: в конструкторе создаётся тело SQL и вручную дополняются тонкие настройки. Обобщённый алгоритм построения запроса
Описание полей данных в результате
Список источников данных Условия
связи между
разл *Усл.
от
*Усл. Суммирования данных *Задание порядка записей в результате * - необязательные блоки алгоритма Т.о Select SQL является наиболее мощной и удобной командой для получения выборок. Позволяет выполнить запрос к одной или более таблицам, направляя при этом результат в курсор или таблицу, в график, на принтер. Команда Select SQL поддерживает функции агрегирования. |
|
1 Методы анализа информационных потоков и структуризации предметной области Процесс потребления информационных ресурсов реализуется информационными потоками или потоками данных. Анализ информационных потоков осуществляется с целью:
Программа обследования должна включать следующие разделы:
На первом этапе обследования разрабатывается структурно-функциональная схема (декомпозиция ИС по структурно-функциональному признаку). Для предприятия.
Выбор функциональных задач осуществлён с учётом основных фаз управления:
Реализация каждой из этих функций в условиях функционирования ИС связано с выбором варианта, эффективность которого оценивается критерием целей управления. Следовательно, одни и те же задачи реализуются с привлечением математической модели и методов (МО). Поиск наилучшего варианта связан со сложностью алгоритма (временная и ёмкостная сложность) возможен на соответствующем варианте технического обеспечения. |
2 Получение аналитических показателей близости и адекватности при построении трендов и производственных функций Независимо от вида и способа построения экономико-математической модели вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т.е. соответствия модели исследуемому процессу или объекту. Так как полного соответствия модели реальному процессу или объекту быть не может, адекватность — в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые считаются существенными для исследования. Трендовая модель ŷt конкретного временного ряда г/( считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента ε=yt-ŷt (t=1, 2. ...,n) удовлетворяла свойствам случайной компоненты временного ряда: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. |
3 Технология СОМ+. Для распределения бизнес приложений большое значение имеют такие характеристики как, надежность, производительность, масштабируемость. Тех.-гия СОМ+ предназначена для поддержки систем обработки транзакций, базируется СОМ технологии, объекты СОМ+ обладают всеми основными свойствами объектов СОМ, кроме этого обеспечивают:
В состав инструментальных средств технологии входят 1. координатор распределения транзакции (DTC – distributed transaction coordinator ) Эта служба которая управляет транзакцией нижнем уровне
Функционирование объектов транзакции По функциональному признаку ПО технологии можно подразделить
Стандартная программная модель СОМ+, представляет по сути 3-х звенную архитектуру. Уровень сервера, уровень ПО промежуточного уровня и уровень клиента. ПО СОМ+ поддерживает технологию вынесения бизнес логики из приложения в БД. Бизнес логика централизуется в объектах транзакций , эти объекты компилируются и остаются в системе в виде пакетов. ПАКЕТ – это контейнер , который обеспечивает группировку объектов транзакций с целью защиты данных, управление ресурсами и увеличение производительности распределенных бизнес приложениями, управляет пакетами в среде MTSExplorer. Создание приложений в СОМ+ в Delphi С позиции объектной модели СОМ объекты транзакций СОМ+ являются СОМ объектами обладающими интерфейсами IObjectControl и IObjectContext. Они используются для реализации небольших блоков бизнес логики приложений. 1 объект может работать с 1 транзакцией монопольно или использовать её совместно с др. объектами. Инкапсулирует функции объект транзакций. TMTSAutoObject. Его основные методы обеспечивают: - Уведомление транзакций о состоянии объекта - Программы защиты данных - Пулинг объектов Основные методы: Proc SetComplete SetAbort Создание объекта транзакций осуществляется с помощью NewTransaction Objection. Объекты транзакций м/б реализованы только в составе внутр. сервера |
|
1 Методы моделирования временных рядов. Поле корреляции. Моделирование временного ряда Динамические процессы, происходящие в экономических системах, чаще всего проявляются в виде ряда последовательно расположенных в хронологическом порядке значений того или иного показателя, который в своих изменениях отражает ход развития изучаемого явления в экономике. Эти значения, в частности, могут служить для обоснования (или отрицания) различных моделей социально-экономических систем. Они служат также основой для разработки прикладных моделей особого вида, называемых трендовыми моделями. Последовательность наблюдений одного показателя (признака), упорядоченных в зависимости от последовательно возрастающих или убывающих значений другого показателя (признака), называют динамическим рядом, или рядом динамики. Если в качестве признака, в зависимости от которого происходит упорядочение, берется время, то такой динамический ряд называется временным рядом. Так как в экономических процессах, как правило, упорядочение происходит в соответствии со временем, то при изучении последовательных наблюдений экономических показателей все три приведенных выше термина используются как равнозначные. Если во временном ряду проявляется длительная («вековая») тенденция изменения экономического показателя, то говорят, что имеет место тренд. Таким образом, под трендом понимается изменение, определяющее общее направление развития, основную тенденцию временных рядов. Отличие временных экономических рядов от простых статистических совокупностей заключается прежде всего в том, что последовательные значения уровней временного ряда зависят друг от друга. Поэтому применение выводов и формул теории вероятностей и математической статистики требует известной осторожности при анализе временных рядов, особенно при экономической интерпретации результатов анализа. Поле корреляции Корреляционный анализ применяется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Коэффициент корреляции выборки представляет отношение ковариации двух наборов данных к произведению их стандартных отклонений. Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция). |
2 Иерархическая, сетевая, реляционная, объектно-ориентированная модели данных. При описании ПО используется инфологическая модель, модель «сущность-связь». При описании данных используются соответствующие модели данных. Модель данных – это форматы данных и состав операции выполняемых над этими данными. В настоящее время существуют следующие модели данных: сетевые; иерархические; реляционные; объектно-ориентированные. Иерархическая модель данных Представляет собой взаимосвязанный набор иерархий, т.е. расположение данных в определенной последовательности и зависимости. Пример – организационная структура предприятия. Особенность иерархической модели заключается в однонаправленном движении по иерархии. Сетевая модель Позволяет сохранять концептуальную простоту иерархического подхода и добавляет ему гибкость, позволяя ему работать со многими иерархиями одновременно. На практике примером этой модели служит модель графика строительства объекта, (движения транспорта, изготовления изделия и т.п.): выбрать котлован – заложить фундамент – поставить стены – заложить перекрытия. В иерархической модели каждое данное находится на определенном уровне, взаимосвязь можно представить в виде диаграммы. В сетевой модели допускается одновременное наличие однотипных данных на различных уровнях. Здесь каждая запись может быть связана с любой другой. Пример – имеются заказы на изготовление изделий. Каждый заказ – запись в БД заказов. Взаимосвязи сущностей вокруг заказа
Объект - Район Изделия -Товар Сегмент рынка Операции: добавить, включить в групповое отношение, переключить, обновить, извлечь, удалить, исключить из группового отношения . Ограничения целостности – то же что и в иерархической. Реляционная модель Облегчает установление связей, дает возможность легко и быстро установить новую связь, позволяет оптимальным образом осуществить доступ к данным любого уровня. Все СУБД, работающие на ПК, поддерживают эту модель. Преимущества модели: гибкость модели объясняется наличием математического аппарата нормализации отношений; наличие внешних ключей; использование языка структурированных запросов. В основу реляционной модели положен теоретико-множественный подход, базирующийся на понятии отношения. В основе отношения – таблица (плоский файл). Набор отношений может быть использован для хранения данных конкретной ПО. Разработана Эдгаром Коддом в 1970г. В основе лежит понятие отношения, которое используется как инструмент моделирования данных. Отношения удобно представлять в виде таблиц. Строки отношения соответствуют кортежам. Каждая строка фактически представляет собой описание одного объекта реального мира, характеристики которого содержаться в столбцах. Реляционные отношения соответствуют наборам сущностей модели «сущность - связь», а кортежи -сущностям. Столбцы в таблице, представляющей реляционное отношение , называют также атрибутами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей является первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными. В отличии от иерархической и сетевой МД в реляционной отсутствует понятие группового отношения. Связи между отношениями описываются в терминах функциональной зависимости. Для отражения функциональных зависимостей между кортежами разных отношений используется дублирование первичного ключа родительского отношения в дочернее. Атрибуты, представляющие собой копии ключей родительских отношений, называются внешними ключами. |
3 Основные стадии и этапы технологической схемы проектирования информационных систем. 1 этап связан с моделированием и анализом процессов, описывающих деятельность организации, технологические особенности работы. Целью является построение моделей существующих процессов, выявление их недостатков и возможных источников усовершенствования. Этот этап не является обязательным в случае, когда существующая технология и организационные структуры четко определены, хорошо поняты и не требуют дополнительного изучения и реорганизации. На 2 этапе разрабатываются детальные концептуальные модели предметной области, описывающие информационные потребности организации, особенности функционирования и т.п. Результатом являются модели двух типов: - информационные, отражающие структуру и общие закономерности предметной области; - функциональные, описывающие особенности решаемых задач. На 3 этапе проектирования на основании концептуальных моделей вырабатываются технические спецификации будущей прикладной системы – определяются структура и состав БД, специализируется набор программных модулей. Первоначальный вариант проектных спецификаций может быть получен автоматически с помощью специальных утилит на основании данных концептуальных моделей. На этапе реализации создаются программы, отвечающие всем требованиям проектных спецификаций.. Процессы, протекающие на протяжении жизненного цикла ИС: Определение производственных требований; - исследование существующих систем; - определение технической архитектуры; - проектирование и построение БД; - проектирование и реализация модулей; - конвертирование данных; - документирование; - тестирование; - обучение; - переход к новой системе; - поддержка и сопровождение. |
|
1 Реляционная алгебра и реляционное исчисление. Реляционная алгебра – это набор операций, который можно использовать, чтобы сообщить системе как в базе данных из определенных отношений реально построить необходимое отношение. Реляционное исчисление – это система обозначений, для определения необходимого отношения в терминах данных отношений. Формулировка запроса в терминах исчисления носит описательный характер, а алгебраическая формулировка – предписывающий. Каждому выражению в алгебре соответствует эквивалентное ему исчисление и наоборот. Реляционное исчисление основано на разделе математической логики, который называется исчислением предикатов. Основным средством исчисления является понятие переменной кортежа. Переменная кортежа – это переменная, которая “изменяется на” некотором отношении, т.е. переменная, допустимые значения которой – кортежи данного отношения. Если переменная кортежа T изменяется в пределах отношения R, то в любое данное время переменная T представляет некоторый кортеж t отношения R. Поэтому рел. исчисление называют исчислением кортежей. Существует альтернативная версия исчисления доменов, где переменные кортежа заменены переменными доменов, т. е. переменными изменяемыми на доменах, а не на отношениях. Переменная кортежа определяется следующим образом: Range of R is x1, x2, …,xn T – определяемая переменная кортежа xi(i=1,2,…,n) – либо имя отношения, либо выражение исчисления кортежей. Если xi – это отношение Ri(i=1,2,…,n), то отношения R1,R2,…,Rn должны д/б совместимы по типу, тогда переменная кортежа T изменяется на объединении этих отношений. Каждый экземпляр переменной в правильно построенной формуле (WFF) является или свободным или связанным. Под экземпляром переменной кортежа в WFF понимают наличие имени переменной в WFF.
Операции объединения, пересечения и вычитания требуют от операндов совместимости по типу. Объединением двух совместимых по типу отношений А и В называется отношение с тем же заголовком, как и в отношениях А и В, и с телом, состоящим из множества всех кортежей t, принадлежащих А или В или обоим отношениям. Пересечением двух совместимых по типу отношений А и В называется отношение с тем же заголовком, как и в отношениях А и В, и с телом, состоящим из множества всех кортежей t, принадлежащих одновременно обоим отношениям А и В. Вычитанием двух совместимых по типу отношений А и В называется отношение с тем же заголовком, как и в отношениях А и В, и с телом, состоящим из множества всех кортежей t, принадлежащих отношению А и не принадлежащих отношению В. Произведение двух множеств является множеством всех таких упорядоченных пар элементов, что первый элемент в каждой паре берется из первого множества, а второй элемент в каждой паре берется из второго множества. Декартово произведение двух отношений должно быть множеством упорядоченных пар кортежей. Декартово произведение двух отношений А и В, где А и В не имеют общих имен атрибутов, определяется как отношение с заголовком, который представляет собой сцепление двух заголовков исходных отношений А и В, и телом, состоящим из множества всех кортежей t, таких, что t представляет собой сцепление кортежа а, принадлежащего отношению А, и кортежа b, принадлежащего отношению В. Кардинальное число результата равняется произведению кардинальных чисел исходных отношений А и В, а степень равняется сумме их степеней. Объединение – возвращает отношение, содержащее все кортежи, которые принадлежат или одному из 2х определённых отношений или обоим. Пересечение – возвращает отношение, содержащее все кортежи, которые принадлежат одновременно двум отношениям. Вычитание – возвращает отношение, содержащее все кортежи, которые принадлежат одному из двух определённых отношений и не принадлежат второму. Кванторы EXIXSTS – существует одно такое значение переменной x, что вычисление формулы WFF дает значение истина. FORALL – для всех значений переменной x вычисление формулы WFF дается значение истина. |
2 Имитационное моделирование простейших систем массового обслуживания. Для моделирования СМО должны быть известны 4 ее параметра λ-плотность вводящего потока, показывающая среднее чисто требований, поступающих в СМО в час (параметр загрузки). Поток заявок простейшкй μ-среднее число заявок, обслуживаемых одним аппаратом в час (пар-р загрузки). Распределение интервалов обслуживания подчиняется показательному распределению. N-число обслуж. аппаратов. Будем полагать что аппараты имеют одинаковую производительность обслуживания μ требований в час. М - максимальное число требований, которое может быть размещено в накопителе при ожидании обслуживания. Будем считать, что если очередное требование, поступающее в СМО в состоянии, когда будут заняты все аппараты и все места в накопителе то требование получает отказ в обслуживании и покидает СМО не обслуженным. В СМО постоянно протекают 2 случайных процесса: процесс загрузки, обусловленный параметром λ и процесс разгрузи, обуслов. параметром μ. В рез-те СМО имеет свои состояния. Опишем и обозначим эти состояния. S0-состояние когда в СМО нет ни одного требования, накопитель свободен, аппараты свободны, S1-когда а в СМ О одно требование, один аппарат занят, накопитель свободен, S2-в системе 2 требования, SN -в системе N требований, все аппараты загружены, накопитель свободен, SN+1|-в системе N+1 требований, все аппараты замяты, одно место в накопителе занято, SN+M—в системе N+М требований, все аппараты заняты, накопитель полностью загружен. В простейших системах, когда заявки поступают на обслуживание по одной и также после обслуживания по одной покидают. Смо, все состояния можно выстроить в одну динамическую цепочку, что удобно изобразить графически. Квадраты изображают состояние СМО, астрелки: верхние затрузку, нижние разгрузу
Хар-ки СМО. Средняя длина оч ф,еци ТМ=M0P0+M1P1+...+MnPn где Mn -количество занятых мест в накопителе в каждом из состояний S0Sn. Вероятность отказа очередному клиенту определяется как вероятность максимально загруженного состояния системы. Относительная пропускная способность ОПС=1-Ротк . Абсолютный отказ (заявок/час) А0=λ Ротк Абсолютная пропускная способность (заявок/час) АПС= Ротк *ОПС. Среднее время ожидания в накопителе (час) WМ:=ТМ/АПС. Среднее время нахождения заявки в СМО (ч ас) WS=WM+1/μ. Средняя длина очереди мастеров ТМ=N0P0+N1P1+...+NnPn Среднее число занятых мастеров ZN=N-TN. Среднее суммарное число заявок в СМО ТS=ТМ+ZК. 3 Этап логического проектирования базы данных. Этап логического проектирования – это моделирование всей информационной системы и ее отдельных составляющих в форме, соответствующей реальной СУБД. Т.о. данный этап ориентируется на конкретную СУБД и инструментальные свойства ПК. Этапы логического проектирования: Типы функциональных зависимостей Ключ отношения Нормальные формы отношений Логическая модель данных Выбор конкретной СУБД Перенос концептуальной модели предметной области на логическую модель данных. описание языка запроса. |

|
1 Реляционные объекты данных: домены, отношения. Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение. Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о Реляционная модель данных - это такая модель, которая представлена в виде совокупности отношений, совокупности кортежей. В основе реляционной модели использовано понятие отношения представляющего собой подмножество декартова произведения доменов. сотрудниках некоторой организации: Домен-это некоторое множество элементов(например, множество целых чисел или множество допустимых значений, которые может принимать объект по некоторому свойству). Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака). Схема отношения базы данных - это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Степень или "арность" схемы отношения - мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, то есть оно является 4-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута). Кортеж, соответствующий данной схеме отношения в базе данных, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или "арность" кортежа, т.е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Попросту говоря, кортеж - это набор именованных значений заданного типа. Отношение - это множество кортежей данной базы данных, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят "отношение-схема" и "отношение-экземпляр", иногда схему отношения называют заголовком отношения, а отношение как набор кортежей - телом отношения. На самом деле, понятие схемы отношения в базе данных ближе всего к понятию структурного типа данных в языках программирования. Было бы вполне логично разрешать отдельно определять схему отношения, а затем одно или несколько отношений с данной схемой. Однако в реляционных базах данных это не принято. Имя схемы отношения в таких базах данных всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных. Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками - кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят "столбец таблицы", имея в виду "атрибут отношения. Реляционная база данных - это набор отношений, имена которых совпадают с именами схем отношений в схеме базы данных. Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных баз данных все они определяются абсолютно формально и точно. |
2 Характеристики внешних запоминающих устройств Внешняя память (ВЗУ) предназначена для длительного хранения программ и данных, и целостность её содержимого не зависит от того, включен или выключен компьютер. В отличие от оперативной памяти, внешняя память не имеет прямой связи с процессором. В состав внешней памяти компьютера входят: накопители на жёстких магнитных дисках; накопители на гибких магнитных дисках; накопители на компакт-дисках; накопители на магнито-оптических компакт-дисках; накопители на магнитной ленте (стримеры) и др. 1 Накопители на гибких магнитных дисках
Дискета
состоит из
круглой полимерной
подложки, покрытой
с обеих сторон
магнитным
окислом и
помещенной
в пластиковую
упаковку, на
внутреннюю
поверхность
которой нанесено
очищающее
покрытие. В
упаковке сделаны
с двух сторон
радиальные
прорези, через
которые головки
считывания/записи
накопителя
получают доступ
к диску. В настоящее время наибольшее распространение получили дискеты со следующими характеристиками: диаметр 3,5 дюйма (89 мм), ёмкость 1,44 Мбайт, число дорожек 80, количество секторов на дорожках 18. Дискета устанавливается в накопитель на гибких магнитных дисках (англ. floppy-disk drive), автоматически в нем фиксируется, после чего механизм накопителя раскручивается до частоты вращения 360 мин-1. В накопителе вращается сама дискета, магнитные головки остаются неподвижными. Дискета вращается только при обращении к ней. Накопитель связан с процессором через контроллер гибких дисков. В последнее время появились трехдюймовые дискеты, которые могут хранить до 3 Гбайт информации. Они изготовливаются по новой технологии Nano2 и требуют специального оборудования для чтения и записи. 2. Накопители на жестких магнитных дисках
Как и у дискеты, рабочие поверхности платтеров разделены на кольцевые концентрические дорожки, а дорожки — на секторы. Головки считывания-записи вместе с их несущей конструкцией и дисками заключены в герметически закрытый корпус, называемый модулем данных. При установке модуля данных на дисковод он автоматически соединяется с системой, подкачивающей очищенный охлажденный воздух. Поверхность платтера имеет магнитное покрытие толщиной всего лишь в 1,1 мкм, а также слой смазки для предохранения головки от повреждения при опускании и подъёме на ходу. При вращении платтера над ним образуется воздушный слой, который обеспечивает воздушную подушку для зависания головки на высоте 0,5 мкм над поверхностью диска. Винчестерские накопители имеют очень большую ёмкость: от 10 до 100 Гбайт. У современных моделей скорость вращения шпинделя (вращающего вала) обычно составляет 7200 об/мин, среднее время поиска данных 9 мс, средняя скорость передачи данных до 60 Мбайт/с. В отличие от дискеты, жесткий диск вращается непрерывно. Все современные накопители снабжаются встроенным кэшем (обычно 2 Мбайта), который существенно повышает их производительность. Винчестер связан с процессором через контроллер жесткого диска. 3. Накопители на компакт-дискахЗдесь носителем информации является CD-ROM (Сompact Disk Read-Only Memory - компакт диск, из которого можно только читать). CD-ROM представляет собой прозрачный полимерный диск диаметром 12 см и толщиной 1,2 мм, на одну сторону которого напылен светоотражающий слой алюминия, защищенный от повреждений слоем прозрачного лака. Информация на диске представляется в виде последовательности впадин (углублений в диске) и выступов (их уровень соответствует поверхности диска), расположеных на спиральной дорожке, выходящей из области вблизи оси диска. На каждом дюйме (2,54 см) по радиусу диска размещается 16 тысяч витков спиральной дорожки. Емкость CD достигает 780 Мбайт. Информация наносится на диск при его изготовлении и не может быть изменена. CD-ROM обладают высокой удельной информационной емкостью, что позволяет создавать на их основе справочные системы и учебные комплексы с большой иллюстративной базой. Cчитывание информации с CD-ROM происходит с достаточно высокой скоростью, хотя и заметно меньшей, чем скорость работы накопителей на жестком диске. В отличие от магнитных дисков, компакт-диски имеют не множество кольцевых дорожек, а одну — спиральную, как у грампластинок. В связи с этим, угловая скорость вращения диска не постоянна. Она линейно уменьшается в процессе продвижения читающей лазерной головки к краю диска. Для работы с CD-ROM нужно подключить к компьютеру накопитель CD-ROM (рис. 2.9), преобразующий последовательность углублений и выступов на поверхности CD-ROM в последовательность двоичных сигналов. Для этого используется считывающая головка с микролазером и светодиодом. |
Сегодня почти все персональные компьютеры имеют накопитель CD-ROM. Но многие мультимедийные интерактивные программы слишком велики, чтобы поместиться на одном CD. На смену технологии СD-ROM стремительно идет технология цифровых видеодисков DVD. Эти диски имеют тот же размер, что и обычные CD, но вмещают до 17 Гбайт данных, т.е. по объему заменяют 20 стандартных дисков CD-ROM. На таких дисках выпускаются мультимедийные игры и интерактивные видеофильмы отличного качества, позволяющие зрителю просматривать эпизоды под разными углами камеры, выбирать различные варианты окончания картины, знакомиться с биографиями снявшихся актеров, наслаждаться великолепным качеством звука. 4. Записывающие оптические и магнитооптические накопители Записывающий накопитель CD-R (Compact Disk Recordable) способен, наряду с прочтением обычных компакт-дисков, записывать информацию на специальные оптические диски емкостью 650 Мбайт. В дисках CD-R отражающий слой выполнен из золотой пленки. Между этим слоем и поликарбонатной основой расположен регистрирующий слой из органического материала, темнеющего при нагревании. В процессе записи лазерный луч нагревает выбранные точки слоя, которые темнеют и перестают пропускать свет к отражающему слою, образуя участки, аналогичные впадинам. Накопители CD-R, благодаря сильному удешевлению, приобретают все большее распространение. Накопитель на магнито-оптических компакт-дисках СD-MO (Compact Disk — Magneto Optical) (рис. 2.10). Диски СD-MO можно многократно использовать для записи. Ёмкость от 128 Мбайт до 2,6 Гбайт. МО накопитель построен на совмещении магнитного и оптического принципа хранения информации. Записывание информации производится при помощи луча лазера и магнитного поля, а считование при помощи одного только лазера. Накопитель WARM (Write And Read Many times), позволяет производить многократную запись и считывание. 3 Использование функционального подхода к проектированию состава и структуры информационных систем. Основные процедуры технологии проектирования ИС:
Этап анализа предполагает подробное исследование бизнес-процессов (функций, определенных на этапе выбора стратегии) и информации, необходимой для их выполнения (сущностей, их атрибутов и связей (отношений)). На этом этапе создается информационная модель, а на следующем за ним этапе проектирования — модель данных. Вся информация о системе, собранная на этапе определения стратегии, формализуется и уточняется на этапе анализа. Особое внимание следует уделить полноте переданной информации, анализу информации на предмет отсутствия противоречий, а также поиску неиспользуемой вообще или дублирующейся информации. Как правило, заказчик не сразу формирует требования к системе в целом, а формулирует требования к отдельным ее компонентам. Уделите внимание согласованности этих компонентов. Аналитики собирают и фиксируют информацию в двух взаимосвязанных формах:
Существую три основных свойства бизнес-функции:
Двумя классическими результатами анализа являются:
Эти результаты являются необходимыми, но не достаточными. К достаточным результатам следует отнести диаграммы потоков данных и диаграммы жизненных циклов сущностей. Довольно часто ошибки анализа возникают при попытке показать жизненный цикл сущности на диаграмме ER. |
|
1 Подсистемы и функциональные узлы ЭВМ. |
2 Одноканальная системы массового обслуживания с отказами, многоканальная система массового обслуживания с отказами. Одноканальная и многоканальная СМО с отказами В качестве примера рассмотрим одноканальную систему массового обслуживания (например, одну телефонную линию), в которой заявка, заставшая канал занятым, не становится в очередь, а покидает систему (получает «отказ»). Это—-дискретная система с непрерывным временем и двумя возможными состояниями: х0—канал свободен, х1 — канал занят. Переходы из состояния в состояние обратимы. Схема возможных переходов показана на рис. 19.2.2.
Для n-канальной системы такого же типа схема возможных переходов показана на рис. 19.2.3. Состояние х0—все каналы свободны; х1—занят ровно один канал, х2—занято ровно два канала и т. д, 3 Характеристика и назначение основных обласией внутренней памяти: стандартной, EMS, UMA, HMA, XMS. Вся адресуемая внутренняя память делится на 3 области:
Дополнительная память – область всей физической памяти, расположенной в адресном пространстве выше 1 МБ. Ее объем указывается после выполнения теста начального включения ПК в строке Extended Memory. Отображаемая память EMS – программная спецификация использования дополнительной памяти DOS-программами реального режима через 4 страницы по 16 Кб. Эти страницы, расположенные в области UMA, могут отображать любую область дополнительной памяти. Пригодна для хранения данных, но не исполняемого в данный момент программного кода, используется в основном старым программным обеспечением. Расширенная память XMS – программная спецификация использования дополнительной памяти DOS-программами через переключение в защищенный режим и обратно. Поддерживается драйвером HYMEM.SYS. Высокая память, HMA – адресуется непосредственно без переключения режимов работы микропроцессора, поэтому может использоваться для хранения и данных, и программ. |
|
1 Построение инфологической модели предметной области. Семантический подход. Семантический подход– ориентирован на смысловые характеристики информации – так называемый подход "от реального мира". Наиболее распространен. Предполагает изменение границ предметной области, непрерывное развитие автоматизированной, экономической информационной системы. Деление на синтаксис и семантику условно и актуально на I этапе проектирования БД. Назначение модели: - семантическое описание ПО и представление информации для обоснования выбора видов моделей и структур данных, которые в дальнейшем будут использоваться в системе. Достоинства модели: относительная простота модели; применение естественного языка; легкость понимания. Все это дает возможность использовать данную модель как инструмент для общения с будущими пользователями с целью сбора информации для описания и проектирования ПО. |
2 Модель сообщений Windows. Модели событий. Модель сообщений Windows Особенностью поведения приложения, работой которого управляют события, является то, что приложение после создания и инициализации всех визуальных и не визуальных компонентов (работа взаимосвязанных методов Create) переходит в бесконечный цикл ожидания событий (Events) от окружения (работа метода Run). Окружением для приложения Delphi выступает системная среда, создаваемая Windows 95. О всех, происходящих в системе событиях : нажатии клавиши на клавиатуре, перемещении курсора мыши, изменении конфигурации и содержимого системных и инициализированных файлов, ядро Windows информирует открытые окна приложений, посылая сообщения (Messages) их оконным функциям. Источниками сообщений кроме ядра Windows могут быть и драйверы устройств , в том числе, клавиатуры и мыши. Например, перемещается курсор мыши - посылается сообщение wm_MouseMove; создается или перемещается окно - wm_Create или wm_Move; выполняется щелчок по кнопкам мыши - wm_LButtonDown, wm_RButtonDown; нажимается клавиша или комбинация клавиш на клавиатуре - wm_Char (точнее, при нажатии клавиш возникают нотификационные сообщения - cn_KeyDown (нажата функциональная клавиша или комбинация клавиш и кнопок мыши), cn_KeyUp(отпущена) и cn_Char (нажата клавиша основного наборного поля)). Все сообщения помещаются в системную очередь, а из системной очереди пересылаются в очередь приложения, которому они предназначены. Приложение извлекает сообщение из очереди и передает его соответствующей оконной функции. С оконной функцией ассоциируется оконный элемент управления, расположенный в соответствующем окне приложения. Определение какому именно элементу предназначено событие осуществляется по правилам :
не получить его, так как его перехватил другой оконный элемент (например, форма имеет возможность перехватывать события от клавиатуры, не пропуская его элементу, находящемуся в «фокусе ввода»). Таким образом, жизненный цикл события с момента его генерации состоит из : поиска элемента, которому принадлежит событие, то есть определение источника события (Sender); поиска метода-обработчика данного события; обработки события и модификации состояния или поведения элемента; удаления события из очереди событий. Разработанное приложение Delphi дает полный доступ пользователю к событийной модели Windows, упрощая процесс обработки того или иного события. Модель событий. Общая характеристика событий от клавиатуры, от мыши. Любой элемент может игнорировать событие, если не содержит собственный обработчик, обработать, или не получить, если событие, адресованное ему, перехвачено другим элементом. Поскольку обработчик события – это метод компонента, внутри этого метода при разработке кода должны быть доступны основные свойства и методы этого класса. Поэтому с позиции объектной модели Delphi событие – это тип, специального процедурного типа, который используется для определения процедуры обработки события. Event->Свойство:=>указатель на процедурный тип. В заголовке процедурного типа обязательным параметром является Sender: TObject, он является указателем на элемент – источник события. Каждый компонент наделен своим множеством обрабатываемых событий. Условно события можно разделить на 5 групп: 1.События от клавиатуры - Могут обрабатывать только оконные элементы, которые могут менять фокус ввода. Форма, как основной оконный элемент может перехватывать события от клавиатуры, адресованное элементу управления, находящемуся в фокусе ввода, если установлено событие KeyPreview .При нажатии клавиши основного наборного поля возникает событие OnKeyPress. Если используются функциональные клавиши, клавиши управления, либо комбинации (Alt+…,Shift+… и т.д.), то возникают события OnKeyDown, OnKeyUp. Для того, чтобы обработать события, поступающие от функциональных клавиш, используются константы виртуальных клавиш: VK_F1, VK_Enter,VK_Home… 2.События от мыши - Относятся к классу позиционных событий, то есть все компоненты, которые визуально доступны курсору мыши, могут обрабатывать события от этого устройства. OnClick (по умолчанию), OnDblClick. OnMouseDown, OnMouseUp, OnMouseMove – x,y:integer – передают координаты курсора мыши в координатной сетке владельца события. С помощью обработчика событий от мыши можно реализовать событие перетаскивания компонентов на этапе RunTime (Drag&Drop).Основных событий в механизме два:1)OnDragOver-это событие генерируется для компонента, над территорией которого проносится захваченный курсором компонент. 2) OnDragDrop – обеспечивает встраивание. Перетаскивание возможно только тогда, когда свойство DragMode - Automatic. 3.События, возникающие на этапе создания, прорисовки и визуализации компонентов : OnCreate – возникает при создании экземпляра класса (1 раз); OnPaint – прорисовка; OnResize – изменение размера; OnShow (OnHide); OnActivate (OnDeactivate) – относится к окну когда оно становится окном переднего плана; OnOpen (OnClose) – при открытии 4.События для компонентов, способных вводить исходные данные –OnChange по умолчанию для TEdit? TDataSource и т.д. 5.События для компонентов, способных принимать фокус ввода: OnEnter - принимает фокус ввода;OnExit – теряет фокус ввода. |
3 Одноканальная система массового обслуживания с накопителем, многоканальная система массового обслуживания с накопителем. Рассмотрим общую схему системы массового обслуживания для разомкнутых смешанных систем. Она состоит из обслуживающей и обслуживаемой систем. Обслуживаемая система включает совокупность источников требований и водящего потока требований. Требование -каждый отдельный запрос на выполнение какой-либо работы (на производство услуги). Источник требования - объект (человек, механизм и т.д.), который может послать в обслуживающую систему одновременно только одно требование Обслуживающая система состоит из накопителя и механизма обслуживания. Обслуживанием считается удовлетворение поступившего запроса на выполнение услуги. Механизм обслуживания состоит из нескольких обслуживаюших аппаратов. Обслуживающий аппарат - это часть механизма обслуживания. которая способна удовлетворить одновременно только одно требование (ремонтный рабочий или бригада, кран, экскаватор, пост мойки и т.д.). После окончания обслуживания требования покидают систему, образуя выходящей поток требований. Для моделирования СМОРС должны быть известны четыре ее параметра λ - плотность входящего потока, показывающая среднее число требований, поступающих в СМО в час (параметр загрузки). Поток заявок простейший. μ -среднее число заявок обслуживаемых одним аппаратом в час (параметр разгрузки). Распределение интервалов обслуживания подчиняется показательному распределению N - чисто обслуживающих аппаратов. Будем полагать, что аппараты имеют одинаковую производительность обслуживания μ требований/час. М - максимальное число требований, которое может быть размещено в накопителе при ожидании обслуживания. Будем считать, что если очередное требований поступающее в СМО в состоянии, когда буду т заняты все аппараты и все места в накопителе то требовании получает отказ в обслуживании и покидает систему массового обслуживания не обслуженным. В системе массового обслуживания постоянно протекают два случайные процесса: - процесс загрузки обуотовтенный параметром λ - процесс разгрузки обуотовтенный параметром μ В результате чего СМО меняет свои состояния Для расчета вероятностей состояний используется формула связывающая вероятности двух соседних состояний из графа состояний по следующему правилу: вероятность Рi равна вероятности предыдущего состояния Рi-1 умноженной на отношение показателя загрузки к показателю разгрузки Si-1 состояния.
Все вероятности связаны между собой, поэтому выразим их через Ро
Воспользуемся формулой:
Получим уравнение с одним неизвестным Ро. из которого и определим
3.1 Если b>1, то b=b-1 и y=0 3.2 Если (b≤1)∩d>0, то b=∆τi ; y=1; d=d-1 3.3 Если (b≤1)∩d=0, то b=0 и y=1 1.1 Если a>1, то а=а-1 и х=0 1.2 Если а=1, то а=∆t и х=1 (5) |
|
Задача линейного и нелинейного программирования Термин «линейное программирование» возник в результате неточного перевода английского «linear programming». Одно из значений слова «programming» - составление планов, планирование. Следовательно, правильным переводом «linear programming» было бы не «линейное программирование», а «линейное планирование», что более точно отражает содержание дисциплины. Можно сказать, что линейное программирование применимо для построения математических моделей тех процессов, в основу которых может быть положена гипотеза линейного представления реального мира: экономических задач, задач управления и планирования, оптимального размещения оборудования и пр. Задачами линейного программирования называются задачи, в которых линейны как целевая функция, так и ограничения в виде равенств и неравенств. Кратко задачу линейного программирования можно сформулировать следующим образом: найти вектор значений переменных, доставляющих экстремум линейной целевой функции при m ограничениях в виде линейных равенств или неравенств. Линейное программирование представляет собой наиболее часто используемый метод оптимизации. К числу задач линейного программирования можно отнести задачи: рационального использования сырья и материалов; задачи оптимизации раскроя; оптимизации производственной программы предприятий; оптимального размещения и концентрации производства; составления оптимального плана перевозок, работы транспорта; управления производственными запасами; и многие другие, принадлежащие сфере оптимального планирования. Так, по оценкам американских экспертов, около 75% от общего числа применяемых оптимизационных методов приходится на линейное программирование. Около четверти машинного времени, затраченного в последние годы на проведение научных исследований, было отведено решению задач линейного программирования и их многочисленных модификаций. В настоящее время линейное программирование является одним из наиболее употребительных аппаратов математической теории оптимального принятия решения. Для решения задач линейного программирования разработано сложное программное обеспечение, дающее возможность эффективно и надежно решать практические задачи больших объемов. Эти программы и системы снабжены развитыми системами подготовки исходных данных, средствами их анализа и представления полученных результатов. Линейное программирование тесно связано с другими методами математического программирования (например, нелинейного программирования, где целевая функция нелинейна). Современные методы линейного программирования достаточно надежно решают задачи общего вида с несколькими тысячами ограничений и десятками тысяч переменных. Для решения сверхбольших задач используются уже, как правило, специализированные методы. Любая задача линейного программирования приводится к стандартной (канонической) форме основной задачи линейного программирования, которая формулируется следующим образом: найти неотрицательные значения переменных X1 , X2 , Xn , удовлетворяющих ограничениям в виде равенств: A1 1X1 + A1 2X2 + … + A1 nXn = B1; A2 1X1 + A2 2X2 + … + A2 nXn = B2; …………………………………… Am 1X1 + Am 2X2 + … + Am nXn = Bm; Xj ≥ 0, j=1,…,n и обращающих в максимум линейную функцию этих переменных: E = C1X1 + C2X2 + … + CnXn max При этом также требуется, чтобы правые части равенств были неотрицательны, т.е. должны соблюдаться условия: Bj ≥ 0, j=1,…,n Приведение к стандартной форме необходимо, так как большинство методов решения задач линейного программирования разработано именно для стандартной формы. Для приведения к стандартной форме задачи линейного программирования может потребоваться выполнить следующие действия: - перейти от минимизации целевой функции к ее максимизации; - изменить знаки правых частей ограничений; - перейти от ограничений-неравенств к равенствам; - избавиться от переменных, не имеющих ограничений на знак. Задача нелинейного программирования В общем виде задача нелинейного программирования состоит в определении максимального (минимального) значения функции f(x1,x2,…,xn) при условии, что ее переменные удовлетворяют соотношениям
Большинство методов нелинейного программирования используют идею движения в n-мерном пространстве в направлении оптимума. |
При этом из некоторого исходного или промежуточного состояния Uk осуществляется переход в следующее состояние Uk+1 изменением вектора Uk на величину DUk, называемую шагом, т.е. Uk+1=Uk+DUk (1) В ряде методов шаг, т.е. его величина и направление определяется как некоторая функция состояния Uk DUk=f(Uk) (2) Следовательно, согласно (1) новое состояние Uk, получаемое в результате выполнения шага (2) может рассматриваться как функция исходного состояния Uk Uk+1=Uk+f(Uk) (3) В некоторых методах DUk обусловлен не только состоянием Uk, но и рядом предшествующих состояний DUK=f(Uk) ,Uk-1...,Uk-2 (4) Uk+1=Uk+f(Uk),Uk-1...,Uk-2 (5) Естественно, что алгоритмы поиска типа (5) являются более общими и принципиально могут обеспечить более высокую сходимость к оптимуму, т.к. используют больший объем информации о характере поведения оптимальной функции. В настоящее время для решения подобных задач разработано значительное число методов, однако нельзя отдать предпочтение какому-либо одному. Выбор метода определяется сложностью объекта и решаемой задачей оптимизации. Методы нелинейного программирования в соответствии со способом определения шага поиска R(U) можно отнести к одному из 3-х типов: 1.Безградиентные методы 2.Градиентные методы 3.Методы случайного поиска. Все эти методы можно назвать прямыми итеративными методами. Задачи оптимизации (экстремальные задачи) называются задачами нелинейного программирования (сокращенно задачами НЛП), если среди функций f, g1...gm, h1..., hk имеется хотя бы одна нелинейная функция. Записи (1)-(3) и (4)-(5) являются стандартными постановками задач минимума и максимума (обратите внимание на знаки неравенств в (2) и (5)). Задачи НЛП, как и любые другие задачи оптимизации, являются математическими моделями некоторых практических задач принятия решения. |