
Рефераты по рекламе
Рефераты по физике
Рефераты по философии
Рефераты по финансам
Рефераты по химии
Рефераты по хозяйственному праву
Рефераты по цифровым устройствам
Рефераты по экологическому праву
Рефераты по экономико-математическому моделированию
Рефераты по экономической географии
Рефераты по экономической теории
Рефераты по этике
Рефераты по юриспруденции
Рефераты по языковедению
Рефераты по юридическим наукам
Рефераты по истории
Рефераты по компьютерным наукам
Рефераты по медицинским наукам
Рефераты по финансовым наукам
Рефераты по управленческим наукам
Психология и педагогика
Промышленность производство
Биология и химия
Языкознание филология
Издательское дело и полиграфия
Рефераты по краеведению и этнографии
Рефераты по религии и мифологии
Рефераты по медицине
Рефераты по сексологии
Рефераты по информатике программированию
Краткое содержание произведений
Реферат: Архитектура IA-32
Реферат: Архитектура IA-32
Введение. 3
Технология SIMD.. 4
Краткое обозрение технологий SIMD.. 5
Технология MMX.. 5
SSE.. 5
SSE2. 6
SSE3. 6
Микроархитектура Intel NetBurst 7
Цели, для которых была разработана Микроархитектура Intel NetBurst 7
Обзор конвейера микроархитектуры Intel NetBurst 7
Блок начальной загрузки. 8
Беспорядочное ядро. 9
Секция изъятий. 9
Обзор блока начальной загрузки конвейера. 11
Предвыборка. 11
Декодер. 11
Исполнительный кэш трасс. 11
Предсказание ветвей. 11
Обзор исполнительного ядра. 13
Задержка инструкций и производительность. 13
Исполнительные блоки и выводные порты.. 13
Кэши. 15
Предвыборка данных. 16
Плюсы и минусы программной и аппаратной предвыборки. 16
Загрузка и хранение. 18
Управление хранением.. 18
Технология Hyper-Threading. 19
Ресурсы процессора и технология Hyper-Threading. 20
Реплицированные ресурсы.. 20
Разделенные ресурсы.. 20
Разделяемые ресурсы.. 20
Микроархитектура конвейера и технология НТ. 21
Блок начальной загрузки конвейера. 21
Исполнительное ядро. 21
Извлечение. 21
Список использованной литературы.. 22
Введение
В этой работе проводиться обзор основных моментов необходимых для оптимизации программного обеспечения для текущего поколения процессоров основанных на технологии IA-32, таких как Intel Pentium 4, Intel Xeon и Intel Pentium M. Работа дает базу для понимания правильного подхода к кодированию для технологии IA-32.
Ключевые моменты, повышающие производительность процессоров текущего поколения на базе IA-32:
· Расширение инструкций SIMD поддерживающих технологию MMX, потоковые расширения инструкций SIMD (SSE), потоковые расширения инструкций SIMD второй редакции (SSE2) и потоковые расширения инструкций SIMD третьей редакции (SSE3)
· Микроархитектуры позволяющие выполнение большего количества инструкций на высоких тактовых частотах, иерархия высокоскоростных КЭШей и возможность получать данные по высокоскоростной системной шине
· Поддержка технологии Hyper Threading
Процессоры Intel Pentium 4 и Intel Xeon построены на микроархитектуре NetBurst. Микроархитектура процессора Intel Pentium M основывается на балансе производительности и низкого энергопотребления.
Технология SIMD
Один из путей к увеличению производительности процессора – это использование технологии вычислений основанной на том, что одна команда оперирует многими данными (single-instruction, multiple data (SIMD)).
Вычисления с помощью SIMD (рисунок 1) представлены в архитектуре IA-32 технологией MMX.Технология MMX позволяет вычислениям SIMD производиться над упакованными целыми числами в виде байтов, слов и двойных слов. Эти целые содержаться в наборе из восьми 64-битных регистрах называемых MMX регистрами (рисунок 2).
В процессоре Intel Pentium III технология SIMD была расширена с помощью потоковых расширений SIMD (SSE). SSE позволяет производить вычисления SIMD над операндами, содержащими четыре упакованных элемента с плавающей точкой одинарной точности. Эти операнды могут храниться как в памяти, так и в одном из 128-битных регистров называемых XMM регистрами (рисунок 2). SSE также расширяет вычислительные способности SIMD, путем добавления дополнительных 64-битных MMX команд.
Рисунок 1 показывает типичную схему вычислений SIMD. Два блока по четыре упакованных элемента данных (X1, X2, X3, X4 и Y1, Y2, Y3,Y4), обрабатываемых параллельно с помощью одной операцией над каждой парой элементов данных (X1 и Y1, X2 и Y2, X3 и Y3 и X4 и Y4). Результаты четырех параллельных вычислений сортируются в набор из четырех элементов данных.
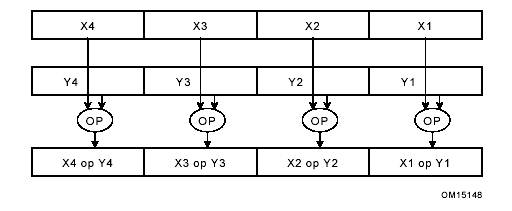
Рисунок 1. Схема вычислений SIMD
В процессорах Pentium 4 и Intel Xeon модель вычислений SIMD была далее расширена с помощью SSE2 и SSE3.
SSE2 работает с операндами, хранящимися в памяти или в XMM регистрах. Технология SSE2 расширяет вычисления SIMD для работы с упакованными элементами данных с плавающей точкой двойной точности и 128-битными упакованными целыми числами. В SSE2 введены 144 дополнительные команды для работы с двумя элементами данных с плавающей точкой двойной точности или над упакованными целыми числами в виде шестнадцати байтов, восьми слов, четырех двойных слов и двух четверных слов.
SSE3 улучшает x87, SSE и SSE2 с помощью добавления тринадцати инструкций, позволяющих повысить производительность приложений в специфичных областях. Таких как: обработка видео, комплексная арифметика синхронизация потоков. SSE3 дополняет SSE и SSE2 с помощью команд ассиметричной обработки данных SIMD, команд позволяющих горизонтальные вычисления, а так же команд позволяющих избежать загрузки в кэш разделенных нитей.
Полный набор технологий SIMD (MMX, SSE, SSE2, SSE3) в технологии IA-32 дает возможность программисту разрабатывать алгоритмы, совмещающие операции над упакованными 64-битными и 128-битными целыми, и операндами с плавающей точкой одинарной и двойной точности.

Рисунок 2. Регистры SIMD
SIMD улучшает выполнение 3D графики, распознавание речи, обработки изображений, научных приложений и приложений удовлетворяющих следующим характеристикам:
· Внутренняя параллельность
· Рекурсивный доступ к областям памяти
· Локальные рекурсивные операции над данными
· Контроль над потоком независимых данных
Инструкции SIMD для работы с числами с плавающей точкой полностью поддерживают стандарт IEEE 754 «для бинарной арифметики чисел с плавающей точкой». Они доступны во всех режимах работы процессора.
Технологии SSE, SSE2 и MMX – это архитектурные дополнения архитектуры IA-32. SSE и SSE2 также включают инструкции кэширования и организации памяти, которые могут улучшить использование КЭШа и производительность приложений.
Краткое обозрение технологий SIMDТехнология MMX
Технология MMX основывается на:
· 64-битных MMX-регистрах
· поддержке операций SIMD над упакованными целыми в виде байтов, слов и двойных слов
Инструкции MMX полезны в мультимедийных и коммуникационных приложениях
SSE
SSE основывается на:
· 128-битных XMM-регистрах
· 128-битных типах данных, содержащих четыре упакованных операнда с плавающей точкой одинарной точности
· инструкциях предвыборки данных
· инструкциях хранения в течение неопределенного срока и других инструкций кэширования и упорядочивания памяти
· дополнительной поддержке 64-битных целых SIMD
Инструкции SSE полезны при обработке трехмерной геометрии, 3D-рендеринга, распознавания речи, а также для кодирования и декодирования видео.
SSE2
SSE2 добавляют следующее:
· 128-битный тип данных с двумя упакованными операндами с плавающей точкой двойной точности
· 128-битные типы данных для целочисленных операций SIMD над целыми в виде шестнадцати байт, восьми слов, четырех двойных слов или двух четверных слов.
· Поддержку арифметики SIMD над 64-битными целочисленными операндами
· Инструкции для конвертирования между новыми и существующими типами данных
· Дополнительная поддержка перемешивания данных
· Дополнительная поддержка операций кэширования и упорядочивания памяти
Инструкции SSE2 полезны для обработки 3D графики, кодирования и декодирования видео и шифрования.
SSE3
SSE3 добавляет следующее:
· SIMD операции с плавающей точкой для ассиметричных и горизонтальных вычислений
· Специальную 128-битную загрузочную инструкцию для избежания разделения нити КЭШа
· x87 FPU – инструкцию для конвертирования в целое независимо от FCW (floating-point control word)
· инструкции для поддержки синхронизации потоков
Инструкции SSE3 могут применяться в научных, видео и многопоточных приложениях.
Микроархитектура Intel NetBurst
В этом разделе описываются основные моменты микроархитектуры Intel NetBurst. Он дает техническую базу необходимую для понимания оптимизационных рекомендаций и правил кодирования процессоров Intel Pentium 4 и Intel Xeon.
Микроархитектура Intel NetBurst она спроектирована для достижения высокой производительности при целочисленных вычислениях и вычислениях операндов с плавающей точкой на высоких частотах. Она основывается на следующих моментах:
· гиперковейерная технология позволяющая работать на высоких частотах (до 10 ГГц)
· высокопроизводительный, четырехкратный шинный интерфейс для системной шины микроархитектуры Intel NetBurst
· скоростной движок для снижения задержек исполнения целочисленных инструкций
· спекулятивное разупорядоченное исполнение для поддержки параллелизма
· суперскалярная выдача для поддержки параллелизма
· поддержка аппаратного переименования регистров для исключения ограничений пространства имен
· 64-байтные нити КЭШа
· аппаратная предвыборка
Цели, для которых была разработана Микроархитектура Intel NetBurst
Цели, для которых была разработана Микроархитектура Intel NetBurst:
· для обеспечения наследственности приложений IA-32 и приложений основанных на SIMD на высокопроизводительных системах
· для оперирования на высоких тактовых частотах и для масштабирования высокой производительности и высоких тактовых частот в будущем
Преимущества микроархитектуры Intel NetBurst:
· многоконвейерный дизайн позволяющий работать на высоких тактовых частотах (различные части кристалла работают с различными тактовыми частотами)
· конвейер, оптимизированный для обработки часто исполняемых инструкций (часто исполняемые инструкции при обычных условиях эффективно декодируются и исполняются с меньшими задержками)
· внедрение специальных техник для исправления зависания конвейера. Среди них: параллельное выполнение, буферизация и спекуляция. Микроархитектура выполняет инструкции динамически и беспорядочно, так что время, которое необходимое для выполнения каждой отдельной инструкции не всегда может быть определено.
Обзор конвейера микроархитектуры Intel NetBurst
Конвейер микроархитектуры Intel NetBurst состоит из:
· блока начальной загрузки упорядоченных команд
· беспорядочного суперскалярного исполнительного ядра
· блок изъятия упорядоченных команд
Блок начальной загрузки поставляет инструкцию в программном порядке в беспорядочное ядро. Оно выбирает и декодирует инструкции IA-32. Декодированные инструкции переводятся в микрокоманды. Основная задача блока начальной загрузки состоит в доставлении непрекращающегося потока микрокоманд в исполнительное ядро в программном порядке.
Беспорядочное ядро жестко переупорядочивает микрокоманды, так что те микрокоманды, чьи входные данные готовы (и имеют доступные исполнительные ресурсы) могли бы быть выполнены как можно быстрее. Ядро может выдавать несколько микроопераций за цикл.
Секция изъятия убеждается, что результаты обработки произвелись в правильном порядке и что правильные архитектурные режимы обновлены.
Рисунок 3 отображает схему основных функциональных блоков конвейера микроархитектуры Intel NetBurst. Ниже перечисленные разделы проводят обзор каждого из блоков.
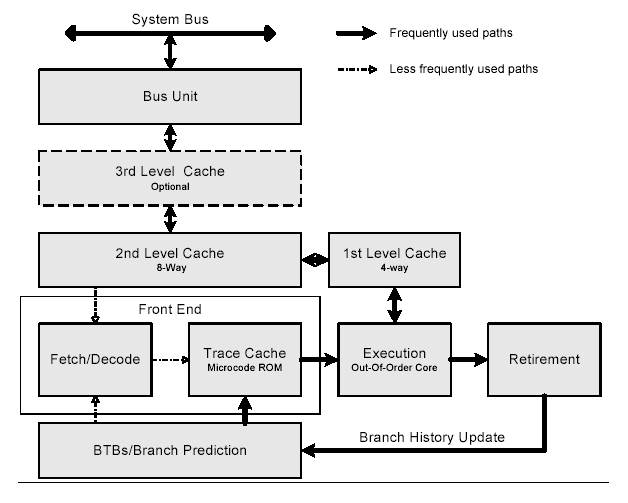
Рисунок 3. Микроархитектура Intel NetBurst
Блок начальной загрузки
Блок начальной загрузки микроархитектуры Intel NetBurst состоит из двух частей:
· Блок выборки/декодирования
· Исполнительный кэш трасс
Он выполняет следующие функции:
· Предвыборка инструкций IA-32 предпочтительных для исполнения
· Выборка требуемых инструкций, которые не были предвыбраны
· Декодировка инструкций в микрокоманды
· Генерация кода сложных инструкций и кода специального назначения
· Доставка декодированных инструкций из исполнительного КЭШа трасс
· Предсказание ветвлений на основе улучшенного алгоритма
Блок начальной загрузки разработан для избежания двух проблем являющихся источниками задержек:
· Уменьшение времени необходимого для декодирования инструкций полученных из источника
· Уменьшения бесполезного кода связанного с ветвлениями или точками ветвления внутри нити КЭШа
Инструкции декодируются и выбираются «переводящим» движком. «Переводящий» движок затем преобразует декодированные инструкции в последовательности микрокоманд называемые трассами. Далее трассы помещаются в исполнительный кэш трасс.
Исполнительный кэш трасс сохраняет микрокоманды на пути исполнения потока программы, где результаты ветвлений в коде уже интегрированы в ту же нить КЭШа. Это увеличивает поток инструкций из КЭШа и позволяет использовать объем КЭШа более эффективно, так как нет необходимости хранить в нем инструкции, которые ответвились и никогда не будут обработаны.
Кэш трасс может доставлять до трех микрокоманд к ядру за такт. Исполнительных кэш трасс и «переводящий» движок имеют кооперированный механизм предсказания ветвей. Точки ветвлений предсказываются на основе их линейного адреса (используя логику предсказания ветвлений и выборок) так скоро, как это возможно. Точки ветвлений берутся из исполнительного КЭШа трасс, если они были кэшированы, или из иерархии памяти. Информация «переводящего» движка о ветвлении используется при формировании трасс по наилучшим маршрутам.
Беспорядочное ядро
Возможность ядра выполнять инструкции без порядка – ключевой фактор для поддержки параллелизма. Этот блок позволяет процессору переупорядочивать инструкции так, что если одна микрокоманда ожидает данные или необходимый ресурс, другая микрокоманда, появившаяся позже, в программе может быть выполнена. Это влечет за собой то, что когда часть конвейера вынужденно задерживается, эта задержка может быть перекрыта за счет других операций, выполняемых параллельно, или исполнением микрокоманд из очереди в буфере.
Ядро спроектировано так, чтобы организовать параллельное выполнение. Оно может отправлять до шести микрокоманд в порты вывода за цикл (рисунок 4). Заметим, что шесть микрокоманд превосходят мощность КЭШа трасс и блока изъятия. Большая мощность ядра сделана, чтобы не обращать внимание на нагрузки более трех микрокоманд и для достижения большей производительности выдачи с помощью гибкости при выдаче микрокоманд в различные исполнительные порты.
Большинство исполнительных блоков ядра могут начинать выполнение новой микрокоманды каждый цикл, так что несколько инструкций могут быть выполнены одновременно в каждом блоке конвейера. Некоторые из инструкций арифметико-логического устройства (ALU) могут выполняться дважды за цикл, множество из инструкций обработки данных с плавающей точкой обрабатываются за два цикла. Наконец, микрокоманды могут быть начаты выполняться вне программного порядка, как только их входные данные готовы и ресурсы доступны.
Секция изъятий
Секция изъятий получает результаты выполненных микрокоманд из исполнительного ядра и выстраивает их в соответствии с оригинальным порядком в программе. Для семантически правильного исполнения, результаты инструкций IA-32 должны быть восстановлены в оригинальном порядке перед их извлечением.
Когда микрокоманда завершена и ее результаты записаны по назначению, она извлекается. За цикл могут быть извлечены три микрокоманды. Переупорядочивающий буфер (ROB) – это блок в процессоре который буферизирует завершенные микрокоманды, обновляет их архитектурный вид и производит упорядочивание в исключительных ситуациях.
Секция изъятия так же наблюдает за ветвлениями и отсылает обновленную информацию о точках ветвления в буфер точек ветвлений (BTB). Это позволяет обновлять историю ветвлений. Рисунок 3 отображает пути часто го исполнения внутри микроархитектуры Intel NetBurst, такие как исполнительные циклы, взаимодействующие с иерархией уровней КЭШа и системной шиной.
Следующие разделы дают более детальное описание операций блока начальной загрузки и исполнительного ядра.
Обзор блока начальной загрузки конвейера
Следующая информация о работе блока начальной загрузки будет полезна для обеспечения программного обеспечения возможностями предвыборки, предсказания ветвлений и операциями для исполнительного КЭШа трасс.
Предвыборка
Микроархитектура Intel NetBurst использует следующие механизмы предвыборки:
· Аппаратный выборщик инструкций, автоматически предвыбирающий инструкции
· Аппаратный механизм, который автоматически выбирает данные и инструкции и помещает их в унифицированный кэш второго уровня
· Механизм выборки только данных состоящий из двух частей:
1. аппаратный механизм для выборки смежных нитей КЭШа в 128-байтном секторе, содержащем данные необходимые в случае сбоя нити, или необходимы для предвыборки нитей КЭШа
2. программно контролируемый механизм, выбирающий данные и помещающий их в кэш, использующий инструкции предвыборки
Аппаратный выборщик инструкций читает инструкции по пути, предсказанному в буфере точек ветвления (BTB), в потоковые буферы инструкций. Данные считываются в 32-байтные блоки, начиная с адреса точки. Второй и третий механизм будут рассмотрены позднее.
Декодер
Блок начальной загрузки микроархитектуры Intel NetBurst имеет один декодер, который декодирует инструкции с максимальной частотой в одну инструкцию за такт. Некоторые сложные инструкции должны поддерживаться с помощью ROM-микрокода. Операции декодера связанны с КЭШем трасс.
Исполнительный кэш трасс
Исполнительный кэш трасс (TC) – это основной кэш инструкций в микроархитектуре Intel NetBurst. Кэш трасс хранит декодированные инструкции (микрокоманды) IA-32.
В реализации процессоров Intel Pentium 4 и Intel Xeon, кэш трасс может хранить до 12 тысяч микрокоманд и выдавать до трех микрокоманд за цикл. Кэш трасс не хранит все микрокоманды необходимые для обработки в исполнительном ядре. В некоторых ситуациях, исполнительному ядру необходимо выполнить поток микрокода, вместо трасс микрокоманд, хранящихся в КЭШе трасс.
Процессоры Intel Pentium 4 и Intel Xeon оптимизированы для выполнения часто-используемых IA-32 инструкций, в то время как только некоторые инструкции вовлекают в процесс декодирования ROM-микрокода.
Предсказание ветвей
Предсказание ветвей очень важно для производительности процессоров с большим конвейером. Это позволяет процессору начать работу задолго до того как будет дотошно известен результат ветвления. Задержка при ветвлении – это расплата за неправильное предсказание ветвление. Для процессоров Intel Pentium 4 и Intel Xeon задержка при правильном предсказании может быть нулевой. Задержка же при неправильном предсказании может быть множество циклов, обычно она равна глубине конвейера.
Предсказание ветвей в микроархитектуре Intel NetBurst затрагивает все ближние ветвления (условные вызовы, безусловные вызовы, возвраты и тупиковые ветви). Но не затрагивает дальние переходы (дальние вызовы, неопределенные возвраты, программные прерывания).
Механизмы внедренные для более точного предсказания ветвей и затрат на их обработку:
· Возможность динамически предсказывать направление и точку ветвления, основанная на линейном адресе инструкции, используя буфер точек ветвления (BTB)
· Если нет возможности динамического предсказания или оно не правильное, то существует возможность статического предсказания результата основанного на замене цели: задняя ветвь берется за основную, а основная не берется.
· Возможность предсказания адресов возвратов, с помощью 16-разрядного стека адресов возвратов
· Возможность строить трассы инструкций по всей взятой ветви для избежания расплаты за неправильно предсказание
Статический предсказатель. Как только инструкция ветвления декодирована, направление ветви (вперед или назад) становиться известным. Если BTB нет упоминаний об этом ветвлении, статический предсказатель делает предсказание, основываясь на направлении ветви. Механизм статических предсказаний предсказывает задние условные цели (например, с отрицательным перемещением, такие как ветви оканчивающиеся циклом) как основные. Вперед направленные ветви предсказываются как не основные.
Для использования преимуществ передних-не-основных и задних-основных статических предсказаний, код должен быть упорядочен так, чтобы нежелательные цели находились в передних ветвях.
Буфер точек ветвлений. Если доступна история ветвлений, процессор может предсказать итог ветвления даже раньше, чем инструкция ветвления будет декодирована. Процессор использует таблицу историй ветвлений и BTB для предсказания направления ветвлений, основываясь на линейном адресе инструкции. Как только ветвь изъята, BTB обновляет адреса точек.
Стек возврата. Возвраты происходят всегда. Но с тех пор как процедура может быть вызвана из нескольких мест, технология предсказания одной точки не удовлетворяет потребностям. Процессоры Intel Pentium 4 и Intel Xeon стек возвратов, который может предсказывать адрес возврата, для нескольких мест вызова процедуры. Это увеличивает выгоду от использования развернутых циклов содержащих вызовы функции. Это так же ослабляет необходимость использования ближних процедур, так как уменьшена расплата за возврат из дальних процедур.
Даже если направление и адрес ветвления правильно предсказаны, взятая ветвь может снизить параллелизм в обычных процессорах. Предсказатель ветвлений позволяет ветви и ее цели сосуществовать в одной нити КЭШа трасс, максимизируя доставку инструкций из блока начальной загрузки.
Обзор исполнительного ядра
Исполнительное ядро разработано для оптимизации общей производительности путем более эффективного управления исполнением простых ситуаций. Аппаратное обеспечение спроектировано для выполнения частых операций в простых случаях как можно быстрее, за счет нечасто исполняемых операций. Некоторые части ядра могут предполагать, что текущее состояние сохраняется для возможности быстрого исполнения похожих операций. Если бы этого не было, машина бы стопорилась. Примером такой конструкции может служить управление хранением-для-загрузки (store-to-load). Если загрузка предсказана зависимой от хранения, она получает данные из этого хранилища и предварительно выполняется. Если же загрузка не зависит от хранения, загрузка задерживается до получения реальных данных из памяти, затем она выполняется.
Задержка инструкций и производительность
Суперскалярное исполнительное ядро содержит аппаратные ресурсы, которые могут выполнять множество микроопераций параллельно. Возможности ядра при использовании доступного параллелизма исполнительных блоков могут быть улучшены поддержкой программным обеспечением следующих возможностей:
· Выбор IA-32 инструкций так, чтобы они были декодированы меньше чем в четыре микрокоманды и/или имели меньшие задержки
· Упорядочивание IA-32 инструкций для сохранения доступного параллелизма с помощью минимизирования цепочек длинной зависимости и перекрытия задержек длинных инструкций
· Упорядочивание инструкций так, чтобы их операнды были готовы и их исполнительные блоки и выводные порты были свободны к моменту достижения ими диспетчера
Этот раздел рассматривает распределение портов, задержки выработки результатов и задержек вывода (так же относящиеся к производительности). Эти концепции формируют основу для помощи программному обеспечению в упорядочивании инструкций для увеличения параллельно выполняемых микрокоманд. Порядок команд поставляемых в ядро процессора далее поступает в ведение ресурсов машинного диспетчера.
Исполнительное ядро – это блок, реагирующий на постоянно изменяющуюся ситуацию в машине, реорганизуя микрокоманды для более быстрой обработки или откладывая их из-за занятости или ограниченности ресурсов. Переупорядочивающие инструкции в программном обеспечении позволяют более эффективно использовать аппаратные средства. Некоторые блоки не имеют конвейеров (имеется в виду, что микрокоманды не могут быть размещены в последовательных циклах и их производительность меньше одной микрокоманды за цикл). Количество микрокоманд ассоциированных с каждой инструкцией позволяет выбирать инструкции для генерации. Все микрооперации, вырабатываемые ROM-микрокода, вызывают экстренную нагрузку.
Исполнительные блоки и выводные порты
На каждом цикле ядро может посылать микрокоманды в один или несколько из четырех портов вывода. На микроархитектурном уровне операции хранения делятся на две группы:
1. операции хранения данных
2. операции хранения адресов
Четыре порта, через которые микрокоманды выводятся в исполнительные блоки и служащие для операций загрузки и хранения показаны на рисунке 4. Некоторые порты могут выводить до двух микрокоманд за такт. Они обозначены как исполнительные блоки двойной скорости.
Порт 0. В первой половине цикла, нулевой порт может вывести либо одну сдвиговую микрокоманду с плавающей точкой (сдвиг стека для плавающей точки, обмен между операндами с плавающей точкой или сохранение данных с плавающей точкой), либо одну из микрокоманд арифметико-логического устройства (арифметические, логические, ветвление или сохранение данных). Во второй половине цикла порт может вывести схожую микрокоманду АЛУ.
Порт 1. В первой части цикли первый порт может вывести либо одну из исполнительных операций с плавающей точкой (все исключительные сдвиговые операции с плавающей точкой, все операции SIMD), либо одну арифметическую АЛУ микрокоманду. Во второй части цикла порт может вывести одну схожую микрокоманду АЛУ.
Порт 2. Этот порт обеспечивает вывод одной загрузочной операции за цикл.
Порт 3. Этот порт обеспечивает вывод одной операции сохранения адреса за цикл.
Общая выводная мощность может варьироваться от нуля до шести микрокоманд за цикл. Каждый конвейер состоит из нескольких исполнительных блоков. Микрокоманда помещается в блок конвейера, отвечающий правильному типу операций. Например, целочисленный АЛУ и блок исполнения операций с плавающей точкой (сумматор, множитель или делитель) могут разделять один конвейер.
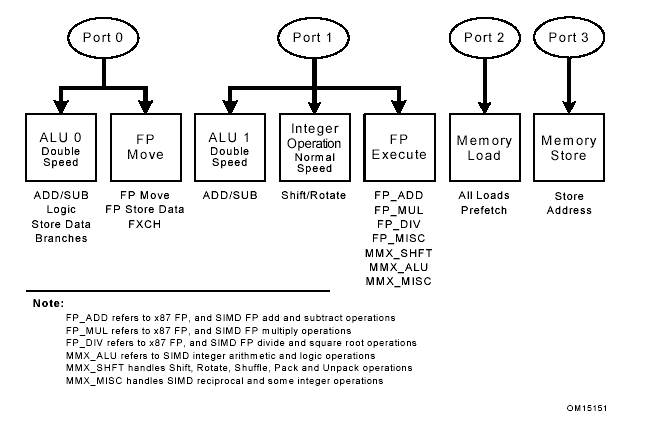
Рисунок 4. Исполнительные блоки и порты беспорядочного ядра
Кэши
Микроархитектура Intel NetBurst поддерживает до трех уровней встроенного КЭШа. По крайней мере, два уровня КЭШа встроены в процессоры, основанные на микроархитектуре Intel NetBurst. Процессоры Intel Xeon MP могут содержать кэш третьего уровня.
Кэш первого уровня (ближайший к исполнительному ядру) состоит из раздельных КЭШей инструкций и данных. Они включают кэш данных первого уровня и кэш трасс (улучшенный кэш инструкций первого уровня). Все остальные кэши делятся между инструкциями и данными.
Уровни в иерархии КЭШа не взаимовключающие. Факт того, что нить находиться на уровне N не означает, что она так же находиться на уровне N+1. Все кэши используют алгоритм замен псевдо-НЧИ (наименее часто используемые).
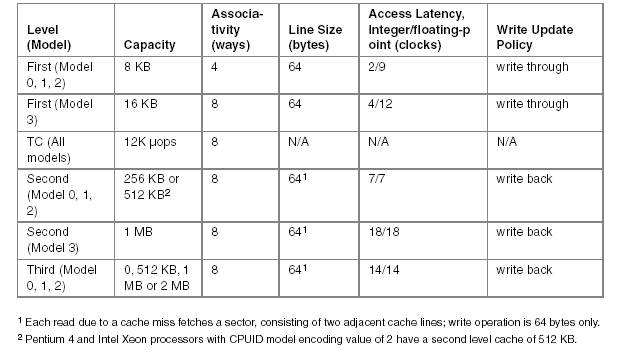
Таблица 1 приводит сравнительные параметры КЭШей всех уровней процессоров Pentium 4 и Xeon.
Таблица 1. Параметры кэша процессоров Pentium 4 и Intel Xeon
На процессорах без КЭШа третьего уровня, промах КЭШа второго уровня инициирует транзакцию через интерфейс системной шины в подсистему памяти. На процессорах с тремя уровнями КЭШа, промах КЭШа третьего уровня инициирует транзакцию через системную шину. Транзакция записи через шину записывает 64 байта в кэшируемую память, или раздельные восьми байтные контейнеры, если место назначения не кэшируется. Транзакция чтения через шину из кэшируемой памяти извлекает две нити данных КЭШа.
Интерфейс системной шины поддерживает работу с масштабируемой частотой шины и достигает эффективной скорости в четыре раза превышающей скорость шины. Маршрут от входа в шину и обратно занимает двенадцать процессорных циклов, и от шести до двенадцати циклов для доступа к памяти, если шина не перегружена. Каждый цикл шины соответствует нескольким циклам процессора. Отношение тактовой частоты процессора к масштабируемой тактовой частоте системной шины, если один цикл шины. Например, один цикл шины с частотой 100 МГц эквивалентен пятнадцати циклом процессора в 1,5 ГГц процессоре.
Предвыборка данных
Процессоры Intel Xeon и Pentium 4 имеют два механизма предвыборки данных: программно управляемая предвыборка и автоматическая аппаратная предвыборка.
Программно управляемая предвыборка включается с помощью четырех инструкций предвыборки (PREFETCHh) представленных в SSE. Программно управляемая предвыборка не обязательна для предвыборки кодов. Ее использование может привести к большим проблемам в многопроцессорных системах, если код разделен между процессорами.
Программно управляемая предвыборка данных может принести выгоду в следующих ситуациях:
· когда блок команд доступа к памяти в приложении позволяет программисту перекрыть задержки доступа к памяти
· когда точный выбор может быть сделан, основываясь на знании количества нитей кэша к выбору в дальнейшем перед исполнением текущей нити
· когда выбор может быть сделан, основываясь на знании того, какую предвыборку необходимо использовать
Инструкции предвыборки SSE имеют различные характеры поведения в зависимости от уровня кэша и реализации процессора. Например, в процессоре может быть реализована постоянная предвыборка, путем возврата данных в уровень кэша, ближайший к ядру процессора. Такой метод приводит к следующему:
· минимизирует нарушения временных данных в других уровнях кэша
· предупреждает необходимость доступа к внекристальным КЭШам, что может увеличить реализованную мощность относительно неправильной загрузки, которая перегружает данные во все уровни кэша
Ситуации, в которых не желательно использовать программно управляемую предвыборку:
· в случаях, когда запросы определены, предвыборка приводит к увеличению требований запросов
· в случае предвыборки далеко вперед, она может привести к вытеснению кэшированных данных из кэша раньше, чем они будут использованы
· слишком близкая предвыборка может снизить возможность к перекрытию задержек доступа к памяти и выполнения
Программные предвыборки потребляют ресурсы в процессоре, и использование слишком многих предвыборок может ограничить их эффективность. Примеры таких предвыборок включают предвыборку данных в цикле для не зависимости от информации находящейся вне цикла и предвыборку в основных блоках, которые часто исполняются, но которые редко используют ее не зависимо от целей предвыборки.
Автоматическая аппаратная предвыборка – механизм, реализованный в процессорах Intel Xeon и Intel Pentium 4. Она заносит нити кэша в унифицированный кэш второго уровня, основанный на ранних независимых моделях.
Плюсы и минусы программной и аппаратной предвыборки
Программная предвыборка имеет следующие характеристики:
· обрабатывает необычные модели доступа, которые не перехватываются аппаратным предвыборщиком
· обрабатывает предвыборку коротких массивов и не имеет аппаратной начальной задержки перед инициацией выборок
· должна быть добавлена в каждый новый код, так что она не относится к уже запущенным приложениям
Аппаратная предвыборка имеет следующие характеристики:
· работает с уже существующими приложениями
· не требует хорошего знания инструкций предвыборки
· требует постоянных моделей доступа
· предупреждает перегрузку инструкций и выводных портов
· имеет начальную задержку на настройку аппаратного предвыборщика и начало инициации выборок
Аппаратный предвыборщик может обрабатывать множество потоков, как в прямом, так и в обратном направлении. Начальная задержка и «выборка-на-перед» имеет больший эффект на коротких массивах, когда аппаратная предвыборка генерирует запрос на данные уже в конце обработки массива (вообще-то в этих случаях она даже не начинается). Аппаратная задержка уменьшается при обработке более длинных массивов.
Загрузка и хранение
В процессорах Intel Xeon и Pentium 4 реализованы следующие механизмы увеличения скорости обработки операций с памятью:
· спекулятивное выполнение загрузок
· реорганизация загрузок с учетом загрузок и хранений
· буферизация записей
· управление потоком данных из хранилищ в зависимые загрузки
производительность может быть увеличена не с помощью ширины канала вывода памяти, а буферизацией ресурсов предоставляемых процессором. По одной операции загрузки и хранения может быть выдано из станции резервирования портов памяти за цикл. Для того, чтобы быть помещенной в станцию хранения, для каждой операции с памятью должен быть доступен буферизированный вход. Имеются 48 загрузочных и 24 хранящих буфера. Эти буфера содержат микрокоманды и адресную информацию до тех пор, пока операция не выполнена, извлечена и перемещена.
Процессоры Intel Pentium 4 и Intel Xeon спроектированы для исполнения операций памяти в беспорядочном режиме относительно других инструкций и относительно друг друга. Загрузки могут выполняться спекулятивно, то есть до того как найдены результаты всех ветвлений. Несмотря на это, спекулятивные загрузки не могут вызвать ошибку страницы.
Реорганизация загрузок относительно друг друга может предотвратить не верную загрузку из более поздних (предсказанных). Реорганизация загрузок относительно других загрузок и хранилищ по различным адресам позволяет больше параллелизма, что в свою очередь позволяет машине выполнять операции, как только готовы их входные данные. Запись в память всегда выполняется спекулятивно в оригинальном порядке для исключения ошибок.
Промах кэша для загрузки не предотвращает другие загрузки от выдачи и завершения. Процессоры Intel Xeon и поддерживают до 4 (8 для Intel Xeon и Pentium 4 с сигнатурой CPUID относящихся к семейству 15, модели 3) исключительных промаха загрузки, произведенных, как кэшем в кристалле, так и памятью.
Хранящие буфера улучшают производительность, позволяя процессору продолжать выполнение инструкций, не задерживаясь пока запись в кэш или память будет завершена. Запись обычно не производиться на практических путях зависимых цепочек, так что обычно лучше отложить запись для более эффективного использования памяти.
Управление хранением
Загрузка может быть сдвинута относительно хранения, если не предсказано загружать по тому же линейному адресу, что и хранение. Если они действительно производят чтение по тому же линейному адресу, они должны дождаться пока сохраненные данные не станут доступными. Несмотря на это, им не требуется ждать, пока хранилище сделает запись в иерархию памяти и закончит работу. Данные из хранилища могут быть направлены напрямую, если выполняются следующие условия:
· Очередность: данные, направляемые в загрузку, сгенерированы программно ранее выполненным хранением
· Размерность: загружаемые байты должны бать подмножеством (включая правильное подмножество, что одно и то же) байтов хранилища
· Выравнивание: хранилище не может вращаться внутри границ нити кэша, и линейный адрес загрузки должен быть идентичен адресу хранилища
Технология Hyper-Threading
Технология Intel Hyper-Threading (HT) поддерживается специфичными членами семейств Intel Xeon (Nocona) и Intel Pentium (Prescott). Технология позволяет приложениям пользоваться преимуществами параллелизма, представляемыми на уровне заданий или потоков несколькими логическими процессорами внутри одного физического. В своей первой реализации в процессоре Intel Xeon, НТ представляла один физический процессор как два логических. Эти два логических процессора имеют полный набор архитектурных регистров, разделяя ресурсы одного физического процессора. Имея архитектуру двух процессоров, НТ встроенная в процессор выглядит как два процессора для приложений, операционных систем и программного кода.
При помощи распределения ресурсов, при пиковых запросах, между двумя логическими процессорами, НТ хорошо подходит для многопроцессорных систем, производя дополнительное увеличение мощности по сравнению с обычными многопроцессорными системами.
Рисунок 6 показывает типичную шинно-основанную симметричную многопроцессорную систему (SMP), основанную на процессорах поддерживающих технологию НТ. Каждый логический процессор может выполнять программный поток, позволяя двум потокам выполняться одновременно в одном физическом процессоре.
В технологии НТ физические ресурсы делятся, а архитектурная модель дублируется для каждого логического процессора. Это минимизирует потери от мертвых зон, при достижении целей много потоковых приложений или многозадачных платформ.

Рисунок 5. Технология Hyper-Threading на SMP
Производительный потенциал НТ основывается:
· на факте, что операционная система и пользовательские приложения могут закреплять потоки или процессы за логическими процессорами каждого из физических процессоров.
· Возможности к использованию исполнительных ресурсов кристалла на более высоком уровне, чем когда один поток потребляет все исполнительные ресурсы
Ресурсы процессора и технология Hyper-Threading
Большинство микроархитектурных ресурсов физического процессора делятся между логическими процессорами. Только некоторые небольшие структуры данных дублируются для каждого логического процессора. В этом разделе описывается, как ресурсы разделяются, делятся или реплицируются.
Реплицированные ресурсы
Архитектурная модель дублируются для каждого логического процессора. Архитектурная модель состоит из регистров используемых операционной системой и программного кода контролирующего взаимодействие программ и хранение данных для вычислений. Эта модель включает восемь регистров специального назначения, контролирующие регистры, регистры отладки и т.д. За исключением MTRRs – регистров (memory type range registers) и ресурсов мониторинга за производительностью
Остальные ресурсы, такие как указатели инструкций, таблицы переименований регистров, реплицируются для одновременного слежения за выполнением и изменениями в логических процессорах. Предсказатель стека возвратов реплицируется для улучшения предсказания ветвлений инструкций возврата.
В дополнение реплицируются несколько буферов (например, двух входные буферы потоковых инструкций), для снижения нагрузки.
Разделенные ресурсы
Несколько буферов делятся пополам между процессорами. Они относятся к разделенным ресурсам. Причины этого деления:
· Операционная равнодоступность
· Возможность операций одного логического процессора не зависеть от зависших операций другого логического процессора
Промах кэша, неверное предсказание ветвления или зависимости инструкций могут помешать логическому процессору работать на полной мощности в течение некоторого числа циклов. Разделение предотвращает зависший логический процессор от блокирования.
Главное, буфера инструкций очередей для главного конвейера делятся между процессорами. Эти буфера включают очереди микрокоманд после исполнительного кэша трасс, очереди после стадии переименования регистра, разупорядочивающий буфер, который хранит очередь инструкций для изъятия и загрузочные и хранящие буфера.
В случае буферов загрузки и хранения, деление так же производиться в легком варианте, для получения реорганизации памяти для каждого логического процессора и для определения ошибок организации памяти.
Разделяемые ресурсы
Большинство ресурсов в физическом процессоре полностью разделяются для улучшения динамического использования ресурсов, включая кэши и все исполнительные блоки. Некоторые разделяемые ресурсы, адресованные линейно, например DTLB, включают бит идентификации логического процессора, для определения какому логическому процессору принадлежит информацию.
Микроархитектура конвейера и технология НТ
В этой части описывается микроархитектура НТ, и как инструкции из двух логических процессоров распределяются между блоком начальной и конечной загрузки конвейера.
Так как инструкции, передаваемые из двух программ или процессов, выполняются одновременно, нет необходимости в жестком программном порядке в исполнительном ядре и иерархии памяти, блоки начальной и конечной загрузки содержат несколько выборных точек для выбора между инструкциями из двух логических процессоров. Все выборные точки работают между двумя логическими процессорами, за исключением случаев, когда один из логических процессоров не может использовать текущее состояние конвейера. В этом случае другой логический процессор использует каждый цикл конвейер в полном объеме. Причины, по которым один из логических процессоров не может использовать конвейер – это промахи загрузки кэша, не верное предсказание ветвлений и зависимость инструкций.
Блок начальной загрузки конвейера
Исполнительный кэш трасс разделяется между двумя логическими процессорами. Доступ к исполнительному кэшу трасс произвольно делиться между двумя логическими процессорами каждый такт. Если нить кэша выбрана для одного логического процессора в одном цикле, в следующем цикле нить будет выбрана для другого логического процессора. Таким образом, оба логических процессора запрашивают доступ к кэшу трасс.
Если один логический процессор зависает или не может использовать исполнительный кэш трасс, другой будет использовать кэш трасс на всю мощность до тех пор, пока инструкция инициации логического процессора не выдаст ему команду возврата из кэша второго уровня.
После выборки инструкций и построения трасс микрокоманд, они ставятся в очередь. Эта очередь разделяет кэш трасс, начиная с блока переименования регистров конвейера. Как было описано выше, если оба логических процессора активны, очередь делиться, так что оба процессора могут обрабатывать информацию независимо.
Исполнительное ядро
Ядро может выдавать до шести микрокоманд за цикл, готовых к исполнению. Как только микрокоманда помещена в очередь, ожидая выполнения, нет разницы между тем из какого процессора пришла эта инструкция. Исполнительному ядру и иерархии памяти так же безразлично, к какому процессору принадлежат инструкции.
После исполнения, инструкции помещаются в переупорядочивающий буфер. Переупорядочивающий буфер разделяет исполнительную стадию от стадии извлечения. Переупорядочивающий буфер делиться так, что каждый логический процессор использует половину входов.
Извлечение
Логика извлечений следит, когда инструкции из двух логических процессоров готовы к извлечению. Она извлекает инструкции в программном порядке для каждого логического процессора по очереди. Если один из логических процессоров не готов к извлечению любой инструкции, все изъятые инструкции направляются в другой процессор.
Как только информация извлечена из хранилища, процессору необходимо записать хранимые данные в кэш данных первого уровня. Выборочная логика чередуется между двумя логическими процессорами для передачи хранимых данных в кэш.
Список использованной литературы
1. IA-32 Intel® Architecture Optimization Reference Manual
2. www.intel.com
3. www.iXTB.com
4. www.allintel.ru